Redis Streams + Apache Spark Structured Streaming
A quick look into how Redis Streams and Apache Spark can be combined to effectively work with structured data streams.
Join the DZone community and get the full member experience.
Join For FreeRecently, I had the honor of presenting my talk, "Redis + Structured Streaming: A Perfect Combination to Scale-out Your Continuous Applications" at the Spark+AI Summit.
My interest in this topic was fueled by new features introduced in Apache Spark and Redis over the last couple months. Based on my previous use of Apache Spark, I appreciate how elegantly it runs batch processes, and the introduction of Structured Streaming in version 2.0 is further progress in that direction.
Redis, meanwhile, recently announced its new data structure, called " Streams," for managing streaming data. Redis Streams offers asynchronous communication between producers and consumers, with additional features such as persistence, look-back queries, and scale-out options — similar to Apache Kafka. In essence, with Streams, Redis provides a light, fast, easy-to-manage streaming database that benefits data engineers.
Additionally, the Spark-Redis library was developed to support Redis data structures as resilient distributed data sets (RDD). Now, with Structured Streaming and Redis Streams available, we decided to extend the Spark-Redis library to integrate Redis Streams as a data source for Apache Spark Structured Streaming.
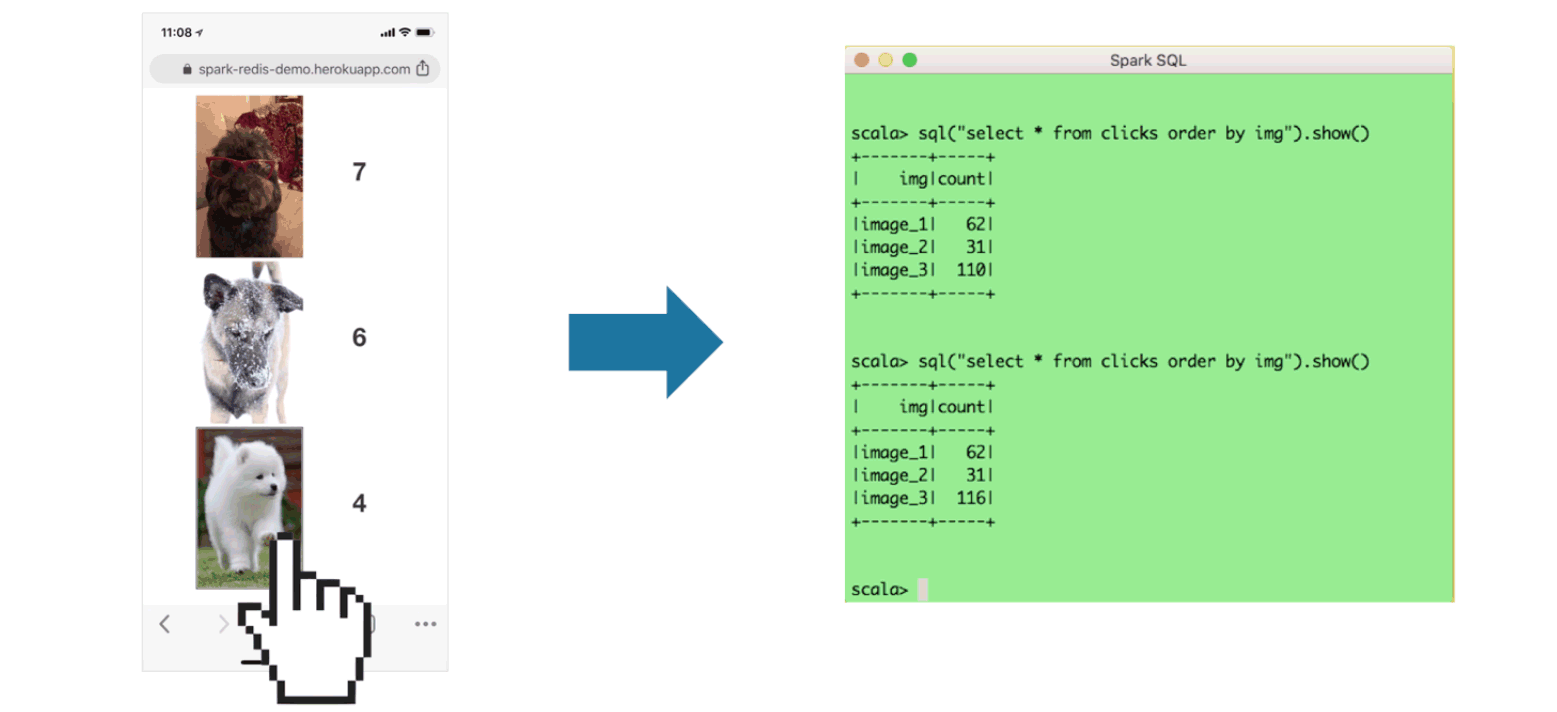
During my talk last month, I demonstrated how you can collect user activity data in Redis Streams and sink it to Apache Spark for real-time data analysis. I developed a small, mobile-friendly Node.js app where people can click on the dog they love most, and I used it to run a fun contest through my session. It was a tough fight, and a couple of folks in the audience even got creative with hacking my app. They changed the HTML button name using the "page inspect" option and tried to mess with my demo. But in the end, Redis Streams, Apache Spark, the Spark-Redis library, and my code were all robust enough to handle those changes effectively.
The audience also asked some interesting questions during and after my presentation, such as:
- How can I scale out if my data processing is slower than the rate at which Redis Streams receives the data? My Answer: Configure a consumer group, and run each Spark job as a different Redis Streams consumer belonging to that group. That way, every job gets an exclusive set of data. It's important to set the output mode to "update" so that each job doesn't overwrite the other job's data commits.
- What happens to the data in Redis Streams if I restart my Spark job? My Answer: Redis Streams persists data. Therefore, your Spark job won't miss any data. If you restart your Spark job, it will pull the data from the point where it left off.
- Can I develop my Spark app in Python? (My demo was written in Scala) My Answer: Yes, you can. Please see our Spark-Redis documentation on GitHub.
- Can I deploy Redis Streams on the cloud? My Answer: Yes, Streams is just another data structure in Redis that's built into Redis starting from release 5.0. The quickest way to start is to sign up at https://redislabs.com/get-started.
My main takeaway from the summit was that there's growing interest in continuous processing and data streaming. Owing to the demand, we published a more detailed article on this topic over at InfoQ, which offers a detailed recipe for how to set up Redis Streams and Apache Spark and connect both using the Spark-Redis library. Or feel free to check out the full video of my presentation here.
Published at DZone with permission of Roshan Kumar, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments