Medallion Architecture: Efficient Batch and Stream Processing Data Pipelines With Azure Databricks and Delta Lake
In this article, learn about Medallion Architecture and how to create processing pipelines with Azure Databricks and Delta Lake.
Join the DZone community and get the full member experience.
Join For FreeIn today's data-driven world, organizations need efficient and scalable data pipelines to process and analyze large volumes of data. Medallion Architecture provides a framework for organizing data processing workflows into different zones, enabling optimized batch and stream processing. This article explores the concepts of Medallion Architecture and demonstrates how to implement batch and stream processing pipelines using Azure Databricks and Delta Lake. Detailed code samples and explanations will be provided to illustrate each implementation step.
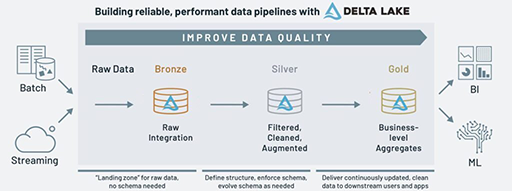
Medallion Architecture
Medallion Architecture is a data processing framework that organizes workflows into different zones: BRONZE, SILVER, and GOLD. Each zone has a specific purpose and plays a critical role in building efficient and scalable data pipelines. In Azure Databricks, this architecture can be implemented using Delta Lake to provide reliable data storage and processing capabilities.
BRONZE Zone
Data Ingestion and Storage The BRONZE zone is responsible for data ingestion and storage. In this zone, raw data is ingested from various sources such as files, databases, or streaming platforms. Azure Databricks provides connectors to these sources, allowing data to be read and processed. Once the data is ingested, it is stored in Delta Lake, a powerful storage layer built on cloud storage platforms like Azure Blob Storage or Azure Data Lake Storage. Delta Lake provides ACID transaction capabilities, schema evolution, and data reliability, ensuring data integrity and efficient storage.
The BRONZE zone acts as the foundation for the entire architecture, as it holds the raw data in its original form. Storing data in Delta Lake allows for schema flexibility and easy data exploration while providing a robust storage layer for subsequent processing steps.
SILVER Zone
Data Transformation and Preparation The SILVER zone focuses on data transformation and preparation. In this zone, data from the BRONZE zone is processed, cleansed, and transformed into a more structured format. Azure Databricks enables data engineers to apply transformations, aggregations, and business logic using Spark's DataFrame API or SQL queries.
Delta Lake plays a crucial role in the SILVER zone by providing features such as schema evolution and schema enforcement. Schema evolution allows for seamless handling of changes in data schemas over time, accommodating new columns or modifications while maintaining backward compatibility. Schema enforcement ensures data consistency by rejecting data that doesn't adhere to the defined schema, preventing data quality issues.
By leveraging Azure Databricks and Delta Lake in the SILVER zone, organizations can perform data cleansing, normalization, and enrichment to prepare the data for downstream analytics and reporting.
GOLD Zone
Batch and Stream Processing The GOLD zone is where the processed data from the SILVER zone is further analyzed, aggregated, and used for batch and stream processing. In this zone, Azure Databricks enables organizations to derive valuable insights, perform advanced analytics, generate reports, and train machine learning models.
- Batch Processing: For batch processing, data is read from Delta Lake in the SILVER zone and transformed using sophisticated analytics algorithms and business logic. Azure Databricks empowers data engineers and data scientists to leverage the distributed computing capabilities of Spark for large-scale data processing. The results of batch processing are then stored back into Delta Lake in the GOLD zone, creating a refined dataset for downstream consumption.
- Stream Processing: In the GOLD zone, Azure Databricks' Structured Streaming enables real-time stream processing. Streaming data is read from sources such as Kafka or Azure Event Hubs, and transformations are applied in near real-time. Stream processing allows organizations to monitor, react, and derive insights from streaming data as events unfold. The processed data is then stored in Delta Lake for further analysis or real-time reporting.
By implementing Medallion Architecture and leveraging Azure Databricks and Delta Lake, organizations can build robust and scalable data pipelines. This architecture provides a clear separation of responsibilities and optimizes data processing at each stage. With the power of Azure Databricks and Delta Lake, data engineers and data scientists can unlock the full potential of their data, driving meaningful insights and enabling informed decision-making.
