Reactive Kafka With Streaming in Spring Boot
How to integrate Spring Boot and Kafka with Streams in a reactive solution.
Join the DZone community and get the full member experience.
Join For FreeThe AngularAndSpring project uses Kafka for the distributed sign-in of new users and the distributed token revocation for logged-out users.
System Architecture
The AngularAndSpring project needs to be able to be horizontally scaled each with its own database. To enable that, a sign-in needs to be propagated to all instances. Kafka serves as a central event streaming platform to send the sign-in events. Kafka is horizontally scalable to high event loads and can be set up to be highly available.
User Sign-in Architecture
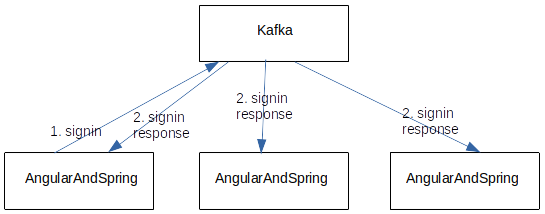
The user sign-in creates a new user that has to be created in all instances of an AngularAndSpring project deployment. To do that, Kafka is used to stream the sign-in events to all deployed AngularAndSpring instances where they are stored. The sign-in is complete after the sign-in response has been processed at the sign-in instance. Then, the login can be done on any AngularAndSpring instance.
User Logout Architecture
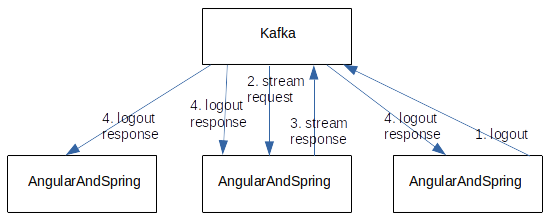
The user logout is processed locally, and the user gets the logout displayed in the UI. The logout process also sends a logout event to Kafka to revoke the JWT of this user login. Kafka then starts a stateful stream (possibly after a timeout) that aggregates all logged-out tokens of the last 120 sec. The processing of the Kafka Stream is processed on an AngularAndSpring instance. The list of revoked tokens is returned to Kafka and sent by Kafka to all AngularAndSpring instances. The AngularAndSpring instances update their in-memory list of revoked tokens. That prevents token renewal.
Deployment Architecture
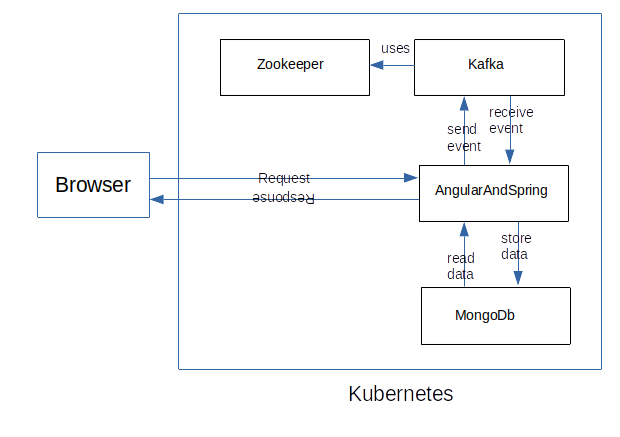
The system is deployed with a Helm chart in Kubernetes. The current Kafka version needs Zookeeper. The AngularAndSpring project sends/receives events from Kafka and reads/stores data in MongoDB. Zookeeper and Kafka are Kubernetes deployments with services to access them. AngularAndSpring has a Kubernetes deployment and a service with a NodePort to access the UI, and MongoDB has a Kubernetes deployment with a service that persists the data in a Kubernetes volume/volumeclaim.
User Sign-in
The AngularAndSpring project uses the reactive APIs of Spring Boot to access MongoDB. The Spring Boot reactive APIs are used for Kafka, too.
In the KafkaConfig class the Kafka consumers/producers/topics are configured or created:
@Configuration
@Profile("kafka | prod")
@EnableKafka
@EnableKafkaStreams
public class KafkaConfig {
...
