How to Design Event Streams, Part 2
This article covers the degree of normalization when using events created from a relational source, and how to go about denormalizing them.
Join the DZone community and get the full member experience.
Join For FreeIn Part 1, we covered several key topics. I recommend you read it, as this next part builds on it.
As a quick review, in part 1, we considered our data from the grand perspective and differentiated between data on the inside and data on the outside. We also discussed schemas and data contracts and how they provide the means to negotiate, change, and evolve our streams over time. Finally, we covered Fact (State) and Delta event types. Fact events are best for communicating state and decoupling systems, while Delta events tend to be used more for data on the inside, such as in event sourcing and other tightly coupled use cases.
Normalized Tables Make Normalized Streams
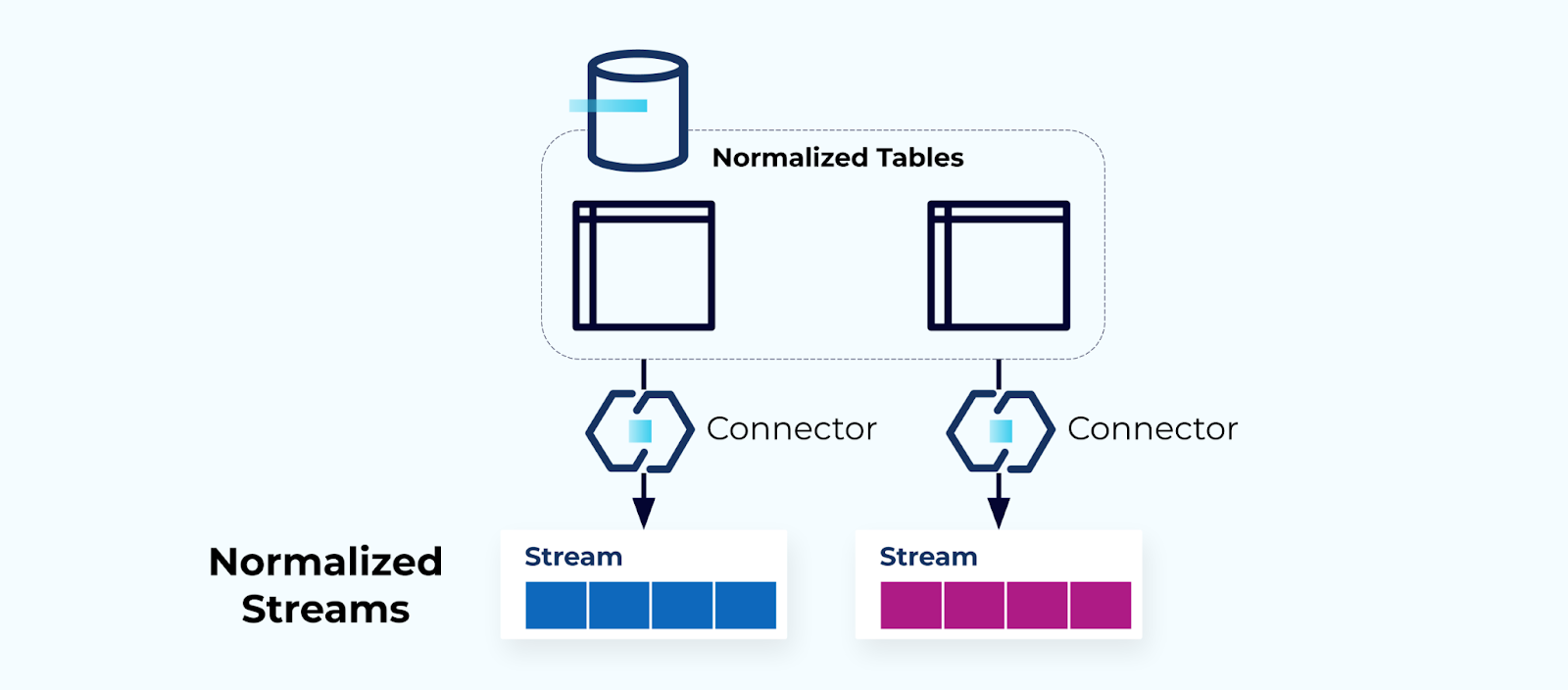
Normalized tables lead to normalized event streams. Connectors (e.g., CDC) pull data directly from the database into a mirrored set of event streams. This is not ideal, as it creates a strong coupling between the internal database tables and the external event streams.
Consider a simple e-commerce Item and its associated Brand and Tax Status tables.
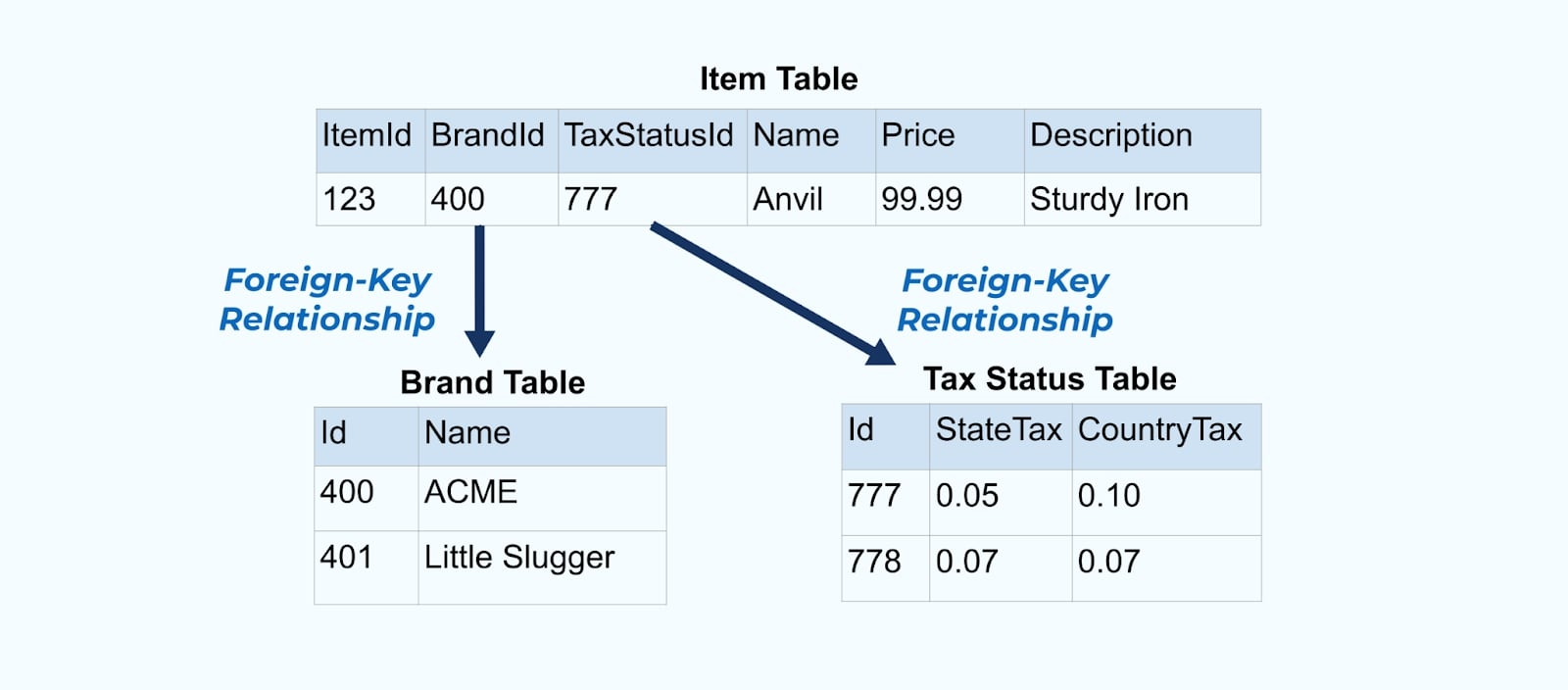
The Brand and Tax Status tables relate to the Item table through foreign-key relationships. While we only show one item in the table, you will likely have thousands (or millions), depending on the products you sell.
It is common to set up a connector for each table, pull the data out of the table, compose it into events, and write each table to a dedicated event stream.
