Real-Time Analytics: All Data, Any Data, Any Scale, at Any Time
All data, any data, any scale, at any time: Learn why data pipelines need to embrace real-time data streams to harness the value of data as it is created.
Join the DZone community and get the full member experience.
Join For FreeThis is an article from DZone's 2023 Data Pipelines Trend Report.
For more:
Read the Report
We live in an era of rapid data generation from countless sources, including sensors, databases, cloud, devices, and more. To keep up, we require real-time analytics (RTA), which provides the immediacy that every user of data today expects and is based on stream processing. Stream processing is used to query a continuous stream of data and immediately process events in that stream. Ideally, your stream is processing events in subseconds as they occur.
RTA enables organizations to process and analyze data in real-time, providing valuable insights and driving timely decisionmaking. The key factor is that we must process each event as it arrives, and time matters. Unlike traditional batch processing, where data is analyzed in predetermined intervals, RTA provides an immediate and continuous understanding of events and data as they arrive.
Why is this important for data pipelines? Let's discuss.
How RTA Is Relevant to Data Pipelines
RTA needs to be fed by a continuous flow of data from various sources. Data pipelines are responsible for ingesting data from sources — like sensors, logs, databases, and APIs — and delivering the data to an RTA platform as a stream. In the case of a real-time streaming data pipeline fed from a tool such as Apache NiFi, we receive each chunk of data as an event from Apache Kafka. There are many data pipelines that are batched by being fed in large chunks at regular intervals or on demand. These batches yield bursts of data when translated to a stream, and the bursts can cause a backup, like going from local roads to a superhighway.
A tool like NiFi that lets you transition batches to streams without code is ideal. There are several architecture decisions based on how to keep batches and streams flowing and available to the same consumers and often having the same sources. An important part is that we need a real-time lakehouse based on Apache Iceberg or Apache Paimon to permanently store large data that will be needed later for LLM, data training, and lookups.
Stream Processing and RTA
RTA is built on stream processing, which includes frameworks like Apache Flink, Apache Kafka Streams, RisingWave, and Faust Streaming. Stream processing is often done by writing code in Java, Scala, or Python. The most exciting form of stream processing is done with SQL, and it can be often done without implicit compiling or deploying in an IDE.
The main feature of stream processing is ingesting a continuous event stream to filter, enrich, join, transform, convert, route, and analyze data as it arrives in near real time. Real time has a lot of definitions, but for stream processing in most contexts, let us assume time means subsecond.
The Importance of Real-Time Analytics
RTA is important for timely decision making since the faster data arrives and is processed, the faster we can act. The immediate usage of data streams can make new types of applications possible, such as detecting fraud while it occurs. With data arriving constantly from thousands of devices, RTA is critical for receiving, processing, handling, and potentially alerting on this data.
RTA allows for predictive analytics on real-world machinery that could be alerting to upcoming failures based on current and historical data and machine learning (ML) analysis. RTA enables processing not just for each event as it arrives, but also for time windows of data, frequently in one-, five-, or 15-minute chunks.
Batch vs. Real Time for Data Pipelines
I often want to make every data pipeline a real-time one for the previously mentioned reasons. But there are a number of reasons batches make sense for certain use cases. Batch is good for collecting data at predefined times and chunks. This often occurs when dealing with mainframes, legacy systems, and old data warehouses.
These batches tend to be easier to scale and more predictable. This can allow for more affordable data processing at slower, timed intervals. Batch workloads can be run at cheaper times on lesser hardware and allow for longer time to process. You can optimize and break up batches to use less resources (in exchange for time).
Real time lowers latency to seconds or less at the cost of being more expensive to scale, less predictable, burstable, and using many resources in a short period of time. Real time lends itself better to things like Kubernetes with the ability to scale on demand or automatically.
If you need results immediately, then you cannot choose batch processing for your pipeline. One great feature of a tool like Apache Nifi is that converting from batch to stream or stream to batch is merely choosing a continuous interval or setting a cron schedule.
For many applications, you may need a combination of batch and real-time processing on your data, aka the famous Lambda architecture. For a variation of this, we send each event immediately to Apache Kafka, while we set an interval before we push chunks of data to Apache Iceberg. We often set chunks to be 250 megabytes, 500,000 records, or five minutes of data — whichever comes first.
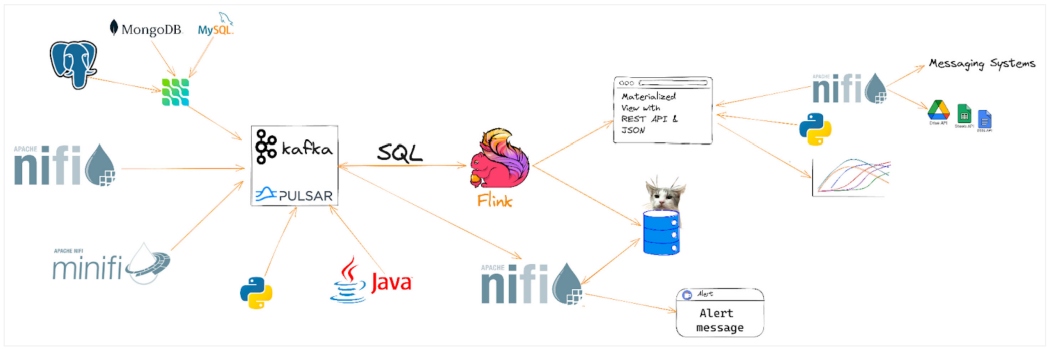
Figure 1: Real-time architecture layout
Implementing a Real-Time Analytics Pipeline
One of the great features of RTA pipelines is that if you plan your architecture, each piece is straightforward to implement. We will be using the most popular open-source frameworks to build a pipeline and highlight alternatives available in the community. The most important thing is to determine your data sources, time and data size requirements, user requirements, and platform.
