How to Design Event Streams, Part 1
This article series addresses commonly asked questions, best practices, practical examples, and info on how to get started with event-driven architectures.
Join the DZone community and get the full member experience.
Join For FreeEvent streaming is becoming increasingly common in the world today. An event is a single piece of data that describes, as a snapshot in time, something important that happened in your business. We record that data to an event stream (typically using an Apache Kafka topic), which provides the basis for other applications and business processes to respond and react accordingly — also known as event-driven architecture (EDA).
Event-driven architectures (EDA) rely extensively on events. To be successful with EDA, you’ll need to know how to properly design your events because this will significantly affect not only what you can do today, but also tomorrow.
Designing events can be challenging, especially when considering consumers' diverse needs, data formats, and latency requirements. In this post, we’ll look at one of the main considerations when building events: designing around state vs. designing around changes.
But first, let’s look at the basics of event streams.
What Is an Event?
An event represents an occurrence at a specific point in time.

An event can really represent anything, but it almost always represents something that is important to the business. For example, an e-commerce business may record events about sales, orders, customers, deliveries, and inventory. An airline may record events about payments, flights, pilots, routes, airports, and flight telemetry.
The Basics of Event Streams
An event stream (also sometimes called a data stream) is a sequence of events, published to an immutable append-only log broker like Apache Kafka. The producer system writes events to the stream (Kafka topic), which is consumed by one or more consumer systems. Once an event is recorded, they are written into an event stream.
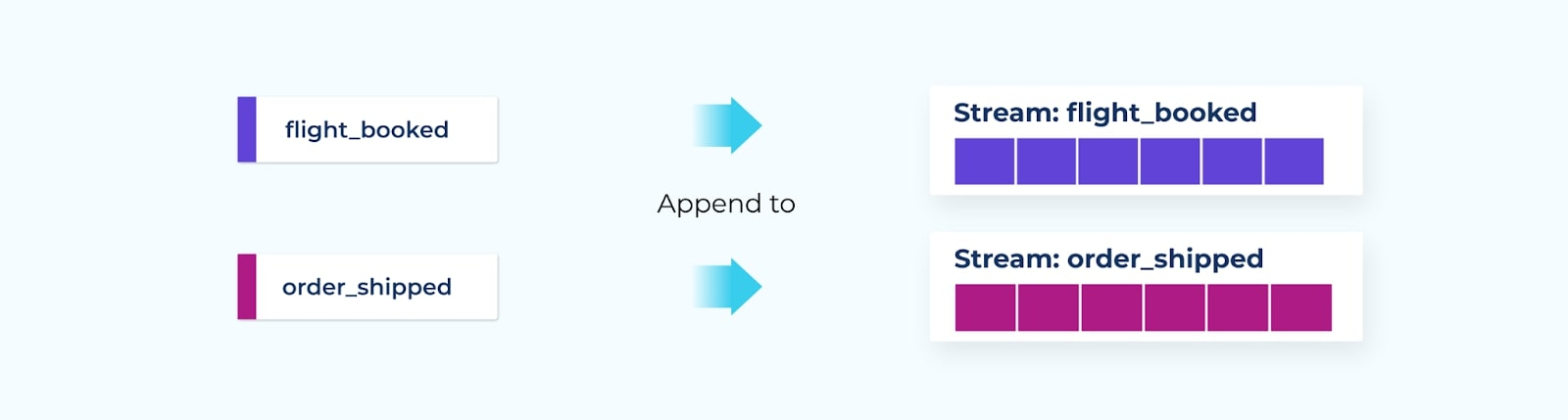
- Both events and event streams are completely immutable — once published, you can’t change their contents, nor can you change their order in the stream. Just like life, you can’t change the past :).
- Multiple consumers can use the event however they choose.
- Events are durable and replayable. Unlike a traditional queuing system, the events written to the topic remain available to process and consume as many times as you choose.
A log of events in a stream can be used to construct a detailed picture of the system over time, rather than just as a snapshot of the present.
There are several factors to consider when designing events. Who is the intended consumer? Is the event being produced within a single system for internal consumption by that same system? Or is it to be shared with external consumers, such as other systems, teams, and people?
