Data Storage Formats for Big Data Analytics: Performance and Cost Implications of Parquet, Avro, and ORC
This article compares the performance and cost efficiency of three storage formats Parquet, Avro, and ORC on Google Cloud Platform.
Join the DZone community and get the full member experience.
Join For FreeEfficient data processing is crucial for businesses and organizations that rely on big data analytics to make informed decisions. One key factor that significantly affects the performance of data processing is the storage format of the data. This article explores the impact of different storage formats, specifically Parquet, Avro, and ORC on query performance and costs in big data environments on Google Cloud Platform (GCP). This article provides benchmarks, discusses cost implications, and offers recommendations on selecting the appropriate format based on specific use cases.
Introduction to Storage Formats in Big Data
Data storage formats are the backbone of any big data processing environment. They define how data is stored, read, and written directly impacting storage efficiency, query performance, and data retrieval speeds. In the big data ecosystem, columnar formats like Parquet and ORC and row-based formats like Avro are widely used due to their optimized performance for specific types of queries and processing tasks.
- Parquet: Parquet is a columnar storage format optimized for read-heavy operations and analytics. It is highly efficient in terms of compression and encoding, making it ideal for scenarios where read performance and storage efficiency are prioritized.
- Avro: Avro is a row-based storage format designed for data serialization. It is known for its schema evolution capabilities and is often used for write-heavy operations where data needs to be serialized and deserialized quickly.
- ORC (Optimized Row Columnar): ORC is a columnar storage format similar to Parquet but optimized for both read and write operations, ORC is highly efficient in terms of compression, which reduces storage costs and speeds up data retrieval.
Research Objective
The primary objective of this research is to assess how different storage formats (Parquet, Avro, ORC) affect query performance and costs in big data environments. This article aims to provide benchmarks based on various query types and data volumes to help data engineers and architects choose the most suitable format for their specific use cases.
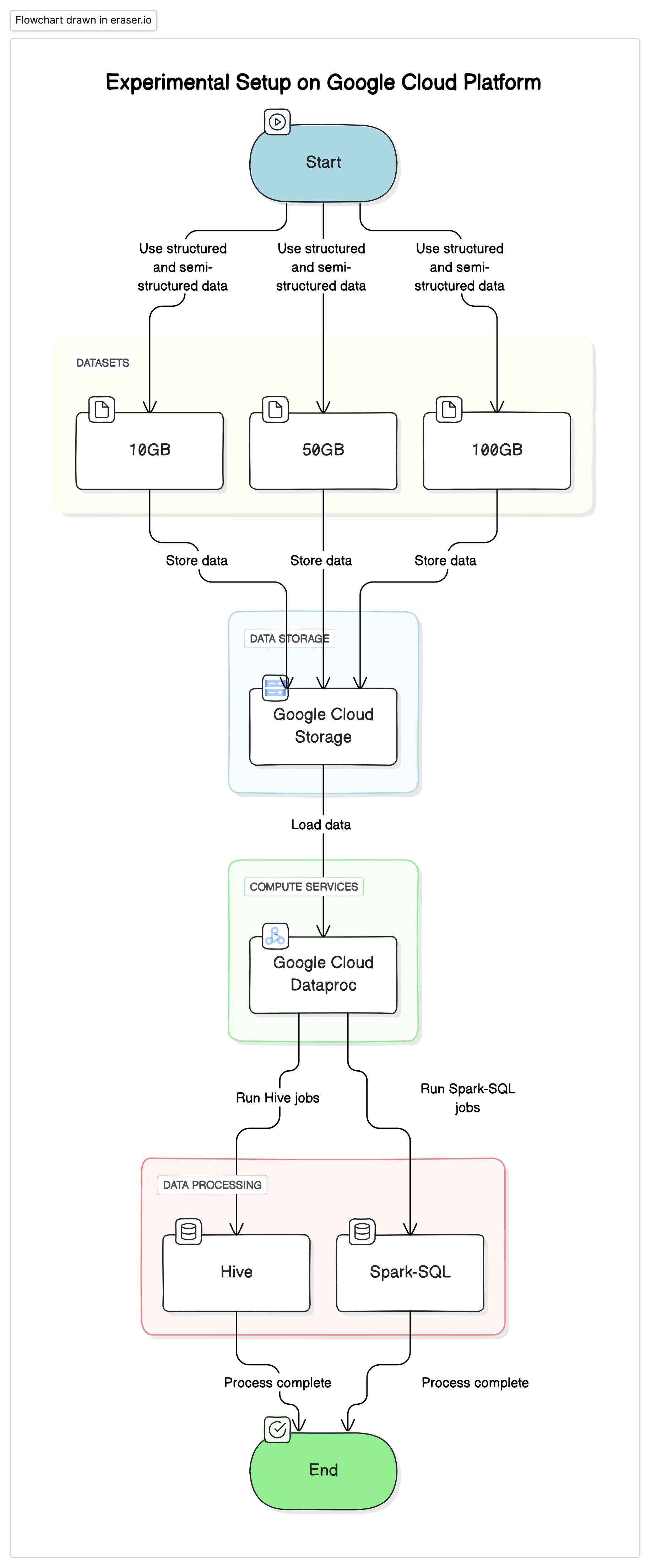
Experimental Setup
To conduct this research, we used a standardized setup on Google Cloud Platform (GCP) with Google Cloud Storage as the data repository and Google Cloud Dataproc for running Hive and Spark-SQL jobs. The data used in the experiments was a mix of structured and semi-structured datasets to mimic real-world scenarios.