@PostConstruct
public void init() throws ClassNotFoundException {
String bootstrap = this.bootstrapServers.split(":")[0].trim();
if (bootstrap.matches("^\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}$")) {
DefaultHostResolver.IP_ADDRESS = bootstrap;
} else if (!bootstrap.isEmpty()) {
DefaultHostResolver.KAFKA_SERVICE_NAME = bootstrap;
}
LOGGER.info("Kafka Servername: {} Kafka Servicename: {}
Ip Address: {}", DefaultHostResolver.KAFKA_SERVER_NAME,
DefaultHostResolver.KAFKA_SERVICE_NAME,
DefaultHostResolver.IP_ADDRESS);
Map<String,Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.ACKS_CONFIG, "all");
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
props.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,
this.compressionType);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
Class.forName(this.producerKeySerializer));
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
Class.forName(this.producerValueSerializer));
this.senderOptions = SenderOptions.create(props);
props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "all");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,
this.consumerAutoOffsetReset);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
Class.forName(this.consumerKeySerializer));
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
Class.forName(this.consumerValueSerializer));
this.receiverOptions = ReceiverOptions.create(props);
}The Annotations make KafkaConfig a Configuration class for the Profiles (‘kafka’ or ‘prod’) and Kafka with KafkaStreams is enabled.
The init() method is used to set up the properties for Kafka consumers and producers. The DefaultHostResolver class of the Kafka API needs to be overwritten to enable the use of a Kafka deployment in a Minikube cluster. The config for the Kafka deployment can be found in this directory.
- The consumers/producers share the BOOTSTRAP_SERVERS_CONFIG that has to be IpAdress:Port (like: 192.168.1.1:9092) or a servicename:Port (like: kafkaservice:9092)
- The producerConfig.ACKS_CONFIG = requires all consumers to have received the event.
- The producerConfig.ENABLE_IDEMPOTENCE_CONFIG = true enables retries
- The producerConfig.COMPRESSION_TYPE_CONFIG = ‘gzip’ enables the gzip compression of messages(other types are available)
- The producerConfig.KEY_SERIALIZER_CLASS_CONFIG/VALUE_SERIALIZER_CLASS_CONFIG set the serializers for event key/value.
- The consumerConfig.GROUP_ID_CONFIG sets the common consumer groupId.
- The consumerConfig.AUTO_OFFSET_RESET_CONFIG configures where new Consumers should start processing.
- The consumerConfig.KEY_DESERIALIZER_CLASS_CONFIG/VALUE_DESERIALIZER_CLASS_CONFIG set the deserializers for the event key/value.
@Bean
public ReceiverOptions<?, ?> kafkaReceiverOptions() {
return this.receiverOptions;
}
@Bean
public KafkaSender<?, ?> kafkaSender() {
return KafkaSender.create(this.senderOptions);
}
@Bean
public NewTopic newUserTopic() {
return TopicBuilder.name(KafkaConfig.NEW_USER_TOPIC)
.config(TopicConfig.COMPRESSION_TYPE_CONFIG,
this.compressionType).compact().build();
}The method kafkaReceiverOptions() provides the receiverOptions that were created in the init() method for Spring to inject.
The method kafkaSender provides a KafkaSender with the senderOptions that were created in the init() method for Spring to inject.
The method newUserTopic() creates on startup a new Kafka Topic with the compression type set.
That is the setup Spring Boot needs for the Kafka sign-in.
Send Events
The EventProducer class sends the events to Kafka:
@Profile("kafka | prod")
@Service
public class EventProducer implements MyEventProducer {
private static final Logger LOGGER =
LoggerFactory.getLogger(EventProducer.class);
private final KafkaSender<String, String> kafkaSender;
private final EventMapper eventMapper;
public EventProducer(KafkaSender<String, String> kafkaSender,
EventMapper eventMapper) {
this.kafkaSender = kafkaSender;
this.eventMapper = eventMapper;
}
public Mono<MyUser> sendNewUser(MyUser dto) {
String dtoJson = this.eventMapper.mapDtoToString(dto);
return this.kafkaSender.createOutbound()
.send(Mono.just(new ProducerRecord<>(KafkaConfig.NEW_USER_TOPIC,
dto.getSalt(), dtoJson))).then()
.doOnError(e -> LOGGER.error(
String.format("Failed to send topic: %s value: %s",
KafkaConfig.NEW_USER_TOPIC, dtoJson), e))
.thenReturn(dto);
}The MessageProducer has the Profile Annotation to be used when the Profile ‘kafka’ or ‘prod’ is added.
The constructor injects the kafkaSender and the EventMapper.
The method sendNewUser(…) uses the EventMapper to turn the MyUser class into a String to send. The kafkaSender sends the dtoJson to the ‘NEW_USER_TOPIC’ with the event key ‘dto.getSalt()’. The method returns a Mono to support reactive sending.
