Effortless Concurrency: Leveraging the Actor Model in Financial Transaction Systems
Learn challenges of financial transaction systems and implement robust mechanisms to handle concurrency effectively to ensure system integrity and reliability.
Join the DZone community and get the full member experience.
Join For FreeIntroduction to the Problem
Managing concurrency in financial transaction systems is one of the most complex challenges faced by developers and system architects. Concurrency issues arise when multiple transactions are processed simultaneously, which can lead to potential conflicts and data inconsistencies. These issues manifest in various forms, such as overdrawn accounts, duplicate transactions, or mismatched records, all of which can severely undermine the system's reliability and trustworthiness.
In the financial world, where the stakes are exceptionally high, even a single error can result in significant financial losses, regulatory violations, and reputational damage to the organization. Consequently, it is critical to implement robust mechanisms to handle concurrency effectively, ensuring the system's integrity and reliability.
Complexities in Money Transfer Applications
At first glance, managing a customer's account balance might seem like a straightforward task. The core operations — crediting an account, allowing withdrawals, or transferring funds between accounts — are essentially simple database transactions. These transactions typically involve adding or subtracting from the account balance, with the primary concern being to prevent overdrafts and maintain a positive or zero balance at all times.
However, the reality is far more complex. Before executing any transaction, it's often necessary to perform a series of checks with other systems. For example, the system must verify that the account in question actually exists, which usually involves querying a central account database or service. Moreover, the system must ensure that the account is not blocked due to issues such as suspicious activity, regulatory compliance concerns, or pending verification processes.
These additional steps introduce layers of complexity that go beyond simple debit and credit operations. Robust checks and balances are required to ensure that customer balances are managed securely and accurately, adding significant complexity to the overall system.
Real-World Requirements (KYC, Fraud Prevention, etc.)
Consider a practical example of a money transfer company that allows customers to transfer funds across different currencies and countries. From the customer's perspective, the process is simple:
- The customer opens an account in the system.
- A EUR account is created to receive money.
- The customer creates a recipient in the system.
- The customer initiates a transfer of €100 to $110 to the recipient.
- The system waits for the inbound €100.
- Once the funds arrive, they are converted to $110.
- Finally, the system sends $110 to the recipient.
This process can be visualized as follows:

While this sequence appears simple, real-world requirements introduce additional complexity:
- Payment verification:
- The system must verify the origin of the inbound payment.
- The payer's bank account must be valid.
- The bank's BIC code must be authorized within the system.
- If the payment originates from a non-bank payment system, additional checks are required.
- Recipient validation:
- The recipient's bank account must be active.
- Customer validation:
- The recipient must pass various checks, such as identity verification (e.g., a valid passport and a confirmed selfie ID).
- Source of funds and compliance:
- Depending on the inbound transfer amount, the source of funds may need to be verified.
- The fraud prevention system should review the inbound payment.
- Neither the sender nor the recipient should appear on any sanctions list.
- Transaction limits and fees:
- The system should calculate monthly and annual payment limits to determine applicable fees.
- If the transaction involves currency conversion, the system must handle foreign exchange rates.
- Audit and compliance:
- The system must log all transactions for auditing and compliance purposes.
These requirements add significant complexity to what initially seems like a straightforward process. Additionally, based on the results of these checks, the payment may require manual review, further extending the payment process.
Visualization of Data Flow and Potential Failure Points
In a financial transaction system, the data flow for handling inbound payments involves multiple steps and checks to ensure compliance, security, and accuracy. However, potential failure points exist throughout this process, particularly when external systems impose restrictions or when the system must dynamically decide on the course of action based on real-time data.
Standard Inbound Payment Flow
Here's a simplified visualization of the data flow when handling an inbound payment, including the sequence of interactions between various components:
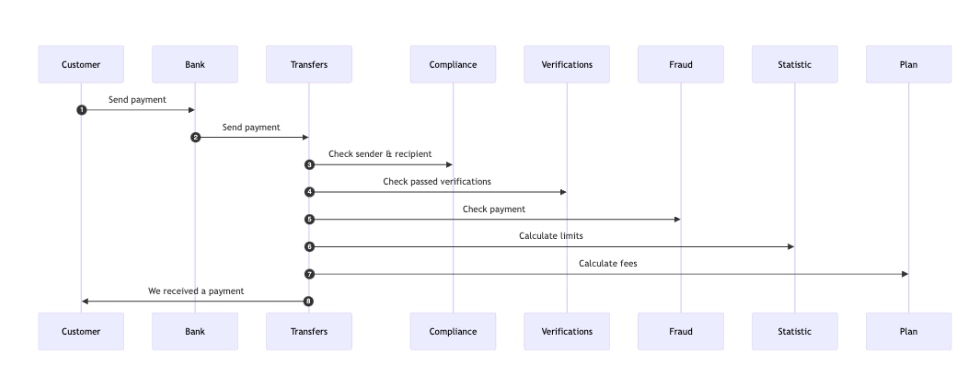
Explanation of the Flow
- Customer initiates payment: The customer sends a payment to their bank.
- Bank sends payment: The bank forwards the payment to the transfer system.
- Compliance check: The transfer system checks the sender and recipient against compliance regulations.
- Verification checks: The system verifies if the sender and recipient have passed necessary identity and document verifications.
- Fraud detection: A fraud check is performed to ensure the payment is not suspicious.
- Statistic calculation: The system calculates transaction limits and other relevant metrics.
- Fee calculation: Any applicable fees are calculated.
- Confirmation: The system confirms receipt of the payment to the customer.
Potential Failure Points and Dynamic Restrictions
While the above flow seems straightforward, the process can become complicated due to dynamic changes, such as when an external system imposes restrictions on a customer's account.