One of the biggest questions in event design is deciding what data should go in the event and what data should not. Solving this question requires the same mental approach that we use for determining service boundaries and API composition. What do we keep encapsulated on the inside of the service, and what are we willing to expose outward to the wider world?
Let’s take a deeper look.
Data on the Inside vs. Data on the Outside
All (or at least the vast majority) of services contain data — data that’s been provided, created, computed, processed, or calculated. Some of this data is private, some is public, some represents intermediate forms as part of the business process, and some represents data that needs to be shared with other systems.
In any case, you can divide the data requirements of a service into two camps:
- Data on the inside consists of the data models and data structures inside of your application or service. This data is private to your system. But it also includes data that you may want to share outside of your boundary.
- Data on the outside is the data that we share with other systems. It’s explicitly modeled for discovery, consumption, and use by other teams, systems, and people.
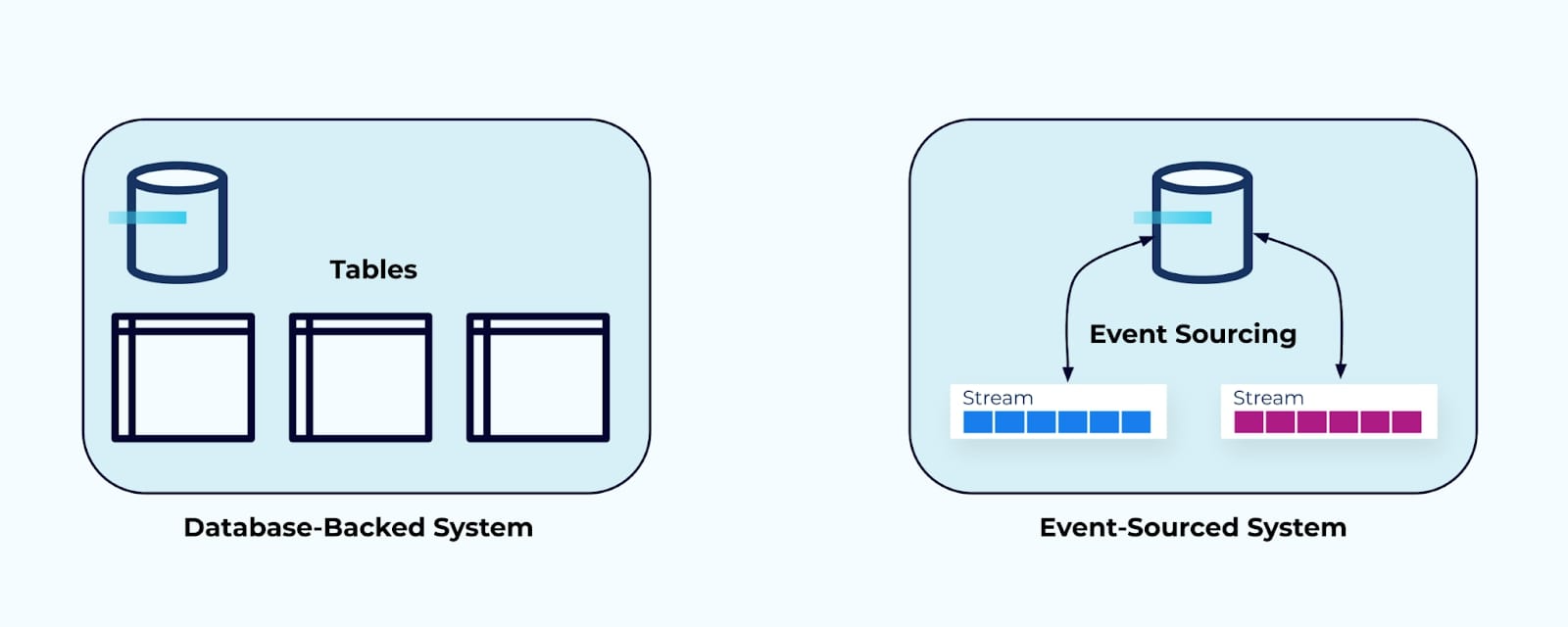
Two examples of data on the inside: A database-backed system and an event-sourced system
Services may store their data in a relational database, a key-value store, a document database, or even in a set of event streams (such as in an event-sourced system). Data on the inside is private and is meant specifically for use inside the system. It is modeled according to the needs of its service. It is not meant for use by other systems and teams and it isn’t opened up to the wider world. It remains encapsulated and tightly coupled to the needs of the service’s internal workings.