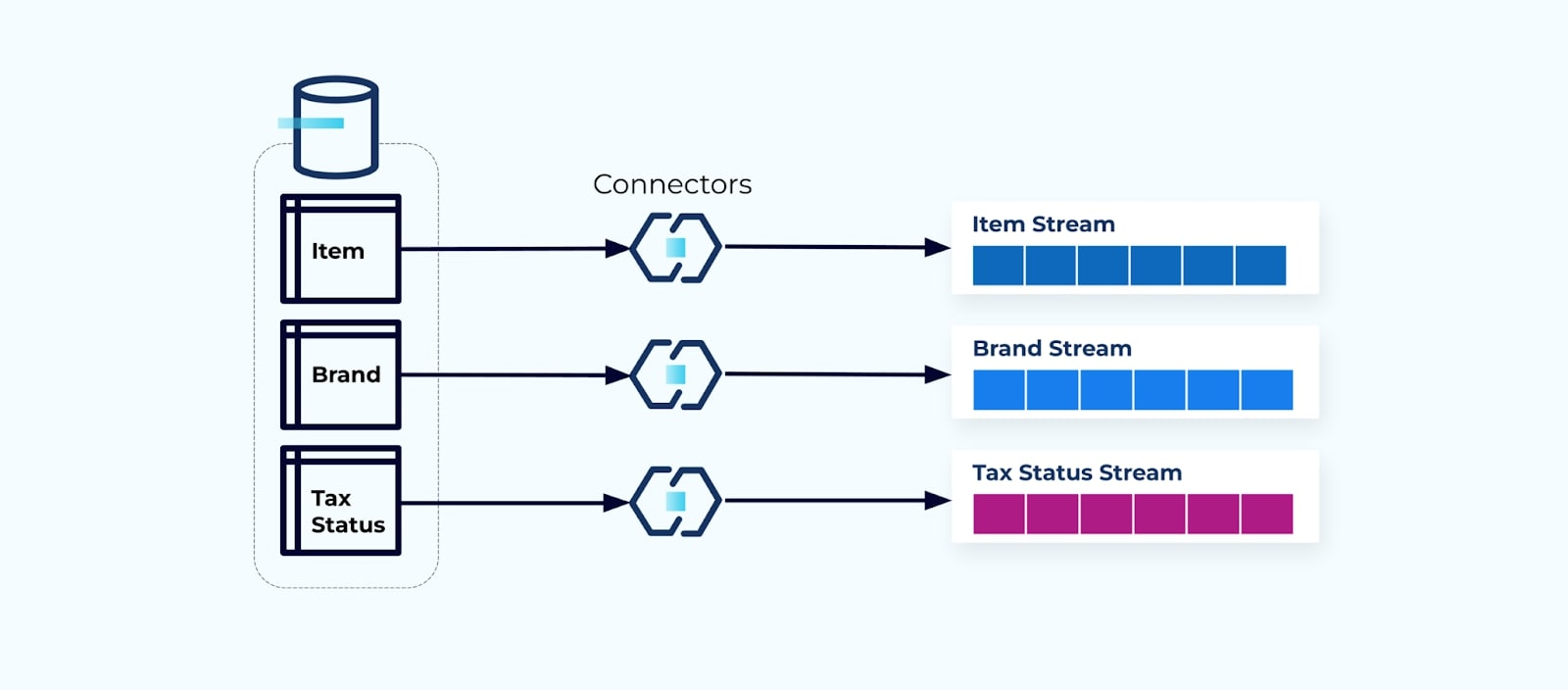
Exposing the underlying tables in the database leads to a corresponding event stream per table. While it is easy to get started this way, it leads to multiple problems, which can be summed up as either a coupling problem or a cost problem. Let’s look at each.
Problem: Consumers Couple on the Internal Model
Exposing the source Item table as-is forces consumers to couple on it directly. Changes to the source system’s data model will impact downstream consumers.
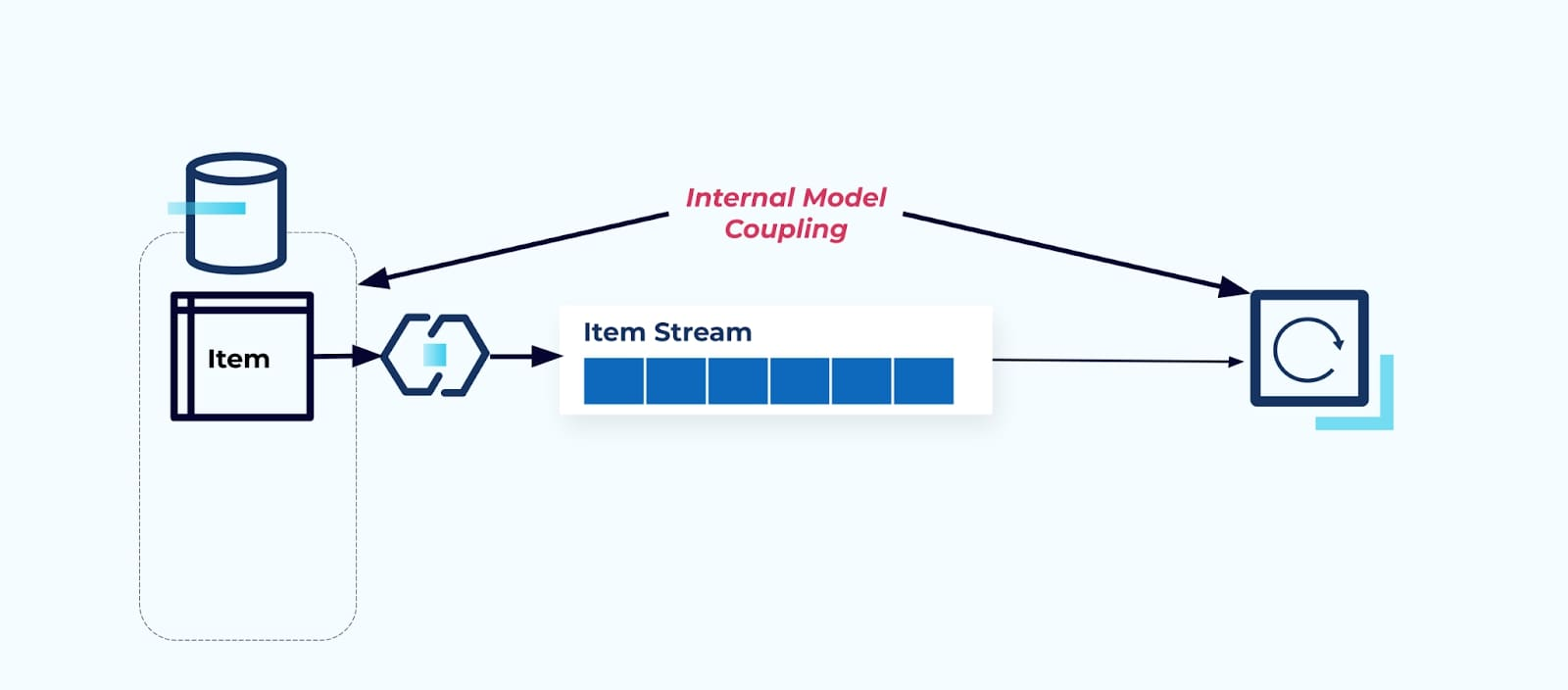
Say we refactor the Item table to extract Pricing into its own table.