Here's how the process might unfold, highlighting the potential failure points:
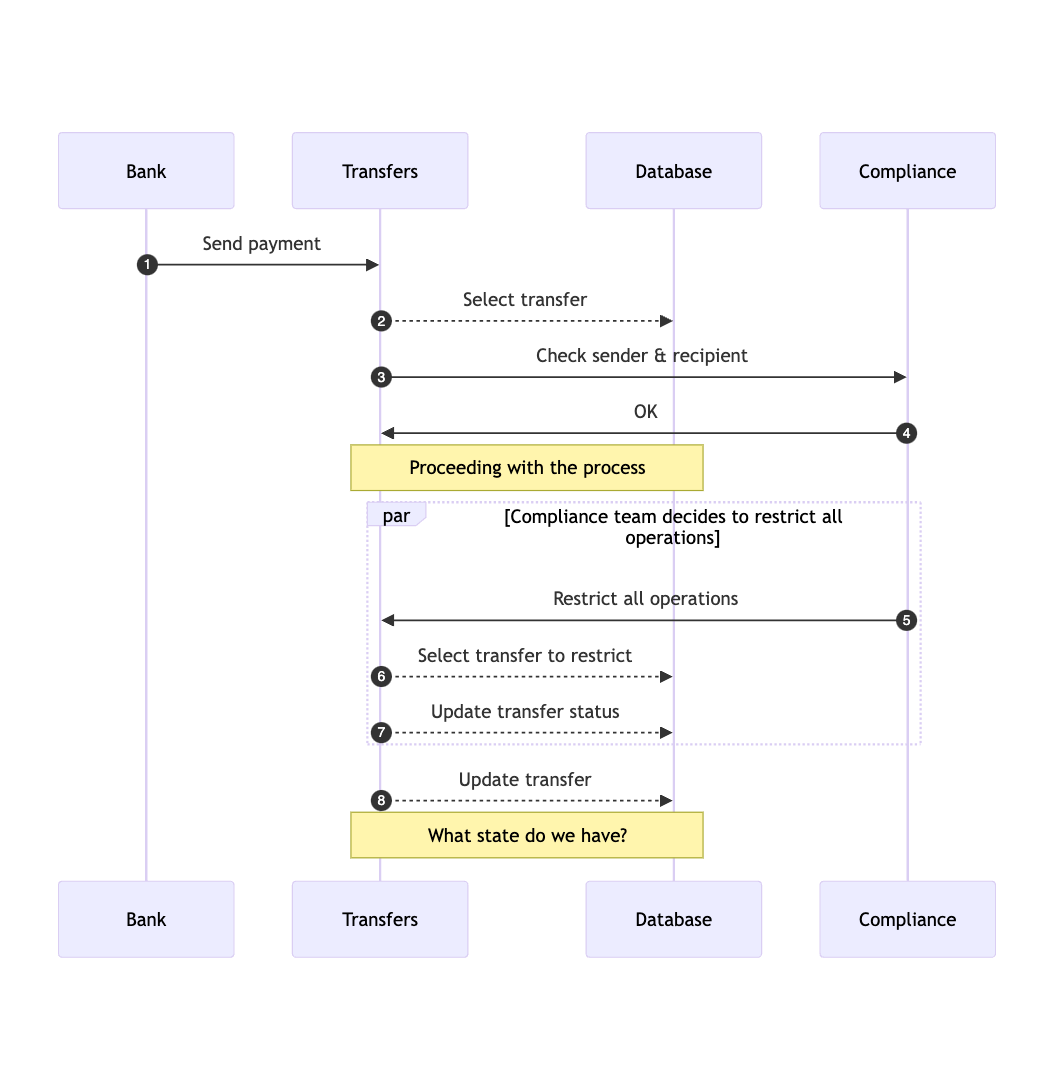
Explanation of the Potential Failure Points
- Dynamic restrictions:
- During the process, the compliance team may decide to restrict all operations for a specific customer due to sanctions or other regulatory reasons. This introduces a potential failure point where the process could be halted or altered mid-way.
- Database state conflicts:
- After compliance decides to restrict operations, the transfer system needs to update the state of the transfer in the database. The challenge here lies in managing the state consistency, particularly if multiple operations occur simultaneously or if there are conflicting updates.
- The system must ensure that the transfer's state is accurately reflected in the database, taking into account the restriction imposed. If not handled carefully, this could lead to inconsistent states or failed transactions.
- Decision points:
- The system's ability to dynamically recalculate the state and decide whether to accept or reject an inbound payment is crucial. Any misstep in this decision-making process could result in unauthorized transactions, blocked funds, or legal violations.
Visualizing the data flow and identifying potential failure points in financial transaction systems reveals the complexity and risks involved in handling payments. By understanding these risks, system architects can design more robust mechanisms to manage state, handle dynamic changes, and ensure the integrity of the transaction process.
Traditional Approaches to Concurrency
There are various approaches to addressing concurrency challenges in financial transaction systems.
Database Transactions and Their Limitations
The most straightforward approach to managing concurrency is through database transactions. To start, let’s define our context: the transfer system stores its data in a Postgres database. While the database topology can vary — whether shared across multiple instances, data centers, locations, or regions — our focus here is on a simple, single Postgres database instance handling both reads and writes.
To ensure that one transaction does not override another's data, we can lock the row associated with the transfer:
SELECT * FROM transfers WHERE id = 'ABCD' FOR UPDATE;
This command locks the row at the beginning of the process and releases the lock once the transaction is complete. The following diagram illustrates how this approach addresses the issue of lost updates: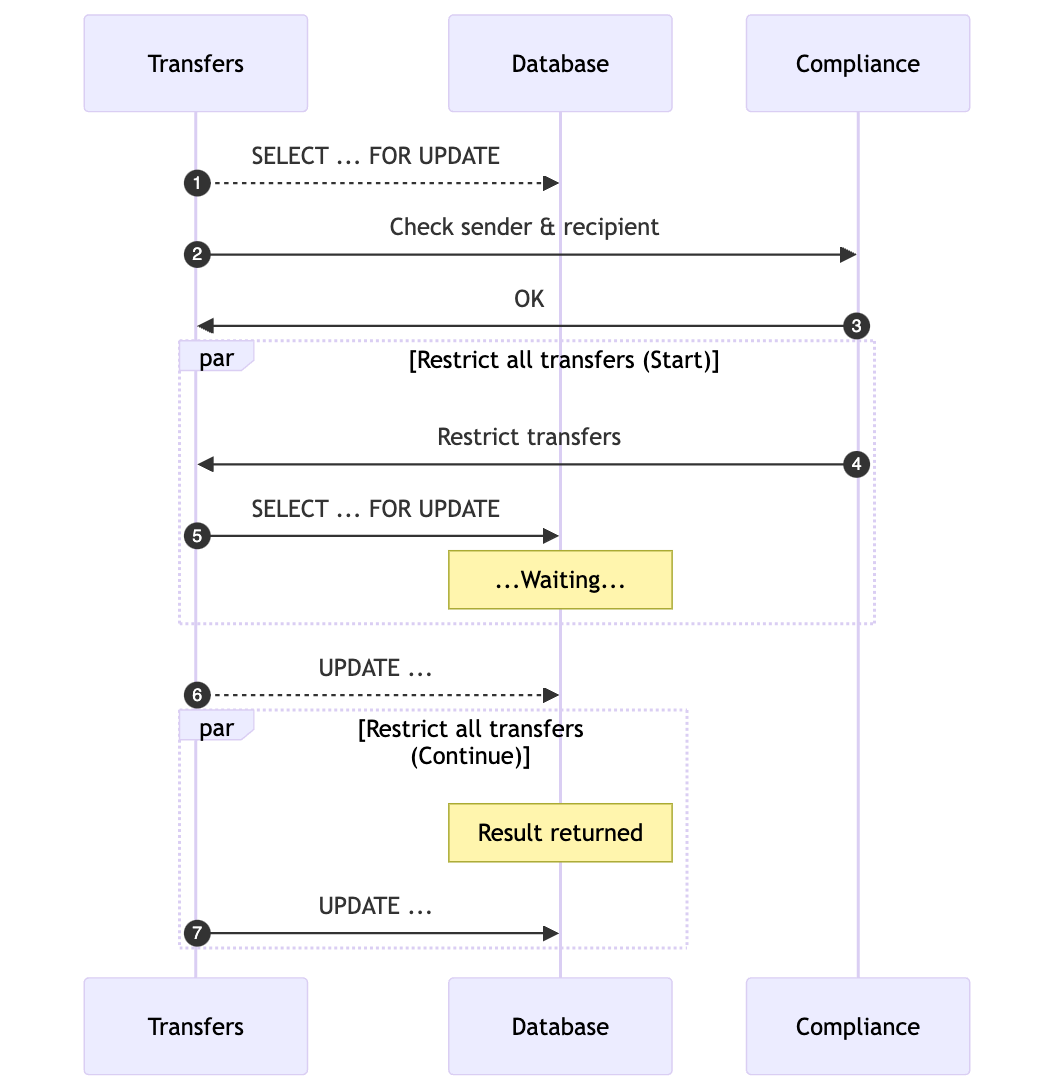
While this approach can solve the problem of lost updates in simple scenarios, it becomes less effective as the system scales and the number of active transactions increases.