Receive Events
The EventConsumer class receives the events from Kafka:
@Profile("kafka | prod")
@Service
public class EventConsumer {
private static final Logger LOGGER =
LoggerFactory.getLogger(EventConsumer.class);
private final ReceiverOptions<String, String> receiverOptions;
private final KafkaReceiver<String, String> userLogoutReceiver;
private final KafkaReceiver<String, String> newUserReceiver;
private final MyUserServiceEvents myUserServiceEvents;
private final EventMapper eventMapper;
@Value("${spring.kafka.consumer.group-id}")
private String consumerGroupId;
public EventConsumer(MyUserServiceEvents myUserServiceEvents,
ReceiverOptions<String, String> receiverOptions,
EventMapper eventMapper) {
this.receiverOptions = receiverOptions;
this.userLogoutReceiver = KafkaReceiver
.create(this.receiverOptions(List
.of(KafkaConfig.USER_LOGOUT_SINK_TOPIC)));
this.newUserReceiver = KafkaReceiver.create(this
.receiverOptions(List.of(KafkaConfig.NEW_USER_TOPIC)));
this.myUserServiceEvents = myUserServiceEvents;
this.eventMapper = eventMapper;
}
private ReceiverOptions<String, String> receiverOptions(
Collection<String> topics) {
return this.receiverOptions
.addAssignListener(p -> LOGGER.info("Group {} partitions assigned
{}", this.consumerGroupId, p))
.addRevokeListener(p -> LOGGER.info("Group {} partitions
revoked {}", this.consumerGroupId, p))
.subscription(topics);
}
@EventListener(ApplicationReadyEvent.class)
public void doOnStartup() {
this.newUserReceiver.receiveAtmostOnce().flatMap(myRecord ->
this.myUserServiceEvents
.userSigninEvent(this.eventMapper.
mapJsonToObject(myRecord.value(),
MyUser.class))).subscribe();
this.userLogoutReceiver.receiveAtmostOnce().flatMap(myRecord ->
this.myUserServiceEvents.logoutEvent(this.eventMapper
.mapJsonToObject(myRecord.value(),
RevokedTokensDto.class))).subscribe();
}
}The EventConsumer class is enabled with profile annotation on the profiles ‘kafka’ or ‘prod’. The constructor sets the MyUserServiceEvents service, the EventMapper, and the newUserReceiver.
The method doOnStartup() is run by Spring just before the startup is finished. The method creates a Spring Reactor Streams that receive newUser/logout events and processes them with the MyUserService. The Streams are then subscribed() and run for the uptime of the application.
Process Events
The MyUserServiceEvents class processes the sign-in events:
@Profile("kafka | prod")
@Service
public class MyUserServiceEvents extends MyUserServiceBean
implements MyUserService {
private static final Logger LOGGER = LoggerFactory.getLogger(
MyUserServiceEvents.class);
private final MyEventProducer myEventProducer;
private final Sinks.Many<MyUser> myUserSink = Sinks.many().multicast()
.onBackpressureBuffer();
private final ConnectableFlux<MyUser> myUserFlux = this.myUserSink
.asFlux().publish();
public MyUserServiceEvents(JwtTokenProvider jwtTokenProvider,
PasswordEncoder passwordEncoder, PasswordEncryption passwordEncryption,
MyMongoRepository myMongoRepository, MyEventProducer myEventProducer) {
super(jwtTokenProvider, passwordEncoder, passwordEncryption,
myMongoRepository);
this.myEventProducer = myEventProducer;
}
@Override
public Mono<MyUser> postUserSignin(MyUser myUser) {
Mono<MyUser> myUserResult = this.myUserFlux.autoConnect()
.filter(myUser1 -> myUser.getUserId().equalsIgnoreCase(
myUser1.getUserId())).shareNext();
return super.postUserSignin(myUser, false, true).flatMap(dto ->
this.myEventProducer.sendNewUser(dto)).zipWith(myUserResult,
(myUser1, msgMyUser1)-> msgMyUser1).flatMap(myUser1 -> {
return Mono.just(myUser1);
});
}
public Mono<MyUser> userSigninEvent(MyUser myUser) {
return super.postUserSignin(myUser, true, false).flatMap(myUser1 -> {
if (this.myUserSink.tryEmitNext(myUser1).isFailure()) {
LOGGER.info("Emit to myUserSink failed. {}", myUser1);
}
return Mono.just(myUser1);
});
}The MyUserServiceEvents class is enabled with profile annotation on the profiles ‘kafka’ or ‘prod’. The constructor injects a MyEventProducer to send events to Kafka.
myUserSink creates a sink that can send Spring Reactor MyUser events.
myUserFlux creates a Spring Reactor Flux that can receive MyUser events.