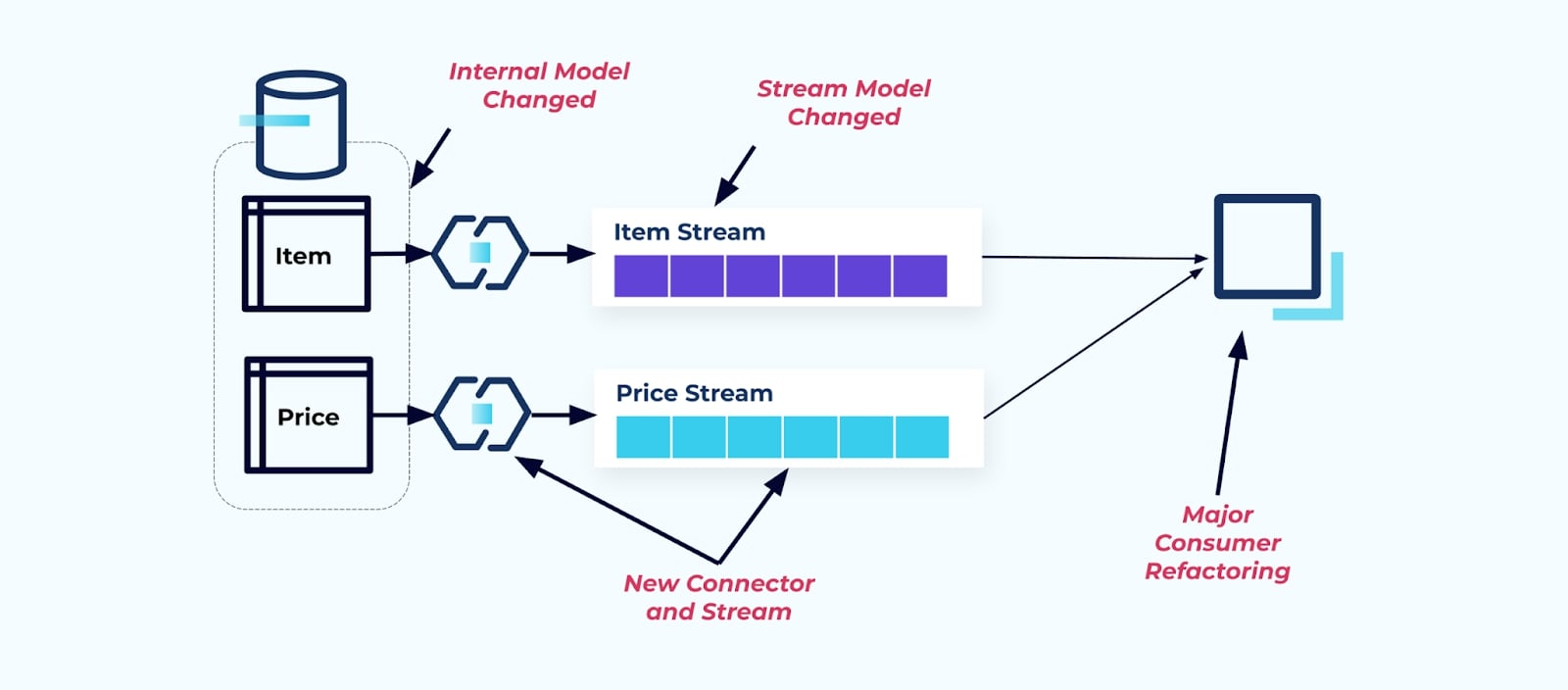
Refactoring the source tables results in a broken data contract for the item stream. The consumer is no longer provided the same item data they originally expected. We must also create a new connector — a new Price stream — and, finally, refactor our consumer logic to get it running again. Renaming columns, changing default values, and changing column types are other forms of breaking changes introduced by tight coupling on the internal data model.
Problem: Streaming Joins Are (Usually) Expensive
Relational databases are purpose-built to quickly and cheaply resolve joins. Streaming joins, unfortunately, are not.
Consider two services that want access to an Item, its Tax, and its Brand info. If the data is already written to its corresponding stream, then each consumer (on the right in the image below) will have to compute the same joins to denormalize Item, Brand, and Tax.
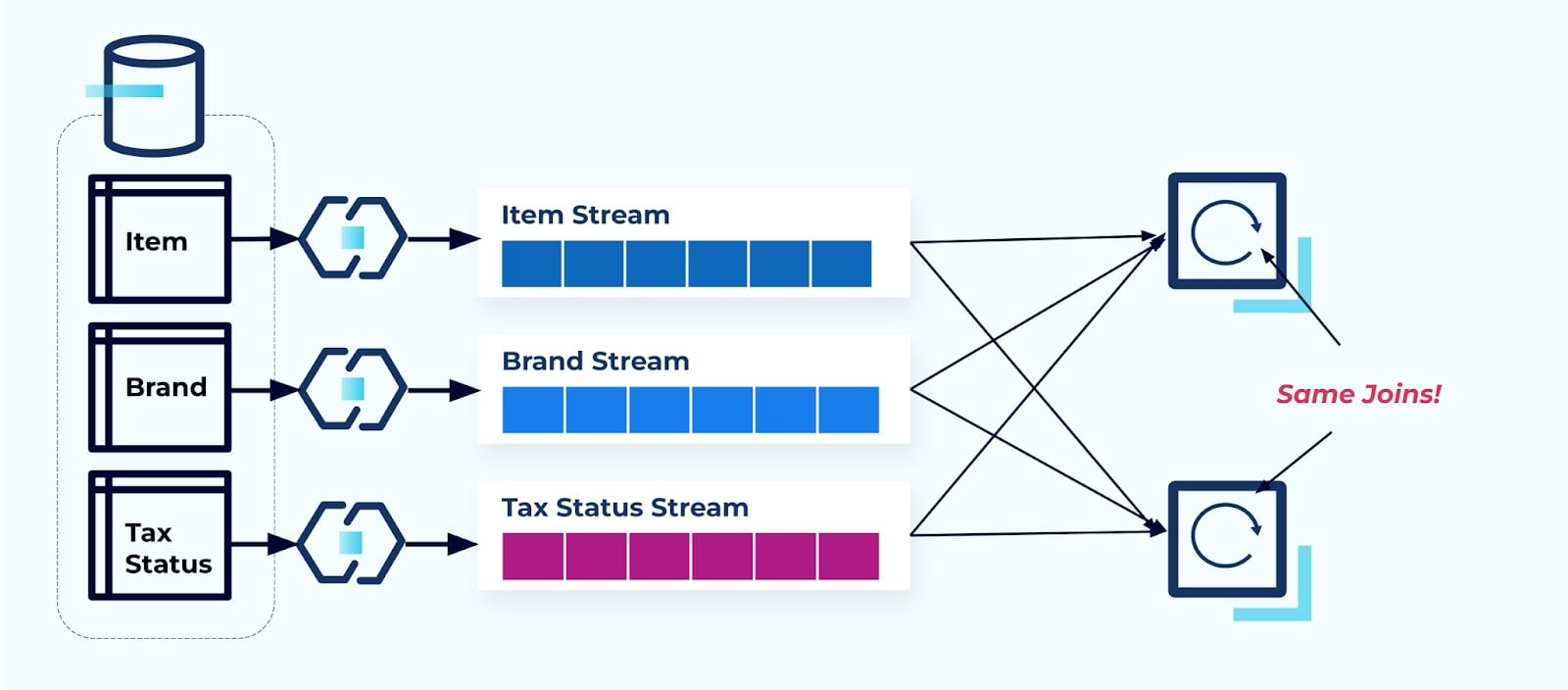
This strategy can incur high costs, both in dev-hours for writing the applications and in server costs for computing the joins. Resolving streaming joins at scale can result in a lot of shuffling of data, which incurs processing power, networking, and storage costs. Furthermore, not all stream processing frameworks support joins, especially on foreign keys. Of those that do, such as Flink, Spark, KSQL, or Kafka Streams (for example), you’ll find yourself limited to a subset of programming languages (Java, Scala, Python).
Solution: Serving Denormalized Data Is Best
As a principle, make event streams easy for your consumers to use. Denormalize the data before making it available to consumers using an abstraction layer and create an explicit external model data contract (data on the outside) for consumers to couple on.
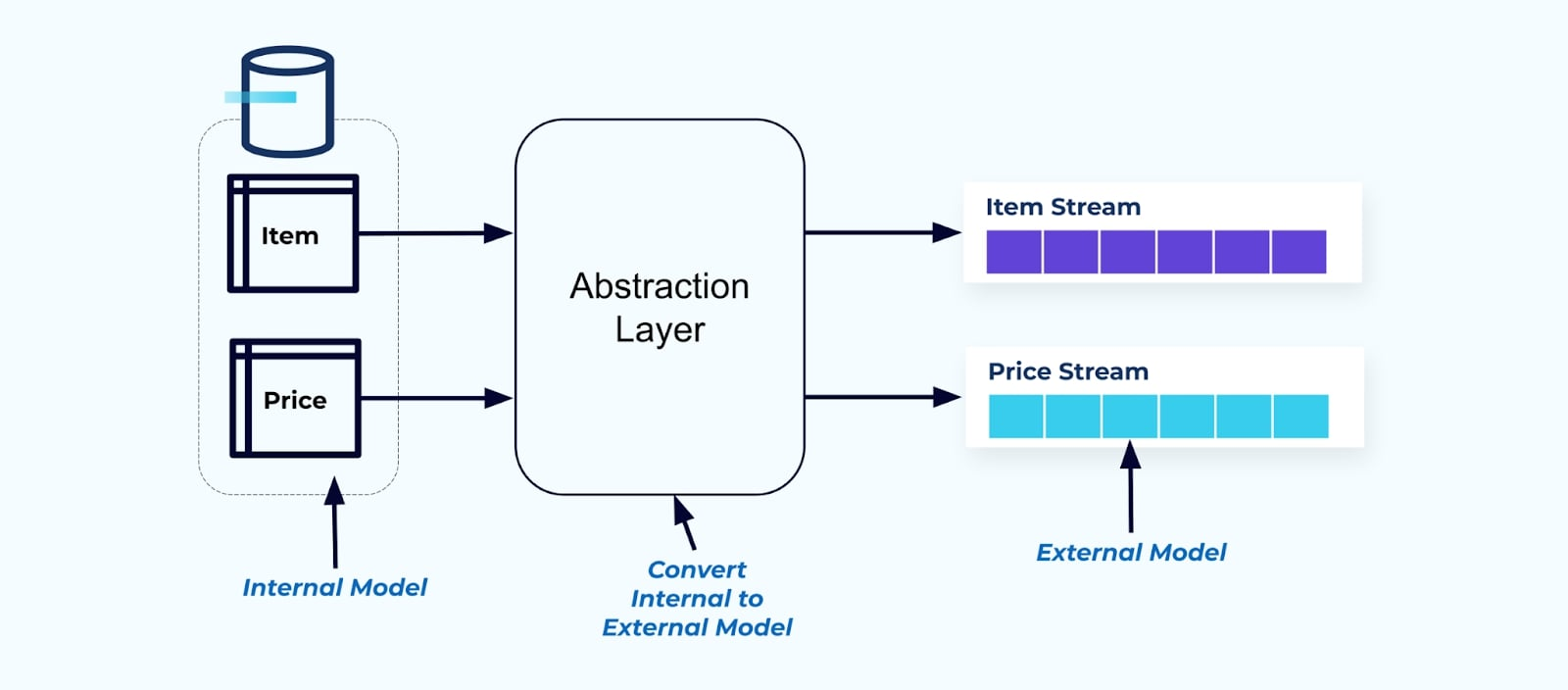
Changes to the internal model remain isolated in the source systems. Consumers get a well-defined data contract for coupling on. Changes made to the source model can go ahead unimpeded, as long as they source system maintains the data contract for the consumers.