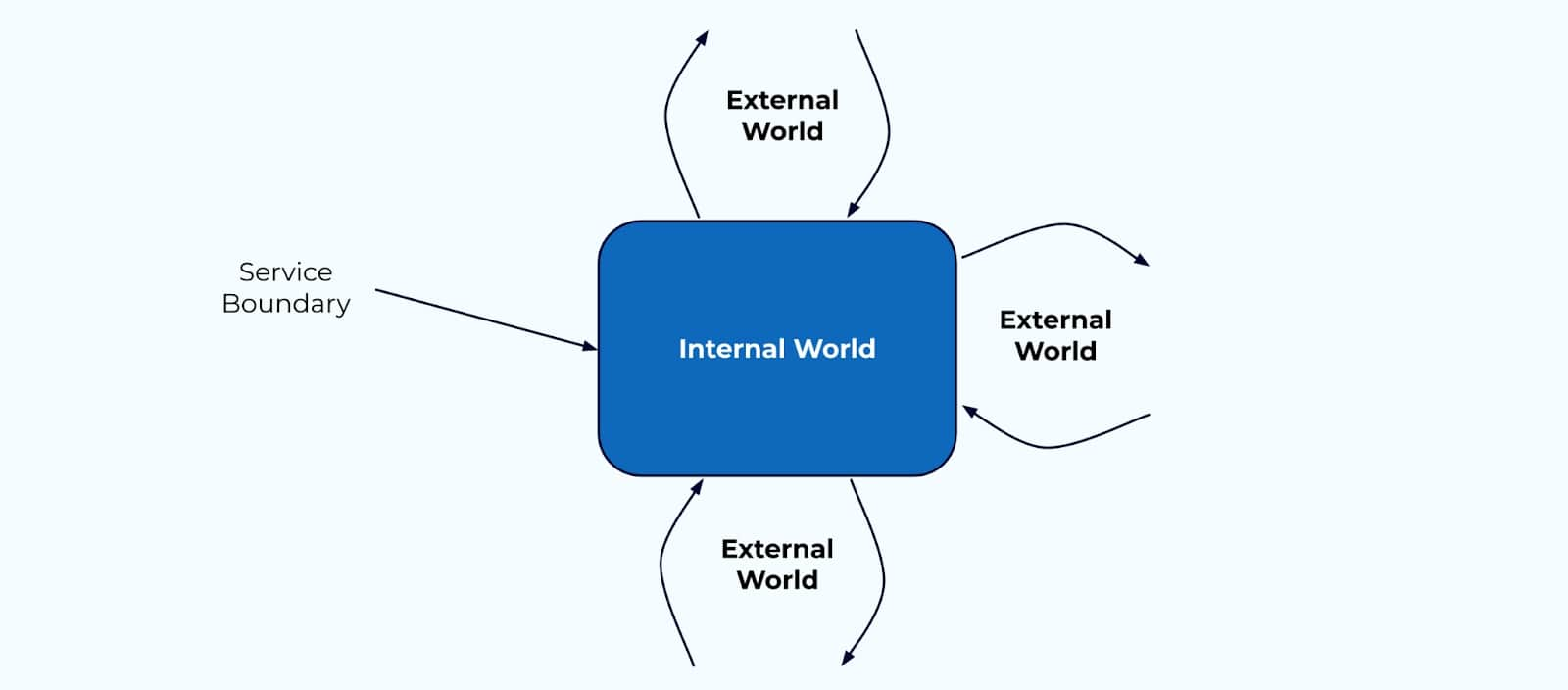 High-level view of the internal (data on the inside) and external (data on the outside) worlds
High-level view of the internal (data on the inside) and external (data on the outside) worlds
In contrast, data on the outside is the data that we share with other systems. It’s explicitly modeled for discovery, consumption, and use by other teams, systems, and people. Creating an external model requires negotiating with downstream consumers, but also requires thinking about state, changes, denormalization, security, performance, and cost — everything that we’ll cover as we look at the four main factors of event design.