The method postUserSignin(…) is called by the rest controller MyUserController and creates a Mono that is connected to the myUserFlux to wait for the matching event for this sign-in. The method postUserSignin(…) checks the sign-in entity but does not store it. In the flatMap(…), the sign-in entity is sent to Kafka with the MyEventProducer. Then, zipWith(…) is used to wait for the result to arrive in the myUserFlux that is received in the myUserResult, and the result Mono is returned.
The method userSigninEvent(…) is called by the EventConsumer and calls the postUserSignin(…) method to store the event. Then, myUserSink is used to emit the Spring Reactor event that enables the postUserSignin(…) method to finish and returns the result Mono.
Conclusion Sign-in
In the first part of the series, the setup and reactive sending/receiving events were shown. Spring enables using Kafka with little code and effort, and the Reactor support for Kafka enables the efficient/reactive sending and receiving of events while keeping the code readable.
Logout
The AngularAndSpring project uses Kafka for the distributed sign-in of new users and the distributed token revocation for logged-out users. This article shows how the login/logout uses stateful Kafka streams to implement token revocation on logout. The architecture is shown in the Sign-in part.
User Login
The login is handled in the MyUserServiceBean. The login process is the same for Kafka- and MongoDB-based authentication.
public Mono<MyUser> postUserLogin(MyUser myUser) throws
NoSuchAlgorithmException, InvalidKeySpecException {
Query query = new Query();
query.addCriteria(Criteria.where("userId").is(myUser.getUserId()));
return this.myMongoRepository.findOne(query,
MyUser.class).switchIfEmpty(Mono.just(new MyUser()))
.delayElement(Duration.ofSeconds(3L))
.map(user1 -> loginHelp(user1, myUser.getPassword()));
}
private MyUser loginHelp(MyUser user, String passwd) {
if (user.getUserId() != null) {
if (this.passwordEncoder.matches(passwd, user.getPassword())) {
String jwtToken = this.jwtTokenProvider.createToken(user.getUserId(),
Arrays.asList(Role.USERS));
user.setToken(jwtToken);
user.setPassword("XXX");
return user;
}
}
return new MyUser();
}The postUserLogin method uses the reactive APIs from Spring Reactor.
The query searches for the ‘userId’ in the documents, and the ‘userId’ is unique.
The ‘findOne(…)’ call searches for the MyUser Document of the query. If it is not found, an empty MyUser Document is returned. The return of the document is delayed for 3 seconds to limit the number of logins per user. The method loginHelp checks if the MyUser Document was found, checks the password, then checks if it is either a MyUser Document with a valid token returned or an empty MyUser Document.
User Logout Event
The logout event is created for Kafka in the MyUserServiceEvents class in the method postLogout(…)
public Mono<Boolean> postLogout(String token) {
String username = this.getTokenUsername(token);
String uuid = this.getTokenUuid(token);
List<RevokedToken> revokedTokens = new ArrayList<>();
revokedTokens.add(new RevokedToken(null, username, uuid,
LocalDateTime.now()));
return revokedTokens.stream().map(myRevokedToken ->
this.myEventProducer.sendUserLogout(myRevokedToken)
.flatMap(value -> Mono.just(value != null)))
.reduce((result1, result2) ->
Mono.just(result1.block() == true && result2.block() == true))
.orElse(Mono.just(Boolean.FALSE));
}First, the ‘username’ and the ‘uuid’ are retrieved from the token. The ‘uuid’ is unique per login not token.
Then, a list of RevokedTokens with a RevokedToken for this login is created.
The revokedToken list is used to create a stream that sends the RevokedToken to the Kafka Stream with the myEventProducer. Because the results can have duplicates, all results are checked to be true and the result is returned.
Send Events
The logout Event is sent in the EventProducer class in the sendUserLogout method:
public Mono<RevokedToken> sendUserLogout(RevokedToken dto) {
String dtoJson = this.eventMapper.mapDtoToString(dto);
return this.kafkaSender.createOutbound().send(Mono.just(
new ProducerRecord<>(KafkaConfig.USER_LOGOUT_SOURCE_TOPIC,
dto.getName(), dtoJson))).then()
.doOnError(e -> LOGGER.error(
String.format("Failed to send topic: %s value: %s",
KafkaConfig.USER_LOGOUT_SOURCE_TOPIC, dtoJson), e))
.thenReturn(dto);
}The EventMapper is used to turn the RevokedToken DTO as a JSON string.