But where do we denormalize? Two options:
- Reconstruct outside of the source system via a purpose-built joiner service.
- During event creation in the source system using the Transactional Outbox pattern.
Let’s take a look at each solution in turn.
Option 1: Denormalize Using a Purpose-Built Joiner Service
In this example, the streams on the left mirror the tables they came from in the database.
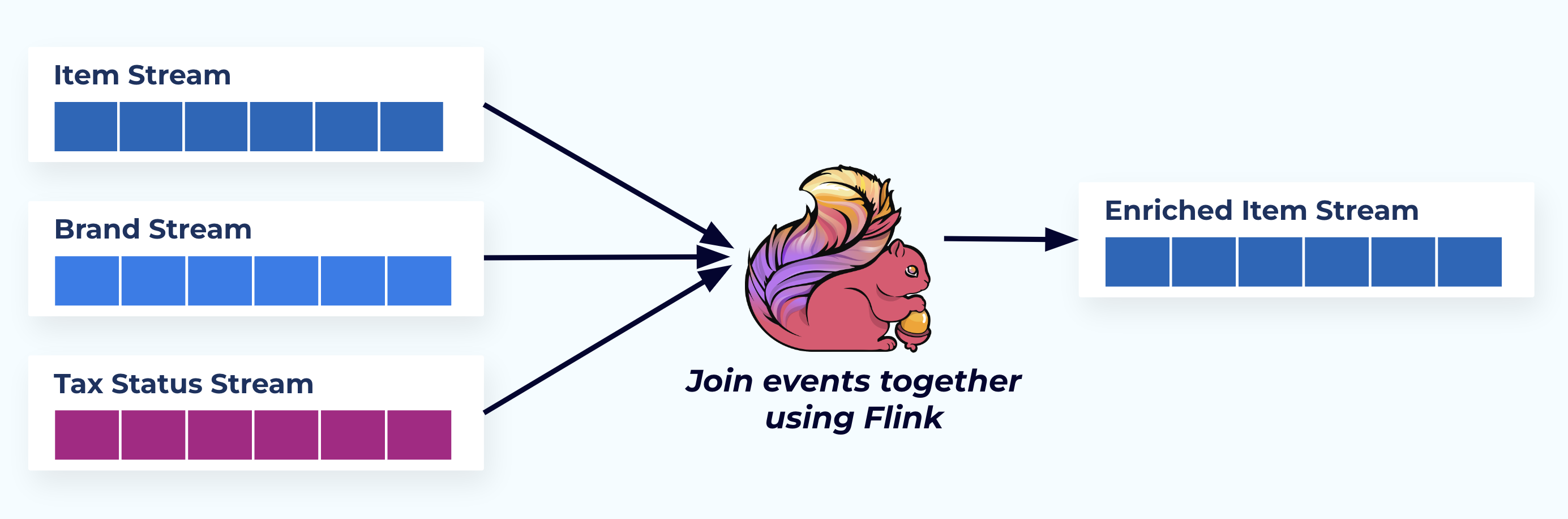
We join the events using a purpose-built application (or streaming SQL query) based on the foreign-key relationships and emit a single enriched item stream.

Logically, we’re resolving the relationships and squashing the data down into a single denormalized row.
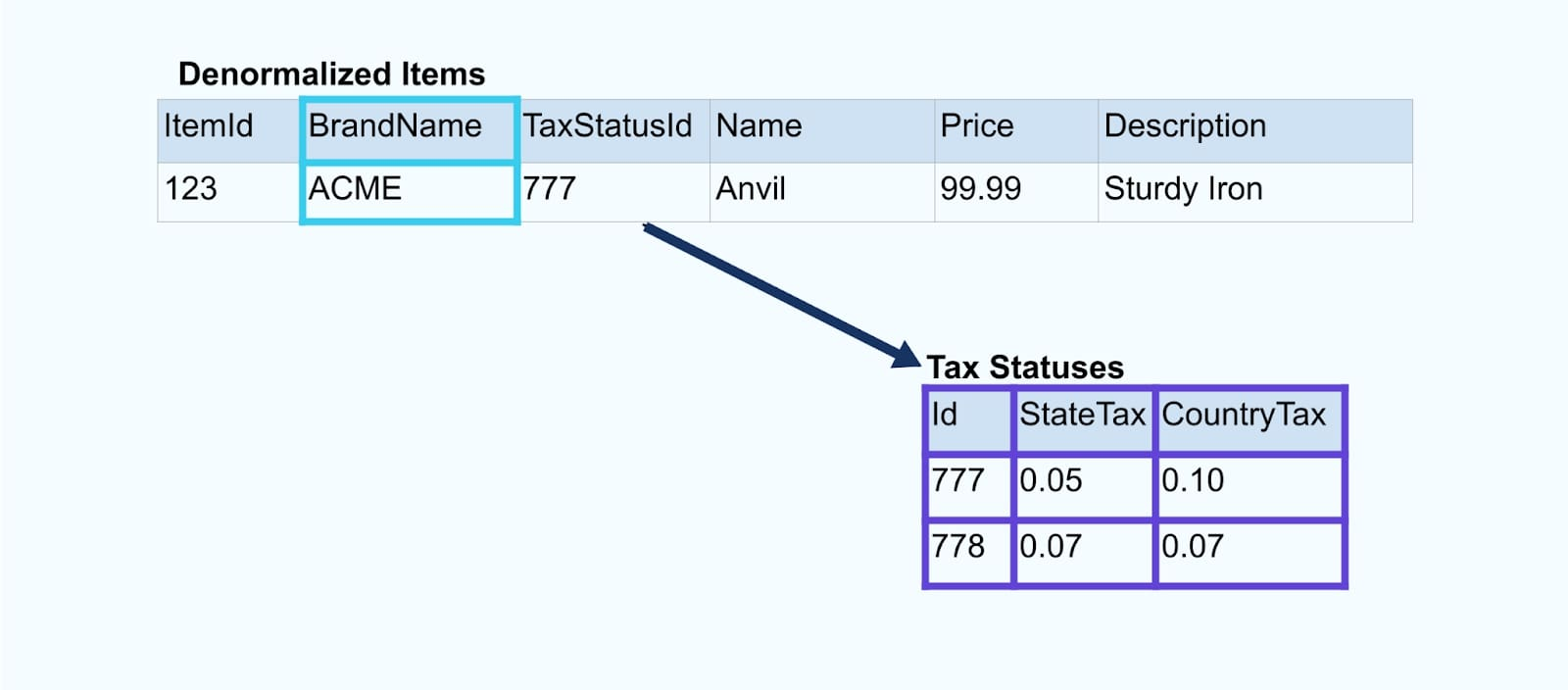
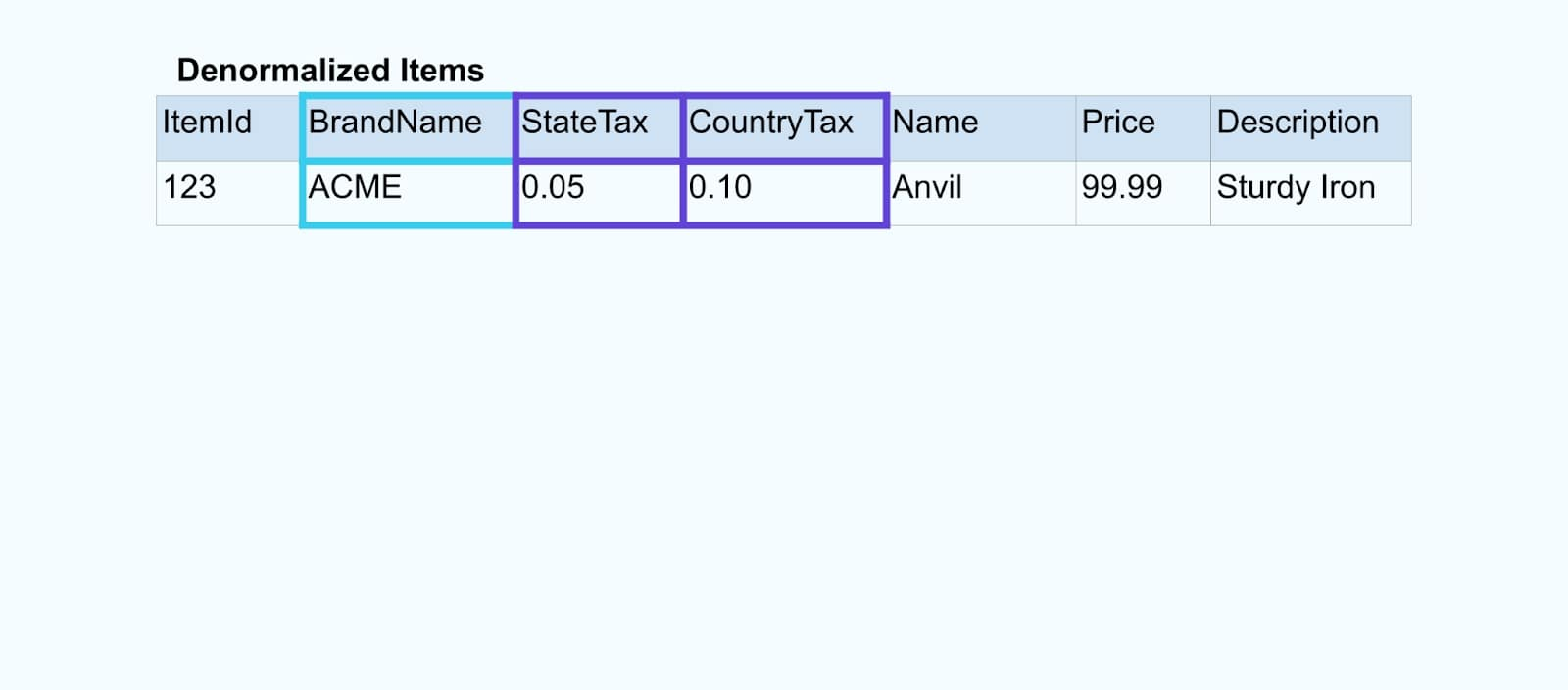
Purpose-built joiners rely on stream processing frameworks like Apache Kafka Streams and Apache Flink to resolve both primary and foreign key joins. They materialize the stream data into durable internal table formats, enabling the joiner application to join events across any period - not just those bound by a time-limited window.