Data on the inside/outside is a helpful way to think about what your data is for, and who should be able to access and use it. Just as we must consider what data we expose via a REST API to other services, we must also consider what data to expose to others using events.
There’s one more parallel to REST APIs to explore. When you make a successful REST request (such as a GET) you’ll receive a data payload with keys and values. You’ll then have to parse that data out to obtain meaning for your services. But we don’t expect each person or service using the REST API to figure out for themselves what that data means. No, we (typically) provide them with documentation and a schema of what data they should expect, so that they can easily use it — and events are no different.
Schemas are essential to creating reusable, discoverable, and error-free event streams. They provide basis and structure and give events the ability to evolve and change over time. Let’s take a deeper look.
Schemas and Data Contracts
Schemas are essential for defining the event. A schema provides all of the information about what should and shouldn’t be in an event, including names, types, optionality, and in-line documentation, just to name a few features. Popular schema technologies include Avro, Protobuf, and JSON Schema.
If you’re trying to stream data without a schema, you’re doing it wrong. I’ve already written more on schemas and data contracts in another blog article, so I recommend you check that out if you’d like to learn more. But if you just want the short form, here it is:
- Use schemas: Schemas keep producers from making mistakes when writing data, as you can generate the producer code directly from the schemas themselves. Similarly, consumers no longer need to interpret the data - just read it as it is on the schema, and use it accordingly. Schemas also provide evolution capabilities, where you can safely modify a schema (to some extent) based on changing business requirements.
- Build data contracts: They formalize the content of the event and the stream itself. It’s akin to a service API, that specifies not only how to use the event stream, but how to access it, security requirements, and ownership.
But now that we’ve established we’re using a schema… let’s look at the first major factor for event design.
Factor 1: State (Facts) vs. Deltas (Changes)
A state event (also called a fact event) details the entire scope of an entity’s state at a specific point in time. It contains all the fields and values necessary for fulfilling the public data contract. You can think of a state event like a row in a relational database, with the required fields represented by the table’s schema definition.
In contrast, a delta event records the changes between two states. It includes data about which fields have changed and their new values, but it does not include information about fields that have not changed.
Let’s take a look at the shopping cart example:
State (fact) event versus an item_added_to_cart delta event
On the left, we have the state event representing the shopping cart’s state at a point in time, though on its own it doesn’t indicate exactly what has changed. For that, you’ll need access to the previous cart fact.
On the right, we have the delta that describes the exact same business occurrence, in particular, that 1 instance of item:521 that was added to the cart. However, it doesn’t show the current state of the cart — for that, you need access to all of the previous delta events.
Facts and deltas each have their tradeoffs: so let’s get straight to the point on when to use which.
Fact Events Are Superior for Communicating State
Facts provide a precomputed state for its consumers, absolving them of computing any state. They simply consume the fact and process the state according to their business logic.
If you try to communicate state with deltas, then you must recreate the state from the very beginning of the topic. You also have to ensure that you use the correct business logic to process each state change. Most domains are more complicated than simply adding/removing an item from a cart, and it is very risky and dangerous to try to recompute state outside of the source system. Instead, just rely on fact events.
Consider the complexity of computing:
- Account balance for a customer corporate banking account
- Current inventory for an e-commerce retailer
- Taxes owed to the government
While each of these could be computed by each individual consumer who cares about it, it’s unsustainably complicated to set up and maintain. There is no practical benefit to it other than a slight reduction in network data usage. In short, it’s best to use fact events for communicating state.
Facts Let You Infer Deltas
A pair of fact events lets you infer your own changes: you can see everything that changed from the first event to the second.
One option for inferring changes: Keep the last fact in your service or job’s state store.
You keep a copy of the last consumed state in your service or job’s state store. Note that you only have to keep the state that you care about, and can throw away the rest. You can choose to keep multiple previous states as well (e.g., the last 3, or last 10 state updates) so that you can infer more complex changes over time.
As a tradeoff, you’re required to provide the state store. You also need to write the code to infer any changes between states, the complexity of which will vary depending on your requirements. In some cases, the logic will simply need to detect an edge transition, such as the image below where a discount_code is applied to the cart. In other cases, the state computation may be more complex, requiring data from multiple events or streams to be cross-referenced with your internal state.
