Preventing and Fixing Bad Data in Event Streams (Part 1)
In this blog, we’ll take a look at how bad data may come to be, and how we can deal with it when it comes to event streams.
Join the DZone community and get the full member experience.
Join For FreeAt a high level, bad data is data that doesn’t conform to what is expected. For example, an email address without the “@”, or a credit card expiry where the MM/YY format is swapped to YY/MM. “Bad” can also include malformed and corrupted data, such that it’s completely indecipherable and effectively garbage.
In any case, bad data can cause serious issues and outages for all downstream data users, such as data analysts, scientists, engineers, and ML and AI practitioners. In this blog, we’ll take a look at how bad data may come to be, and how we can deal with it when it comes to event streams.
Event Streams in Apache Kafka are predicated on an immutable log, where data, once written, cannot be edited or deleted (outside of expiry or compaction — more on this later). The benefit is that consumers can read the events independently, at their own pace, and not worry about data being modified after they have already read it. The downside is that it makes it trickier to deal with “bad data,” as we can’t simply reach in and edit it once it’s in there.
In this post, we look at bad data in relation to event streams. How does bad data end up in an event stream? What can we do about it? What’s the impact on our downstream consumers, and how can we fix it?
First, let’s take a look at the batch processing world, to see how they handle bad data and what we can learn from them.
Bad Data in Batch Processing
What is batch processing? Let’s quote Databricks, and go with:
Batch Processing is a process of running repetitive, high volume data jobs in a group on an ad-hoc or scheduled basis. Simply put, it is the process of collecting, storing and transforming the data at regular intervals.
Batch processing jobs typically rely on extracting data from a source, transforming it in some way, and then loading it into a database (ETL). Alternately, you can load it into the destination before you transform any of the data, in a recently trendy mode of operations known as ELT (by the way, data lake/warehouse people LOVE this pattern as they get all the $$$ from the transform).
A friend and former colleague wrote more about ELTs and ETLs here, so take a look if you want to see another data expert’s evaluation. The gist, though, is that we get data from “out there” and bring it into “here”, our data lake or warehouse.

In this figure, a periodic batch job kicks off, processes the data that lands in the landing table, and does something useful with it — like figure out how much money the company is owed (or how much your Datalake is costing you). Accomplishing this requires a reliable source of data — but whose job is it to ensure that the data powering the data lake is trustworthy and high quality?
To cut to the chase, the data (or analytics) engineers in the data lake are responsible for getting data from across the company, pulling it in, and then sorting it out into a trustworthy and reliable format. They have little to no control over any of the changes made in production land.
Data engineers typically engage in significant break-fix work keeping the lights on and the pipelines up and running. I would know, as I did this type of work for nearly 10 years. We’d typically apply schemas to the data once it lands in the data lake, meaning that changes to the source database table in production land may (likely) break the data sources in the data lake. Data engineers spend nights and weekends fixing malfunctioning data pipelines, broken just hours ago by the 5 pm database migration.
Why are the data engineers responsible for applying schemas? The operational system owners have historically had no responsibility for data once it has crossed out of the source application boundary. Additionally, the data engineers taking the data out of the operational system are performing a “smash ‘n grab”, taking the data wholesale from the underlying database tables. It’s no surprise then that the operational team, with no responsibility for data modeling outside of their system, causes a breakage through a perfectly reasonable database change.
The following figure shows how a broken ETL job (1) can cause bad data to show up in the Landing table (2), eventually resulting in (3) bad results. The exact reason for a broken ETL can vary, but let’s just say in this case it’s due to a change in types in the source database table (an int is now a string) that causes type-checking errors downstream.
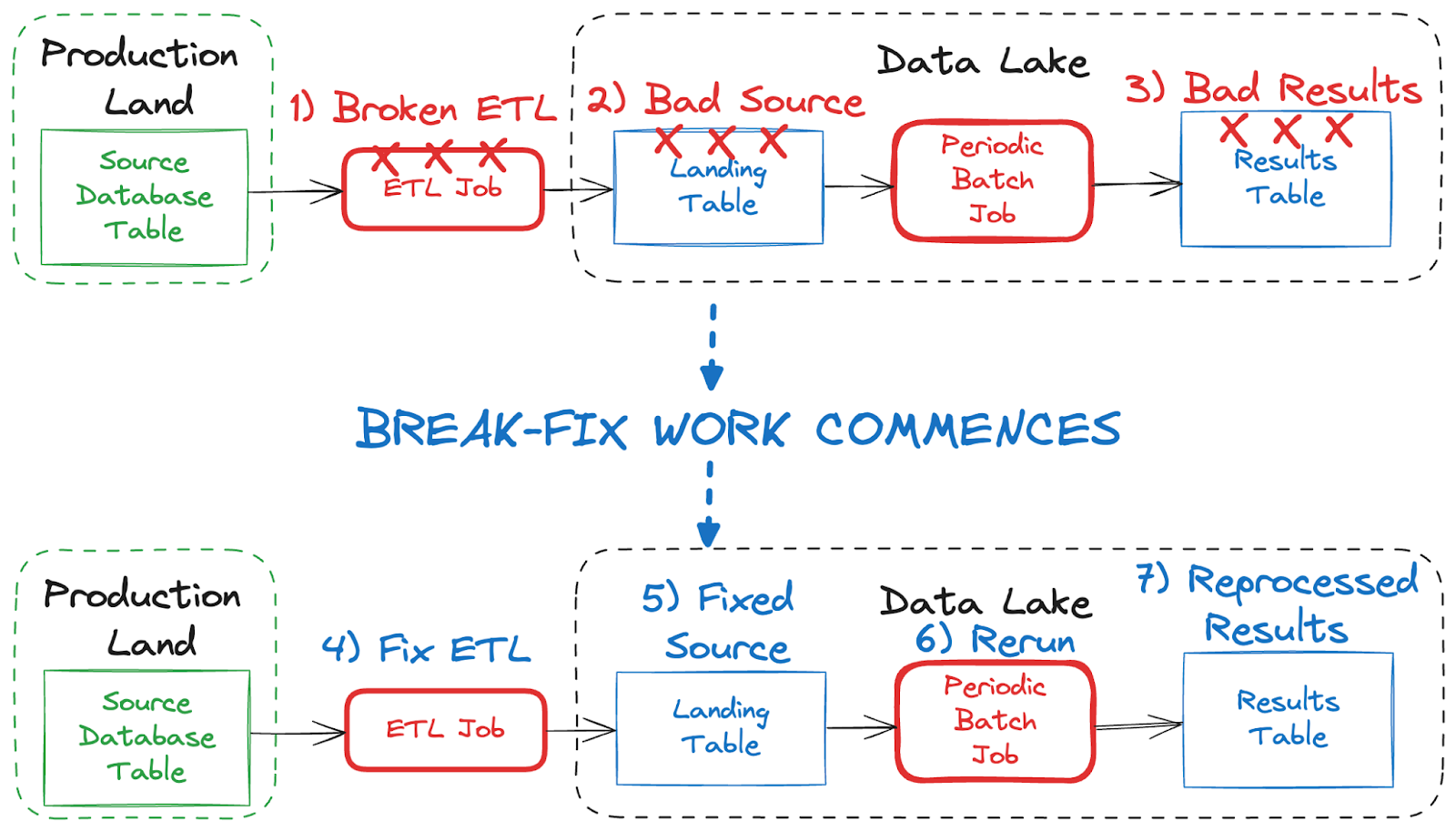
Once the data engineers spring from their beds and leap into action at 3 in the morning (when all data problems naturally occur), they can proceed to fix the ETL (4) by adding logic to handle the unexpected change. Next, they reprocess the failed batch to fix the landing table data (5), then rerun the job (6) that recomputes the results table (7) for the affected rows.