The first implementation step is to choose how you are ingesting data sources. I suggest utilizing Apache NiFi, which is a great way to start the ingestion process and explore that data as it arrives. This is also when you start building data schemas, determine the enrichments and transformations needed, and tour intermediate and final data formats.
Often, there will be multiple data destinations, including real-time OLAP datastores like Apache Pinot, vector databases like Milvus, analytic data lake tables like Apache Iceberg, and column-oriented data stores like Apache Kudu. For many use cases, we often write a raw copy of the incoming data into storage like Apache Ozone or Hadoop Distributed File System (HDFS). This may be used later for validation, reloads, or training ML models.
Once the data meets the minimum clean format and has a basic schema, we stream it into Apache Kafka or Pulsar for stream processing. We usually choose JSON or Apache Avro as the format for this data.
Now that our data is streaming into one or more topics within Kafka, we can start consuming it with our real-time stream processing and analytics tools. There are a number of ways to create RTA applications with Flink, but I recommend starting with Flink SQL. This allows you to build streaming applications with just SQL. You will be able to join streams, do windowing, and handle multiple sources and sinks.
When Flink SQL has completed its flows, we often sink it to another Kafka topic, database table, or other datastore. For most architectures, I sink it to Kafka.
Exploring RTA Use Cases
There are many interesting use cases out there for RTA. I will highlight a couple that I have worked on, but this is not an exhaustive list. You can do much more; your data dreams are the only limit.
Monitoring IoT Devices and Systems
A use case that I love due to personal experience is monitoring IoT devices and systems. This use case is constantly expanding as every real-world object is adding sensors, networks, cameras, GPUs, computers, and even edge AI systems. One of the main difficulties with IoT is that often, existing systems are not designed to stream data and may not make sensor endpoints available at all or in non-standard formats. This has been challenging in the past but is improving.
Often, we add additional devices alongside built-in systems so we can control the data types, speed, and operation. This is enabled by adding a small smart agent such as Apache MiNiFi.
Real-Time Fraud Detection
This is probably one of the most quintessential use cases for protecting people from bad transactions, and most major credit cards have been implementing this for some time. With real time, we can see not just every transaction and all the metadata surrounding them, but we can see trends over windows of time. The ability of stream processing to discover duplicate, anomalous, and overly frequent charges in unusually small windows of event time helps detect fraud.
Stream processing makes it possible to compare new data against existing data profiles of people and credit cards. This is also supercharged by real-time pipelines continuously training ML models on new data so that they recognize typical and atypical patterns for every credit card and its user.
RTA Data Pipeline Guiding Principles
Designing an RTA data pipeline with Apache NiFi, Apache Kafka, and Apache Flink involves careful consideration of the data sources, processing logic, and how each component fits into the overall architecture. Here's a step-by-step approach to help you decide how to process different data sources:
- Discover your data sources such as databases, APIs, files, logs, messages, documents, images, videos, and sensors.
- Start collecting them with NiFi to see what the data looks like, how large the stream is, and if you need to use a different tool. This is where you can do basic cleanup, transformations, enrichment, and field definitions. Then you can route to Kafka for additional processing. For simple use cases, you may have a NiFi stream to a datastore directly.
- Before arriving in Kafka, you must plan out your topics, schemas of data, and run some tests to see the amount of data.
- The next step is where you determine which RTA you need. This could be as simple as detecting alert conditions; joining data streams like weather and transit on latitude and longitude; transforming data further; or making computations, aggregations, and anything you can do with advanced SQL using Flink SQL.
- Often, you will want this data stored for future usage. Flink SQL can store in an underlying streaming table format in Apache Paimon or in an open lakehouse format like Apache Iceberg.
- Finally, to move this to production, you need to run on an enterprise data platform that provides things like monitoring, fault tolerance, auto-scaling, data security, data governance, and control of the underlying hybrid cloud environment.
Remember that the specific implementation details will depend on your use case, data volume, processing requirements, and technical constraints. It's crucial to thoroughly understand the capabilities and limitations of each framework to design an efficient and robust RTA pipeline.
Conclusion
All data pipelines need to embrace real-time data streams to harness the value of data as it is created, and it's also time to embrace both real-time analytics and batch processing as the two processes converge. It is critical to be ready for the future, which will push more data, more speed, more requirements, and more challenges, including:
- As edge computing and edge AI continue to grow, they will produce ever increasing amounts of data and require faster processing.
- New frameworks, updated cloud computing architectures, more integrated AI/ML workloads, and new paradigms are bound to intercept with RTA and data pipelines.
The next couple of years should be very exciting.
Additional Resources:
- "Harnessing the Power of NiFi" by Timothy Spann
- "Real-Time Stream Processing With Hazelcast and StreamNative" by Timothy Spann and Fawaz Ghali, PhD
- Getting Started With Apache Iceberg Refcard by Ted Gooch
- Apache Kafka Patterns and Anti-Patterns Refcard by Abhishek Gupta
- Apache Kafka Essentials Refcard by Sudip Sengupta
- "Flink + Iceberg," Alibaba Cloud, Community Blog
- GitHub RTA examples
This is an article from DZone's 2023 Data Pipelines Trend Report.
For more:
Read the Report
Opinions expressed by DZone contributors are their own.
Comments