 A second option for inferring changes: Use
A second option for inferring changes: Use before and after fields in the event.
You can provide two states within a single event. As you’ve probably guessed, the before field holds the state before the change was made, while the after holds the post-change state. Commonly used as part of change-data capture (CDC) services, it gives you the ability to see the entirety of an update between two states, and infer for yourself what changed in a single event. Note that this doubles the event size and can result in additional costs.
 Cart Fact with a before and after subsection
Cart Fact with a before and after subsection
Fact events are inherently larger than delta events. These could be expensive to maintain if their data is very large or they are updated very frequently. Look at a claim-check pattern if you would like to reduce the event size.
Delta Events Enable Event Sourcing
But what about delta events?
One of their main use cases is event sourcing. To compose the current state, you record each change as its own event and then apply the events in order, with specific state composition logic. This is an event-driven pattern for building a system with data on the inside, as there is a tightly coupled relationship between the events and the state composition logic.
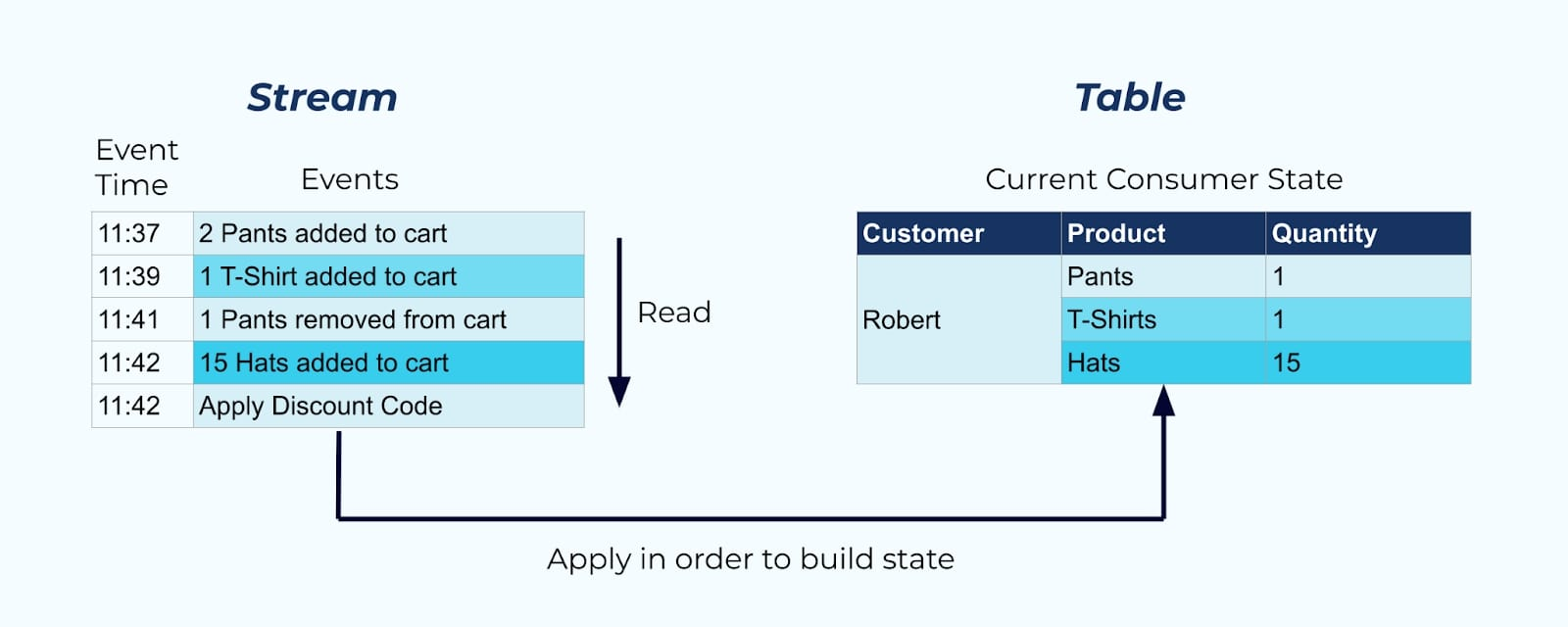 Event Sourcing: building state from a sequence of deltas
Event Sourcing: building state from a sequence of deltas
While fact events are triggered whenever a data field is updated, delta events are triggered whenever specific business logic conditions are met. For example, the item_added_to_cart event is triggered whenever an item is added to the cart.