For instance, say (7 — above) is a hive-declared table containing daily sales aggregate. I’m only going to delete and recompute the aggregates that I know (or think) are incorrect. I won’t drop the whole table and delete all the data if only a known subset is affected. I’ll just surgically remove the bad days (eg, April 19 to 21, 2024), reprocess (6 — above) for that time range, and then move on to reprocessing the affected downstream dependencies.
Batch processing relies extensively on cutting out bad data and selectively replacing it with good data. You reach right into that great big data set, rip out whatever you deem as bad, and then fill in the gap with good data — via reprocessing or pulling it back out of the source.
Bad Data Contaminated Data Sets
The jobs that are downstream of this now-fixed data set must also be rerun, as their own results are also based on bad input data. The downstream data sets are contaminated, as are any jobs that run off of a contaminated data set. This is actually a pretty big problem in all of data engineering, and is why tools like dbt, and services like Databrick’s Delta Tables and Snowflake’s Dynamic Tables are useful — you can force recomputation of all dependent downstream jobs, including dumping bad data sets and rebuilding them from the source.
But I digress. The important thing to note here is that once you get bad data into your data lake, it spreads quickly and easily and contaminates everything it touches. I’m not going to solve this problem here for you in this blog, however, but I do want you to be aware that it’s not always as simple as “cut out the bad, put in the good!” for fixing bad data sets. The reality is a lot messier, and that’s a whole other can of worms that I’m just going to acknowledge as existing and move on.
Incremental Batch Processing
One more word about processing data in batches. Many people have correctly figured out that it’s cheaper, faster, and easier to process your data in small increments, and named it incremental processing. An incremental processing job reads in new data and then applies it to its current state based on its business logic. For example, computing the most popular advertisements in 2024 would simply require a running tally of (advertisementId, clickCount), merging in the new events as they arrive.
However, let’s say that you had bad data as input to your incremental job — say we’ve incorrectly parsed some of the click data and attributed them to the wrong advertisementId. To fix our downstream computations we’d have to issue unclick data, telling them “remove X clicks from these ads, then add X clicks to these other ads”.
While it’s possible we could wire up some code to do that, the reality is we’re going to keep it simple: Stop everything, blow all the bad data away, rebuild it with good data, and then reprocess all the jobs that were affected by it.
“Hold on”, you might say. “That’s nonsense! Why not just code in removals in your jobs? It can’t be that hard”. Well… kinda. For some jobs with no dependencies, you may be correct. But consider a moment if you have a process computing state beyond just simple addition and subtraction, as pretty much all businesses do.
Let’s say you’re computing taxes owed for a corporation, and you’re dealing with dozens of different kinds of data sets. The logic for generating the final state of your corporate taxes is winding, treacherous, and not easily reversible. It can be very challenging and risky to code mechanisms to reverse every conceivable state, and the reality is that there will be cases that you simply don’t foresee and forget to code.
Instead of trying to account for all possible reversal modes, just do what we do with our misbehaving internet routers. Just unplug it, wipe the state, and start it over. Heck, even dbt encourages this approach for misbehaving incremental jobs, calling it a full_refresh.
Here are the important takeaways as we head into the streaming section.
- There is little prevention against bad data: The data engineering space has typically been very reactive. Import data of any and all quality now, and let those poor data engineers sort it out later. Enforced schemas, restrictions on production database migrations, and formalized data contracts between the operations and data plane are rarely used.
- The batch world relies on deleting bad data and reprocessing jobs: Data is only immutable until it causes problems, then it’s back to the drawing board to remutate it into a stable format. This is true regardless of incremental or full refresh work.
I am often asked, “How do we fix bad data in our Kafka topic?” This is one of the big questions I myself asked as I got into event streaming, as I was used to piping unstructured data into a central location to fix up after the fact.
I’ve definitely learned a lot of what not to do over the years, but the gist is that the strategies and techniques we use for batch-processed data at rest don’t transfer well to event streams. For these, we need a different set of strategies for addressing bad data.
But before we get to those strategies, let’s briefly examine what happens to your business when you have bad data in your system.