Scaling Issues and Resource Exhaustion
Let’s consider the implications of scaling this approach. Assume that processing one payment takes 5 seconds, and the system handles 100 inbound payments every second. This results in 500 active transactions at any given time. Each of these transactions requires a database connection, which can quickly lead to resource exhaustion, increased latency, and degraded system performance, particularly under high load conditions.
Locks: Local and Distributed
Local locks are another common method for managing concurrency within a single application instance. They ensure that critical sections of code are executed by only one thread at a time, preventing race conditions and ensuring data consistency. Implementing local locks is relatively simple using constructs like synchronized blocks or ReentrantLocks in Java, which manages access to shared resources effectively within a single system.
However, local locks fall short in distributed environments where multiple instances of an application need to coordinate their actions. In such scenarios, a local lock on one instance does not prevent conflicting actions on other instances. This is where distributed locks come into play. Distributed locks ensure that only one instance of an application can access a particular resource at any given time, regardless of which node in the cluster is executing the code.
Implementing distributed locks is inherently more complex, often requiring external systems like ZooKeeper, Consul, Hazelcast, or Redis to manage the lock state across multiple nodes. These systems need to be highly available and consistent to prevent the distributed lock mechanism from becoming a single point of failure or a bottleneck.
The following diagram illustrates the typical flow of a distributed lock system:
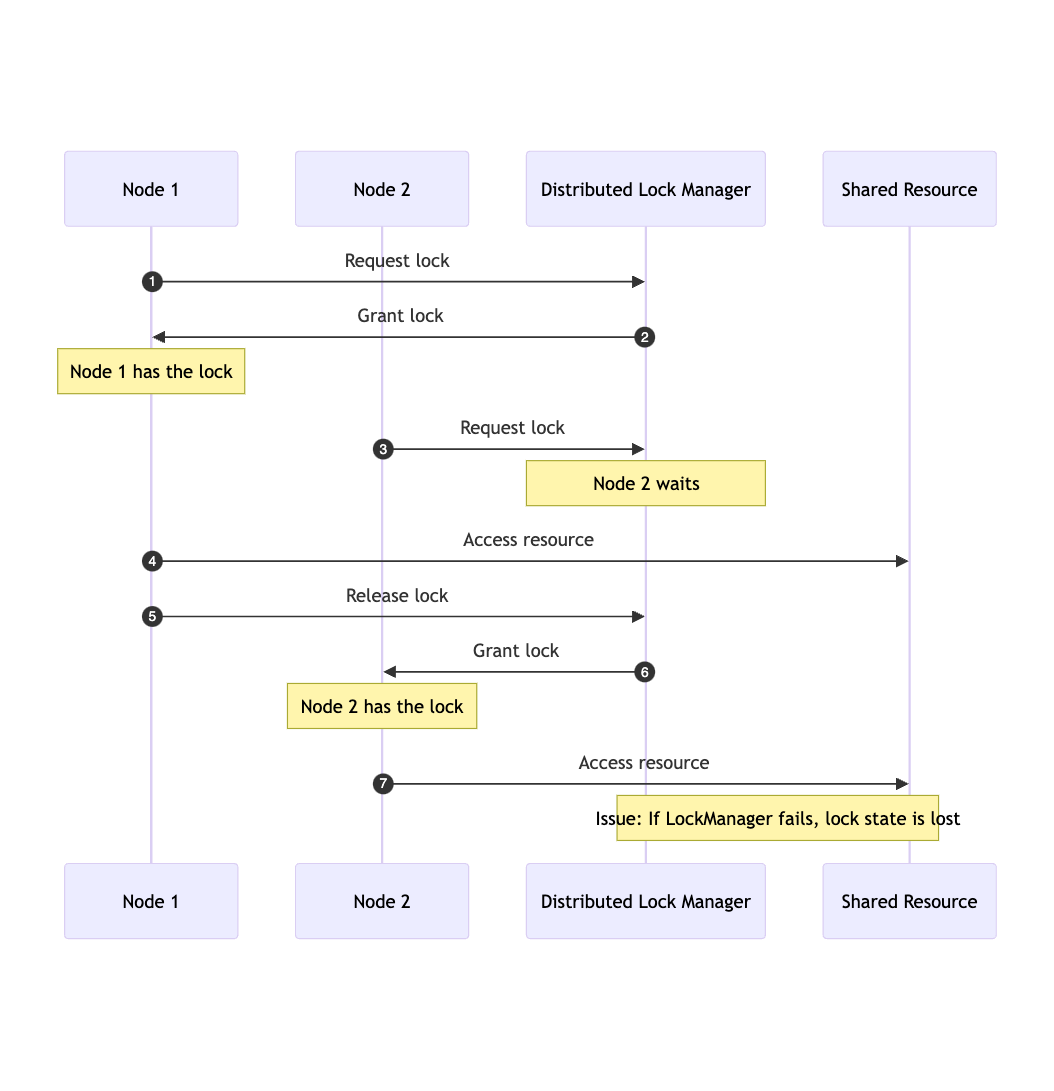
The Problem of Ordering
In distributed systems, where multiple nodes may request locks simultaneously, ensuring fair processing and maintaining data consistency can be challenging. Achieving an ordered queue of lock requests across nodes involves several difficulties:
- Network latency: Varying latencies can make strict ordering difficult to maintain
- Fault Tolerance: The ordering mechanism must be fault-tolerant and not become a single point of failure, which adds complexity to the system.
