On Some Aspects of Big Data Processing in Apache Spark, Part 1: Serialization
In this post, review the basics of how Apache Spark runs its jobs and discover how to avoid serialization errors.
Join the DZone community and get the full member experience.
Join For FreeMany beginner Spark programmers encounter a "Task not serializable" exception when they try to break their Spark applications into Java classes. There are a number of posts to instruct developers on how to solve this problem. Also, there are excellent overviews of Spark. Nonetheless, I think it is worthwhile to look at the Spark source code to see where and how tasks get serialized and such exceptions are thrown to better understand those instructions.
This post is organized as follows:
- In Section 1, I briefly review Spark architecture and Spark run modes.
- In Section 2, I review what RDD is and what operations we can do on it.
- In Section 3, I review how Spark creates a physical plan out of a logical plan.
- In Section 4, I demonstrate how a physical plan gets executed and where and how Spark tasks get serialized.
- Finally, in Section 5, I summarize all these as simple rules to avoid the exception.
Let's recall Spark architecture and terminology.
1. Spark Architecture and Run Modes
Apache Spark is a unified computing engine and a set of libraries for parallel data processing on computer clusters (for detailed exposition, consider "Spark in Action" by J-G Perrin and "Spark: The Definitive Guide" by D. Chambers and M. Zaharia). Algorithmically, parallel computations are done in jobs. A job consists of stages, and a stage consists of tasks. A task is an abstraction of the smallest individual unit of execution (more on these later).
In terms of software architecture, every Spark application consists of a Driver and a set of distributed worker processes (Executors) (see Fig 1). The Driver runs the main() method of our application and it is where a Spark Context (sc for brevity) is created. The Driver runs on a node in our cluster, or on our client, and schedules how jobs are executed with a Cluster Manager. Also, the Driver analyzes, schedules, and distributes work across the Executors.
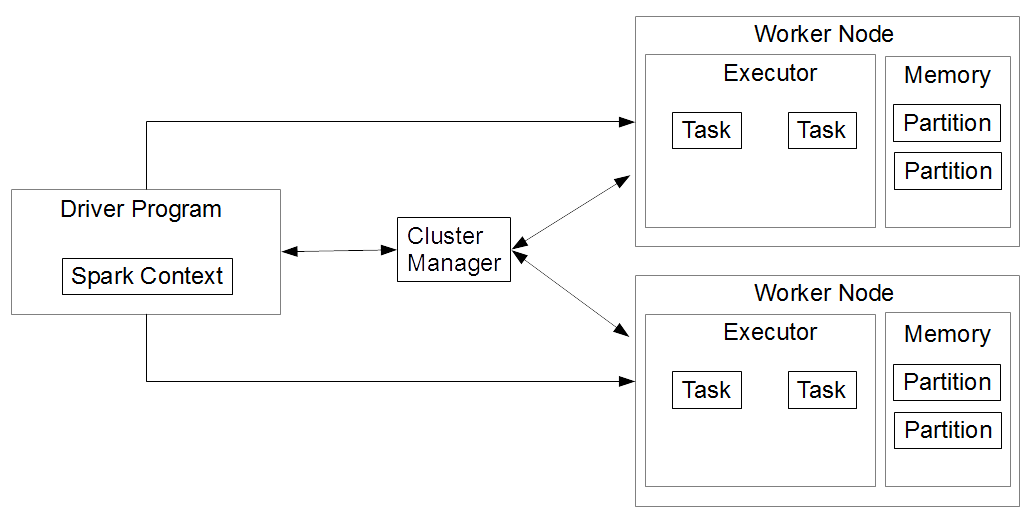
Fig 1: Spark architecture
The Executor is a distributed process to execute tasks. The Executors of every Spark application stay alive for the lifecycle of a Spark application. Executors process all the data of a Spark job. Also, Executors store results in memory and persist the results to a disk only when specifically instructed to do so by the Driver. Finally, Executors return computation results to the Driver. Each Worker Node may have one or more Executors.
To process a large amount of data, Spark divides the data into multiple partitions. To process data efficiently, Spark tries to do as many computations as possible on the same partition. When it is absolutely necessary to merge multiple partitions, Spark writes the partitions on the disk (more on this later).
A typical Spark application follows the following steps:
- The application initializes an instance of Spark Context.
- The Driver asks the Cluster Manager to allocate the necessary resources to run the application.
- The Cluster Manager launches the Executors.
- The Driver runs our Spark code.
- The Executors run the code and send the results back to the Driver.
- The Spark Context is stopped, all the Executors are shut down, and the Cluster manager reclaims the resources.
A Spark application can run in 3 modes: Local, Client, and Cluster. In Local mode, all Spark components run on a single machine. The mode achieves parallelism via threads on that single machine. In Client mode, the client machine maintains the Driver, and the cluster maintains the Executors. In Cluster mode, a user submits a jar file to a Cluster Manager. The manager then launches the Driver on a worker node, in addition to the Executor process.
To investigate how these components work and serialize tasks, let's review how Resilient Distributed Data Structure (RDD), the Spark primary data abstraction, functions internally.
2. RDD: The Primary Abstraction
According to the Spark source code docs, an RDD represents an immutable partitioned collection of elements that can be operated in parallel. The elements (or records) are just Java or Scala objects of the programmer's choosing. Datasets and DataFrames wrap RDDs. In contrast to RDDs, Datasets and DataFrames contain records, where each record is a structured row with a known schema.
Each RDD contains the following:
- A list of partitions (actually, partition indexes: the actual data, accessed by the indexes, is stored in every node)
- A function to compute each split (a split is a chunk of partitioned data in every node)
- A list of dependencies on other RDDs
- Optionally, a partitioner for key-value RDDs (not discussed here)
- Optionally, a list of preferred locations to compute each split (the same)
An RDD can do transformations and actions (Fig 2). A transformation accepts an RDD and returns another RDD. An action accepts an RDD and does not return an RDD. An action may, for example, save an RDD to a disk, or return the number of rows in an RDD. For example, the RDD.count() action returns the number of elements in an RDD. Internally the action calls the Spark context to initialize a new job:
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sumHere, the first argument is the current RDD, and the second is a function to process partitions. We discuss this in detail in later sections. Let's go back to transformations.

Fig 2: RDD operations
There are narrow and wide transformations. In a narrow transformation, all the data elements that are required to compute the records in a single partition are located in the single partition of the parent RDD. In a wide transformation, all the data elements that are required to compute the records in a single partition may live in many partitions of the parent RDD so the partitions need to be shuffled to complete the transformation. Transformations are lazy: they get executed only when we call an action. Let us see how an RDD transformation works under the hood.
All RDDs extend an abstract class RDD. This class contains the basic operations available to all RDDs. Let's see, for example, how the RDD.map(...) method works (Fig 3). Let our rddIn be a collection of strings (each composed of words with a " " delimeter). We want to map this collection to a collection rddOut = rddIn.map(x->x.split(" ").length).

Fig 3: Some RDD operations
When an RDD.map(f) where f=x->x.split(" ").length is called, the Spark Context cleans the callback f (Fig 3A). According to SparkContext.scala docs, sc.clean(f) cleans the callback's closure and makes the callback ready to be serialized and sent to tasks. The cleaner removes unused variables from the callback's outer scope and updates REPL variables (command-line variables; not our concern in this post). sc.clean(f) calls ClosureCleaner.ensureSerializable(f). It is there where a dreaded "Task not serializable" exception may be thrown (Fig 3C).
If the callback is serializable, rddIn.map(f) returns rddOut = new MapPartitionsRDD(rddIn, f), where rddIn becomes the parent RDD of rddOut. rddOut.compute method executes the callback f on rddIn (the parent RDD of rddOut; Fig 3B). The transformation is complete.
So far, we see that a Spark application throws a "Task not serializable" exception only if a transformation callback and the callback's closure are not serializable. It follows that, if we split a Spark job into POJOs, the job runs without the exception, even if the POJOs' fields are not serializable, as long as the non-serializable fields do not interfere with transformation callbacks and their closures.
It is easy to see how multiple transformations form up into a Direct Acyclic Graph. Every transformation creates a new RDD, where the parent RDD is the one being transformed. Actions that produce no RDD are leaves of the DAG. Such a DAG of RDDs is called a Logical Execution Plan (see "RDD Lineage — Logical Execution Plan" by Jacek Laskowski for details and more examples). Let's proceed down the road to see how a physical execution plan gets created from a logical plan to check if the formulated serialization rule holds.
3. Physical Plan: Jobs, Stages, and Tasks
To compute a logical plan, the Driver creates a set of jobs, stages, and tasks out of the logical plan. Such a set is called a Physical Execution Plan. What are jobs, stages, and tasks? Let's start with the job.