Beware the Side Effects of Processing Bad Data
Bad data can lead to bad decisions, both by humans and by services. Regardless of batch processing or streaming, bad data can cause your business to make incorrect decisions. Some decisions are irreversible, but other decisions may not be.
For one, reports and analytics built on bad data will disagree with those built on good data. Which one is wrong? While you’re busy trying to figure it out, your customer is losing confidence in your business and may choose to pull out completely from your partnership. While we may call these false reports a side effect, in effect, they can seriously affect the affectations of our customers.
Alternatively, consider a system that tabulates vehicle loan payments, but incorrectly flags a customer as non-paying. Those burly men that go to repossess the vehicle don’t work for free, and once you figure out you’ve made a mistake, you’ll have to pay someone to go give it back to them.
Any decision-making that relies on bad data, whether batch or streaming, can lead to incorrect decisions. The consequences can vary from negligible to catastrophic, and real costs will accrue regardless of if it’s possible to issue corrective action. You must understand there can be significant negative impacts from using bad data in stream processing, and only some results may be reversible.
With all that being said, I won’t be able to go into all of the ways you can undo bad decisions made by using bad data. Why? Well, it’s primarily a business problem. What does your business do if it makes a bad decision with bad data? Apologize? Refund? Partial Refund? Take the item back? Cancel a booking? Make a new booking?
You’re just going to have to figure out what your business requirements are for fixing bad data. Then, you can worry about the technology to optimize it. But let’s just get to it and look at the best strategies for mitigating and dealing with bad data in event streams.
I’m Streaming My Life Away
Event streams are immutable (aside from compaction and expiry). We can’t simply excise the bad data and inject corrected data into the space it used to occupy. So what else can we do?
The most successful strategies for mitigating and fixing bad data in streams include, in order:
- Prevention: Prevent bad data from entering the stream in the first place: Schemas, testing, and validation rules. Fail fast and gracefully when data is incorrect.
- Event design: Use event designs that let you issue corrections, overwriting previous bad data.
- Rewind, rebuild, and retry: When all else fails.
In this blog, we’re going to look primarily at prevention, covering the remaining strategies in a follow-up post. But to properly discuss these solutions, we need to explore what kind of bad we’re dealing with and where it comes from. So let’s take a quick side trip into the main types of bad data you can expect to see in an event stream.
The Main Types of Bad Data in Event Streams
As we go through the types, you may notice a recurring reason for how bad data can get into your event stream. We’ll revisit that at the end of this section.
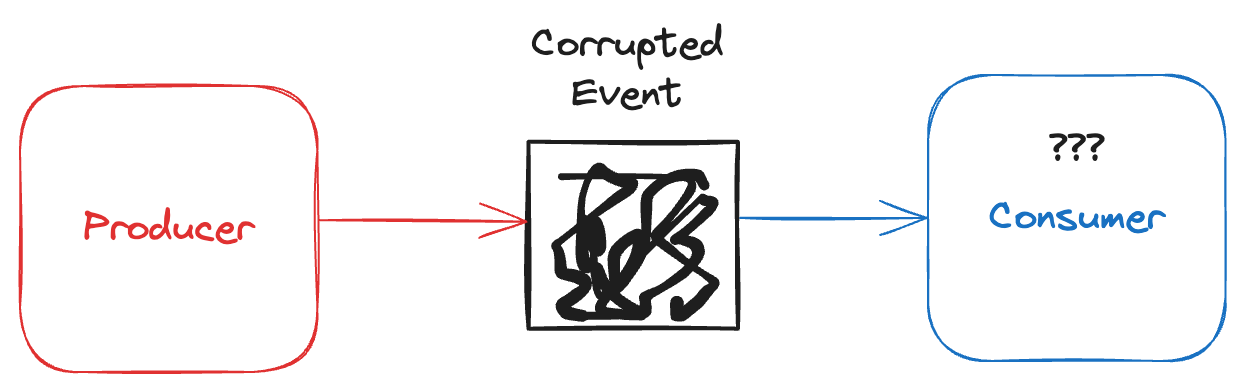
1. Corrupted Data
The data is simply indecipherable. It’s garbage. It turned into a sequence of bytes with no possible way to retrieve the original data. Data corruption is relatively rare but may be caused by faulty serializers that convert data objects into a plain array of bytes for Kafka. Luckily, you can test for that.
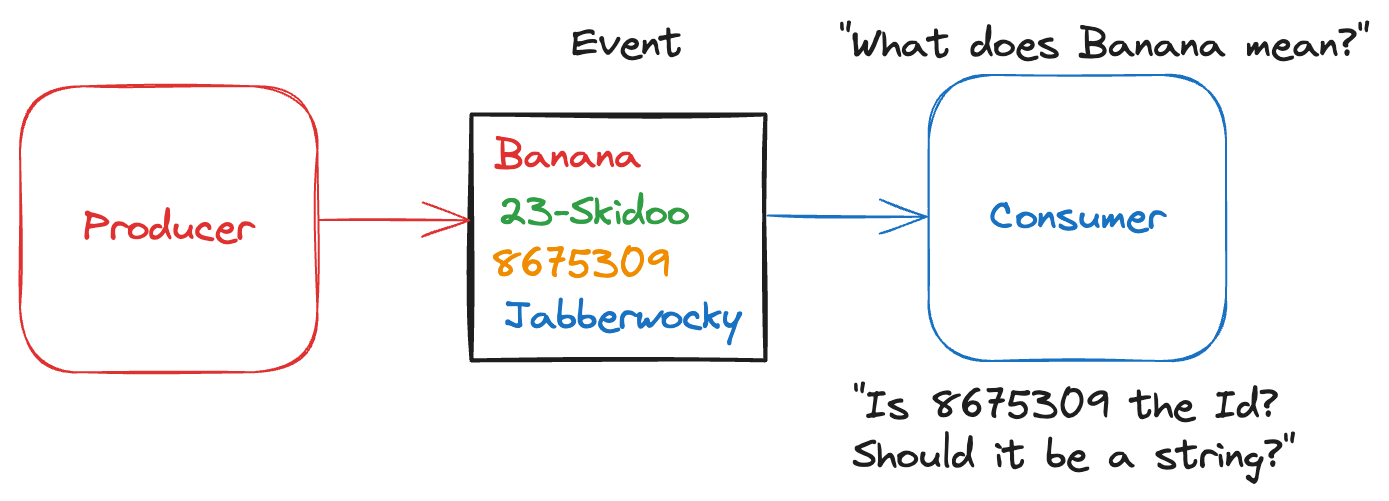
2. Event Has No Schema
Someone has decided to send events with no schema. How do you know what’s “good data” and what’s “bad data”, if there are no structure, types, names, requirements, or limitations?