Waiting of Lock Consumers and Deadlocks
When multiple nodes hold various resources and wait for each other to release locks, a deadlock can occur, halting system progress. To mitigate this, distributed locks often incorporate timeouts.
Timeouts
- Lock acquisition timeouts: Nodes specify a maximum wait time for a lock. If the lock is not granted within this time, the request times out, preventing indefinite waiting.
- Lock holding timeouts: Nodes holding a lock have a maximum duration to hold it. If the time is exceeded, the lock is automatically released to prevent resources from being held indefinitely.
- Timeout handling: When a timeout occurs, the system must handle it gracefully, whether by retrying, aborting, or triggering compensatory actions.
Considering these challenges, guaranteeing reliable payment processing in a system that relies on distributed locking is a complex endeavor. Balancing the need for concurrency control with the realities of distributed systems requires careful planning and robust design.
A Paradigm Shift: Simplifying Concurrency
Let’s take a step back and review our transfer processing approach. By breaking the process into smaller steps, we can simplify each operation, making the entire system more manageable and reducing the risk of concurrency issues.
When a payment is received, it triggers a series of checks, each requiring computations from different systems. Once all the results are in, the system decides on the next course of action. These steps resemble transitions in a finite state machine (FSM).
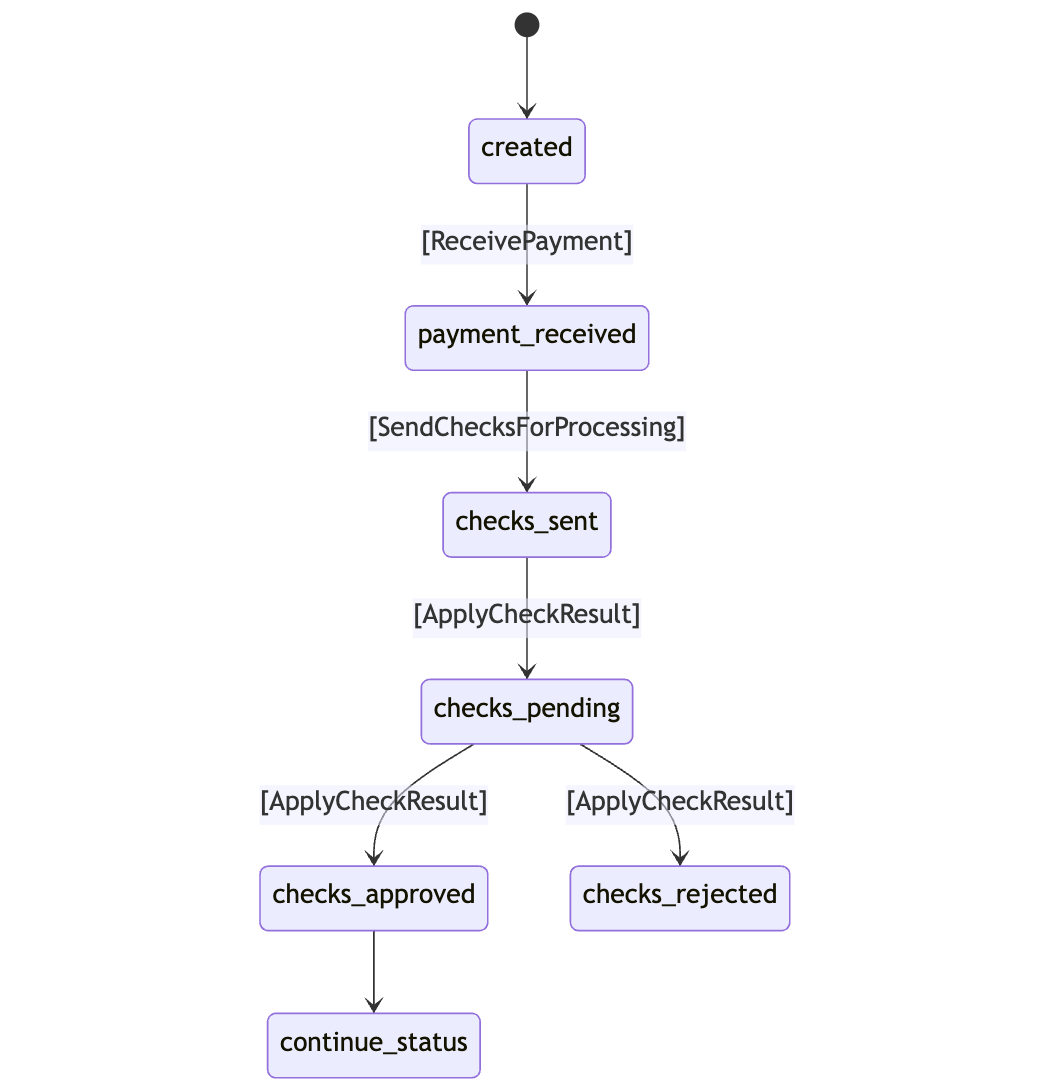
Introducing a Message-Based Processing Model
As shown in the diagram, payment processing involves a combination of commands and state transitions. For each command, the system identifies the initial state and the possible transition states.
For example, if the system receives the [ReceivePayment] command, it checks if the transfer is in the created state. If not, it does nothing. For the [ApplyCheckResult] command, the system transitions the transfer to either checks_approved or checks_rejected based on the results of the checks.
These checks are designed to be granular and quick to process, as each check operates independently and does not modify the transfer state directly. It only requires the input data to determine the result of the check.