The actual job class is called ActiveJob (Fig 4). The class has a jobId: Int, a finalStage: Stage, a listener: JobListener, and some other fields. Jobs are only tracked for "leaf" (or final) stages (and no RDDs) of the computational process (more on this later). There are two kinds of stages.
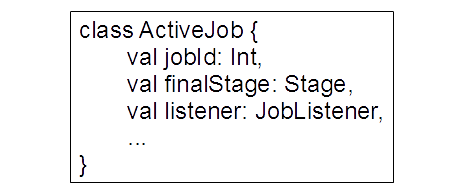
Fig 4: ActiveJob class (other fields and methods are omitted for brevity)
The first kind of Stage is called ShuffleMapStageand the second one is ResultStage. The difference between the two stages is illustrated in Fig 5 (see "What is Spark's Shuffle" for details). Here, the system uploads data from Database 1 into 3 partitions. Then the data undergoes a narrow transform (map), then a wide transform (reduceByKey). Finally, the transformed data is saved to another Database 2. So, the transformations are included in the ShuffleMapStage, where the stage ends on the wide (or shuffle) transformation. On the other hand, the ResultStage is composed of a single action: save.
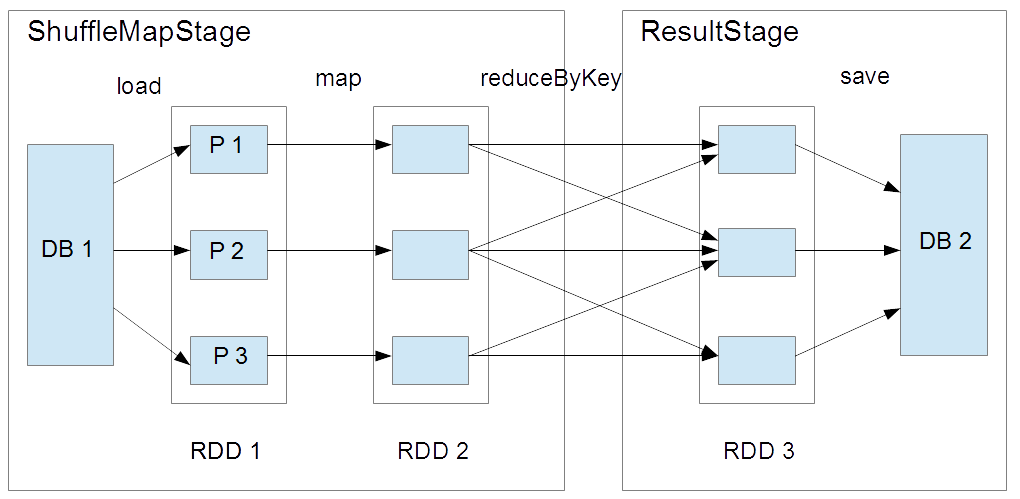
Fig 5: Example of a simple two-stage Spark job
Let's take a look at a ShuffleMapStage (Fig 6). According to the source code docs:
"ShuffleMapStages are intermediate stages in the execution DAG that produce data for a shuffle. They occur right before each shuffle operation, and might contain multiple pipelined operations before that (e.g. map and filter). When executed, they save map output files that can later be fetched by reduce tasks. The 'shuffleDep' field describes the shuffle each stage is part of."
The dependency contains a parent RDD, a serializer, an aggregator, a writeProcessor, etc. (the methods needed to complete the stage). Also, the stage contains id:Int, rdd: RDD, and parent stages parents: List[Stage] , mapStageJobs: Seq[ActiveJob]. This stage can be called by multiple jobs.

Fig 6: Spark Stages (other fields, methods, and the Stage constructor arguments are omitted for brevity)
For a ResultStage (Fig 6), the ResultStage source code docs say:
"ResultStages apply a function on some partitions of an RDD to compute the result of an action. The ResultStage object captures the function to execute, 'func,' which will be applied to each partition, and the set of partition IDs, 'partitions.' Some stages may not run on all partitions of the RDD, for actions like first() and lookup()."
Also, the stage contains id:Int, partitions: Array[Int] (these are partition indexes) , rdd: RDD, and parent stages parents: List[Stage] , activeJob: ActiveJob (the active job for this result stage). Finally, there is the mentioned func: (TaskContext, Iterator[_]) => _ to apply on each partition. Notice that neither stages nor jobs directly refer to any tasks.