Key Components
- Google Cloud Storage: Used to store the datasets in different formats (Parquet, Avro, ORC)
- Google Cloud Dataproc: A managed Apache Hadoop and Apache Spark service used to run Hive and Spark-SQL jobs.
- Datasets: Three datasets of varying sizes (10GB, 50GB, 100GB) with mixed data types.
# Initialize PySpark and set up Google Cloud Storage as file system
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("BigDataQueryPerformance") \
.config("spark.jars.packages", "com.google.cloud.bigdataoss:gcs-connector:hadoop3-2.2.5") \
.getOrCreate()
# Configure the access to Google Cloud Storage
spark.conf.set("fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem")
spark.conf.set("fs.gs.auth.service.account.enable", "true")
spark.conf.set("google.cloud.auth.service.account.json.keyfile", "/path/to/your-service-account-file.json")Test Queries
- Simple SELECT queries: Basic retrieval of all columns from a table
- Filter queries: SELECT queries with WHERE clauses to filter specific rows
- Aggregation queries: Queries involving GROUP BY and aggregate functions like SUM, AVG, etc..
- Join queries: Queries joining two or more tables on a common key
Results and Analysis
1. Simple SELECT Queries
- Parquet: It performed exceptionally well due to its columnar storage format, which allowed for fast scanning of specific columns. Parquet files are highly compressed, reducing the amount of data read from disk, which resulted in faster query execution times.
# Simple SELECT query on Parquet file
parquet_df.select("column1", "column2").show()- Avro: Avro performed moderately well. Being a row-based format, Avro required reading the entire row, even when only specific columns were needed. This increases the I/O operations, leading to slower query performance compared to Parquet and ORC.
-- Simple SELECT query on Avro file in Hive
CREATE EXTERNAL TABLE avro_table
STORED AS AVRO
LOCATION 'gs://your-bucket/dataset.avro';
SELECT column1, column2 FROM avro_table;- ORC: ORC showed similar performance to Parquet, with slightly better compression and optimized storage techniques that enhanced read speeds. ORC files are also columnar, making them suitable for SELECT queries that only retrieve specific columns.
# Simple SELECT query on ORC file
orc_df.select("column1", "column2").show()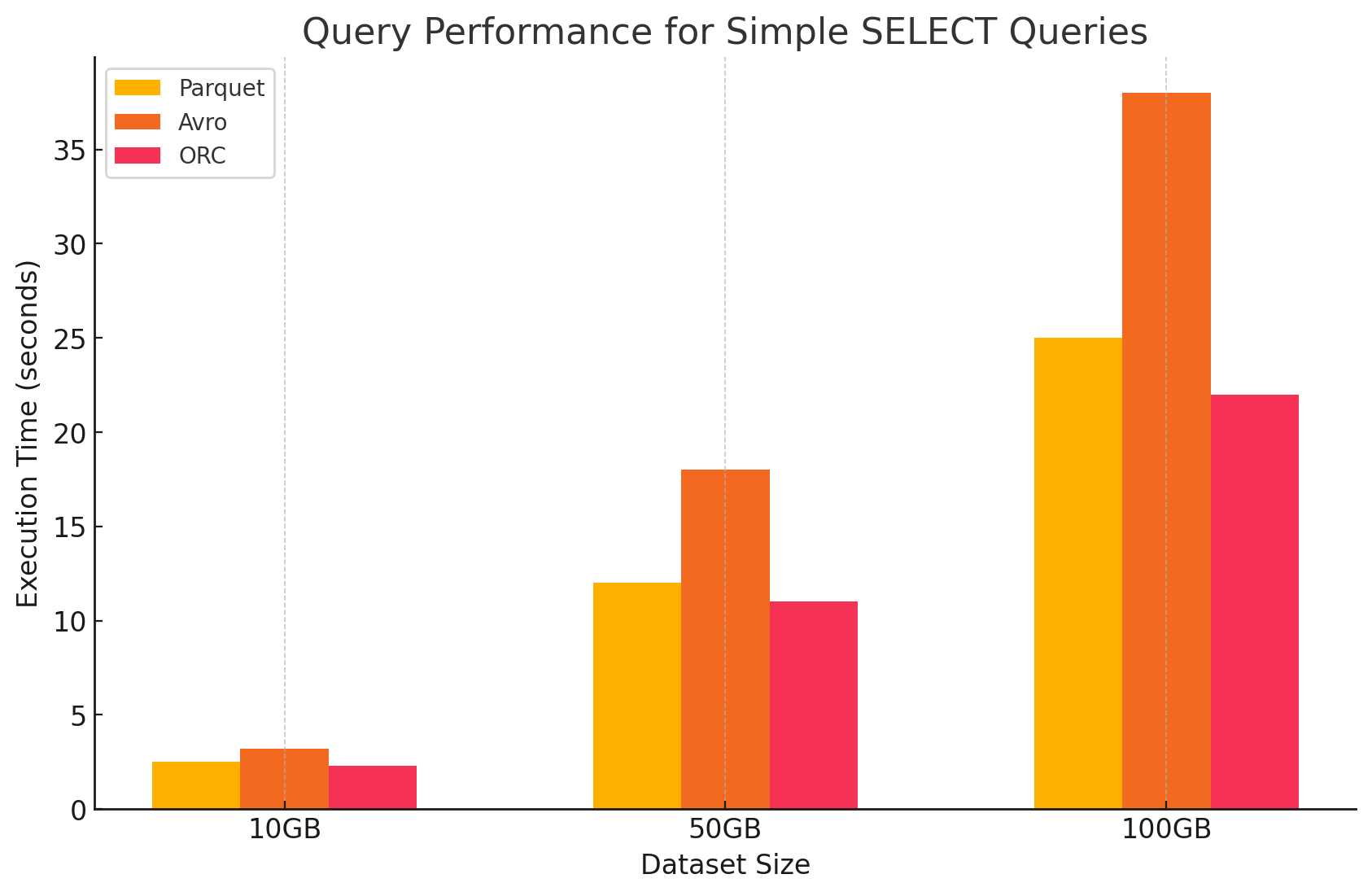
2. Filter Queries
- Parquet: Parquet maintained its performance advantage due to its columnar nature and the ability to skip irrelevant columns quickly. However, performance was slightly impacted by the need to scan more rows to apply filters.