Here is how the code for such processing might look:
interface Check<Input> {
CheckResult run(Input input);
}
interface Processor<State, Command> {
State process(State initial, Command command);
}
interface CommandSender<Command> {
void send(UUID transferId, Command command);
}
Let’s see how these components interact to send, receive, and process checks:
enum CheckStatus {
NEW,
ACCEPTED,
REJECTED
}
record Check(UUID transferId, CheckType type, CheckStatus status, Data data);
class CheckProcessor {
void process(Check check) {
// Run all required calculations
// Send result to `TransferProcessor`
}
}
enum TransferStatus {
CREATED,
PAYMENT_RECEIVED,
CHECKS_SENT,
CHECKS_PENDING,
CHECKS_APPROVED,
CHECKS_REJECTED
}
record Transfer(UUID id, List<Check> checks);
sealed interface Command permits
ReceivePayment,
SendChecks,
ApplyCheckResult {}
class TransferProcessor {
State process(State state, Command command) {
// (1) If status == CREATED and command is `ReceivePayment`
// (2) Write payment details to the state
// (3) Send command `SendChecks` to self
// (4) Set status = PAYMENT_RECEIVED
// (4) If state = PAYMENT_RECEIVED and command is `SendChecks`
// (5) Calculate all required checks (without processing)
// (6) Send checks for processing to other processors
// (7) Set status = CHECKS_SENT
// (10) If status = CHECKS_SENT or CHECKS_PENDING
// and command is ApplyCheckResult
// (11) Update `transfer.checks()`
// (12) Compute overall status
// (13) If all checks are accepted - set status = CHECKS_APPROVED
// (14) If any of the checks is rejected - set status CHECKS_REJECTED
// (15) Otherwise - set status = CHECKS_PENDING
}
}
This approach reduces processing latency by offloading check result calculations to separate processes, leading to fewer concurrent operations. However, it does not entirely solve the problem of ensuring atomic processing for commands.
Communication Through Messages
In this model, communication between different parts of the system occurs through messages. This approach enables asynchronous communication, decoupling components and enhancing flexibility and scalability. Messages are managed through queues and message brokers, which ensure orderly transmission and reception of messages.
The diagram below illustrates this process:
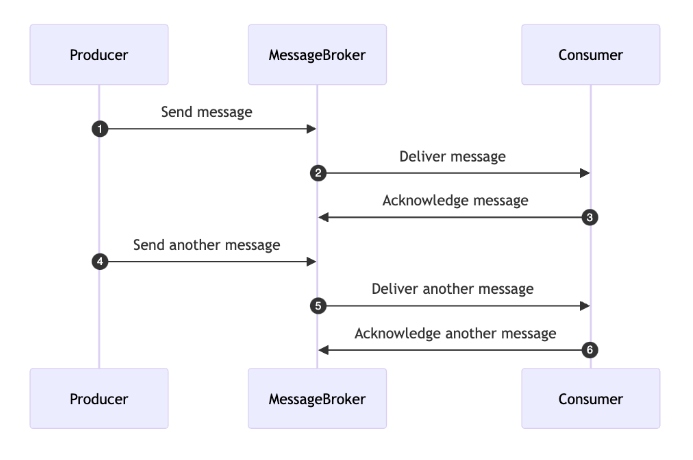
One-at-a-Time Message Handling
To ensure correct and consistent command processing, it is crucial to order and linearize all messages for a single transfer. This means messages should be processed in the order they were sent, and no two messages for the same transfer should be processed simultaneously. Sequential processing guarantees that each step in the transaction lifecycle occurs in the correct sequence, preventing race conditions, data corruption, or inconsistent states.
Here’s how it works:
- Message queue: A dedicated queue is maintained for each transfer to ensure that messages are processed in the order they are received.
- Consumer: The consumer fetches messages from the queue, processes them, and acknowledges successful processing.
- Sequential processing: The consumer processes each message one by one, ensuring that no two messages for the same transfer are processed simultaneously.
Durable Message Storage
Ensuring message durability is crucial in financial transaction systems because it allows the system to replay a message if the processor fails to handle the command due to issues like external payment failures, storage failures, or network problems.
Imagine a scenario where a payment processing command fails due to a temporary network outage or a database error. Without durable message storage, this command could be lost, leading to incomplete transactions or other inconsistencies. By storing messages durably, we ensure that every command and transaction step is persistently recorded. If a failure occurs, the system can recover and replay the message once the issue is resolved, ensuring the transaction completes successfully.
Durable message storage is also invaluable for dealing with external payment systems. If an external system fails to confirm a payment, we can replay the message to retry the operation without losing critical data, maintaining the integrity and consistency of our transactions.
Additionally, durable message storage is essential for auditing and compliance, providing a reliable log of all transactions and actions taken by the system, and making it easier to track and verify operations when needed.
The following diagram illustrates how durable message storage works:
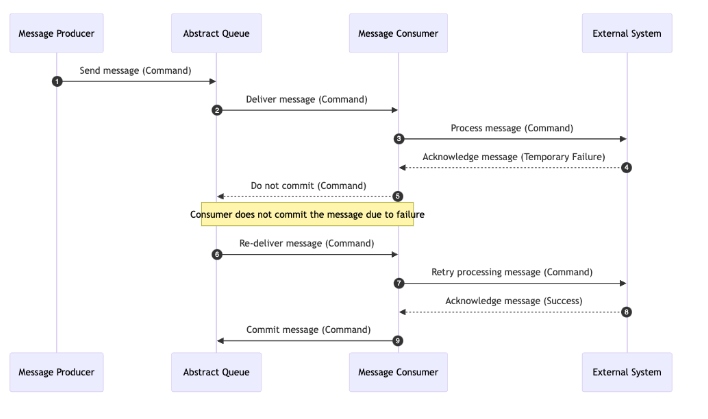
By using durable message storage, the system becomes more reliable and resilient, ensuring that failures are handled gracefully without compromising data integrity or customer trust.
Kafka as a Messaging Backbone
Apache Kafka is a distributed streaming platform designed for high-throughput, low-latency message handling. It is widely used as a messaging backbone in complex systems due to its ability to handle real-time data feeds efficiently. Let's explore Kafka's core components, including producers, topics, partitions, and message routing, to understand how it operates within a distributed system.