Here's a detailed code block showcasing the implementation of Medallion Architecture with best practices for ingestion, data cleaning, deduplication, partitioning, bucketing, and optimization using Azure Databricks and Delta Lake:
# Import required libraries
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
# Initialize SparkSession
spark = SparkSession.builder \
.appName("Medallion Architecture") \
.config("spark.sql.legacy.allowCreatingManagedTableUsingNonemptyLocation", "true") \
.getOrCreate()
# Define BRONZE, SILVER, and GOLD paths
bronze_path = "dbfs:/mnt/bronze-zone/raw_data"
silver_path = "dbfs:/mnt/silver-zone/processed_data"
gold_path = "dbfs:/mnt/gold-zone/results"
# Ingestion: Reading data from various sources
df = spark.read.format("csv").option("header", "true").load("dbfs:/mnt/data-source/*.csv")
# Data Cleaning: Apply data cleaning and transformation operations
cleaned_df = df.withColumn("cleaned_column", regexp_replace(col("column"), "[^a-zA-Z0-9]", ""))
# Deduplication: Remove duplicates based on selected columns
dedup_df = cleaned_df.dropDuplicates(["cleaned_column"])
# Partitioning: Partition the data by a specific column for optimized query performance
partitioned_df = dedup_df.repartition("partition_column")
# Bucketing: Bucket the data to improve query performance
bucketed_df = partitioned_df.write.format("delta").bucketBy(8, "bucket_column").options(path=f"{silver_path}").saveAsTable("silver_data")
# Optimization: Optimize the Delta Lake table for better performance
spark.sql("OPTIMIZE silver_data ZORDER BY (column1)")
# Read data from the SILVER zone
silver_df = spark.read.format("delta").load(silver_path)
# Batch Processing: Perform batch processing on the SILVER data
batch_result = silver_df.filter(col("column2") > 50).groupBy("column1").agg(count("column1").alias("count"))
# Stream Processing: Process streaming data from Kafka
stream_df = spark.readStream.format("kafka").option("kafka.bootstrap.servers", "your_kafka_server").load()
processed_stream = stream_df.selectExpr("CAST(value AS STRING)")
# Write processed batch result to the GOLD zone
batch_result.write.format("delta").mode("overwrite").save(gold_path)
# Write processed streaming result to the GOLD zone
stream_query = processed_stream.writeStream.format("delta").option("checkpointLocation", "dbfs:/mnt/gold-zone/stream_checkpoint").start(gold_path)
# Await the termination of the streaming query
stream_query.awaitTermination()
Note:
- This code block serves as a starting point and should be adapted to your specific use case and environment.
- Ensure that you have the necessary access and permissions to read from/write to the specified paths in Delta Lake and other data sources.
- Customize the file paths, column names, and transformations according to your dataset and requirements.
- Adjust the partition and bucket column choices based on your data distribution and query patterns for optimal performance.
- Remember to manage checkpoint locations appropriately for stream processing to maintain fault tolerance.
Optimizing Medallion Architecture and the Lakehouse Pattern
Optimizing Medallion Architecture and the Lakehouse pattern using Azure Databricks and Delta Lake is crucial for achieving superior query performance and storage efficiency. Three key optimization techniques—OPTIMIZE, VACUUM, and Z-Order—play a vital role in maximizing the potential of data pipelines. By implementing these techniques, organizations can unlock the full power of their data assets.
The OPTIMIZE command in Delta Lake is a powerful tool for improving query performance. By rewriting and reorganizing data files, OPTIMIZE optimizes table layout and reduces the number of small files. This optimization technique enhances data retrieval efficiency and minimizes query execution time.
VACUUM, another optimization technique, reclaims storage space by removing unnecessary data files in Delta Lake. As data evolves and updates are performed, obsolete data files may accumulate, consuming valuable storage resources. VACUUM helps organizations reduce storage costs and enhance performance by reclaiming space and ensuring optimal data storage.