# Filter query on Parquet file
filtered_parquet_df = parquet_df.filter(parquet_df.column1 == 'some_value')
filtered_parquet_df.show()- Avro: The performance decreased further due to the need to read entire rows and apply filters across all columns, increasing processing time.
-- Filter query on Avro file in Hive
SELECT * FROM avro_table WHERE column1 = 'some_value';- ORC: This outperformed Parquet slightly in filter queries due to its predicate pushdown feature, which allows filtering directly at the storage level before the data is loaded into memory.
# Filter query on ORC file
filtered_orc_df = orc_df.filter(orc_df.column1 == 'some_value')
filtered_orc_df.show()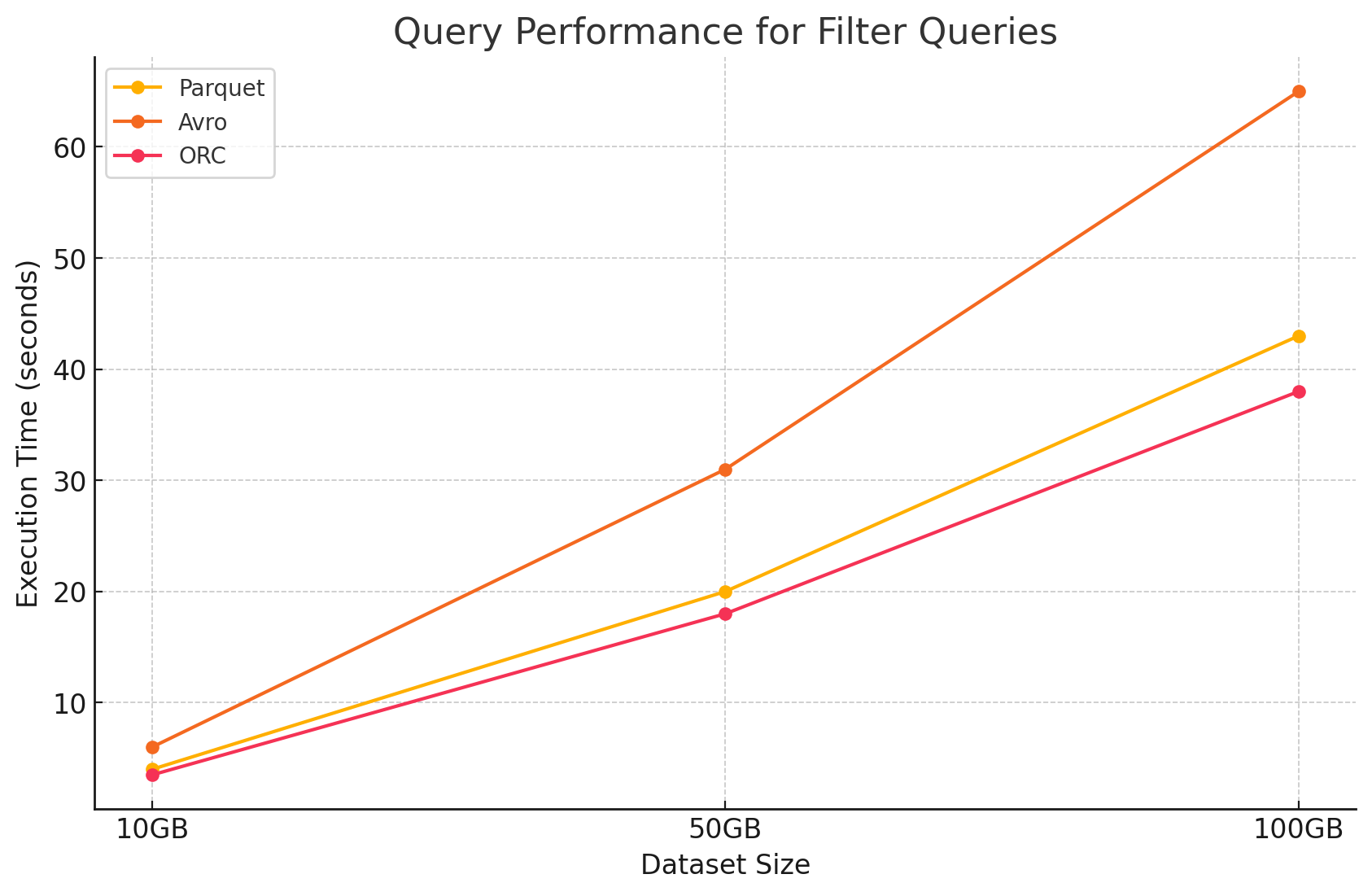
3. Aggregation Queries
- Parquet: Parquet performed well, but slightly less efficient than ORC. The columnar format benefits aggregation operations by quickly accessing required columns, but Parquet lacks some of the built-in optimizations that ORC offers.