The kafkaSencer creates an outbound connection and sends the ProducerRecord of Kafka to the USER_LOGOUT_SOURCE_TOPIC with the username as the key and the JSON string as the content. Errors are logged, and, after the event was sent, the DTO is returned.
Kafka Logout Stream
The stateful Kafka stream to handle the revokedTokens is in the KafkaStreams class:
@Profile("kafka | prod")
@Component
public class KafkaStreams {
private static final Logger LOGGER =
LoggerFactory.getLogger(KafkaStreams.class);
private static final long LOGOUT_TIMEOUT = 120L;
private static final long GRACE_TIMEOUT = 5L;
private ObjectMapper objectMapper;
public KafkaStreams(ObjectMapper objectMapper) {
this.objectMapper = objectMapper;
}
@Bean("UserLogoutTopology")
public Topology userLogout(final StreamsBuilder builder) {
builder.stream(KafkaConfig.USER_LOGOUT_SOURCE_TOPIC,
Consumed.with(Serdes.String(), Serdes.String())).groupByKey()
.windowedBy(SlidingWindows
.ofTimeDifferenceAndGrace(Duration.ofSeconds(
KafkaStreams.LOGOUT_TIMEOUT),
Duration.ofSeconds(KafkaStreams.GRACE_TIMEOUT)))
.aggregate(LinkedList<String>::new, (key, value, myList) -> {
myList.add(value);
return myList;
}, Materialized.with(Serdes.String(),
Serdes.ListSerde(LinkedList.class, Serdes.String())))
.toStream().mapValues(value ->
convertToRevokedTokens((List<String>) value))
.to(KafkaConfig.USER_LOGOUT_SINK_TOPIC);
Properties streamsConfiguration = new Properties();
streamsConfiguration.put(
StreamsConfig.DEFAULT_TIMESTAMP_EXTRACTOR_CLASS_CONFIG,
LastlogoutTimestampExtractor.class.getName());
streamsConfiguration.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG,
1000L);
return builder.build(streamsConfiguration);
}The KafkaStreams class is activated with the ‘kafka’ or ‘prod’ profiles.
The method userLogout(…) creates the ‘UserLogoutTopology’ for the Kafka stream that has ‘USER_LOGOUT_SOURCE_TOPIC’ as the source. The stream has groupByKey() to group the Events by userId. The stream has windowedBy(…) to have a persistent window of 125 seconds for the logout events after that the events are out of the window. The windowBy(…) persists the events and returns an aggregation of the events for the userId in the window. The Event key and the value are strings in the Materialized(stateful) Kafka Topic. In Materialized.with(…) are the values mapped in a list of RevokedToken objects and send to the ‘USER_LOGOUT_SINK_TOPIC’. Then are two Kafka stream config properties set and the builder returns the topology.
Stateful Kafka topics are processed after either the 10 MB of data are received or a timeout of 30 seconds has passed.
Receive Events
The Kafka Events are received with the EventConsumer:
@EventListener(ApplicationReadyEvent.class)
public void doOnStartup() {
this.newUserReceiver.receiveAtmostOnce().flatMap(myRecord ->
this.myUserServiceEvents.userSigninEvent(this.eventMapper.
mapJsonToObject(myRecord.value(), MyUser.class))).subscribe();
this.userLogoutReceiver.receiveAtmostOnce().flatMap(myRecord ->
this.myUserServiceEvents.logoutEvent(this.eventMapper.
mapJsonToObject(myRecord.value(),
RevokedTokensDto.class))).subscribe();
} The ‘ApplicationReadyEvent’ is sent before startup is complete. The ‘userLogoutReceiver’ processes the Json(String) events with the EventMapper and the logoutEvent(…) method of the MyUserServiceEvents class. The subscribe() method activates the Kafka receiver.
Process the Events
The RevokedTokensDto class is processed in the logoutEvent(…) in the MyUserServiceEvents class.
public Mono<Boolean> logoutEvent(RevokedTokensDto revokedTokensDto) {
return Mono.just(this.updateLoggedOutUsers(revokedTokensDto
.getRevokedTokens()));
}
public Boolean updateLoggedOutUsers(List<RevokedToken> revokedTokens) {
this.jwtTokenProvider.updateLoggedOutUsers(revokedTokens);
return Boolean.TRUE;
}The method updateLoggedOutUsers(…) calls the method updateLoggedOutUsers(…) that is used to update the in-memory list of RevokedToken DTOs that are checked on each request.