 A Cart fact event vs. two cart-related delta events
A Cart fact event vs. two cart-related delta events
Deltas are suitable for capturing the intent behind a change. They’re often used for delivering notifications (e.g., food is ready for pickup, incoming email/text/message) to a consumer, which can provide helpful signaling solutions.
But deltas can be misused fairly easily. For one, customers tend to request fine-grained customized events to meet their downstream consumer needs. For example, “notify me when there are 15 items added to the cart”, or “let me know when the customer has spent $1000 on shoes in the last 90 days”. While these notifications may be essential for the consumer’s business unit, they put the onus of determining the condition on the producer of the data — moving responsibilities upstream, and blurring exactly which system is responsible for which computation.
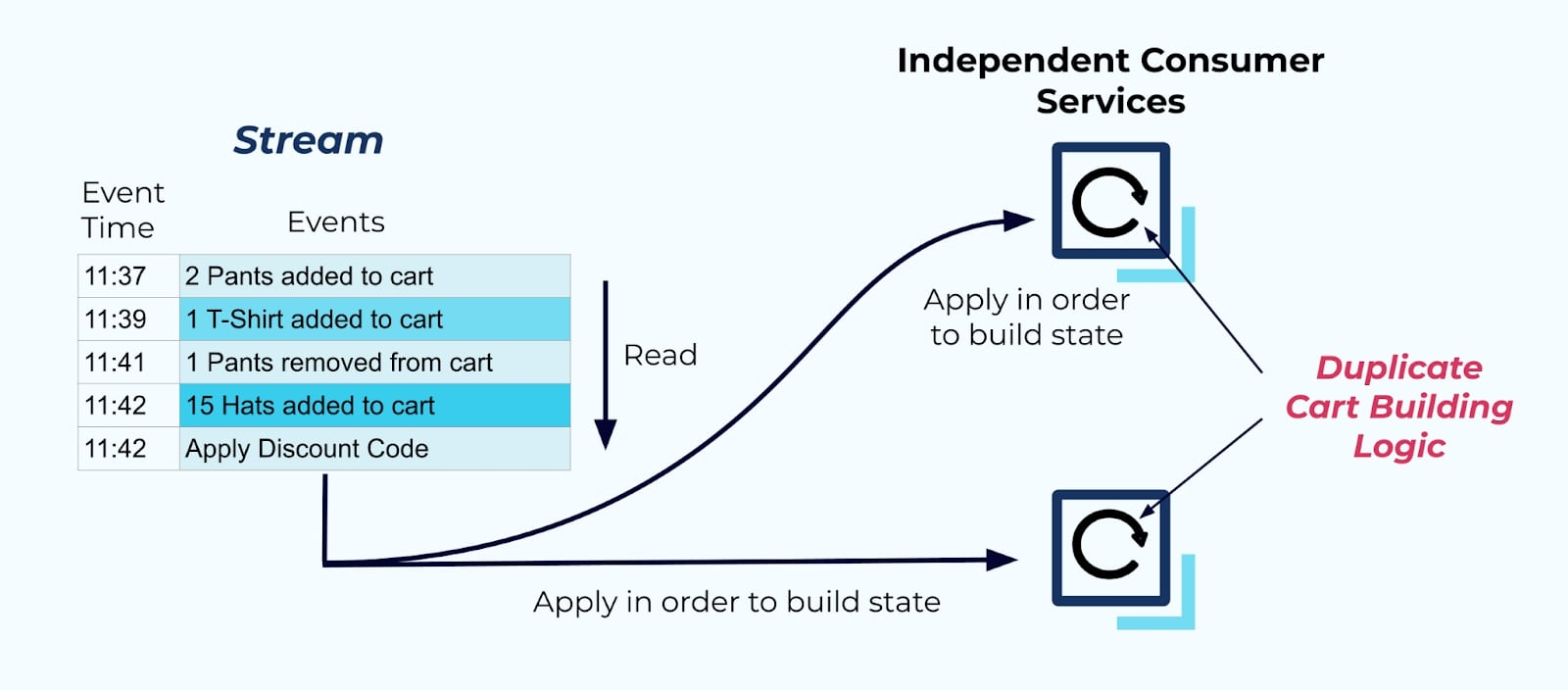 Deltas are unsuitable for rebuilding state on the outside
Deltas are unsuitable for rebuilding state on the outside
Instead, put consumer-specific business logic downstream, inside the services that care about detecting and acting on those conditions. Then, rely on state events to determine when those circumstances have occurred.