# Aggregation query on Parquet file
agg_parquet_df = parquet_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_parquet_df.show()- Avro: Avro lagged behind due to its row-based storage, which required scanning and processing all columns for each row, increasing the computational overhead.
-- Aggregation query on Avro file in Hive
SELECT column1, SUM(column2), AVG(column3) FROM avro_table GROUP BY column1;- ORC: ORC outperformed both Parquet and Avro in aggregation queries. ORC's advanced indexing and built-in compression algorithms enabled faster data access and reduced I/O operations, making it highly suitable for aggregation tasks.
# Aggregation query on ORC file
agg_orc_df = orc_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_orc_df.show()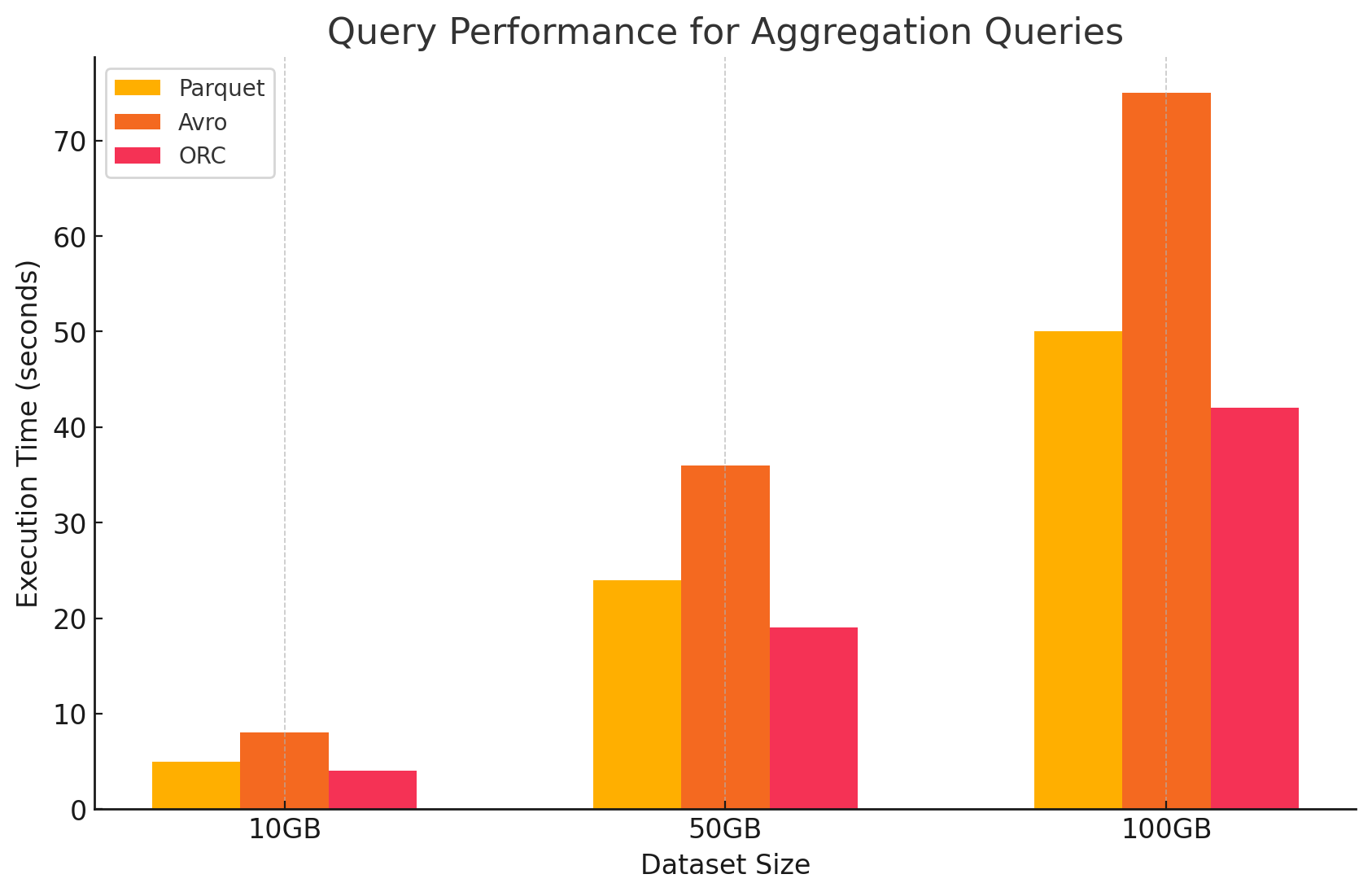
4. Join Queries
- Parquet: Parquet performed well, but not as efficiently as ORC in join operations due to its less optimized data reading for join conditions.
# Join query between Parquet and ORC files
joined_df = parquet_df.join(orc_df, parquet_df.key == orc_df.key)
joined_df.show()- ORC: ORC excelled in join queries, benefitting from advanced indexing and predicate pushdown capabilities, which minimized data scanned and processed during join operations.
# Join query between two ORC files
joined_orc_df = orc_df.join(other_orc_df, orc_df.key == other_orc_df.key)
joined_orc_df.show()- Avro: Avro struggled significantly with join operations, primarily due to the high overhead of reading full rows and the lack of columnar optimizations for join keys.