Joiners using Flink or Kafka Streams are also remarkably scalable — they can scale up and down with load and handle massive volumes of traffic.
A tip: Do not put any business logic into the joiner. To be successful in this pattern, the joined data must accurately represent the source, simply as a denormalized result. Let the consumers downstream apply their own business logic, using the denormalized data as a single source of truth.
If you don’t want to use a downstream joiner, there are other options. Let’s take a look at the transactional outbox pattern next.
Option 2: Transactional Outbox Pattern
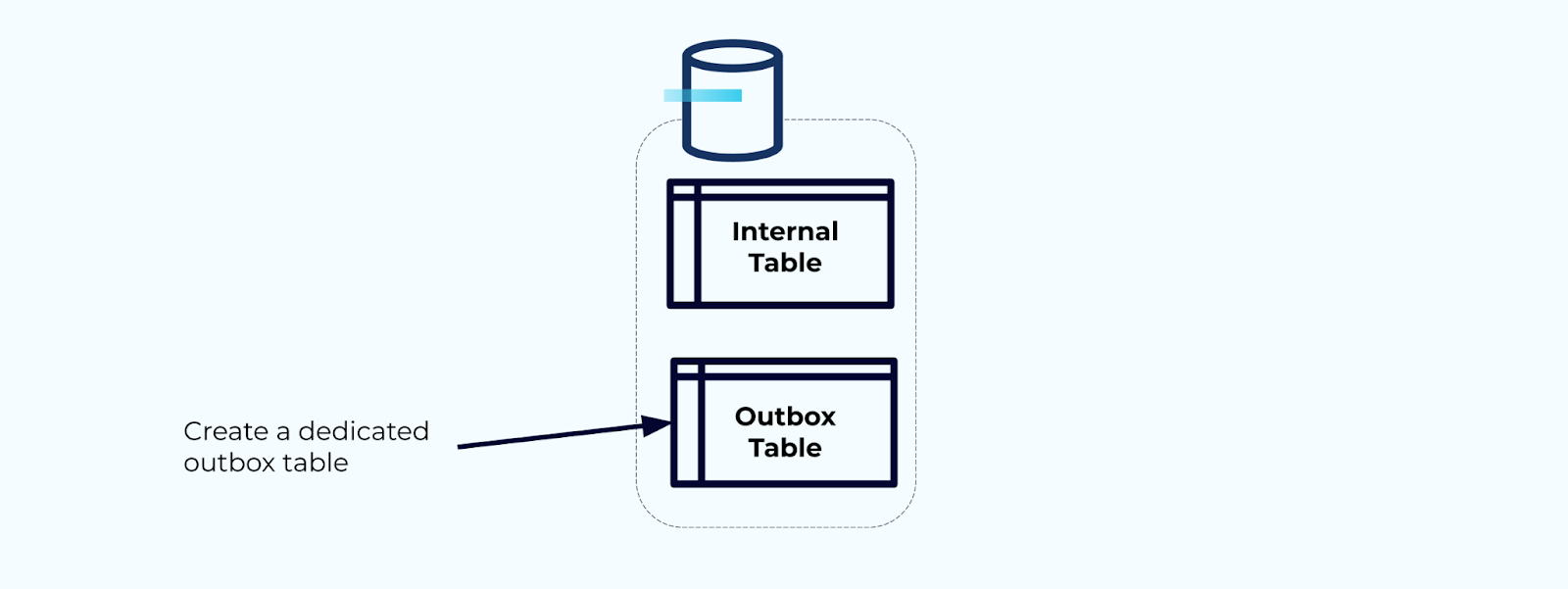
First, create a dedicated outbox table for writing events to the stream.
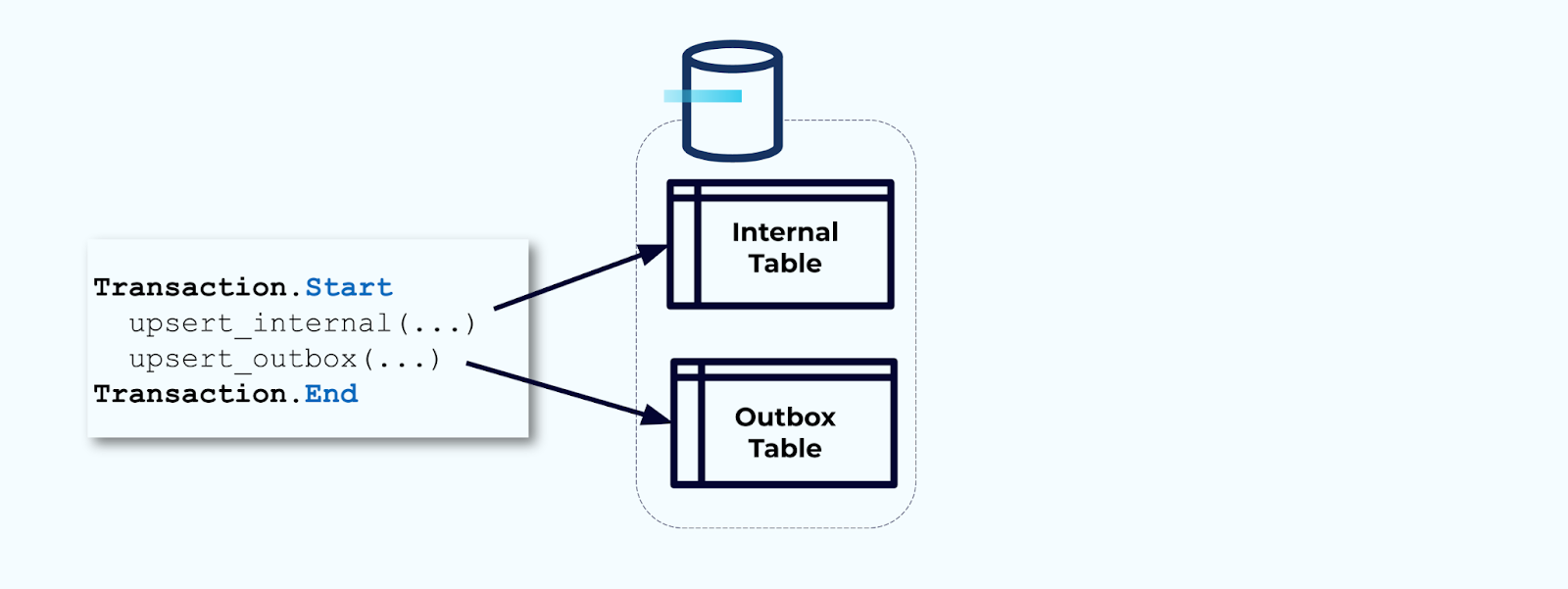
Second, wrap all necessary internal table updates inside of a transaction. Transactions guarantee that any updates made to the internal table will also be written to the outbox table.
