High-Speed Real-Time Streaming Data Processing
The article discusses the need for streaming data processing and evaluates available options. It explains that one size fits all is approach is not appropriate.
Join the DZone community and get the full member experience.
Join For FreeFrom data ingestion to reporting, the primary goal is to convert data into actionable information. Online data is growing at a much faster rate than data processing speeds. For businesses to stay competitive, data must be readily available for making informed decisions as early as possible. Live data streaming software is becoming a vital part of data infrastructures to get data to processing systems as early as possible. While different streaming software are available, it is crucial to understand the domain context and available infrastructure.
Each business use case is unique and should be treated with white-glove treatment. The critical thing to remember is that cheap, fast, and good will never make a feasible combination. The affordable solution may be quick but not good; a fast solution may be good but not cheap, and so on. An ideal example of this concept would be real-time streaming data processing.
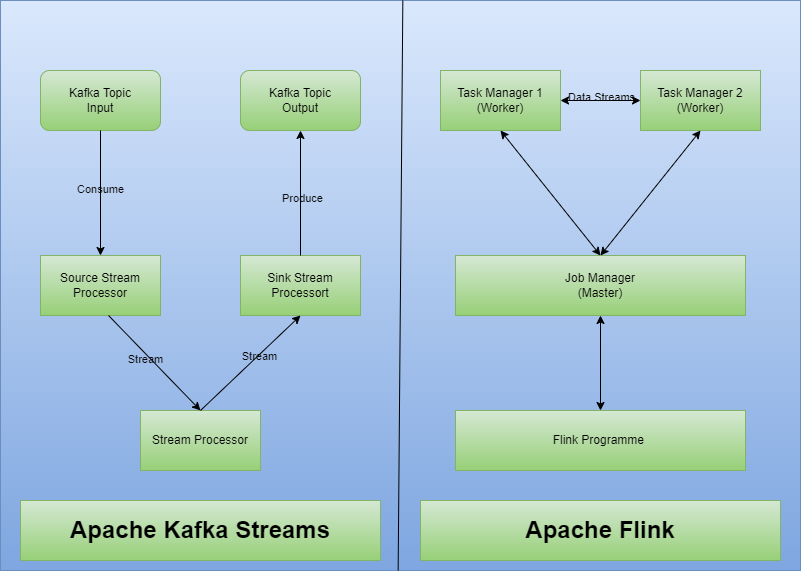
Processing Real-Time Streaming Data Apache Flink or Kafka Streams
As new technologies fuel today's businesses, digital data generation is vast and needs to be ingested faster than its current pace.
Apache Kafka stands tall for ingesting live streaming data and enabling businesses to ingest it much faster than traditional batch processing workflows. It is an open-source, publish-subscribe model event store and streaming platform. With its distributed fault-tolerant architecture, Apache Kafka can reliably process millions of events in seconds.
Pairing Kafka with either Kafka Streams or Flink tools would boost its functionality significantly as they enable real-time data processing before data reaches the applications could lessen or eliminate the need for data processing steps. Kafka Streams is a Kafka library provided for stream processing and manipulation. Apache Flink is a data processing software that can work with stream or batch data.
Cost and Infrastructure
The setup differences between Apache Kafka Streams and Apache Flink are notable regarding infrastructure configuration needs: Apache Kafka Streams can function without machine expenses as it operates on Kafka brokers, while Apache Flink demands a cluster of machines to manage larger workloads.
Performance
Although the Flink setup and configuration are more intensive than those of Kafka Stream, its benefits outweigh the work needed for its setup. Kafka streams can be used in real-time analytics with moderate workloads. Flink can distribute this load across multiple servers and process it in parallel, making it much more suitable for low-latency, high-volume complex workloads.
Complex Event Processing
In real-time streaming analytics, complex event processing helps to establish patterns and trends in data as it arrives. Given the extensive nature of this process, it demands more compute resources. Apache Flink, with its dedicated hardware setup, is more suited for advanced complex event processing use cases.
Reliability
Kafka streams provide reasonable fault tolerance by leveraging their built-in fault tolerance mechanism. Apache Flink offers fault tolerance through an enhanced checkpoint system that's highly reliable for critical data processing scenarios.
Development
Kafka Streams development is Java-dependent and one might face limitations when trying to integrate programming languages compared to the flexibility that Flink offers in supporting languages seamlessly.
Conclusion
Fundamentally, it comes down to the business use case, as Apache Flink and Kafka Streams serve the same purpose of live-stream data processing. The context, e.g., current infrastructure, learning curve for adopting new technology, workload volume, and complexity, is critical in deciding which technologies align with a company's best practices.
Opinions expressed by DZone contributors are their own.
Comments