-- Join query between Parquet and Avro files in Hive
SELECT a.column1, b.column2
FROM parquet_table a
JOIN avro_table b
ON a.key = b.key;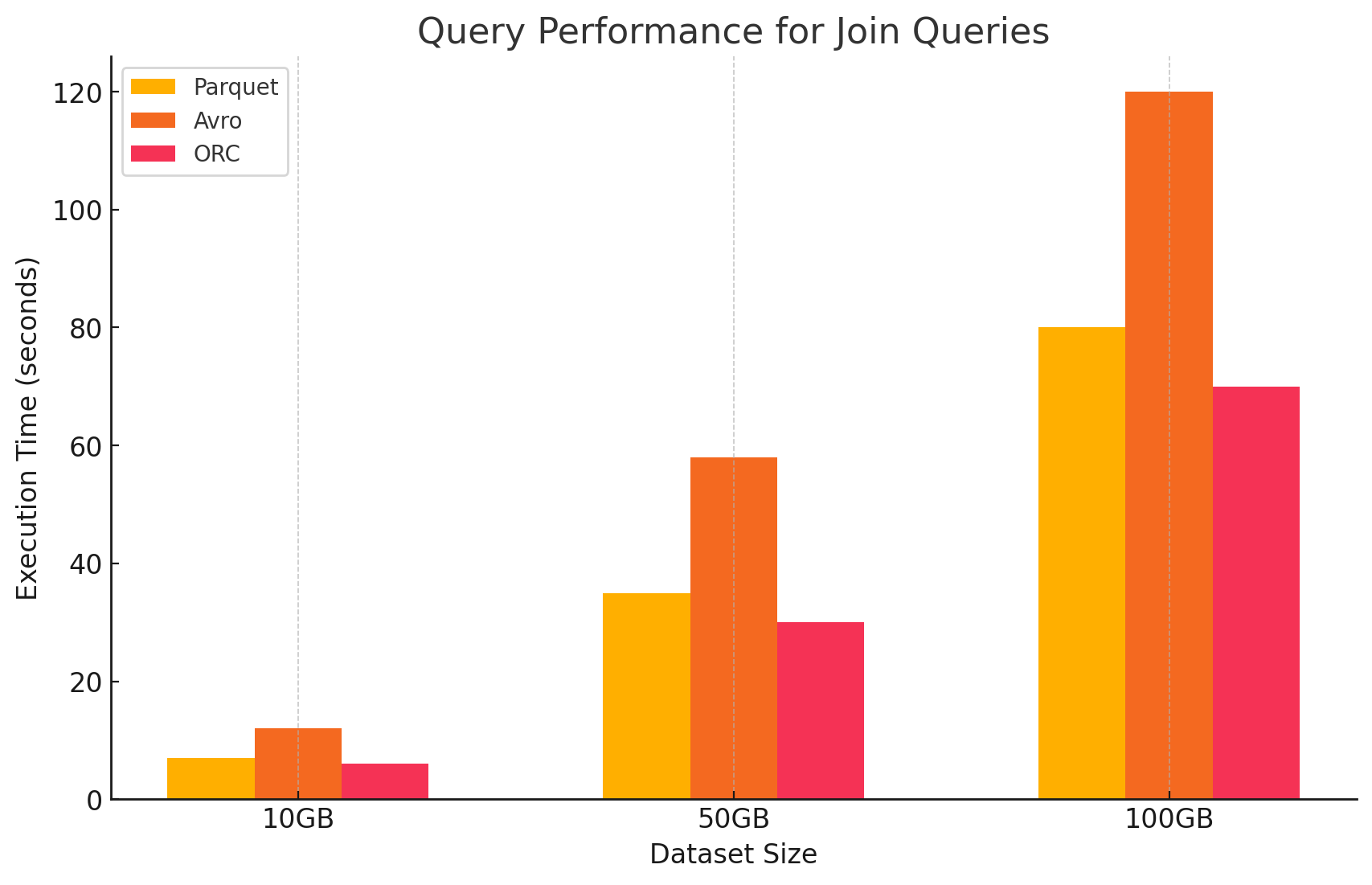
Impact of Storage Format on Costs
1. Storage Efficiency and Cost
- Parquet and ORC (columnar formats)
- Compression and storage cost: Both Parquet and ORC are columnar storage formats that offer high compression ratios, especially for datasets with many repetitive or similar values within columns. This high compression reduces the overall data size, which in turn lowers storage costs, particularly in cloud environments where storage is billed per GB.
- Optimal for analytics workloads: Due to their columnar nature, these formats are ideal for analytical workloads where only specific columns are frequently queried. This means less data is read from storage, reducing both I/O operations and associated costs.
- Avro (row-based format)
- Compression and storage cost: Avro typically provides lower compression ratios than columnar formats like Parquet and ORC because it stores data row by row. This can lead to higher storage costs, especially for large datasets with many columns, as all data in a row must be read, even if only a few columns are needed.
- Better for write-heavy workloads: While Avro might result in higher storage costs due to lower compression, it is better suited for write-heavy workloads where data is continuously being written or appended. The cost associated with storage may be offset by the efficiency gains in data serialization and deserialization.
2. Data Processing Performance and Cost
- Parquet and ORC (columnar formats)
- Reduced processing costs: These formats are optimized for read-heavy operations, which makes them highly efficient for querying large datasets. Because they allow reading only the relevant columns needed for a query, they reduce the amount of data processed. This leads to lower CPU usage and faster query execution times, which can significantly reduce computational costs in a cloud environment where compute resources are billed based on usage.