The outbox allows you to isolate the internal data model since you can join and transform the data before writing it to your outbox. The outbox acts as the abstraction layer between your data on the inside and data on the outside, acting as a data contract for your consumers.
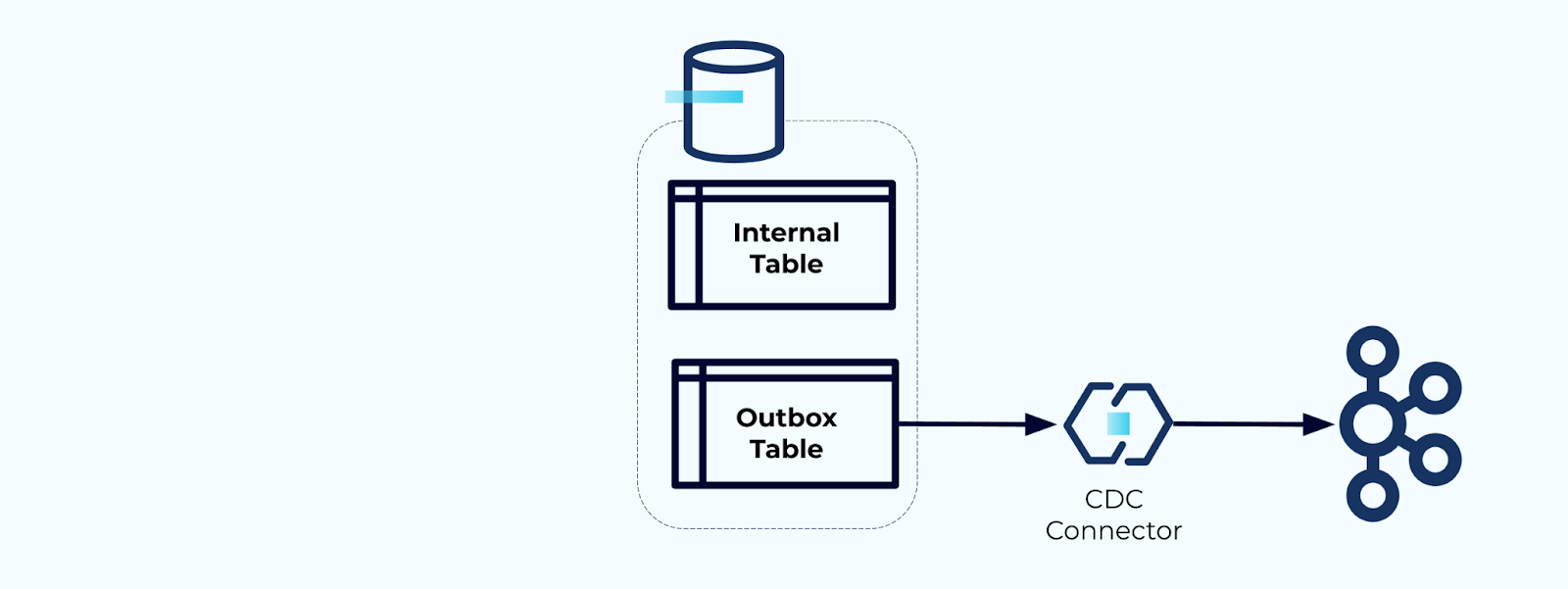
Finally, you can use a connector to get the data out of the outbox and into Kafka.
You must ensure that the outbox doesn’t grow indefinitely — either delete the data after it is captured by the CDC or periodically with a scheduled job.
Example: Denormalizing User Behavior Tracking Events
Tracking user behavior on your web pages and applications is a common source of normalized events - think Google Analytics or first-party in-house options. But we don’t include all of the information in the event; instead, we limit it to identifiers (faster, smaller, cheaper), denormalizing after the facts are created.
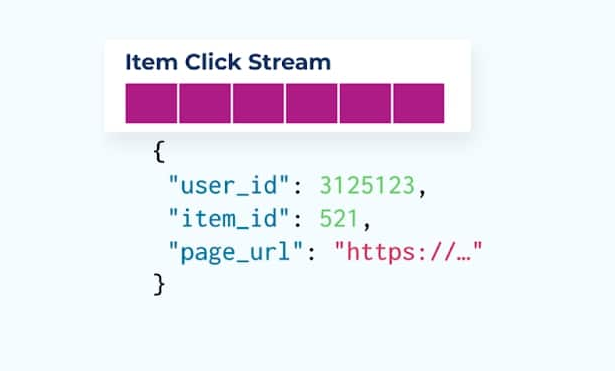
Consider a stream of item click events detailing when a user has clicked on an item while browsing e-commerce items. Note that this item click event doesn’t contain richer item information such as name, price, and description, just basic ids.
The first thing many click-stream consumers do is join it with the item fact stream. And since you’re dealing with many click events, you discover that it ends up using a large amount of computing resources. A purpose-built Flink application can join the item clicks with the detailed item data and emit them to an enriched item click stream.
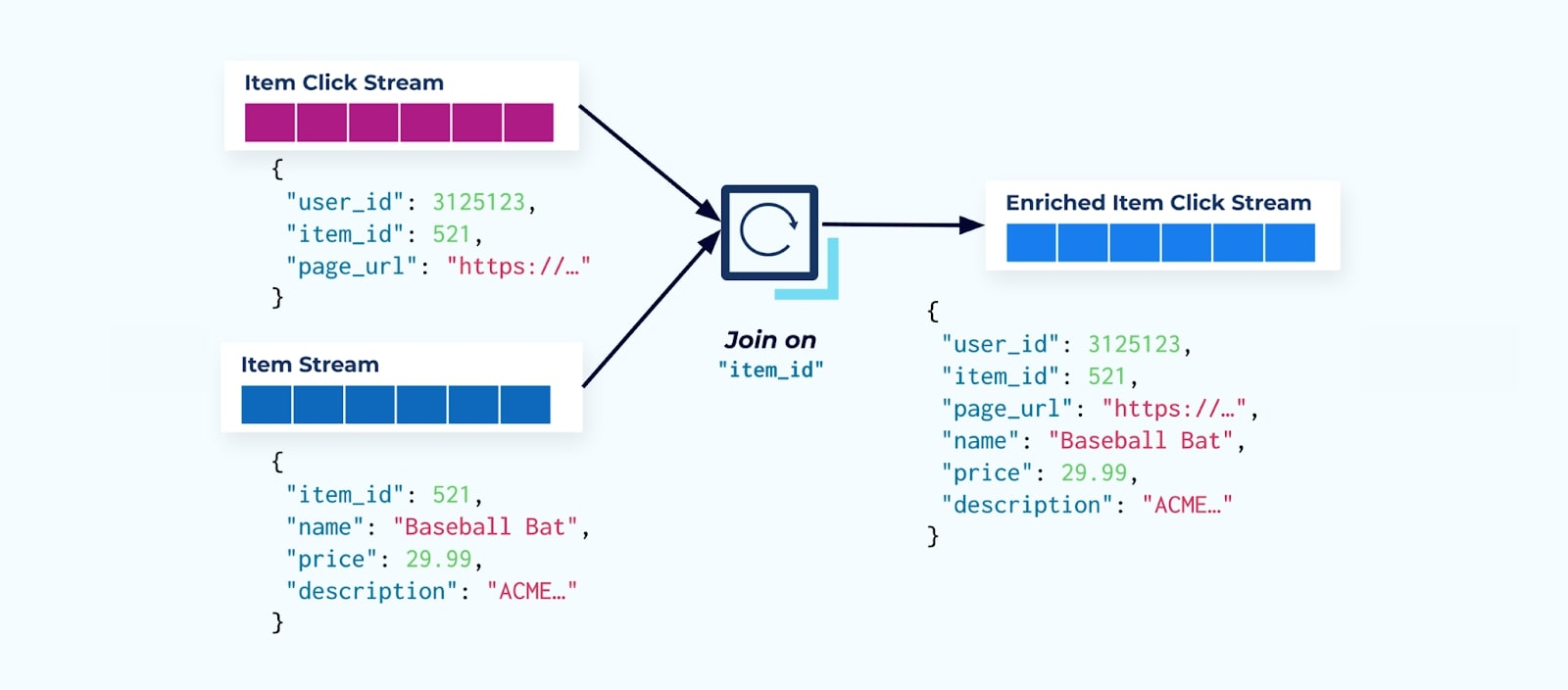
Larger companies with multiple divisions (and systems) will likely see their data come from different sources, and joining after the fact using a stream joiner is the most probable outcome.