There are two kinds of tasks - ShuffleMapTask and ResultTask (Fig 7). According to the ShuffleMapTask source code docs:
"A ShuffleMapTask divides the elements of an RDD into multiple buckets (based on a partitioner specified in the ShuffleDependency)."
A ResultTask sends back the task output to the driver application. Both tasks have a stageId: Int, taskBinary: Broadcast[Array[Byte]], a binary to execute, and partition: Partition, the partition the task is associated with. A ResultTask also has an outputId: Int field, the index of the task in its job. See "The Internals of Apache Spark 3.3.0" for more details of these elements.
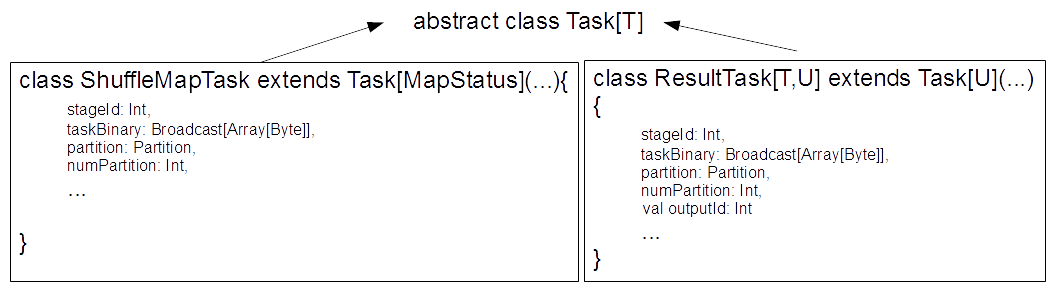
Fig 7: Spark Tasks (other fields, methods, and Task constructor arguments are omitted for brevity)
To answer our serialization question, we need to investigate how this taskBinary is produced by the Driver, as the Driver creates tasks out of a logical plan.
4. Job Execution
In Section 2, we saw a simple example of how RDD.count() action calls the spark context (SC) to initiate a new job. Let's see what happens next in a general case (Fig 8).

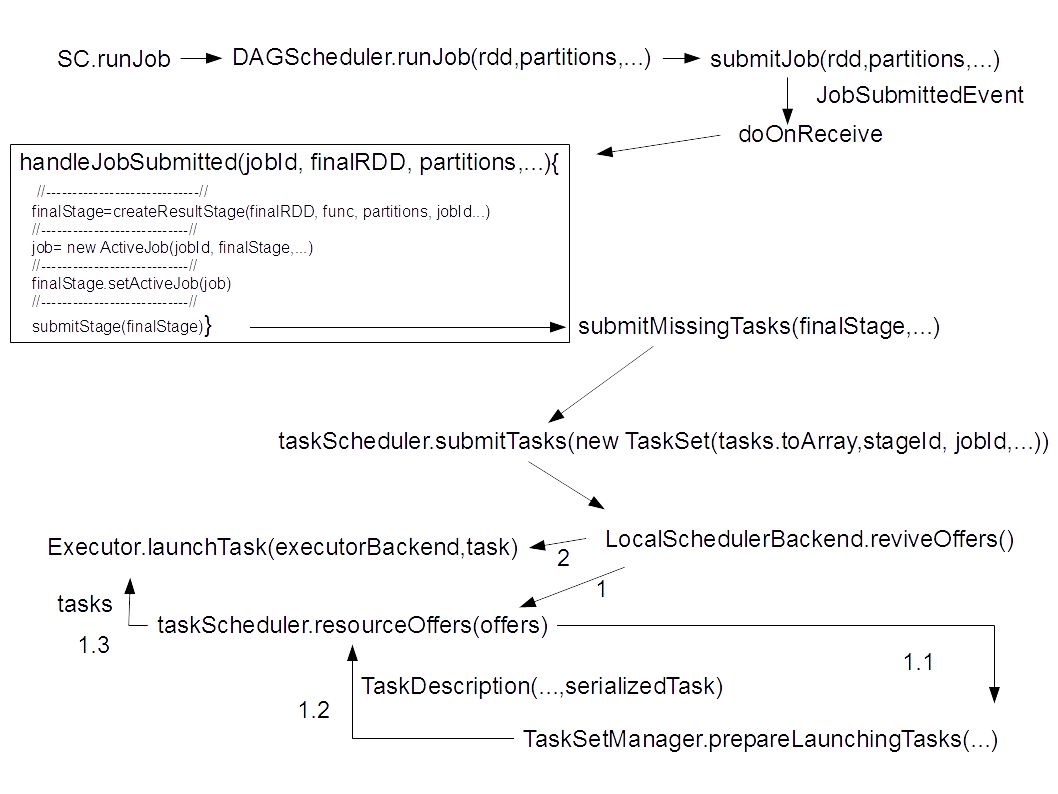
Fig 8. Spark job workflow (omitted method arguments are (...), omitted pieces of code are //---//)
So, the SC calls DAGScheduler.runJob(rdd, func, partitions: Seq[Int],...), where the func processes the partitions. Then the DAGScheduler calls submitJob with the same rdd, func, and partitions. Next, the submitJob method issues a JobSubmittedEvent: the event gets caught in doOnReceive listener. The listener calls handleJobSubmitted method with the same rdd, func, and partitions. It is in this method that a final stage is created, and a new ActiveJob is created from this stage. Next, the final stage is submitted to the submitStage method. This method, in turn, recursively calls the submitMissingTasks(finalStage,..)method on all the parent stages up the logical plan. It is here, where the tasks are created.