- Advanced features for cost optimization: ORC, in particular, includes features like predicate push-down and built-in statistics, which enable the query engine to skip reading unnecessary data. This further reduces I/O operations and speeds up query performance, optimizing costs.
- Avro (row-based formats)
- Higher processing costs: Since Avro is a row-based format, it generally requires more I/O operations to read entire rows even when only a few columns are needed. This can lead to increased computational costs due to higher CPU usage and longer query execution times, especially in read-heavy environments.
- Efficient for streaming and serialization: Despite higher processing costs for queries, Avro is well suited for streaming and serialization tasks where fast write speeds and schema evolution are more critical.
3. Cost Analysis With Pricing details
- To quantify the cost impact of each storage format, we conducted an experiment using GCP. We calculated the costs associated with both storage and data processing for each format based on GCP's pricing models.
- Google Cloud storage costs
- Storage cost: This is calculated based on the amount of data stored in each format. GCP charges per GB per month for data stored in Google Cloud Storage. Compression ratios achieved by each format directly impact these costs. Columnar formats like Parquet and ORC typically have better compression ratios than row-based formats like Avro, resulting in lower storage costs.
- Here is a sample of how storage costs were calculated:
- Parquet: High compression resulted in reduced data size, lowering storage costs
- ORC: Similar to Parquet, ORC's advanced compression also reduced storage costs effectively
- Avro: Lower compression efficiency led to higher storage costs compared to Parquet and ORC