Considerations on Slowly-Changing Dimensions
We’ve already discussed the performance considerations of writing events containing large data sets (e.g., large text blobs) and data domains that change frequently (e.g., item inventory). Now, we’ll look at slowly changing dimensions (SCDs), often indicated via a foreign-key relationship, as these can be another source of significant data volumes.
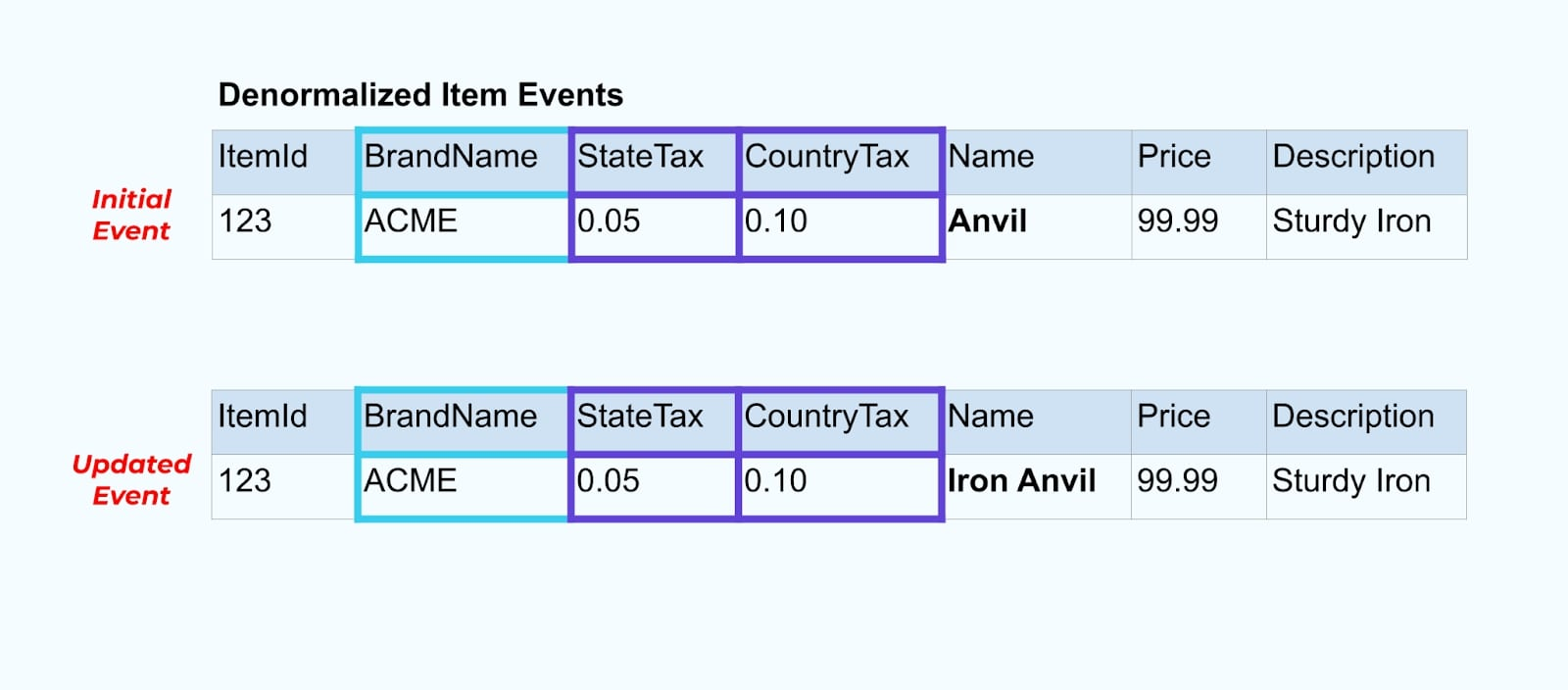
Let’s go back to our item example again. Say you have an operation that updates the Item Table. We’re going to rename the item from Anvil to Iron Anvil.
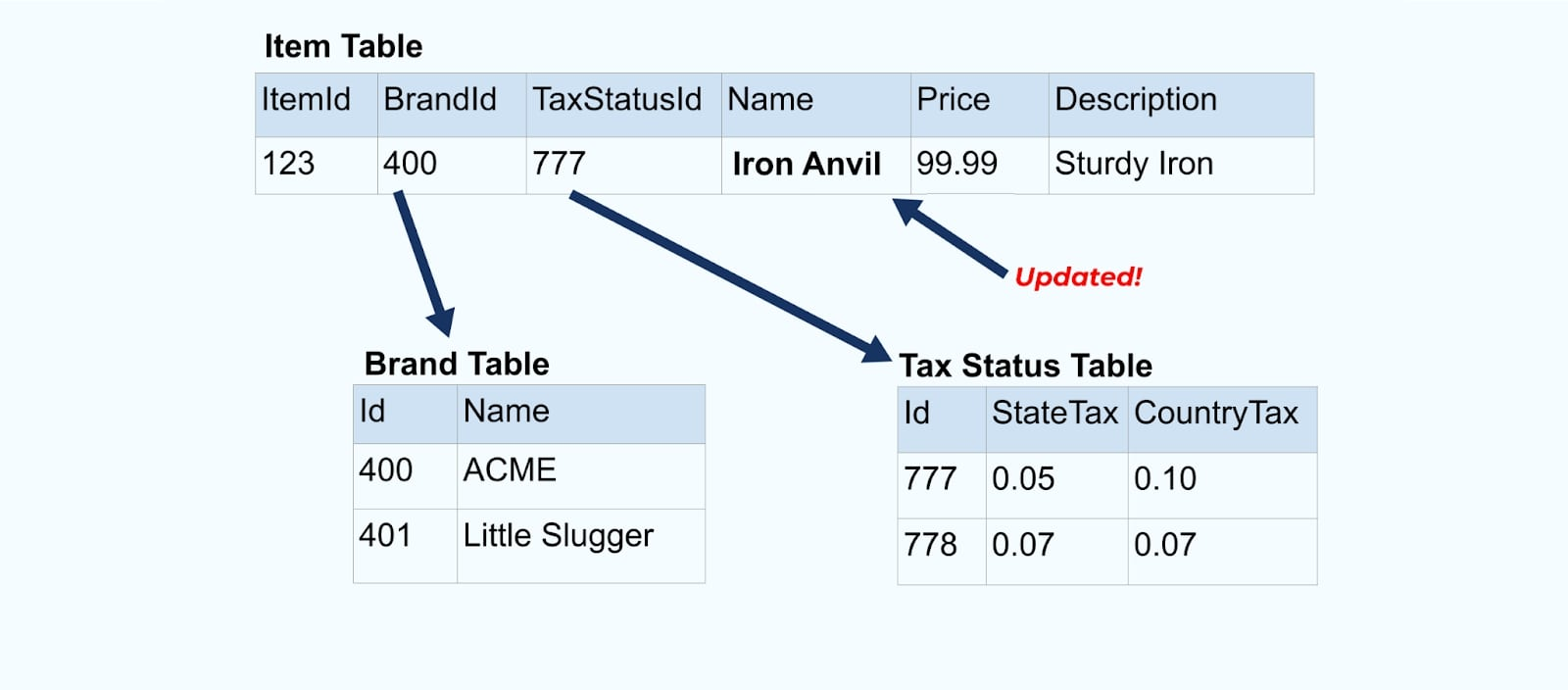
Upon updating the data in the database, we also emit the updated item (say via the outbox pattern), complete with the denormalized tax status and brand table.
However, we also need to consider what happens when we change values in the brand or tax tables. Updating one of these slowly changing dimensions can result in a significantly large number of updates for all the affected items.
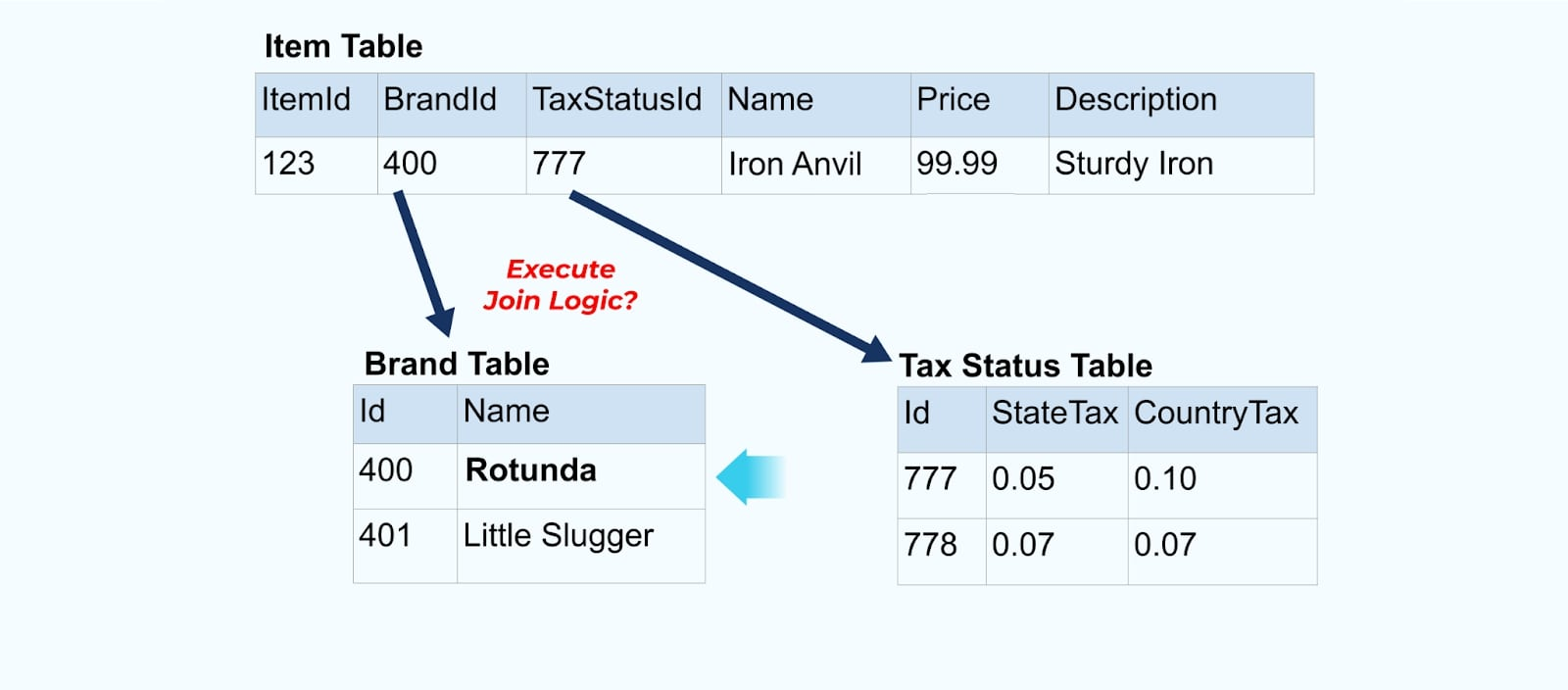
For example, the ACME company undergoes a rebranding and comes up with a new brand name, changing from ACME to Rotunda. We produce another event for ItemId=123.
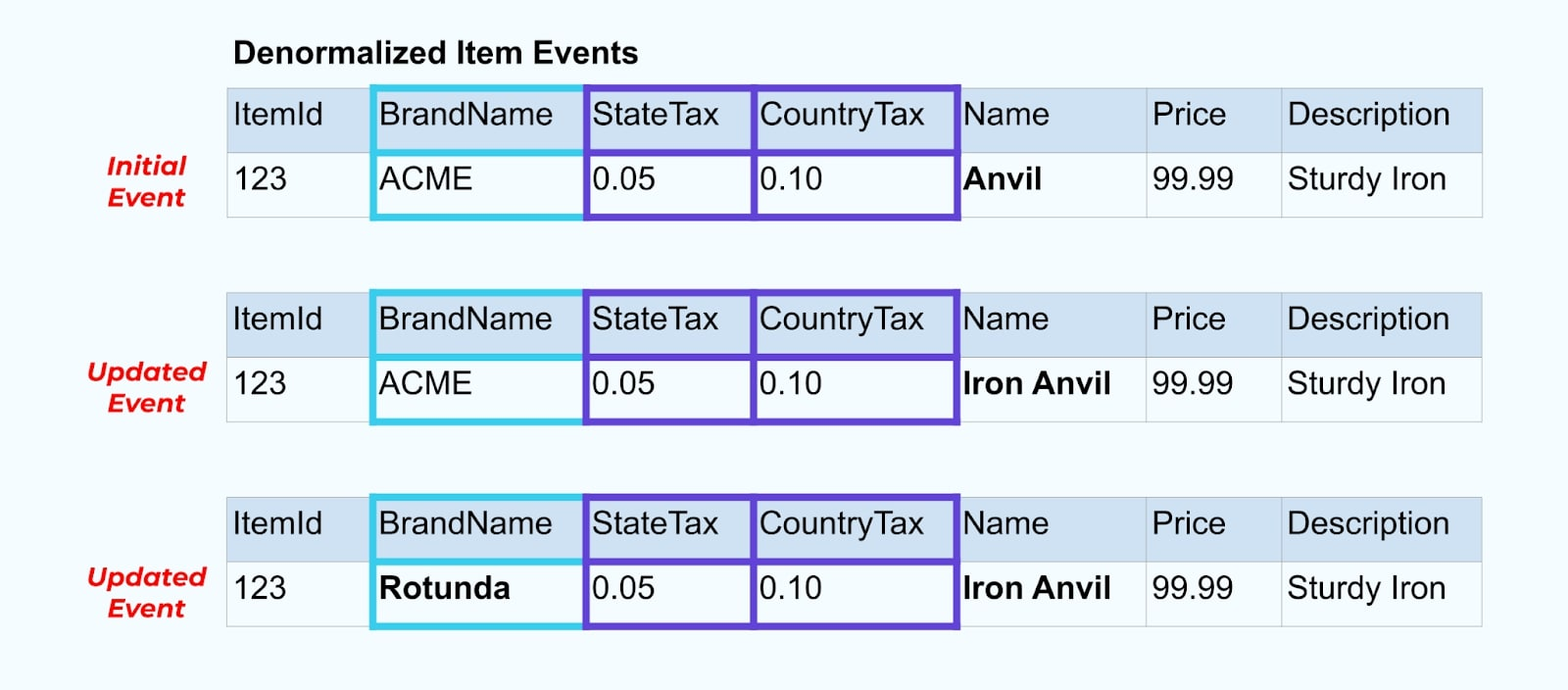
However, Rotunda (formerly ACME) likely has many hundreds (or thousands) of items that are also updated by this change, resulting in a corresponding number of updated enriched item events.
When denormalizing SCDs and foreign-key relationships, keep in mind the impact that a change in the SCD may have on the event stream as a whole. You may decide to forgo denormalization and leave it up to the consumer in the case that changing the SCD results in millions or billions of updated events.
Summary
Denormalization makes it easier for consumers to use data but comes at the expense of more upstream processing and a careful selection of data to include. Consumers may have an easier time building applications and can choose from a wider range of technologies, including those that don’t natively support streaming joins.
Normalizing data upstream works well when the data is small and infrequently updated. Larger event sizes, frequent updates, and SCDs are all factors to watch out for when determining what to denormalize upstream and what to leave for your consumers to do on their own.
Ultimately, choosing what data to include in an event and what to leave out is a balancing act between consumer needs, producer capabilities, and the unique data model relationships. But the best place to start is by understanding the needs of your consumers and isolation of your source system’s internal data model.
Opinions expressed by DZone contributors are their own.
Comments