Composite Events
The third type of event is the composite event: it’s a combination of fact and delta.
Starting with a fact event, you can add information about why the event was created. In the following example, we include “item_added_to_cart” as the reason for the event’s creation (though you could also infer that yourself from your own state).
 Cart Fact with a “reason” field indicating why it was created
Cart Fact with a “reason” field indicating why it was created
Similarly, you could choose to include it in a “before/after” event, as follows:
 Composite Cart event with before/after fields
Composite Cart event with before/after fields
Note that adding a “reason” to the event can introduce strong coupling with the source system. You may have noticed: “Hey Adam, isn’t this just the name of the delta embedded inside the fact?” You’re correct. That’s precisely what it is.
To be clear, I don’t advocate using composite events because they introduce tight coupling on the upstream system’s reason-populating logic. There can be a lot of semantics loaded into the reason, and it can be difficult for consumers to make sense of them — particularly when new ones are added, or old ones are removed.
This is only one way to build a composite event. You may also wonder, “But Adam, what about a delta event that contains some state?”. While in theory, you could build a composite event in this way, the reality is that most delta events are very lean and contain no state at all — only the transition information. Part of this is due to convention (developers who prefer to use deltas typically minimize all data sent over the wire), and part of this is due to boundaries. We’ve already seen why it’s problematic to force your consumers to compute state from deltas.
The reality is that composite events are relatively rare in the wild. I’ve included them in this blog post because you may run into them in your own existing systems. I’ve never found that I needed to create a composite event in practice, instead favoring state events for data on the outside, leaving deltas (and the aforementioned reason field above) for data on the inside use cases.
Let’s segue away from composite events and back into looking at state. What do you do if you want to communicate large amounts of state, but it won’t fit into the event? For that, you’ll want to use a claim check.
The Claim Check Pattern
A claim check is where you embed a URI in the event, such that the consumers can access it for more information if they require it. The additional_state field contains a URI where you can obtain the additional information, such as a file store, a database, or a REST interface, for example.
 Additional state using the claim check pattern
Additional state using the claim check pattern
A claim check makes it easy for you to offload state storage to another event, while including common information that most event consumers will need. It can reduce the volume and cost of data transferred over your network. The claim check pattern can be useful when the data is very large, particularly if it’s not commonly used (e.g., the complete set of plain text reviews for an e-commerce item).
However, keep in mind that there are several major considerations for implementing this pattern, including:
- Access controls: Ensuring that only the appropriate consumers can read the additional state
- Storage: Ensuring that the
additional_statedata is only deleted when the event is deleted or compacted - Schemas: The data in the
additional_stateURI will have its own schema and format. You’ll need to ensure that consumers can read it easily and that it doesn’t undergo any unplanned breaking changes. Coordinating the event version and theadditional_stateversion evolutions can also be challenging. - Replayability: Immutability is a key notion of replayability. If you choose to implement claim checks, you need to ensure that your URI points to a snapshot of the data at that point in time. A common anti-pattern is to point to the current state in a database table, which provides no replayability since the
additional_stateis overwritten at every change.
Proceed with caution, as you may find the above-mentioned complexity outweighs the benefits.