Topics and Partitions
Topics
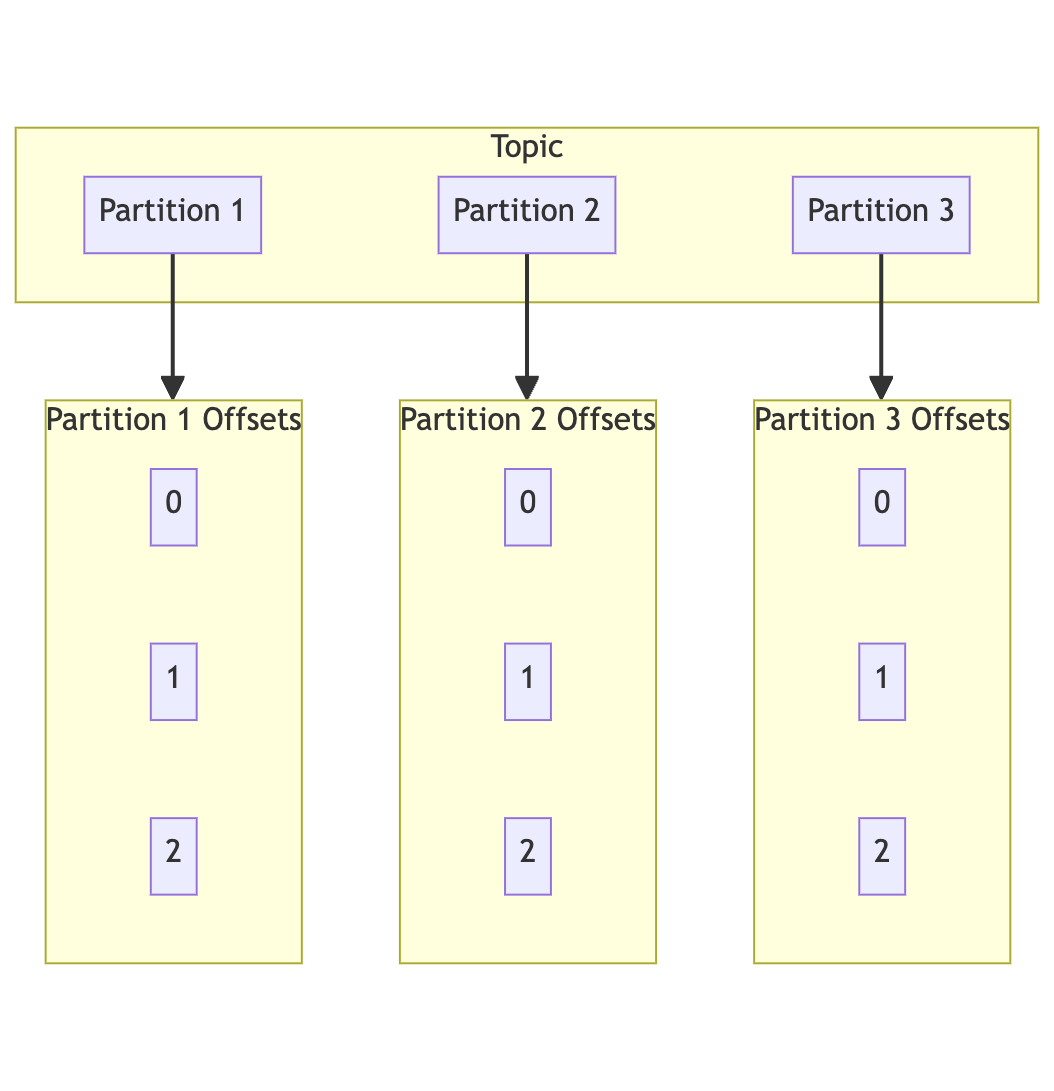
In Kafka, a topic is a category or feed name to which records are stored and published. Topics are divided into partitions to facilitate parallel processing and scalability.
Partitions
Each topic can be divided into multiple partitions, which are the fundamental units of parallelism in Kafka. Partitions are ordered, immutable sequences of records continually appended to a structured commit log. Kafka stores data in these partitions across a distributed cluster of brokers. Each partition is replicated across multiple brokers to ensure fault tolerance and high availability. The replication factor determines the number of copies of the data, and Kafka automatically manages the replication process to ensure data consistency and reliability.
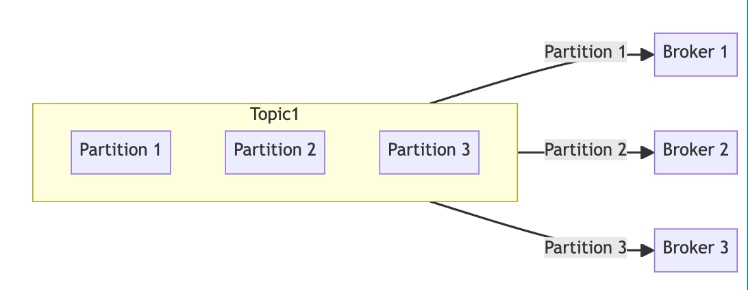
Each record within a partition has a unique offset, serving as the identifier for the record's position within the partition. This offset allows consumers to keep track of their position and continue processing from where they left off in case of a failure.
Message Routing
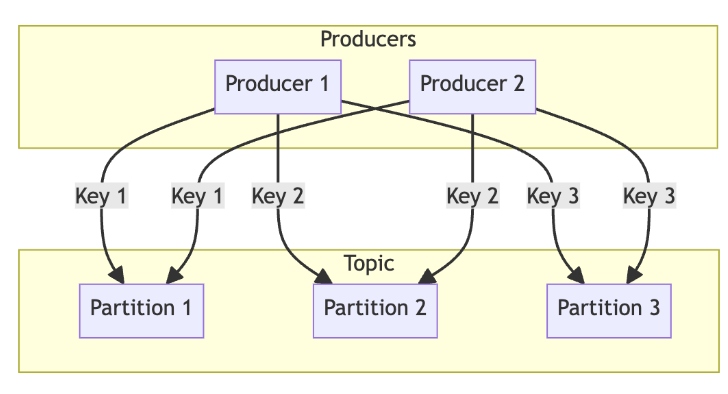
Kafka's message routing is a key mechanism that determines how messages are distributed across the partitions of a topic. There are several methods for routing messages:
- Round-robin: The default method where messages are evenly distributed across all available partitions to ensure a balanced load and efficient use of resources
- Key-based routing: Messages with the same key are routed to the same partition, which is useful for maintaining the order of related messages and ensuring they are processed sequentially. For example, all transactions for a specific account can be routed to the same partition using the account ID as the key.
- Custom partitioners: Kafka allows custom partitioning logic to define how messages should be routed based on specific criteria. This is useful for complex routing requirements not covered by the default methods.
This routing mechanism optimizes performance, maintains message order when needed, and supports scalability and fault tolerance.