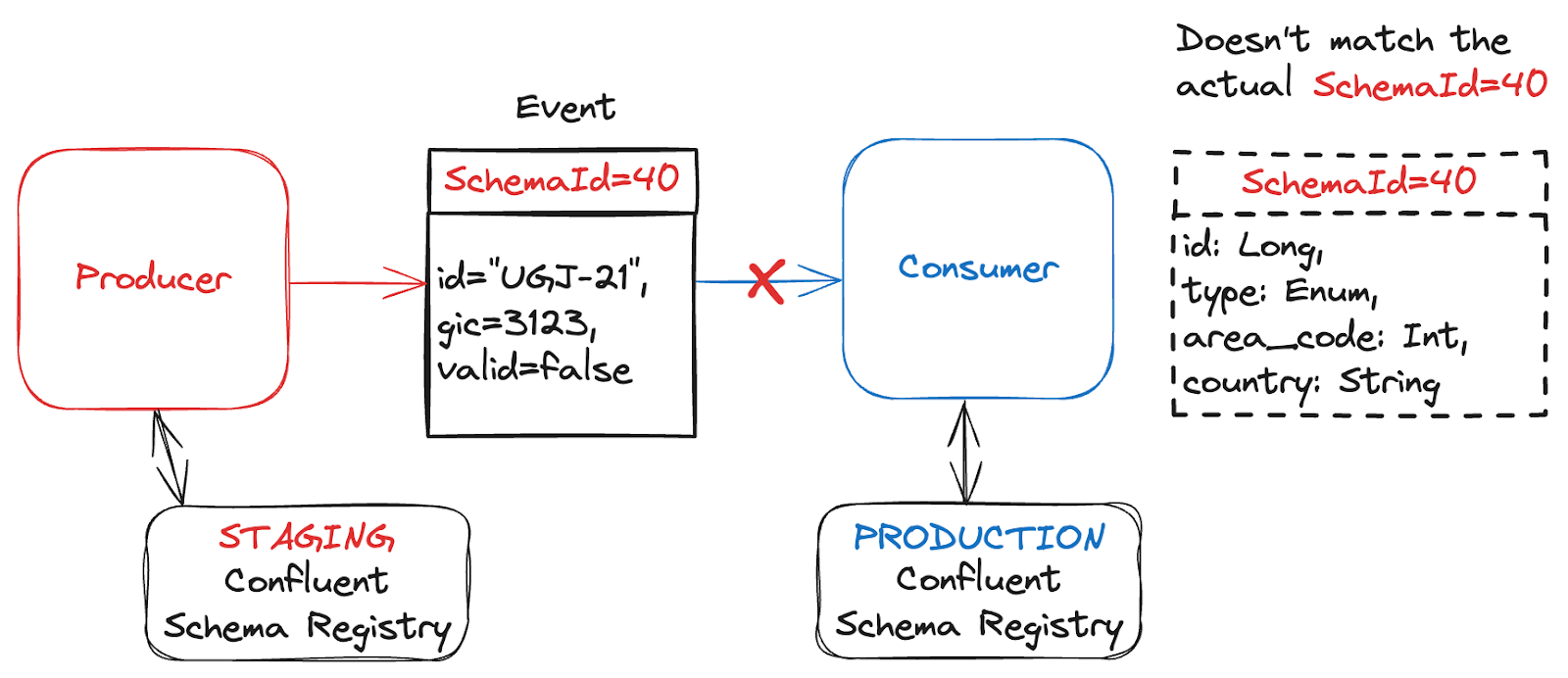
3. Event Has an Invalid Schema
Your event’s purported schema can’t be applied to the data. For example, you’re using the Confluent Schema Registry with Kafka, but your event’s Schema Id doesn’t correspond to a valid schema. It is possible you deleted your schema, or that your serializer has inserted the wrong Schema Id (perhaps for a different schema registry, in a staging or testing environment?).