Conclusion Logout
Kafka enables the easy implementation of Jwt token revokation. If the limitations of stateful Kafka Topic Streams are not a blocker they can reduce the amount of logic in the applications for this feature. Kafka is a very powerful tool that can do a lot but it does take time to get up to speed with it.
Development/System Deployment
The AngularAndSpring project uses Kafka for the distributed sign-in of new users, and the distributed token revocation for logged-out users. This article shows how the development deployment of Kafka and the system deployment of Kafka/Zookeeper/MongoDb/AngularAndSpring.
Patching the Kafka DNS Name Resolution
The Spring Kafka client checks the DNS name of the Kafka instance. To disable the DNS check, the DefaultHostResolver class is overwritten.
public class DefaultHostResolver implements HostResolver {
public static volatile String IP_ADDRESS = "";
public static volatile String KAFKA_SERVER_NAME = "";
public static volatile String KAFKA_SERVICE_NAME = "";
@Override
public InetAddress[] resolve(String host) throws UnknownHostException {
if(host.startsWith(KAFKA_SERVER_NAME) && !IP_ADDRESS.isBlank()) {
InetAddress[] addressArr = new InetAddress[1];
addressArr[0] = InetAddress.getByAddress(host,
InetAddress.getByName(IP_ADDRESS).getAddress());
return addressArr;
} else if(host.startsWith(KAFKA_SERVER_NAME) &&
!KAFKA_SERVICE_NAME.isBlank()) {
host = KAFKA_SERVICE_NAME;
}
return InetAddress.getAllByName(host);
}
}The ‘KAFKA_SERVER_NAME’ contains the string that the DNS name of the Kafka server starts with. The ‘IP_ADDRESS’ contains the IP address of the Kubernetes cluster (Minikube in this example). The ‘KAFKA_SERVICE_NAME’ contains the service name that has to be used to connect to Kafka in the Kubernetes cluster.
If the ‘KAFKA_SERVER_NAME’ and the ‘IP_ADDRESS’ are set, the ‘IP_ADDRESS’ is returned if the DNS name starts with the ‘KAFKA_SERVER_NAME’. That enables the Kafka DNS resolution in the development deployment.
If the ‘KAFKA_SERVER_NAME’ and the ‘KAFKA_SERVICE_NAME’ are set, and the Kafka DNS name starts with the ‘KAFKA_SERVER_NAME’, the ‘KAFKA_SERVICE_NAME’ is set as the Kafka DNS name to access Kafka in the Kubernests cluster.
Development Deployment
For development, a local Kafka instance is needed, and Kafka and Zookeeper need to be deployed together. This can be done with Docker Compose or Kubernetes. Kubernetes is used for system deployment, so it is also used for development.
The Helm chart for the deployment can be found in the kafka directory. The values.yaml looks like this:
kafkaName: kafkaapp
zookeeperName: zookeeperserver
kafkaImageName: bitnami/kafka
kafkaImageVersion: latest
zookeeperImageName: bitnami/zookeeper
zookeeperImageVersion: latest
kafkaServiceName: kafkaservice
zookeeperServiceName: zookeeperservice
volumeClaimName: mongo-pv-claim
persistentVolumeName: mongo-pv-volume
secret:
name: app-env-secret
nameKafka: kafka-env-secret
nameZookeeper: zookeeper-env-secret
envZookeeper:
normal:
ALLOW_ANONYMOUS_LOGIN: yes
secret:
ZOOKEEPER_TICK_TIME: "2000"
envKafka:
normal:
KAFKA_BROKER_ID: "1"
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_CFG_LISTENERS: PLAINTEXT://:9092
KAFKA_CFG_ADVERTISED_LISTENERS: PLAINTEXT://:9092
KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE: false
ALLOW_PLAINTEXT_LISTENER: yes
secret:
KAFKA_ZOOKEEPER_CONNECT: "zookeeperservice:2181" First, all the Helm variables are set. The secret contains the encoded secret values for Kafka and Zookeeper.
The ‘envZookeeper’ and ‘envKafka’ part has the normal environment variables and the secret ones. The secret variables are handled by the _helpers.tpl script and are supplied as Kubernetes secrets.