Producers
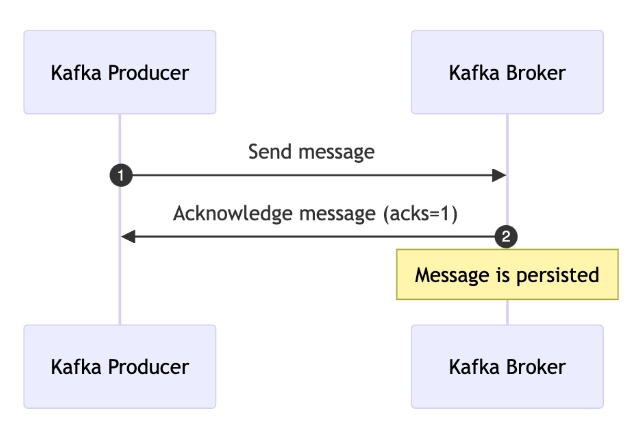
Kafka producers are responsible for publishing records to topics. They can specify acknowledgment settings to control when a message is considered successfully sent:
acks=0: No acknowledgment is needed, providing the lowest latency but no delivery guaranteesacks=1: The leader broker acknowledges the message, ensuring it has been written to the leader's log.acks=all: All in-sync replicas must acknowledge the message, providing the highest level of durability and fault tolerance.
These configurations allow Kafka producers to meet various application requirements for message delivery and persistence, ensuring that data is reliably stored and available for consumers.
Consumers
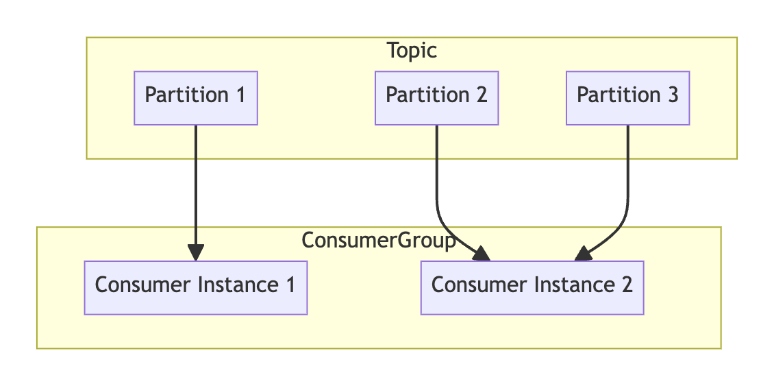
Kafka consumers read data from Kafka topics. A key concept in Kafka's consumer model is the consumer group. A consumer group consists of multiple consumers working together to read data from a topic. Each consumer in the group reads from different partitions of the topic, allowing for parallel processing and increased throughput.
When a consumer fails or leaves the group, Kafka automatically reassigns the partitions to the remaining consumers, ensuring fault tolerance and high availability. This dynamic balancing of partition assignments ensures that the workload is evenly distributed among the consumers in the group, optimizing resource utilization and processing efficiency.
Kafka's ability to manage high volumes of data, ensure fault tolerance, and maintain message order makes it an ideal choice for serving as a messaging backbone in distributed systems, particularly in environments requiring real-time data processing and robust concurrency management.
Messaging System Using Kafka
Incorporating Apache Kafka as the messaging backbone into our system allows us to address various challenges associated with message handling, durability, and scalability. Let's explore how Kafka aligns with our requirements and facilitates the implementation of an Actor model-based system.
One-at-a-Time Message Handling
To ensure that messages for a specific transfer are handled sequentially and without overlap, we can create a Kafka topic named transfer.commands with multiple partitions. Each message's key will be the transferId, ensuring that all commands related to a particular transfer are routed to the same partition. Since a partition can only be consumed by one consumer at a time, this setup guarantees one-at-a-time message handling for each transfer.
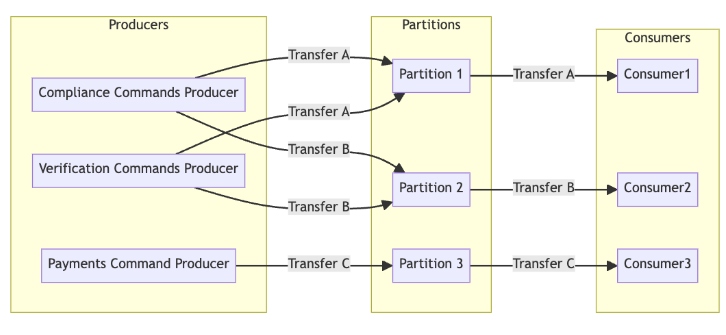
Durable Message Store
Kafka's architecture is designed to ensure message durability by persisting messages across its distributed brokers. Here are some key Kafka configurations that enhance message durability and reliability:
retention.ms: Specifies how long Kafka retains a record before it is deleted; for example,setting log.retention.ms=604800000retains messages for 7 dayslog.segment.bytes: Controls the size of each log segment; for instance, settinglog.segment.bytes=1073741824creates new segments after 1 GBmin.insync.replicas: Defines the minimum number of replicas that must acknowledge a write before it is considered successful; settingmin.insync.replicas=2ensures that at least two replicas confirm the write.acks: A producer setting that specifies the number of acknowledgments required. Settingacks=allensures that all in-sync replicas must acknowledge the message, providing high durability.
Example configurations for ensuring message durability:
# Example 1: Retention Policy
log.retention.ms=604800000 # Retain messages for 7 days
log.segment.bytes=1073741824 # 1 GB segment size
# Example 2: Replication and Acknowledgment
min.insync.replicas=2 # At least 2 replicas must acknowledge a write
acks=all # Producer requires acknowledgment from all in-sync replicas
# Example 3: Producer Configuration
acks=all # Ensures high durability
retries=5 # Number of retries in case of transient failures
Revealing the Model: The Actor Pattern
In our system, the processor we previously discussed will now be referred to as an Actor. The Actor model is well-suited for managing state and handling commands asynchronously, making it a natural fit for our Kafka-based system.
Core Concepts of the Actor Model
Actorsas fundamental units: EachActoris responsible for receiving messages, processing them, and modifying its internal state. This aligns with our use of processors to handle commands for each transfer.- Asynchronous message passing: Communication between
Actorsoccurs through Kafka topics, allowing for decoupled, asynchronous interactions. - State isolation: Each
Actormaintains its own state, which can only be modified by sending a command to theActor. This ensures that state changes are controlled and sequential. - Sequential message processing: Kafka guarantees that messages within a partition are processed in order, which supports the
Actormodel's need for sequential handling of commands. - Location transparency:
Actorscan be distributed across different machines or locations, enhancing scalability and fault tolerance. - Fault tolerance: Kafka’s built-in fault-tolerance mechanisms, combined with the
Actormodel’s distributed nature, ensure that the system can handle failures gracefully. - Scalability: The system’s scalability is determined by the number of Kafka partitions. For instance, with 64 partitions, the system can handle 64 concurrent commands. Kafka's architecture allows us to scale by adding more partitions and consumers as needed.
Implementing the Actor Model in the System
We start by defining a simple interface for managing the state:
interface StateStorage<K, S> {
S newState();
S get(K key);
void put(K key, S state);
}
Next, we define the Actor interface:
interface Actor<S, C> {
S receive(S state, C command);
}
To integrate Kafka, we need helper interfaces to read the key and value from Kafka records:
interface KafkaMessageKeyReader<K> {
K readKey(byte[] key);
}
interface KafkaMessageValueReader<V> {
V readValue(byte[] value);
}
Finally, we implement the KafkaActorConsumer, which manages the interaction between Kafka and our Actor system:
class KafkaActorConsumer<K, S, C> {
private final Supplier<Actor<S, C>> actorFactory;
private final StateStorage<K, S> storage;
private final KafkaMessageKeyReader<K> keyReader;
private final KafkaMessageValueReader<C> valueReader;
public KafkaActorConsumer(Supplier<Actor<S, C>> actorFactory, StateStorage<K, S> storage,
KafkaMessageKeyReader<K> keyReader, KafkaMessageValueReader<C> valueReader) {
this.actorFactory = actorFactory;
this.storage = storage;
this.keyReader = keyReader;
this.valueReader = valueReader;
}
public void consume(ConsumerRecord<byte[], byte[]> record) {
// (1) Read the key and value from the record
K messageKey = keyReader.readKey(record.key());
C messageValue = valueReader.readValue(record.value());
// (2) Get the current state from the storage
S state = storage.get(messageKey);
if (state == null) {
state = storage.newState();
}
// (3) Get the actor instance
Actor<S, C> actor = actorFactory.get();
// (4) Process the message
S newState = actor.receive(state, messageValue);
// (5) Save the new state
storage.put(messageKey, newState);
}
}
This implementation handles the consumption of messages from Kafka, processes them using an Actor, and updates the state accordingly. Additional considerations like error handling, logging, and tracing can be added to enhance the robustness of this system.
By combining Kafka’s powerful messaging capabilities with the Actor model’s structured approach to state management and concurrency, we can build a highly scalable, resilient, and efficient system for handling financial transactions. This setup ensures that each command is processed correctly, sequentially, and with full durability guarantees.
Advanced Topics
Outbox Pattern
The Outbox Pattern is a critical design pattern for ensuring reliable message delivery in distributed systems, particularly when integrating PostgreSQL with Kafka. The primary issue it addresses is the risk of inconsistencies where a transaction might be committed in PostgreSQL, but the corresponding message fails to be delivered to Kafka due to a network issue or system failure. This can lead to a situation where the database state and the message stream are out of sync.
The Outbox Pattern solves this problem by storing messages in a local outbox table within the same PostgreSQL transaction. This ensures that the message is only sent to Kafka after the transaction is successfully committed. By doing so, it provides exactly-once delivery semantics, preventing message loss and ensuring consistency between the database and the message stream.
Implementing the Outbox Pattern
With the Outbox Pattern in place, the KafkaActorConsumer and Actor implementations can be adjusted to accommodate this pattern:
record OutboxMessage(UUID id, String topic, byte[] key, Map<String, byte[]> headers, byte[] payload) {}
record ActorReceiveResult<S, M>(S newState, List<M> messages) {}
interface Actor<S, C> {
ActorReceiveResult<S, OutboxMessage> receive(S state, C command);
}
class KafkaActorConsumer<K, S, C> {
public void consume(ConsumerRecord<byte[], byte[]> record) {
// ... other steps
// (5) Process the message
var result = actor.receive(state, messageValue);
// (6) Save the new state
storage.put(messageKey, result.newState());
}
@Transactional
public void persist(S state, List<OutboxMessage> messages) {
// (7) Persist the new state
storage.put(stateKey, state);
// (8) Persist the outbox messages
for (OutboxMessage message : messages) {
outboxTable.save(message);
}
}
}
In this implementation:
- The
Actornow returns anActorReceiveResultcontaining the new state and a list of outbox messages that need to be sent to Kafka. - The
KafkaActorConsumerprocesses these messages and persists both the state and the messages in the outbox table within the same transaction. - After the transaction is committed, an external process (e.g., Debezium) reads from the outbox table and sends the messages to Kafka, ensuring exactly-once delivery.
Toxic Messages and Dead-Letters
In distributed systems, some messages might be malformed or cause errors that prevent successful processing. These problematic messages are often referred to as "toxic messages." To handle such scenarios, we can implement a dead-letter queue (DLQ). A DLQ is a special queue where unprocessable messages are sent for further investigation. This approach ensures that these messages do not block the processing of other messages and allows for the root cause to be addressed without losing data.
Here's a basic implementation for handling toxic messages:
class ToxicMessage extends Exception {}
class LogicException extends ToxicMessage {}
class SerializationException extends ToxicMessage {}
class DefaultExceptionDecider {
public boolean isToxic(Throwable e) {
return e instanceof ToxicMessage;
}
}
interface DeadLetterProducer {
void send(ConsumerRecord<?, ?> record, Throwable e);
}
class Consumer {
private final ExceptionDecider exceptionDecider;
private final DeadLetterProducer deadLetterProducer;
void consume(ConsumerRecord<String, String> record) {
try {
// process record
} catch (Exception e) {
if (exceptionDecider.isToxic(e)) {
deadLetterProducer.send(record, e);
} else {
// throw exception to retry the operation
throw e;
}
}
}
}
In this implementation:
ToxicMessage: A base exception class for any errors deemed "toxic," meaning they should not be retried but rather sent to the DLQDefaultExceptionDecider: Decides whether an exception is toxic and should trigger sending the message to the DLQDeadLetterProducer: Responsible for sending messages to the DLQConsumer: Processes messages and uses theExceptionDeciderandDeadLetterProducerto handle errors appropriately
Conclusion
By leveraging Kafka as the messaging backbone and implementing the Actor model, we can build a robust, scalable, and fault-tolerant financial transaction system. The Actor model offers a straightforward approach to managing state and concurrency, while Kafka provides the tools necessary for reliable message handling, durability, and partitioning.
The Actor model is not a specialized or complex framework but rather a set of simple abstractions that can significantly increase the scalability and reliability of our system. Kafka’s built-in features, such as message durability, ordering, and fault tolerance, naturally align with the principles of the Actor model, enabling us to implement these concepts efficiently and effectively without requiring additional frameworks.
Incorporating advanced patterns like the Outbox Pattern and handling toxic messages with DLQs further enhances the system's reliability, ensuring that messages are processed consistently and that errors are managed gracefully. This comprehensive approach ensures that our financial transaction system remains reliable, scalable, and capable of handling complex workflows seamlessly.
Opinions expressed by DZone contributors are their own.
Comments