Lastly, Z-Order significantly improves query performance by organizing data within partitions. By colocating related data based on specific columns, Z-Order minimizes data skipping during queries, leading to faster data retrieval. Implementing Z-Order in Delta Lake tables enhances the efficiency of both the SILVER and GOLD zones.
Code sample to apply OPTIMIZE, VACUUM, and Z-Order:
# To apply OPTIMIZE in the SILVER zone, we can use the following code snippet:
spark.sql("OPTIMIZE silver_data ZORDER BY (column1)")
# To perform VACUUM in the GOLD zone, we can utilize the following code snippet:
spark.sql("VACUUM gold_data RETAIN 24 HOURS")
# Consider the following code snippet to utilize Z-Order:
spark.sql("ALTER TABLE silver_data CLUSTERED BY (column1) INTO 8 BUCKETS")
By leveraging these optimization techniques, organizations can maximize the efficiency and performance of their Medallion Architecture and Delta Lake implementations. The code samples provided demonstrate how to apply OPTIMIZE, VACUUM, and Z-Order in the SILVER and GOLD zones. Organizations can achieve faster query execution, reduce storage costs, and unlock the full potential of their data assets.
Scheduling the Data Pipelines
The above pipelines implemented with Azure Databricks and Delta Lake can be scheduled using Azure Data Factory (ADF).
Azure Data Factory is a powerful data integration service that allows you to schedule, orchestrate, and monitor data pipelines. By integrating Azure Databricks and Delta Lake pipelines with ADF, you can automate the execution of your Medallion Architecture workflows based on time triggers or event-driven scenarios.
To schedule the pipelines, follow these steps:
- Create an Azure Data Factory instance in the Azure portal.
- Define the pipelines in Azure Data Factory using the graphical user interface or by authoring JSON code. Here's an example of a pipeline definition in JSON:
{
"name": "BatchProcessingPipeline",
"properties": {
"activities": [
{
"name": "ExecuteDatabricksNotebook",
"type": "DatabricksNotebook",
"linkedServiceName": {
"referenceName": "AzureDatabricksLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"notebookPath": "/Users/your_username/notebooks/batch_processing",
"baseParameters": {
"inputPath": "dbfs:/mnt/silver-zone/processed_data",
"outputPath": "dbfs:/mnt/gold-zone/batch_results"
}
}
}
],
"start": {
"type": "Schedule",
"recurrence": {
"frequency": "Day",
"interval": 1
},
"timezone": "UTC",
"startTime": "2022-01-01T00:00:00Z"
}
}
}
In this example, the pipeline contains a single activity that executes a Databricks notebook. The notebook path and input/output parameters are specified in the typeProperties section. The pipeline is scheduled to run daily starting from the specified start time.
Create an Azure Databricks linked service in Azure Data Factory to establish a connection with your Azure Databricks workspace.
Publish and deploy the pipeline in Azure Data Factory.
Once the pipeline is deployed, Azure Data Factory takes care of triggering the pipeline execution based on the defined schedule. You can monitor the pipeline runs, view execution logs, and troubleshoot any issues directly from the Azure Data Factory portal.
By integrating Azure Databricks and Delta Lake pipelines with Azure Data Factory, organizations can automate the execution of their Medallion Architecture workflows, ensuring timely and efficient data processing.
Note: The code snippet provided is a simplified example for scheduling a batch-processing pipeline. You can adapt and extend the pipeline definition based on your specific requirements and add additional activities for other pipelines, such as streaming or data ingestion.
Please ensure you have the necessary permissions and access rights to create and manage Azure Data Factory pipelines, linked services, and resources.
Conclusion
In conclusion, Medallion Architecture, implemented with Azure Databricks and Delta Lake, provides a powerful framework for efficient data processing and analytics. By leveraging optimization techniques such as VACUUM, OPTIMIZE, and Z-Order, organizations can enhance query performance and storage efficiency, ensuring optimal utilization of resources. Additionally, integrating these pipelines with Azure Data Factory enables automated scheduling and orchestration, further streamlining the data workflows. With the combined power of Medallion Architecture, Delta Lake, Azure Databricks, and Azure Data Factory, organizations can unlock the full potential of their data, derive valuable insights, and make informed decisions to drive business success.
Opinions expressed by DZone contributors are their own.
Comments