The Helm template looks like this:
apiVersion: v1
kind: Secret
metadata:
name: {{ .Values.secret.nameZookeeper }}
type: Opaque
data:
{{- range $key, $val := .Values.envZookeeper.secret }}
{{ $key }}: {{ $val | b64enc }}
{{- end}}
---
apiVersion: v1
kind: Secret
metadata:
name: {{ .Values.secret.nameKafka }}
type: Opaque
data:
{{- range $key, $val := .Values.envKafka.secret }}
{{ $key }}: {{ $val | b64enc }}
{{- end}}
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Values.zookeeperName }}
labels:
app: {{ .Values.zookeeperName }}
spec:
replicas: 1
selector:
matchLabels:
app: {{ .Values.zookeeperName }}
template:
metadata:
labels:
app: {{ .Values.zookeeperName }}
spec:
containers:
- name: {{ .Values.zookeeperName }}
image: "{{ .Values.zookeeperImageName }}:{{ .Values.zookeeperImageVersion }}"
resources:
limits:
memory: "768M"
cpu: "0.5"
requests:
memory: "512M"
cpu: "0.5"
env:
{{- include "helpers.list-envZookeeperApp-variables" . | indent 10 }}
ports:
- containerPort: 2181
---
apiVersion: v1
kind: Service
metadata:
name: {{ .Values.zookeeperServiceName }}
labels:
app: {{ .Values.zookeeperServiceName }}
spec:
ports:
- port: 2181
protocol: TCP
selector:
app: {{ .Values.zookeeperName }}
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Values.kafkaName }}
labels:
app: {{ .Values.kafkaName }}
spec:
replicas: 1
selector:
matchLabels:
app: {{ .Values.kafkaName }}
template:
metadata:
labels:
app: {{ .Values.kafkaName }}
spec:
securityContext:
runAsUser: 0
runAsGroup: 0
fsGroup: 0
containers:
- name: {{ .Values.kafkaName }}
image: "{{ .Values.kafkaImageName }}:{{ .Values.kafkaImageVersion }}"
imagePullPolicy: Always
resources:
limits:
memory: "1G"
cpu: "1.5"
requests:
memory: "768M"
cpu: "1.0"
env:
{{- include "helpers.list-envKafkaApp-variables" . | indent 10 }}
ports:
- containerPort: 9092
---
apiVersion: v1
kind: Service
metadata:
name: {{ .Values.kafkaServiceName }}
labels:
run: {{ .Values.kafkaServiceName }}
spec:
type: NodePort
ports:
- port: 9092
nodePort: 9092
protocol: TCP
selector:
app: {{ .Values.kafkaName }}The first two sections create opaque secrets that are base64 encoded for the Kafka and Zookeeper secrets.
The next two sections have the deployment/service for Zookeeper. The memory is limited to ‘768M’ and the CPU is limited to ‘0.5’. The lines ‘env: {{- include “helpers.list-envZookeeperApp-variables” . | indent 10 }}’ include the variables and secrets of the values.yaml that configures the Docker image.
The next two sections have the deployment/service for Kafka. The ‘securityContext’ parameters are needed to make the Kafka image run as root. The memory is limited to ‘1G’ and the CPU is limited to ‘1.5’. The lines ‘env: {{- include “helpers.list-envKafkaApp-variables” . | indent 10 }}’ include the variables and secrets of the values.yaml that configures the Docker image. The service has a NodePort that enables access to port 9092 from the outside of the Kubernetes cluster.
The commands to set up/start the Minikube cluster can be found in the minikubeSetup.sh file.
The start command is: ‘minikube start –extra-config=apiserver.service-node-port-range=1024-65535’.
The Helm commands can be found in the helmCommand.sh file. The Helm deployment command is ‘helm install kafka ./kafka’ and uninstall command is ‘helm uninstall kafka’.
System Deployment
The system deployment is a combination of the Helm charts angularandspring and kafka. It deploys Kafka with Zookeeper and AngularAndSpring with MongoDB and provides a NodePort to access the AngularAndSpring UI. The Helm chart can be found in angularandspringwithkafka. The values.yaml and the _helpers.tpl are extended and the template.yaml is a combination of the other templates.