4. Incompatible Schema Evolution
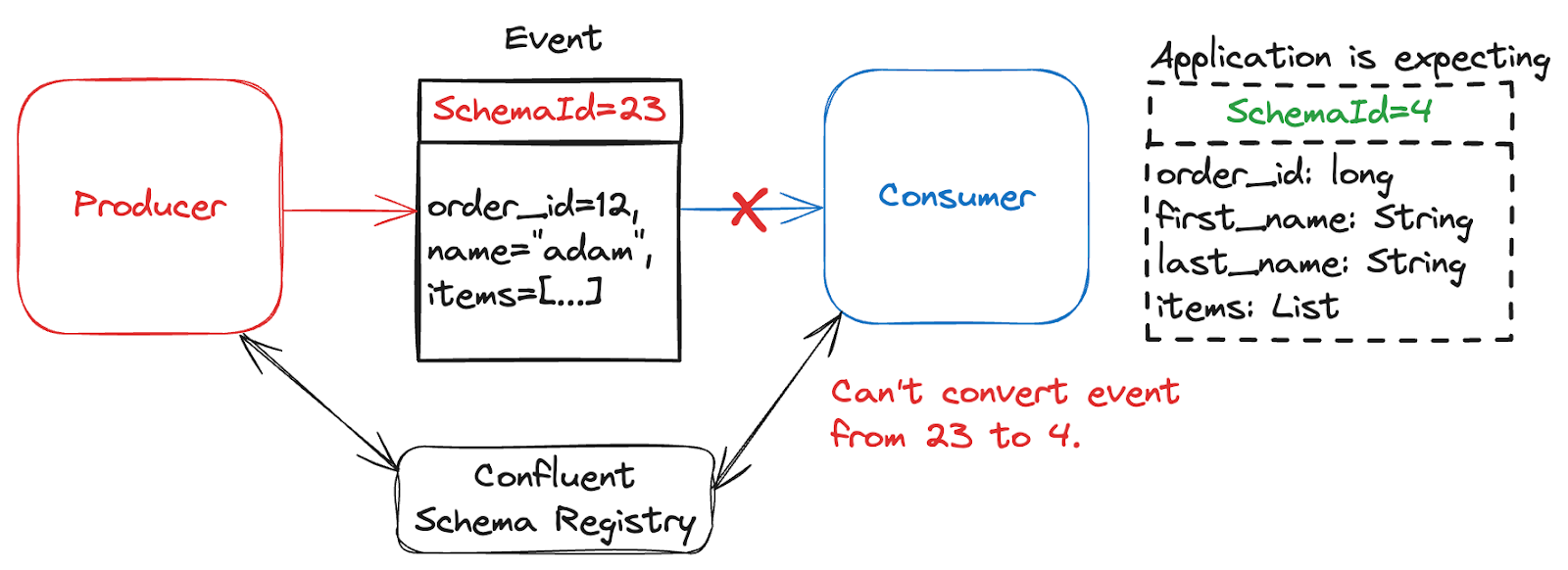
You’re using a schema (hooray!), but the consumer cannot convert the schema into a suitable format. The event is deserializable, but not mappable to the schema that the consumer expects. This is usually because your source has undergone breaking schema evolution (note that evolution rules vary per schema type), but your consumers have not been updated to account for it.
5. Logically Invalid Value in a Field
Your event has a field with a value that should never be. For example, an array of integers for “first_name”, or a null in a field declared as a NPE (see below).
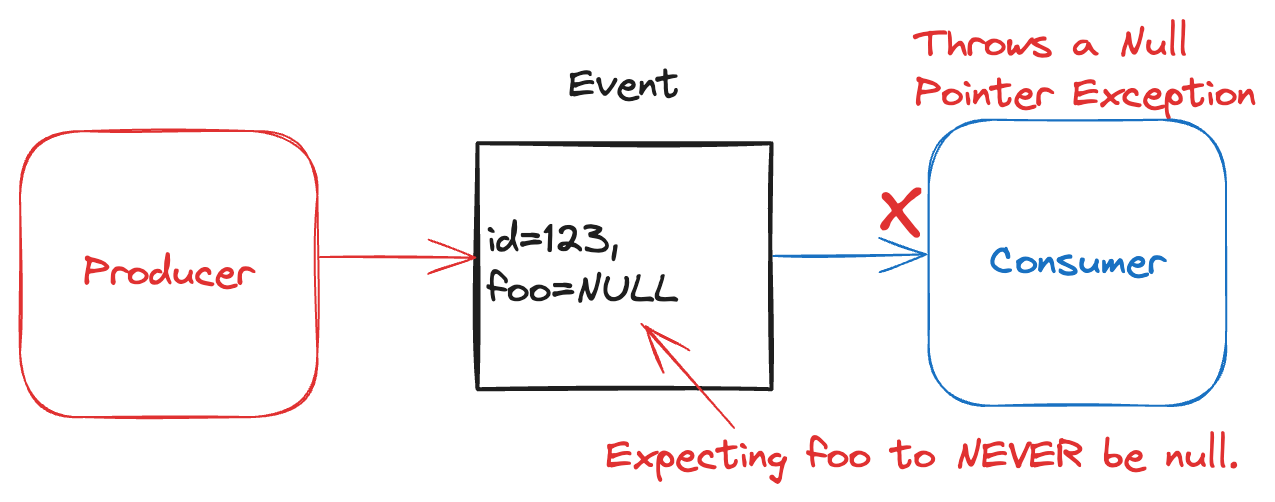
This error type arises when you are not using a well-defined schema, but simply a set of implicit conventions. It can also arise if you are using an invalid, incomplete, old, or homemade library for serialization that ignores parts of your serialization protocol.
6. Logically Valid but Semantically Incorrect
These types of errors are a bit trickier to catch. For example, you may have a serializable string for a “first_name” field (good!), but the name is “Robert’); DROP TABLE Students; — ”.
While little Bobby Tables here is a logically valid answer for a first_name field, it is highly unlikely improbable that this is another one of Elon Musk’s kids. The data in the entry may even be downright damaging.
The following shows an event with a negative “cost”. What is the consumer supposed to do with an order where the cost is negative? This could be a case of a simple bug that slipped through into production, or something more serious. But since it doesn’t meet expectations, it’s bad data.