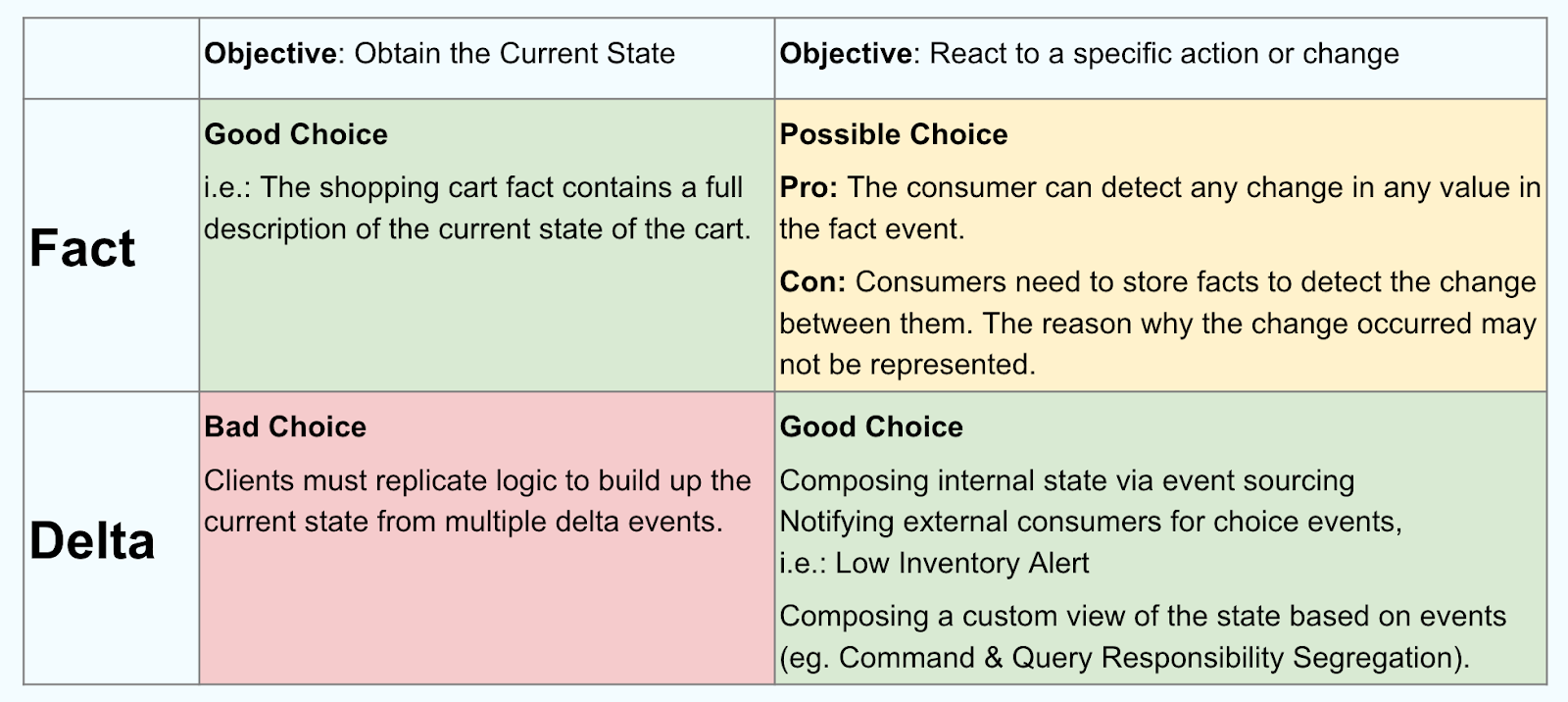
When Should I Use Facts Versus Deltas?
The following table sums it up nicely.
Event streams form the bedrock of any event-driven architecture, and a correct design is an essential starting point. Well-designed streams make it easy to communicate important business events so that interested consumers can read, ingest, store, and respond to them at their own pace.
You must consider the stream's role — will it provide data on the inside or the outside? Facts are a flexible and resilient model to build your events around, but they tend to be larger and require more over-the-wire data use. However, compared to deltas, they completely isolate the internal logic of the upstream system, making it easy to build resilient decoupled consumers to serve specific business purposes.
But this is just the first of four of our main factors!
What’s Next
In part 2, we’ll explore how the source of the data (often a database) plays in the design and modeling of our event streams. We’ll explore the impact of relational data on our streams, and how it affects how we use it. Stay tuned to find out.
Opinions expressed by DZone contributors are their own.
Comments