The values.yaml of the system deployment looks like this:
webAppName: angularandspring
dbName: mongodb
webImageName: angular2guy/angularandspring
webImageVersion: latest
dbImageName: mongo
dbImageVersion: 4.4
volumeClaimName: mongo-pv-claim
persistentVolumeName: mongo-pv-volume
kafkaName: kafkaapp
zookeeperName: zookeeperserver
kafkaImageName: bitnami/kafka
kafkaImageVersion: latest
zookeeperImageName: bitnami/zookeeper
zookeeperImageVersion: latest
kafkaServiceName: kafkaservice
zookeeperServiceName: zookeeperservice
secret:
name: app-env-secret
nameKafka: kafka-env-secret
nameZookeeper: zookeeper-env-secret
envApp:
normal:
MONGODB_HOST: mongodb
CPU_CONSTRAINT: true
SPRING_PROFILES_ACTIVE: prod
KAFKA_SERVICE_NAME: kafkaService
secret:
JWTTOKEN_SECRET: secret-key1234567890abcdefghijklmnopqrstuvwxyz
envZookeeper:
normal:
ALLOW_ANONYMOUS_LOGIN: yes
secret:
ZOOKEEPER_TICK_TIME: "2000"
envKafka:
normal:
KAFKA_BROKER_ID: "1"
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_CFG_LISTENERS: PLAINTEXT://:9092
KAFKA_CFG_ADVERTISED_LISTENERS: PLAINTEXT://:9092
KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE: false
ALLOW_PLAINTEXT_LISTENER: yes
secret:
KAFKA_ZOOKEEPER_CONNECT: "zookeeperservice:2181" In the first part are the Helm variables for AngularAndSpring/MongoDb/Storage defined. The Docker image names and versions are set and the persistentVolume/persistentVolumeClaim get a name.
In the next part are the Helm variables for Kafka/Zookeeper defined by the Docker image names and versions and the service names.
In the next part are the secrets for AngularAndSpring/Kafka/Zookeeper defined.
In the ‘envApp’/’envZookeeper’/’envKafka’ are the variables/secrets for the Docker image configurations defined.
The _helpers.tpl looks like this:
{{/*
Create envApp values
*/}}
{{- define "helpers.list-envApp-variables"}}
{{- $secretName := .Values.secret.name -}}
{{- range $key, $val := .Values.envApp.secret }}
- name: {{ $key }}
valueFrom:
secretKeyRef:
name: {{ $secretName }}
key: {{ $key }}
{{- end}}
{{- range $key, $val := .Values.envApp.normal }}
- name: {{ $key }}
value: {{ $val | quote }}
{{- end}}
{{- end }}
{{/*
Create envZookeeper values
*/}}
{{- define "helpers.list-envZookeeperApp-variables"}}
{{- $secretName := .Values.secret.nameZookeeper -}}
{{- range $key, $val := .Values.envZookeeper.secret }}
- name: {{ $key }}
valueFrom:
secretKeyRef:
name: {{ $secretName }}
key: {{ $key }}
{{- end}}
{{- range $key, $val := .Values.envZookeeper.normal }}
- name: {{ $key }}
value: {{ $val | quote }}
{{- end}}
{{- end }}
{{/*
Create envKafka values
*/}}
{{- define "helpers.list-envKafkaApp-variables"}}
{{- $secretName := .Values.secret.nameKafka -}}
{{- range $key, $val := .Values.envKafka.secret }}
- name: {{ $key }}
valueFrom:
secretKeyRef:
name: {{ $secretName }}
key: {{ $key }}
{{- end}}
{{- range $key, $val := .Values.envKafka.normal }}
- name: {{ $key }}
value: {{ $val | quote }}
{{- end}}
{{- end }}The script creates values and secrets for the AngularAndSpring/Zookeeper/Kafka deployments. The ‘helpers.list-envApp-variables’ is used as an example. The other scripts work similarly.
The ‘helpers.list-envApp-variables’ are defined.
The secret name is set and then the script iterates over the secret values. For each secret is a name and secretKeyRef with the name and key created. That provides the secret as an opaque configuration value to the Docker image.
Then script iterates over the normal values. For each value, a name and a value are created.
These values and the Secrets that are defined in the template.yaml are the Docker images configured.
Conclusion Deployment
The Kubernetes setup for development has created the basis to create the system deployment. If the Kafka version is released that does no longer need Zookeeper, Kafka can be started as a Docker image. The Helm chart can be extended to deploy/configure several systems. In this case 4 images. A Kafka cluster can get its own Helm chart for deployment and a central/scalable/fault-tolerant Kafka cluster can be used by the applications that have access to the cluster. Applications(Microservices) and their databases that depend on each other should be deployed together.
Opinions expressed by DZone contributors are their own.
Comments