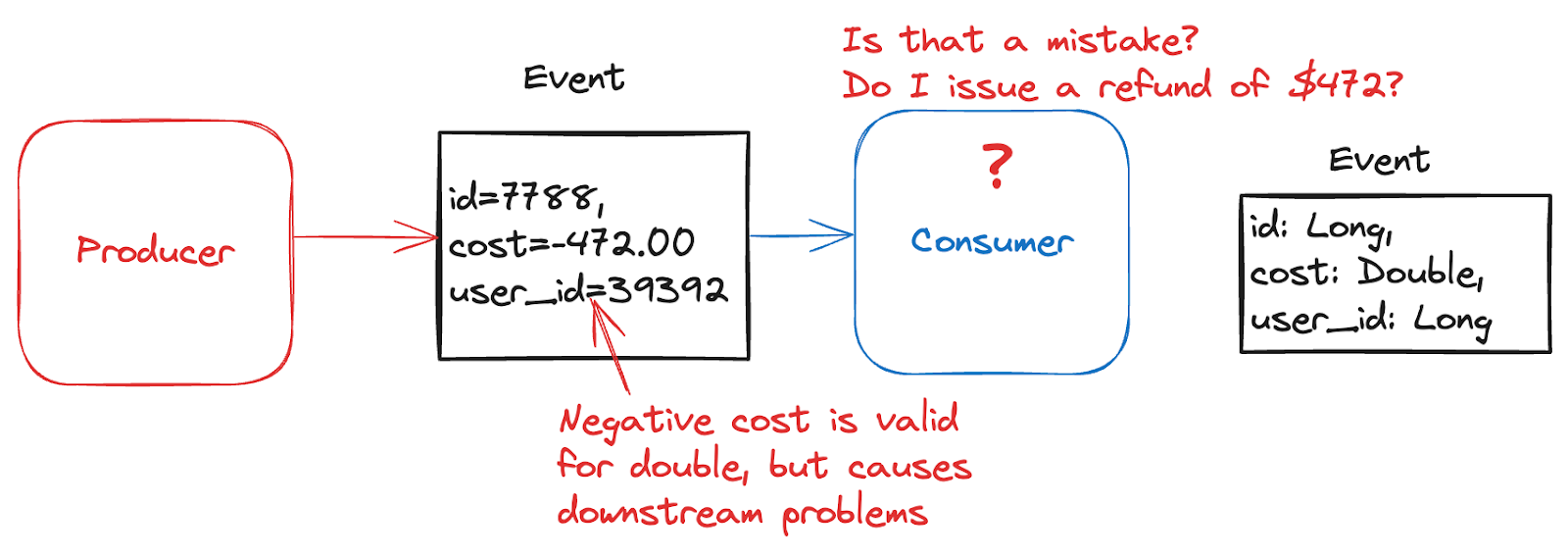
Some event producer systems are more prone to these types of errors. For example, a service that parses and converts NGINX server logs or customer-submitted YAML/XML files of product inventory into individual events. Malformed sources may be partially responsible for these types of errors.
7. Missing Events
This one is pretty easy. No data was produced, but there should have been something. Right?
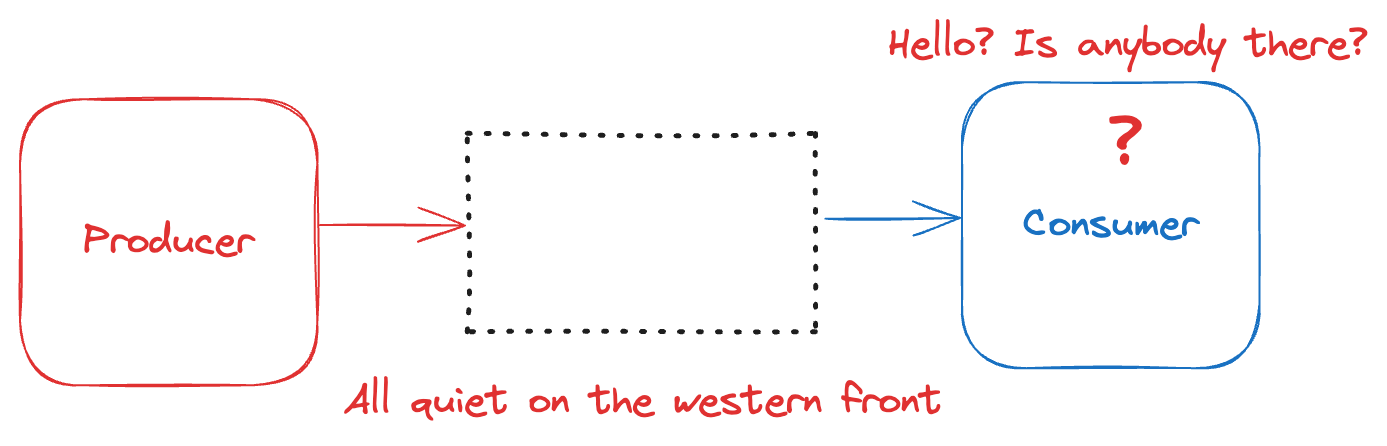
The nice thing about this type of bad data is that it’s fairly easy to prevent via testing. However, it can have quite an impact if only some of the data is missing, making it harder to detect. More on this in a bit.
8. Events That Should Not Have Been Produced
There is no undo button to call back an event once it is published to an event stream. We can fence out one source of duplicates with idempotent production, meaning that intermittent failures and producer retries won’t accidentally create duplicates. However, we cannot fence out duplicates that are logically indistinguishable from other events.
These types of bad events are typically created due to bugs in your producer code. For example, you may have a producer that creates a duplicate of:
- An event that indicates a change or delta (“add 1 to sum”), such that an aggregation of the data leads to an incorrect value.
- An analytics event, such as tracking which advertisements a user clicked on. This will also lead to an overinflation of engagement values.
- An e-commerce order with its own unique order_id (see below). It may cause a duplicate order to be shipped (and billed) to a customer.
