NiFi In-Memory Processing
This article provides a brief introduction to NiFi in-memory processing as well as how to configure the data flow and some use cases.
Join the DZone community and get the full member experience.
Join For FreeApache NiFi is an easy-to-use, powerful, highly available, and reliable system to process and distribute data. Made for data flow between source and target systems, it is a simple robust tool to process data from various sources and targets (find more on GitHub). NiFi has 3 repositories:
- FlowFile Repository: Stores the metadata of the FlowFiles during the active flow
- Content Repository: Holds the actual content of the FlowFiles
- Provenance Repository: Stores the snapshots of the FlowFiles in each processor; with that, it outlines a detailed data flow and the changes in each processor and allows an in-depth discovery of the chain of events
NiFi Registry is a stand-alone sub-project of NiFi that allows version control of NiFi. It allows saving FlowFile state and sharing FlowFiles between NiFi applications. Primarily used to version control the code written in Nifi.
General Setup and Usage
As data flows from the source to the target, the data and metadata of the FlowFile reside in the FlowFile and content repositories. NiFi stores all FlowFile content on disk to ensure resilience across restarts. It also provides backpressure to prevent data consumers/sources from overwhelming the system if the target is unable to keep up for some time.
For example, ConsumeKafka receives data as a FlowFile in NiFi (through the ConsumeKafka processor). Say the target is another Kafka topic (or Hive/SQL/Postgres table) after general filters, enrichments, etc. However, if the target is unavailable, or any code fails to work as expected (i.e., the filter code or enrichment code), the flow stops due to backpressure, and ConsumeKafka won't run. Fortunately, data loss does not occur because the data is present in the content repository, and once the issue is resolved, the data resumes flowing to the target.
Most application use cases work well in this setup. However, some use cases may require a slightly different architecture than what traditional NiFi provides.
Use Cases
If a user knows that the data source they are receiving data from is both persistent and replayable, it might be more beneficial to skip storing the data (in NiFi, as FlowFile in the content repository) instead of replaying the data from the source after restarting. This approach has multiple advantages. Firstly, data could be stored in memory instead of on disk, offering better performance and faster load times. Secondly, it enables seamless data transfer between machines without any loss.
This can be achieved with the NiFi EXECUTESTATELESS processor.
How to Setup and Run
- First, prepare the flow you want to set up. For example: Consume Kafka receives the data as FlowFile to the content repository. Application code runs (general filters/enrichments, etc.) publish to another Kafka/writes to Hive/SQL table/Postgres table, etc.
- Say the code, which consumes a lot of resources on disk/CPU due to some filter/enrichment, can be converted to the
EXECUTESTATELESSprocess and can be run in memory.
The flow looks like this:
Consumekafka --> executestateless processor --> publish kafka/puthiveql/putdatabaserecord.
3. When the stateless process fails and because of this back pressure occurs, and data can be replayed after the issue is resolved. As this is executed in memory, it is faster compared to a conventional NiFi run.
4. Once the above code is ready (#2), keep it in processgroup. Right-click and check the code to NiFi Registry to start version control.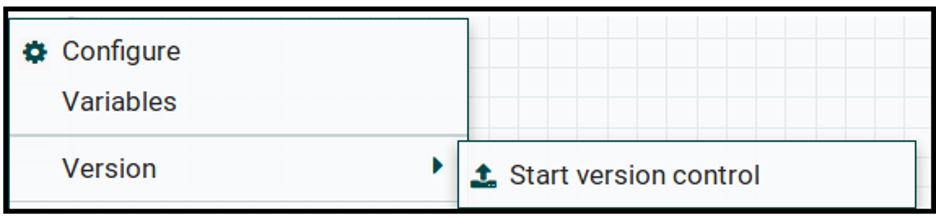
5. Now complete the full setup of the code: Drag the consumekafka and set up the configs like Kafka topic/SSL config/offset, etc. properties (considering the above example). Drag the execute stateless processor and follow step 7 below to configure. Connect this to the consumekafka processor and publishkafka processor as per the flow shown in #3. Drag publishKafka and set up the configs like Kafka topic/SSL config/any other properties like compression, etc.