The DAGScheduler.submitMissingTasks method creates taskBinary out of stage RDDs and stage procession functions (Fig 9A). For this, the method calls closureSerialer.serialize(stage.rdd, stage.func), where closureSerializer is our familiar SparkEnv.get.closureSerializer.newInstance().
 Fig 9: submitMissedTasks and launchTasks methods (omitted method arguments are (...) and omitted pieces of code are //--//)
Fig 9: submitMissedTasks and launchTasks methods (omitted method arguments are (...) and omitted pieces of code are //--//)
As we already saw, the serializer doesn't throw a "task not serialized exception" if the operation callback and its closure are serializable. After the task is serialized, the submitMissingTasks method creates a TaskSet out of these taskBinary, and submits the set to a taskScheduler (Fig 8).
Next, I describe what happens in the local mode. The taskScheduler.submitTasks calls localSchedulerBackend.reviveOffers() to call TaskSetManager.prepareLaunchingTasks(...) to create a TaskDescription. The description contains serializedTask: ByteBuffer and data to run the task. Finally, these taskDescriptions are submitted to Executor.launchTask(executorBackend.task).
On the Executor side (Fig 9B), the Executor creates an instance of TaskRunner with the submitted taskDescription. The task runner is executed in the Spark thread pool. This is it! Let's summarize what we learned about Spark serialization.
5. Task Serialization in Spark
So, we see that to do computations on RDDs, Spark Driver serializes two things: the RDD data and the RDD operation (transformation or action) callback (and the callback's closure). You may wish to refer again to this article's first linked post by Michael Knopf about how JVM treats closures and serializes objects. Obviously, the data should be serializable. As for the callback (and its closure), we may need Spark tools to do CRUD operations on the data. The tools include: SparkSession, SparkContext, HadoopConfiguration, HiveContext, etc. Of these objects, only SparkSession is serializable and can be set as a class field in custom POJOs. How do we use the other tools practically, then?
One way is to use them as local variables inside class methods. For example:
Dataset<Row> transform(Dataset<Row> ds){
SparkContext sparkContext = this.sparkSession.sparkContext();
HiveContext hiveContext = new HiveContext(sparkContext);
JavaRDD<Row> resultRDD = //transformations that use the hiveContext go here
return resultRDD.toDS();
} Yes, the variables are created every time the method is called, but this way we get rid of a "task not serializable" exception. Also, some of the configurations may be serializable via SerializableConfiguration utility.
Notice, that sometimes you may have a POJO with non-serializable fields, like SparkContext, and the application still runs. For example, data is simply uploaded from one database and saved into another without any transformation. The application runs fine because there are no transformation or action callbacks to serialize!
So, the serialization rules are:
- Use non-serializable objects as local variables inside POJO methods.
- In lambda-expressions, don't refer to non-serializable objects, since the Driver will try to serialize those objects to build a closure.
- If possible, serialize objects via SerializableConfiguration-like utilities.
Check other more exotic Spark serialization rules.
Conclusions
In this post, I demonstrated how Spark serializes tasks to execute them. I listed simple rules to avoid a "task not serializable" exception. Also, I presented a situation where a Spark application may work even with non-serializable POJO fields. Hope to see you in Part 2, where I present design patterns to construct Spark applications in a flexible and maintainable way.
Opinions expressed by DZone contributors are their own.
Comments