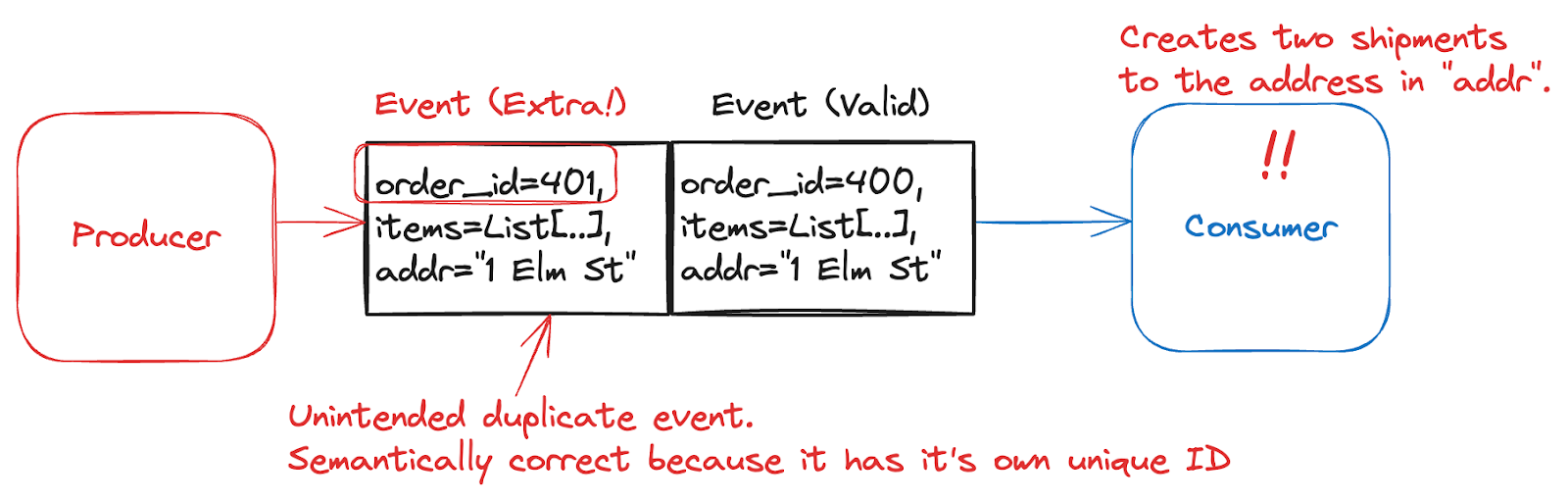
While there are likely more types of bad data in event streams that I may have missed, this should give you a good idea of the types of problems we typically run into. Now let’s look at how we can solve these types of bad data, starting with our first strategy: Prevention.
Preventing Bad Data With Schemas, Validation, and Tests
Preventing the entry of bad data into your system is the number one approach to making your life better. Diet and exercise are great, but there’s no better feeling than watching well-structured data seamlessly propagate through your systems.
First and foremost are schemas. Confluent Schema Registry supports Avro, Protobuf, and JSON Schema. Choose one and use it (I prefer Avro and Protobuf myself). Do yourself, your colleagues, and your future selves a favor. It’s the best investment you’ll ever make.
There are also other schema registries available, though I personally have primarily used the Confluent one over the years (and also, I work at Confluent). But the gist is the same — make it easy to create, test, validate, and evolve your event schemas.
Preventing Bad Data Types 1–5 With Schemas and Schema Evolution
Schemas significantly reduce your error incident rates by preventing your producers from writing bad data, making it far easier for your consumers to focus on using the data instead of making best-effort attempts to parse its meaning. Schemas form a big part of preventing bad data, and it’s far, far, far easier to simply prevent bad data from getting into your streams than it is to try to fix it after the damage has already started.

JSON is a lightweight data-interchange format. It is a common yet poor choice for events, but it doesn’t enforce types, mandatory and optional fields, default values, or schema evolution. While JSON has its uses, it’s not for event-driven architectures. Use an explicitly-defined schema such as Avro, Protobuf, or JSON Schema.
Going schemaless (aka using JSON) is like going around naked in public. Sure, you’re “free” of the constraints, boundaries, and limitations, but at what expense? Everyone else has to figure out what the hell is going on, and chaos (and the police) will follow. But reeling back in the hyperbole, the reality is that your consumers need well-defined data. If you send data with a weak or loose schema, it just puts the onus on the consumer to try to figure out what you actually mean.
Let’s say we have 2 topics with no schemas and 4 consumers consuming them.
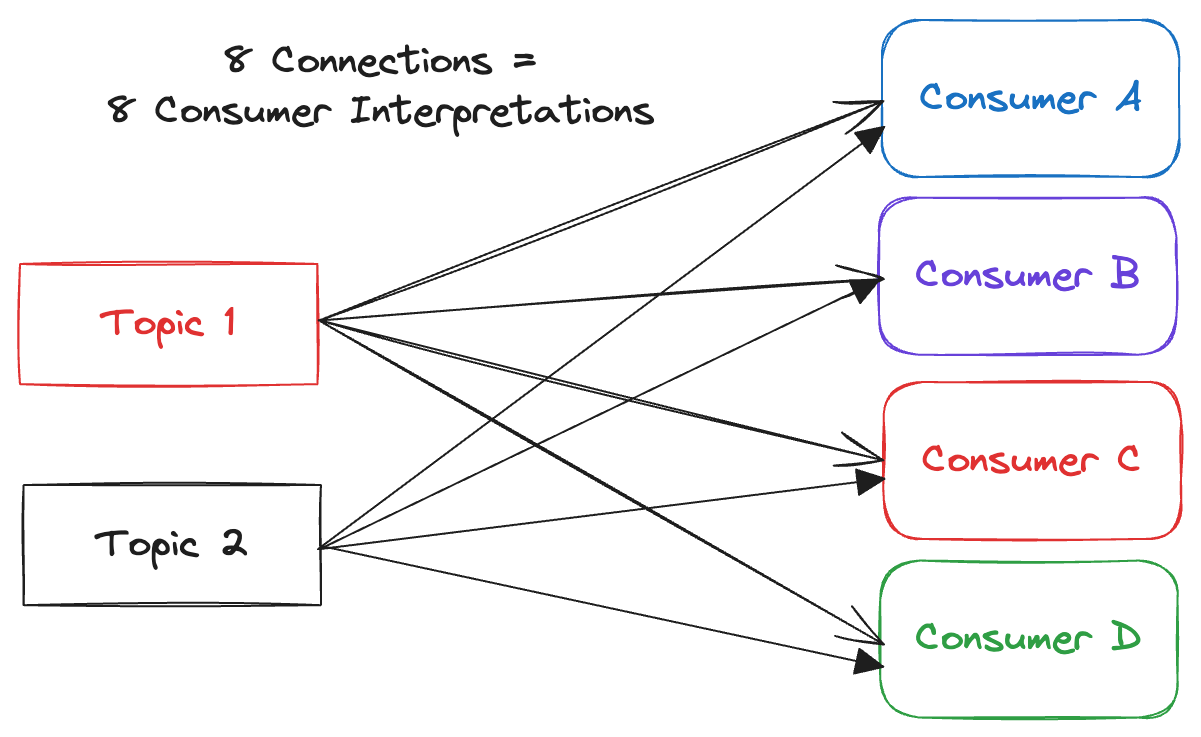 So many chances to screw up the data interpretation!