# Example of how to save data back to Google Cloud Storage in different formats
# Save DataFrame as Parque
parquet_df.write.parquet("gs://your-bucket/output_parquet")
# Save DataFrame as Avro
avro_df.write.format("avro").save("gs://your-bucket/output_avro")
# Save DataFrame as ORC
orc_df.write.orc("gs://your-bucket/output_orc")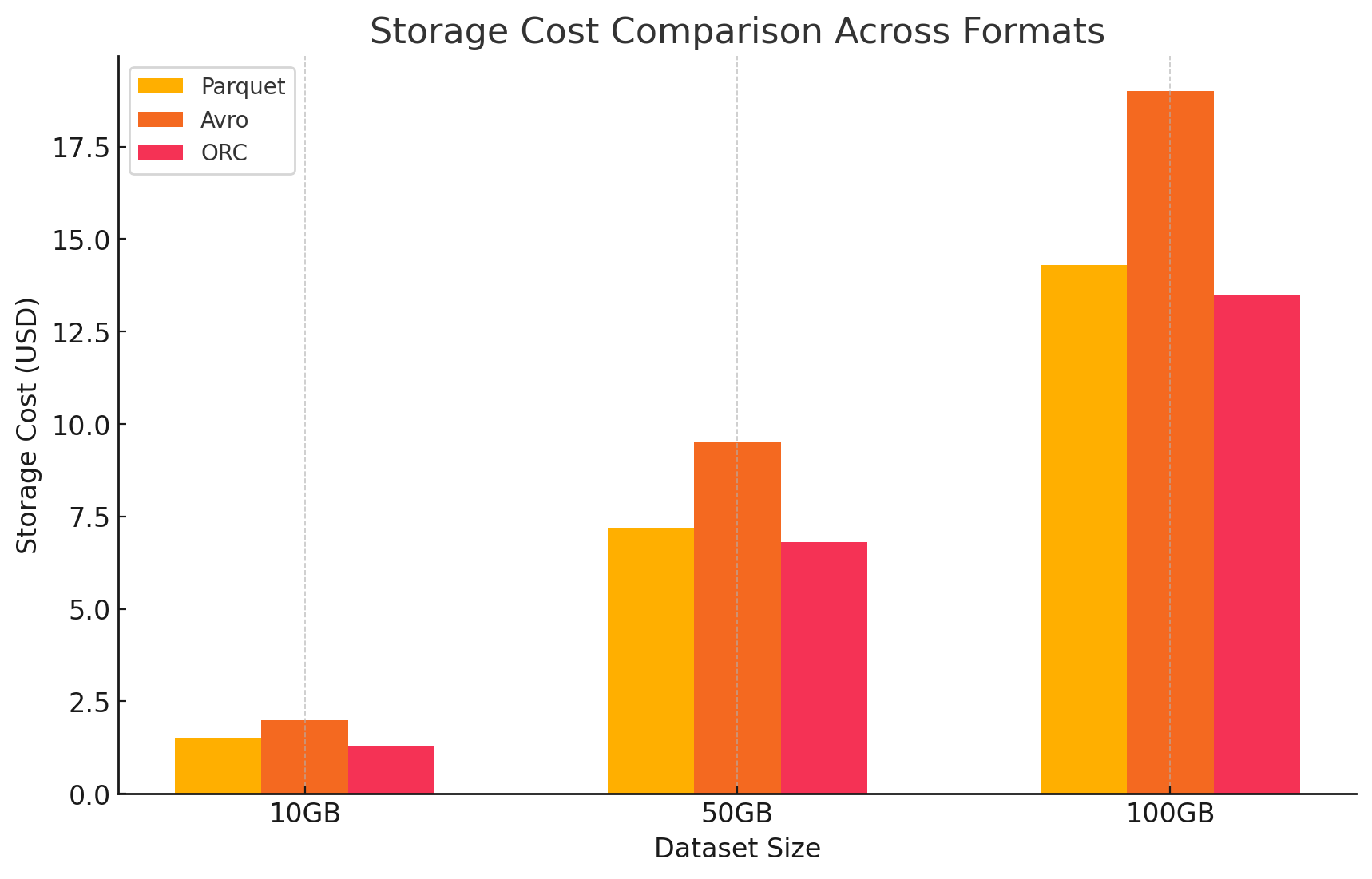
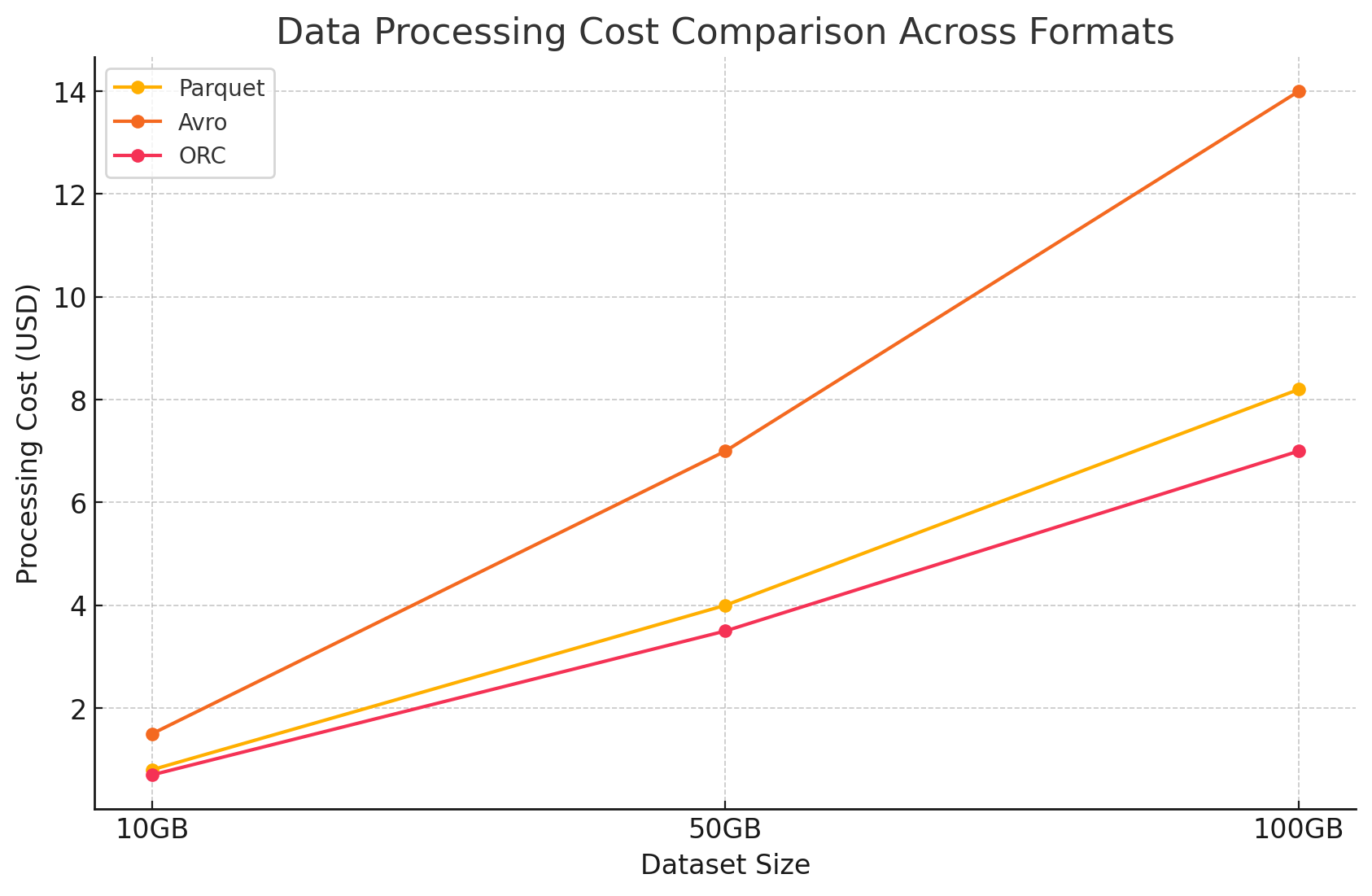
- Data processing costs
- Data processing costs were calculated based on the compute resources required to perform various queries using Dataproc on GCP. GCP charges for dataproc usage based on the size of the cluster and the duration for which the resources are used.
- Compute costs:
- Parquet and ORC: Due to their efficient columnar storage, these formats reduced the amount of data read and processed, leading to lower compute costs. Faster query execution times also contributed to cost savings, especially for complex queries involving large datasets.
- Avro: Avro required more compute resources due to its row-based format, which increased the amount of data read and processed. This led to higher costs, particularly for read-heavy operations.
![Data processing cost comparison across formats]()
Conclusion
The choice of storage format in big data environments significantly impacts both query performance and cost. The above research and experiment demonstrate the following key points:
- Parquet and ORC: These columnar formats provide excellent compression, which reduces storage costs. Their ability to efficiently read only the necessary columns greatly enhances query performance and reduces data processing costs. ORC slightly outperforms Parquet in certain query types due to its advanced indexing and optimization features, making it an excellent choice for mixed workloads that require both high read and write performance.
- Avro: While Avro is not as efficient in terms of compression and query performance as Parquet and ORC, it excels in use cases requiring fast write operations and schema evolution. This format is ideal for scenarios involving data serialization and streaming where write performance and flexibility are prioritized over read efficiency.
- Cost efficiency: In a cloud environment like GCP, where costs are closely tied to storage and compute usage, choosing the right format can lead to significant cost savings. For analytics workloads that are predominantly read-heavy, Parquet and ORC are the most cost-effective options. For applications that require rapid data ingestion and flexible schema management, Avro is a suitable choice despite its higher storage and compute costs.
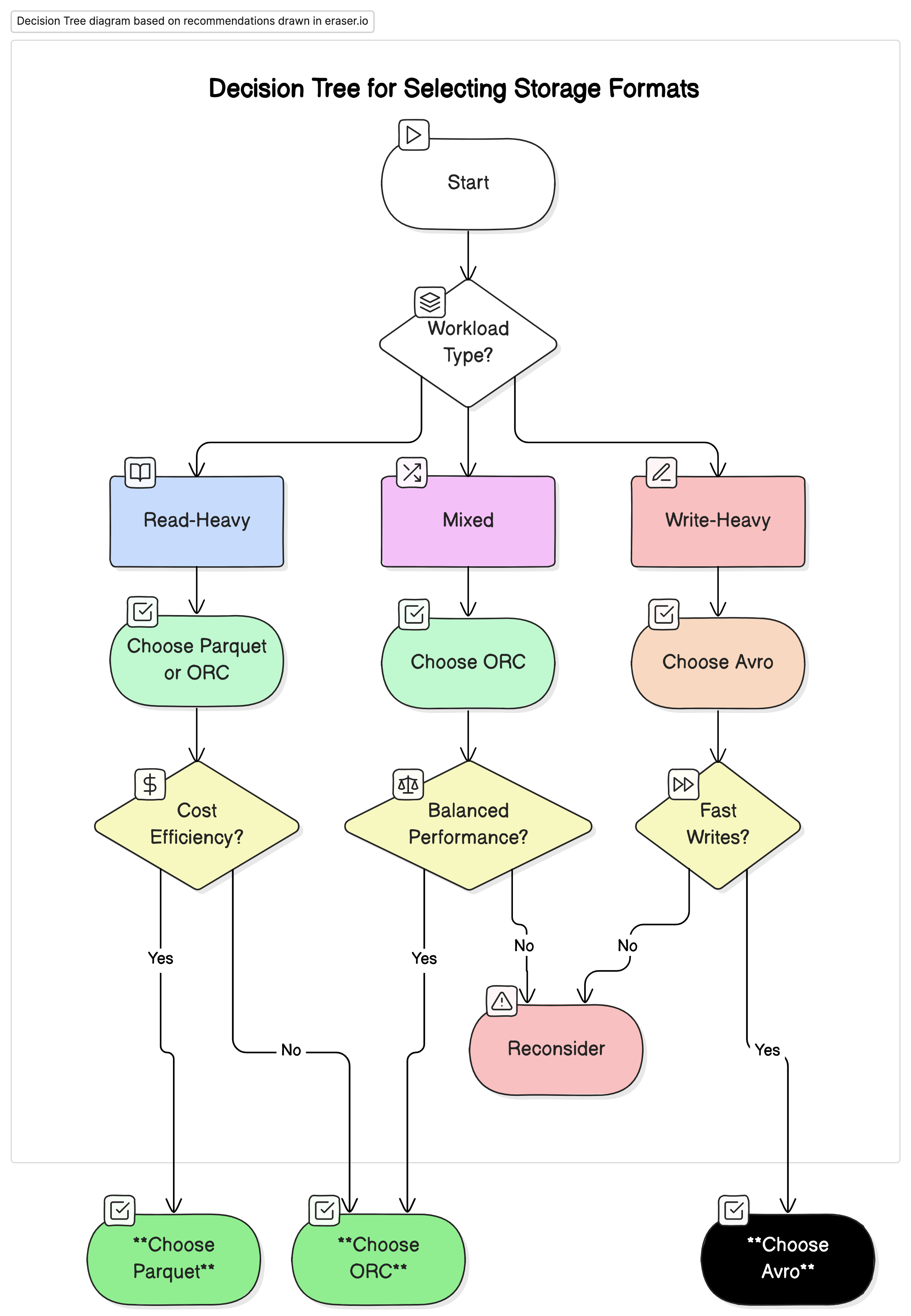
Recommendations
Based on our analysis, we recommend the following:
- For read-heavy analytical workloads: Use Parquet or ORC. These formats provide superior performance and cost efficiency due to their high compression and optimized query performance.
- For write-heavy workloads and serialization: Use Avro. It is better suited for scenarios where fast writes and schema evolution are critical, such as data streaming and messaging systems.
- For mixed workloads: ORC offers balanced performance for both read and write operations, making it an ideal choice for environments where data workloads vary.
Final Thoughts
Selecting the right storage format for big data environments is crucial for optimizing both performance and cost. Understanding the strengths and weaknesses of each format allows data engineers to tailor their data architecture to specific use cases, maximizing efficiency and minimizing expenses. As data volumes continue to grow, making informed decisions about storage formats will become increasingly important for maintaining scalable and cost-effective data solutions.
By carefully evaluating the performance benchmarks and cost implications presented in this article, organizations can choose the storage format that best aligns with their operational needs and financial goals.
Opinions expressed by DZone contributors are their own.
Comments