- An important point to note: If this code uses any secrets, such as keystore/truststore passwords or database credentials, they should be configured within the
processgroupfor which theexecutestatelessprocess is going to run. This should also be passed from theexecutestatelessprocess as variables with the same name as to how the configuration is made inside the process group.
6. The screenshot below shows the configuration of the executestateless processor:
- Dataflow specification strategy: Use the NiFi registry
- Registry URL: Configured NiFi Registry URL
- Registry bucket: Specific bucket name where the code has been checked
- Flow name: The name of the flow where the code has been checked
- Input port: The name of the port where
consumekafkais connecting (considering the above example); the process group should have an input port - if you have multiple inputs, give the names as comma-separated - Failure port: In case of any failures, the actual code should have failure ports present and these FlowFiles can be reprocessed again. If you have multiple failure ports, give the names as comma-separated.
7. Based on the point mentioned in #6 above, add additional variables at the end of this as shown below for any of the secrets.
- Content storage strategy: change it to "store content on heap".
- Please note: One of the most impactful configuration options for the Processor is the configuration of the "Content Storage Strategy" property. For performance reasons, the processor can be configured to hold all FlowFiles in memory. This includes incoming FlowFiles, as well as intermediate and output FlowFiles. This can be a significant performance improvement but comes with a significant risk. The content is stored on NiFi's heap. This is the same heap that is shared by all other
ExecuteStatelessflows by NiFi's processors and the NiFi process itself. If the data is very large, it can quickly exhaust the heap, resulting in out-of-memory errors in NiFi. These, in turn, can result in poor performance, as well as instability of the NiFi process itself. For this reason, it is not recommended to use the "Store Content on Heap" option unless it is known that all FlowFiles will be small (less than a few MB). Also, in order to help safeguard against the case that the processor receives an unexpectedly large FlowFile, the "Max Input FlowFile Size" property must be configured when storing data on the heap. Alternatively, and by default, the "Content Storage Strategy" can be configured to store FlowFile content on disk. When this option is used, the content of all FlowFiles is stored in the configured Working Directory. It is important to note, however, that this data is not meant to be persisted across restarts. Instead, this simply provides the stateless engine with a way to avoid loading everything into memory. Upon restart, the data will be deleted instead of allowing FlowFiles to resume from where they left off (reference).
- Please note: One of the most impactful configuration options for the Processor is the configuration of the "Content Storage Strategy" property. For performance reasons, the processor can be configured to hold all FlowFiles in memory. This includes incoming FlowFiles, as well as intermediate and output FlowFiles. This can be a significant performance improvement but comes with a significant risk. The content is stored on NiFi's heap. This is the same heap that is shared by all other
8. The final flow looks like this:

Conclusion
Stateless NiFi provides a different runtime engine than traditional NiFi. It is a single-threaded runtime engine, in which data is not persisted across restarts, but this can be run in multi-threaded. Make sure to set up multiple threads (according to the use case as described below). As explained above in step 7, performance implications should be considered.
When designing a flow to use with Stateless, it is important to consider how the flow might want to receive its data and what it might want to do with the data once it is processed. Different options are as below:
- The flow to fully encapsulate the source of data and all destinations: For example, it might have a
ConsumeKafkaRecordprocessor, perform some processing, and then publish to another topic viaPublishKafkaRecord. - Build a flow that sources data from some external source, possibly performing some processing, but not defining the destination of the data. For example, the flow might consist of a
ConsumeKafkaRecordprocessor and perform some filtering and transformation, but stop short of publishing the data anywhere. Instead, it can transfer the data to an output port, which could then be used byExecuteStatelessto bring that data into the NiFi dataflow. - A dataflow may not define where it receives its input from, and instead just use an input port, so that any dataflow can be built to source data, and then deliver it to this dataflow, which is responsible for preparing and delivering the data.
- Finally, the dataflow may define neither the source nor the destination of the data. Instead, the dataflow will be built to use an input port, it will perform some filtering/routing/transformation, and finally provide its processing results to an Output Port.
(reference).
Both the traditional NiFi Runtime Engine and the Stateless NiFi Runtime Engine have their strengths and weaknesses. The ideal situation would be one in which users could easily choose which parts of their data flow run Stateless and which parts run in the traditional NiFi Runtime Engine.
Additional Reference
Opinions expressed by DZone contributors are their own.
Comments