So many chances to screw up the data interpretation!There are 8 possible chances that a consumer will misinterpret the data from an event stream. And the more consumers and topics you have, the greater the chance they misinterpret data compared to their peers. Not only will your consumers get loud, world-stopping exceptions, but they may also get silent errors — miscalculating sums and misattributing results, leading to undetected divergence of consumer results. These discrepancies regularly pop up in data engineering, such as when one team’s engagement report doesn’t match the other team’s billing report due to divergent interpretations of unstructured data.
It’s worth contrasting this multi-topic, multi-consumer approach with the typical ETL/ELT pipeline into the data plane. In this streaming model, we’re not differentiating who uses the data for what purposes. A consumer is a consumer. In contrast, with ETLs, we’re typically moving data into one major destination, the data lake (or warehouse), so it’s a lot easier to apply a schema to the data after it lands but before any dependent jobs consume it. With streaming, once it’s in the stream, it’s locked in.
Implicit schemas, historical conventions, and tribal knowledge are unsuitable for providing data integrity. Use a schema, make it strict, and reduce your consumer's exposure to unintentional data issues. Once adopted, you can rely on your CI/CD pipelines to perform schema, data, and evolution validation before deploying. The result? No more spewing bad data into your production streams.
Data Quality Rules: Handling Type 6: (Logically Valid but Semantically Incorrect)
While many of the “bad data” problems can be avoided by using schemas, they are only a partial solution for this type. Sure, we can enforce the correct type (so no more storing Strings in Integer fields), but we can’t guarantee the specific semantics of the data. So what can we do, aside from using a schema?
- Producer unit tests.
- Throw Exceptions if malformed (eg: If the phone number is longer than X digits)
- Rely on Data Contracts and Data Quality Rules (note: JSON Schema also has some built-in data quality rules)
Here’s an example of a Confluent data quality rule for a US Social Security Number (SSN).
{
"schema": "…",
"ruleSet": {
"domainRules": [
{
"name": "checkSsnLen",
"kind": "CONDITION",
"type": "CEL",
"mode": "WRITE",
"expr": "size(message.ssn) == 9"
}
]
}
}This rule enforces an exact length of 9 characters for the SSN. If it’s an Integer, we could also enforce that it must be positive, and if it is a string it must only contain numeric characters.
The data quality checks are applied when the producer attempts to serialize data into a Kafka record. If the message.ssn field is not exactly 9 characters in length, then the serializer will throw an exception. Alternatively, you can also send the record to a dead-letter queue (DLQ) upon failure.
Approach DLQ usage with caution. Simply shunting the data into a side stream means that you’ll still have to deal with it later, typically by repairing it and resending it. DLQs work best where each event is completely independent with no relation to any other event in the stream and ordering is not important. Otherwise, you run the risk of presenting an error-free yet incomplete stream of data, which can also lead to its own set of miscalculations and errors!
Don’t get me wrong. DLQs are a good choice in many scenarios, but they should truly be a last-ditch effort at preventing bad data from getting into a stream. Try to ensure that you test, trial, and foolproof your producer logic to publish your record to Kafka correctly the first time.
Testing — Handling Types 7 (Missing Data) and 8 (Data That Shouldn’t Have Been Produced)
Third in our trio of prevention heroes is testing. Write unit and integration tests that exercise your serializers and deserializes, including schema formats (validate against your production schema registry), data validation rules, and the business logic that powers your applications. Integrate producer testing with your CI/CD pipeline so that your applications go through a rigorous evaluation before they’re deployed to production.
Both Type 7: Missing Data and Type 8: Data that shouldn’t have been produced are actually pretty easy to test against. One of the beautiful things about event-driven systems is that it’s so easy to test them. For integration purposes, you simply produce events on the inputs, wait to see what comes out of the outputs, and evaluate accordingly. Once you find the bug in your logic, write another test to ensure that you don’t get a regression.
Summary
Bad data can creep into your data sets in a variety of ways.
Data at rest consists of partitioned files typically backed by a Parquet or ORC format. The data is both created and read by periodically executed batch processes. The files are mutable, which means that bad data can be fixed in place and overwritten, or it can be deleted and regenerated by the upstream batch job.
Kafka topics, in contrast, are immutable. Once a bad event is written into the event stream, it cannot be surgically removed, altered, or overwritten. Immutability is not a bug but a feature — every consumer gets the same auditable data. But this feature requires you to be careful and deliberate about creating your data.
Good data practices prevent you from getting into trouble in the first place. Write tests, use schemas, use data contracts, and follow schema evolution rules. After your initial investment, you and your colleagues will save so much time, effort, and break-fix work that you’ll actually have time to do some of the fun stuff with data — like getting actual work done.

Prevention is the single most effective strategy for dealing with bad data. Much like most things in life, an ounce of prevention is worth a pound of cure (or 28.3g of prevention and 454g of cure for those of us on the metric system).
In the next post, we’ll take a look at leveraging event design as part of handling bad data in event streams. There are many ways you can design your events, and we’ll look at a few of the most popular ways and their tradeoffs. Don’t touch that dial, we’ll be right back (yes, TVs used to have dials, and needed time to warm up).
Published at DZone with permission of Adam Bellemare. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments