Managing Schema Validation in a Data Lake Using Data Version Control
Open-source data version control tools can help you manage schema evolution, data transformations, and compatibility checks across multiple formats.
Join the DZone community and get the full member experience.
Join For FreeIt’s not uncommon for a data team to be dependent on many other “third parties” that send in the data. They often change the schema of the data without communicating anything or letting the data team know too late.
Whenever that happens, data pipelines break, and the data team needs to fix the data lake. This is a manual process filled with heavy-lifting tasks. Typically, teams engage in a blame game, trying to prove that the schema has changed.
But as they progressed, teams realized that it was smarter to simply prevent schemas from changing together in an automatic CI/CD way.
Schema changes and schema validation bring a lot of pain to teams, but there are a few solutions on the market that help with that — and, luckily, some are open-source.
This is a step-by-step tutorial on approaching the schema validation problem with the open-source data version control tool lakeFS.
What Is Schema Validation?
Schema validation allows you to create validation rules for your data lake, such as allowed data types and value ranges. It guarantees that the data saved in the lake adheres to an established schema, which describes the data's structure, format, and limitations.
Since your data lake can be filled with data coming from various sources with different schema definitions, enforcing a uniform schema across all the data in the lake is a challenge.
And one that definitely needs solving — if you don’t act fast, you’re going to see inconsistencies and mistakes all over your data processing.
Why Do We Need To Deal With Schema Validation?
Taking your time to manage schemas properly is worth it for these four reasons:
- Consistency — Data lakes often contain massive amounts of data from several sources. Without schema validation, you might end up with data in inconsistent or incorrect forms stored in the lake, resulting in issues during processing.
- Quality — Schema validation contributes to the good quality of the data kept in the lake by imposing data restrictions and standards. It helps you identify and flag data quality concerns, such as missing or inaccurate information, before they cause problems downstream.
- Efficiency — Schema validation expedites data processing and analysis by ensuring a uniform schema across all data in the lake. This, in turn, reduces the time and effort required to clean, convert, and analyze the data — and increases the overall efficiency of your data pipeline.
- Compliance — Many companies have to meet strict regulatory and compliance requirements. Schema validation helps to make sure that the data stored in the lake matches these standards, providing a clear audit trail of data lineage and quality.
Dealing With Schemas in Data Lakes Is Not All Roses
In a data warehouse, you’re dealing with a rigid data model and a rigid schema. Data lakes are the opposite of that. Most of the time, they end up containing a wide range of data sources.
Why does it matter? Because in data lakes, schema definitions can change between data sources, and your schema may evolve over time when new data is added. This makes enforcing a uniform schema across all data in the lake a massive challenge. If you fail to solve this issue, you’ll be dealing with data processing issues down the line.
But that’s not everything.
You can’t have one consistent schema due to the ever-increasing complexity of data pipelines built on top of data lakes. Data pipelines can include multiple processes and transformations, each requiring a unique schema definition.
The schema may vary as data is processed and modified, making it hard to ensure schema validation across the entire pipeline.
This is where a version control system can come in handy, right?
Implementing Data Version Control for Schema Validation in a Data Lake
lakeFS is an open-source tool that transforms your data lake into a Git-like repository, letting you manage it just like software engineers manage their code. This is what data version control is all about.
Like other source control systems, lakeFS has a feature called hooks, which are bespoke scripts or programs that the lakeFS platform can run in response to specified events or actions.
These events can include committing changes, merging branches, creating new branches, adding or removing tags, and so on. For example, when a merge happens, a pre-merge hook runs on the source branch before the merge is finished.
How does it all apply to schema validation?
You can create a pre-merge hook that verifies that the schema for Parquet files is not different from the current schema.
What You’ll Need To Have in Place
- A lakeFS server (you can install it or spin one up in the cloud for free).
- Optionally: You can use this sample-repo to launch a notebook that can be configured to connect to the lakeFS Server.
In this scenario, we'll create a delta table in an ingest branch and merge it into production. Next, we'll change the table's schema and try to merge it again, simulating the process of promoting data to production.
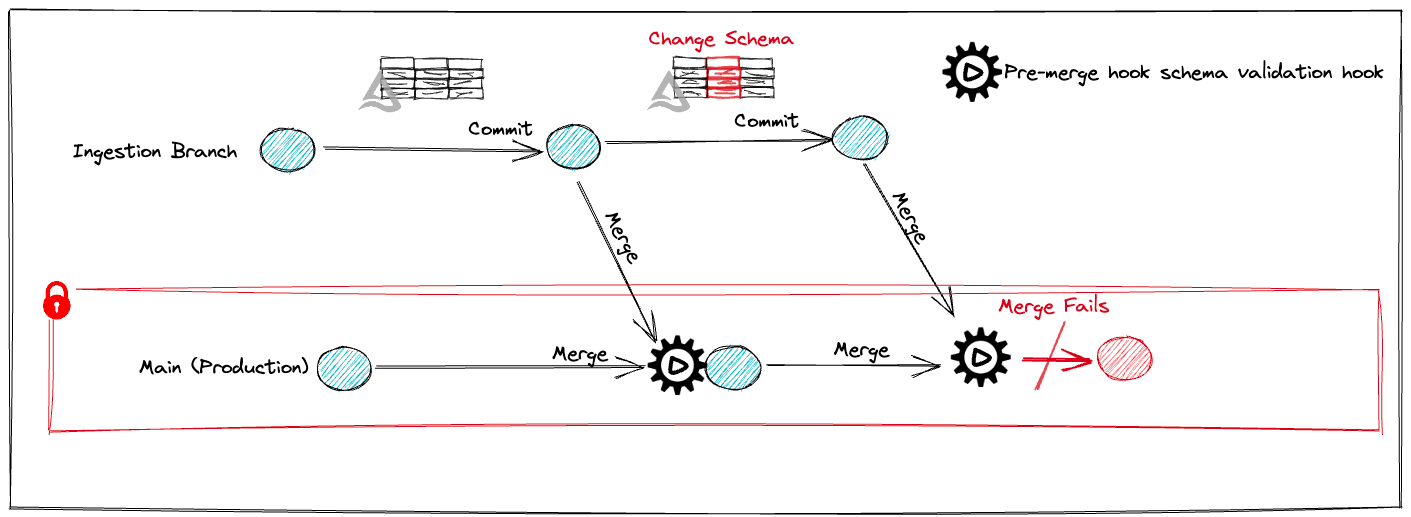
1. Setup
To begin, we'll set a number of global variables and install packages that will be used in this example, running in a Python notebook.
After setting up the lakeFS credentials, we can start creating some global variables containing the repository and branch names:
repo = "schema-validation-example-repo"
mainBranch = "main"
ingestionBranch = "ingestion_branch"Each lakeFS repository needs to have its own storage namespace, so we need to create one too:
storageNamespace = 's3://' # e.g. "s3://username-lakefs-cloud/"
In this example, we’re using AWS S3 storage. For everything to work out, your storage needs to be configured to operate with lakeFS, which works with AWS, Azure, Google Cloud, or on-premise object storage like MinIO.
If you’re running lakeFS in the cloud, you can link it to your storage by copying the storage namespace of the sample repository and attaching a string to it. So, if lakeFS Cloud provided this sample-repo for you:

You can configure it in the following way:
storageNamespace = 's3://lakefs-sample-us-east-1-production/AROA5OU4KHZHHFCX4PTOM:2ae87b7718e5bb16573c021e542dd0ec429b7ccc1a4f9d0e3f17d6ee99253655/my_random_string'
In our notebook, we will use Python code, so we must import the lakeFS Python client packages too:
import lakefs_client
from lakefs_client import models
from lakefs_client.client import LakeFSClient
import os
from pyspark.sql.types import ByteType, IntegerType, LongType, StringType, StructType, StructField
Next, we configure our client:
%xmode Minimal
if not 'client' in locals():
# lakeFS credentials and endpoint
configuration = lakefs_client.Configuration()
configuration.username = lakefsAccessKey
configuration.password = lakefsSecretKey
configuration.host = lakefsEndPoint
client = LakeFSClient(configuration)
print("Created lakeFS client.")We will create delta tables in this example, so we need to include the following packages:
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages io.delta:delta-core_2.12:2.0.0 --conf "spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension" --conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog" pyspark-shell'
LakeFS exposes an S3 Gateway, which allows applications to interface with lakeFS in the same way that they would communicate with S3. To configure the gateway, follow these steps:
from pyspark.context import SparkContext
from pyspark.sql.session import SparkSession
sc = SparkContext.getOrCreate()
spark = SparkSession(sc)
sc._jsc.hadoopConfiguration().set("fs.s3a.access.key", lakefsAccessKey)
sc._jsc.hadoopConfiguration().set("fs.s3a.secret.key", lakefsSecretKey)
sc._jsc.hadoopConfiguration().set("fs.s3a.endpoint", lakefsEndPoint)
sc._jsc.hadoopConfiguration().set("fs.s3a.path.style.access", "true")We’re ready to start using lakeFS version control at scale in our notebook.
2. Creating the Repository and Hooks
We will create our repository using the Python client:
client.repositories.create_repository(
repository_creation=models.RepositoryCreation(
name=repo,
storage_namespace=storageNamespace,
default_branch=mainBranch))In this case, we'll use a pre-merge hook to ensure that the schema hasn't changed. Action files should be submitted to the lakeFS repository with the prefix _lakefs_actions/. Failure to parse an action file will result in a failed Run.
We will submit the following hook configuration action file, pre-merge-schema-validation.yaml:
#Parquet schema Validator
#Args:
# - locations (list of strings): locations to look for parquet files under
# - sample (boolean): whether reading one new/changed file per directory is enough, or go through all of them
#Example hook declaration: (_lakefs_actions/pre-merge-schema-validation.yaml):
name: pre merge checks on main branch
on:
pre-merge:
branches:
- main
hooks:
- id: check_schema_changes
type: lua
properties:
script_path: scripts/parquet_schema_change.lua # location of this script in the repository
args:
sample: false
locations:
- tables/customers/
This file (pre-merge-schema-validation.yaml) is stored in the subfolder LuaHooks in our example repo. We must submit the file to the lakeFS repository under the folder _lakefs_actions:
hooks_config_yaml = "pre-merge-schema-validation.yaml"
hooks_prefix = "_lakefs_actions"
with open(f'./LuaHooks/{hooks_config_yaml}', 'rb') as f:
client.objects.upload_object(repository=repo,
branch=mainBranch,
path=f'{hooks_prefix}/{hooks_config_yaml}',
content=f
)We just set up an action script to run scripts/parquet_schema_change.lua before merging into the main.
The script itself (parquet_schema_change.lua) will then be created and uploaded to the scripts directory. As you can see, we’re employing an embedded Lua VM to run hooks without relying on other components.
This file is also located in the LuaHooks subfolder in the sample-repo:
--[[
Parquet schema validator
Args:
- locations (list of strings): locations to look for parquet files under
- sample (boolean): whether reading one new/changed file per directory is enough, or go through all of them
]]
lakefs = require("lakefs")
strings = require("strings")
parquet = require("encoding/parquet")
regexp = require("regexp")
path = require("path")
visited_directories = {}
for _, location in ipairs(args.locations) do
after = ""
has_more = true
need_more = true
print("checking location: " .. location)
while has_more do
print("running diff, location = " .. location .. " after = " .. after)
local code, resp = lakefs.diff_refs(action.repository_id, action.branch_id, action.source_ref, after, location)
if code ~= 200 then
error("could not diff: " .. resp.message)
end
for _, result in pairs(resp.results) do
p = path.parse(result.path)
print("checking: '" .. result.path .. "'")
if not args.sample or (p.parent and not visited_directories[p.parent]) then
if result.path_type == "object" and result.type ~= "removed" then
if strings.has_suffix(p.base_name, ".parquet") then
-- check it!
code, content = lakefs.get_object(action.repository_id, action.source_ref, result.path)
if code ~= 200 then
error("could not fetch data file: HTTP " .. tostring(code) .. "body:\n" .. content)
end
schema = parquet.get_schema(content)
for _, column in ipairs(schema) do
for _, pattern in ipairs(args.column_block_list) do
if regexp.match(pattern, column.name) then
error("Column is not allowed: '" .. column.name .. "': type: " .. column.type .. " in path: " .. result.path)
end
end
end
print("\t all columns are valid")
visited_directories[p.parent] = true
end
end
else
print("\t skipping path, directory already sampled")
end
end
-- pagination
has_more = resp.pagination.has_more
after = resp.pagination.next_offset
end
end
We will upload the file (this time parquet_schema_change.lua) from the LuaHooks directory to our lakeFS repository at the location specified in the action configuration file (i.e., inside the scripts folder):
hooks_config_yaml = "pre-merge-schema-validation.yaml"
hooks_prefix = "_lakefs_actions"
with open(f'./LuaHooks/{hooks_config_yaml}', 'rb') as f:
client.objects.upload_object(repository=repo,
branch=mainBranch,
path=f'{hooks_prefix}/{hooks_config_yaml}',
content=f
)We must commit the changes after submitting the action file for them to take effect:
client.commits.commit(
repository=repo,
branch=mainBranch,
commit_creation=models.CommitCreation(
message='Added hook config file and schema validation scripts'))If we switch to the lakeFS UI, we should see the following directory structure and files beneath the main directory:
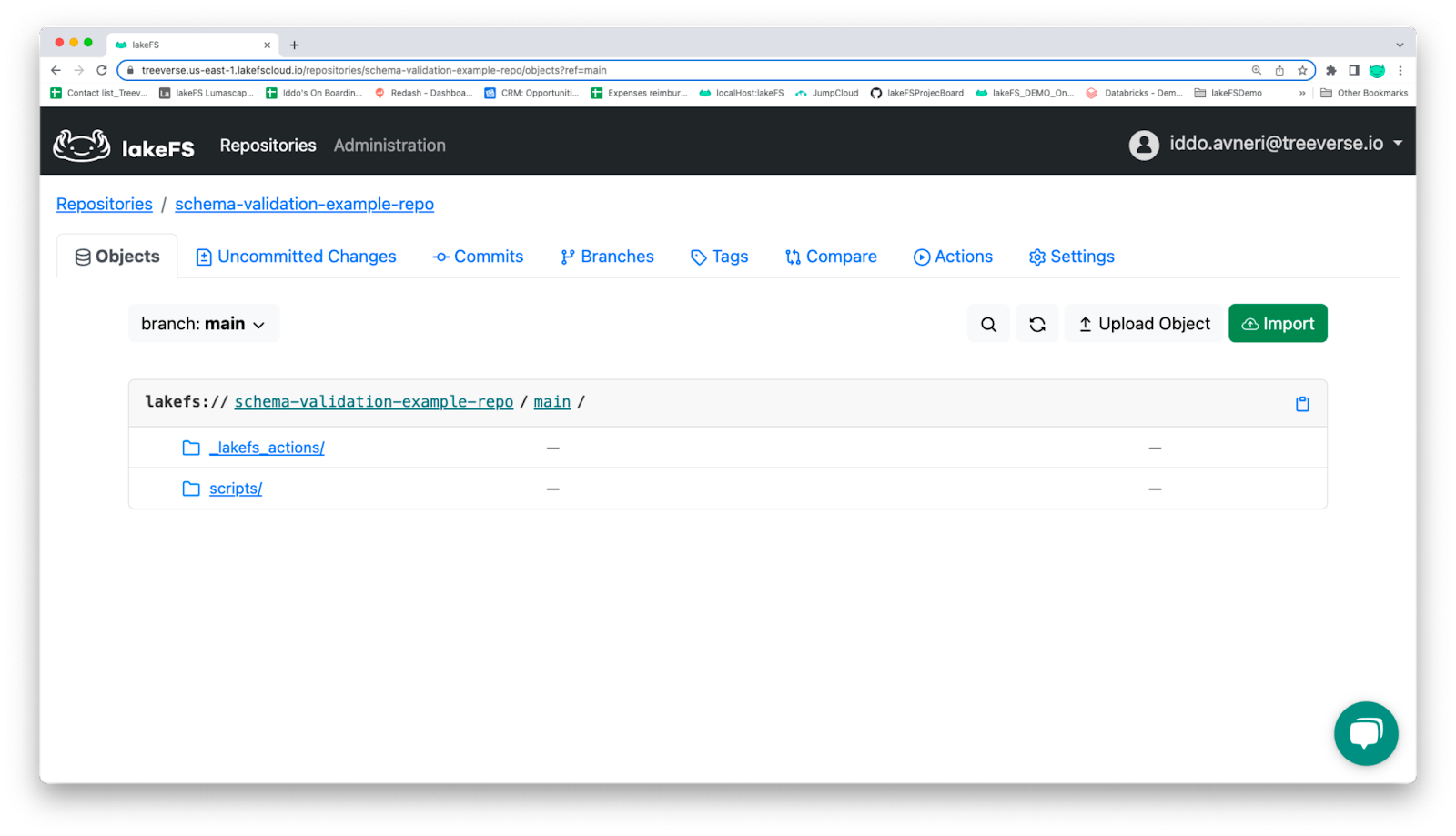
The lakeFS UI’s directory structure
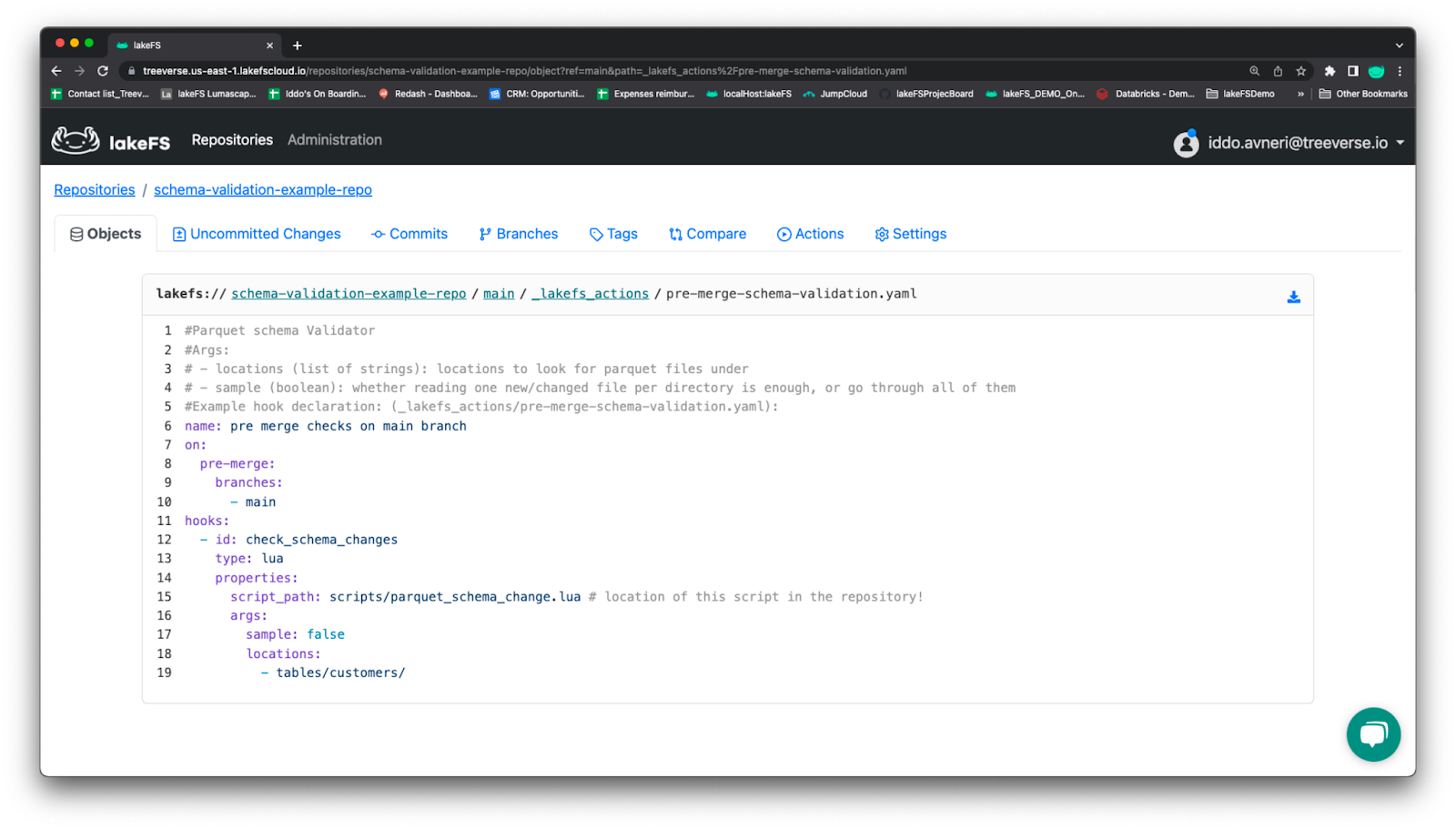
Pre-merge schema validation as shown in the lakeFS UI
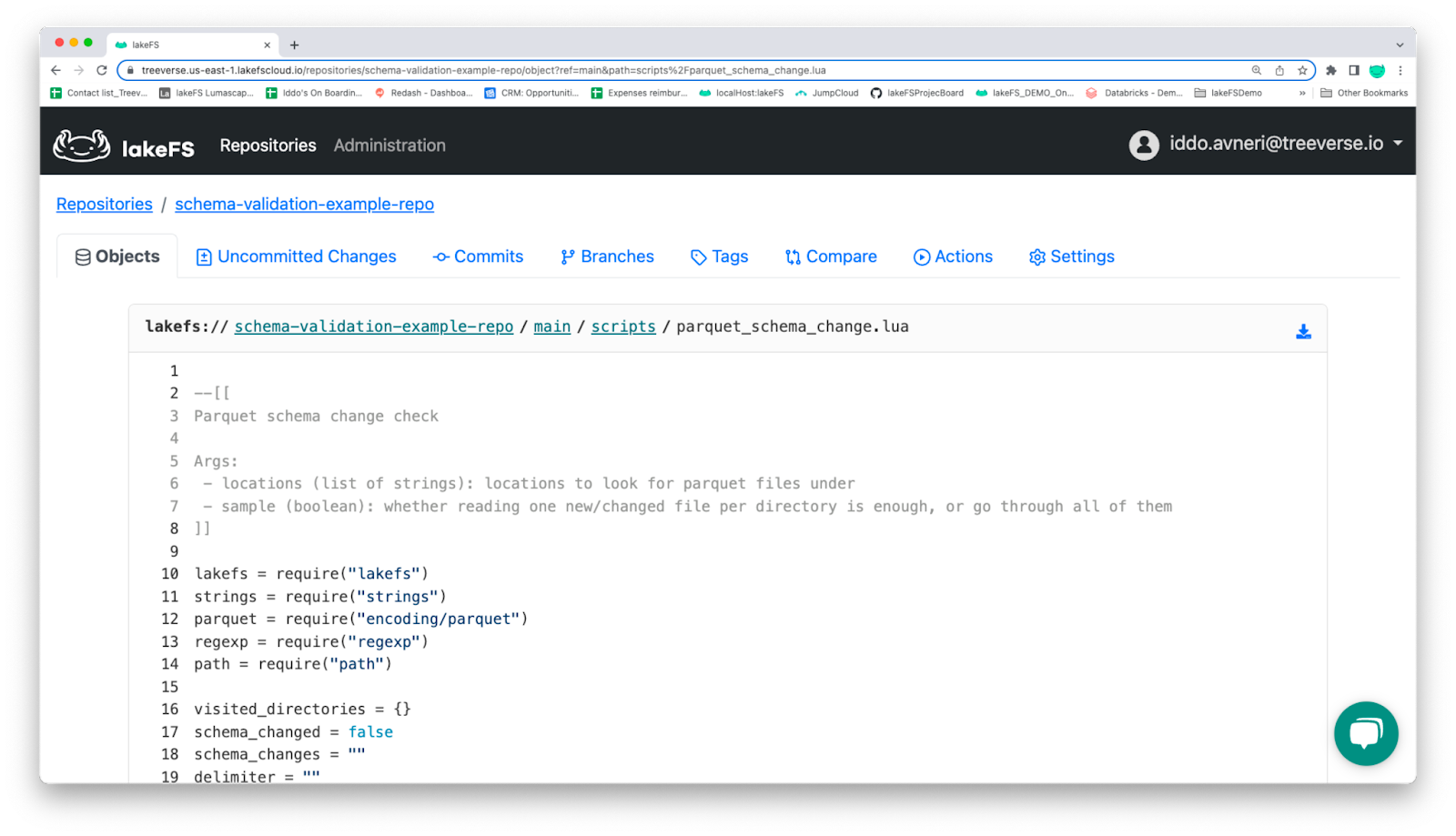
Schema validation scripts as seen in the lakeFS UI
3. Running the First ETL Using the Original Schema
Ingestion and transformation can be performed on a distinct branch from the production (main) branch in lakeFS.
We will establish an ingestion branch:
client.branches.create_branch(
repository=repo,
branch_creation=models.BranchCreation(
name=ingestionBranch, source=mainBranch))Following that, we will use the Kaggle dataset Orion Star – Sports and outdoors RDBMS dataset. Let’s use Customer.csv, which we can upload to our sample repository from data/samples/OrionStar/.
First, the table schema needs to be defined:
customersSchema = StructType([
StructField("User_ID", IntegerType(), False),
StructField("Country", StringType(), False),
StructField("Gender", StringType(), False),
StructField("Personal_ID", IntegerType(), True),
StructField("Customer_Name", StringType(), False),
StructField("Customer_FirstName", StringType(), False),
StructField("Customer_LastName", StringType(), False),
StructField("Birth_Date", StringType(), False),
StructField("Customer_Address", StringType(), False),
StructField("Street_ID", LongType(), False),
StructField("Street_Number", IntegerType(), False),
StructField("Customer_Type_ID", IntegerType(), False)
])
Then, from the CSV file, we will create a delta table and submit it to our repository:
customersTablePath = f"s3a://{repo}/{ingestionBranch}/tables/customers"
df = spark.read.csv('./data/samples/OrionStar/CUSTOMER.csv',header=True,schema=customersSchema)
df.write.format("delta").mode("overwrite").save(customersTablePath)
We need to commit changes:
client.commits.commit(
repository=repo,
branch=ingestionBranch,
commit_creation=models.CommitCreation(
message='Added customers Delta table',
metadata={'using': 'python_api'}))And then, using a merge, send the data to production:
client.refs.merge_into_branch(
repository=repo,
source_ref=ingestionBranch,
destination_branch=mainBranch)The sequence of schema validation that has been completed:
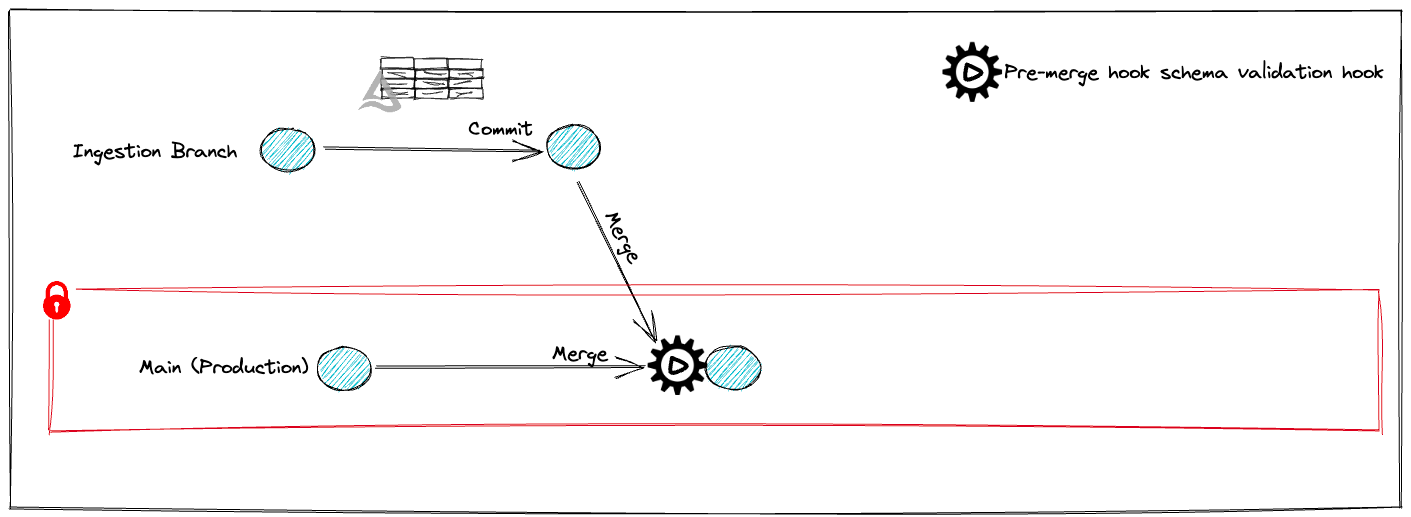
4. Modify the Schema and Attempt To Move the Table to Production
To make things easier, we'll rename one of the columns. Let’s replace Country with Country_name:
customersSchema = StructType([
StructField("User_ID", IntegerType(), False),
StructField("Country_Name", StringType(), False), # Column name changes from Country to Country_name
StructField("Gender", StringType(), False),
StructField("Personal_ID", IntegerType(), True),
StructField("Customer_Name", StringType(), False),
StructField("Customer_FirstName", StringType(), False),
StructField("Customer_LastName", StringType(), False),
StructField("Birth_Date", StringType(), False),
StructField("Customer_Address", StringType(), False),
StructField("Street_ID", LongType(), False),
StructField("Street_Number", IntegerType(), False),
StructField("Customer_Type_ID", IntegerType(), False)
])
In the ingest branch, let’s recreate the delta table:
customersTablePath = f"s3a://{repo}/{ingestionBranch}/tables/customers"
df = spark.read.csv('./data/samples/OrionStar/CUSTOMER.csv',header=True,schema=customersSchema)
df.write.format("delta").mode("overwrite").option("overwriteSchema", "true").save(customersTablePath)
])Changes need to be committed:
client.commits.commit(
repository=repo,
branch=ingestionBranch,
commit_creation=models.CommitCreation(
message='Added customers table with schema changes',
metadata={'using': 'python_api'}))
And then, we can try to get the data into production:
client.commits.commit(
repository=repo,
branch=ingestionBranch,
commit_creation=models.CommitCreation(
message='Added customer tables with schema changes!',
metadata={'using': 'python_api'}))
We got a precondition Failed error as a result of schema modifications. The pre-merge hook thwarted the promotion. So, this data won’t be used in production:
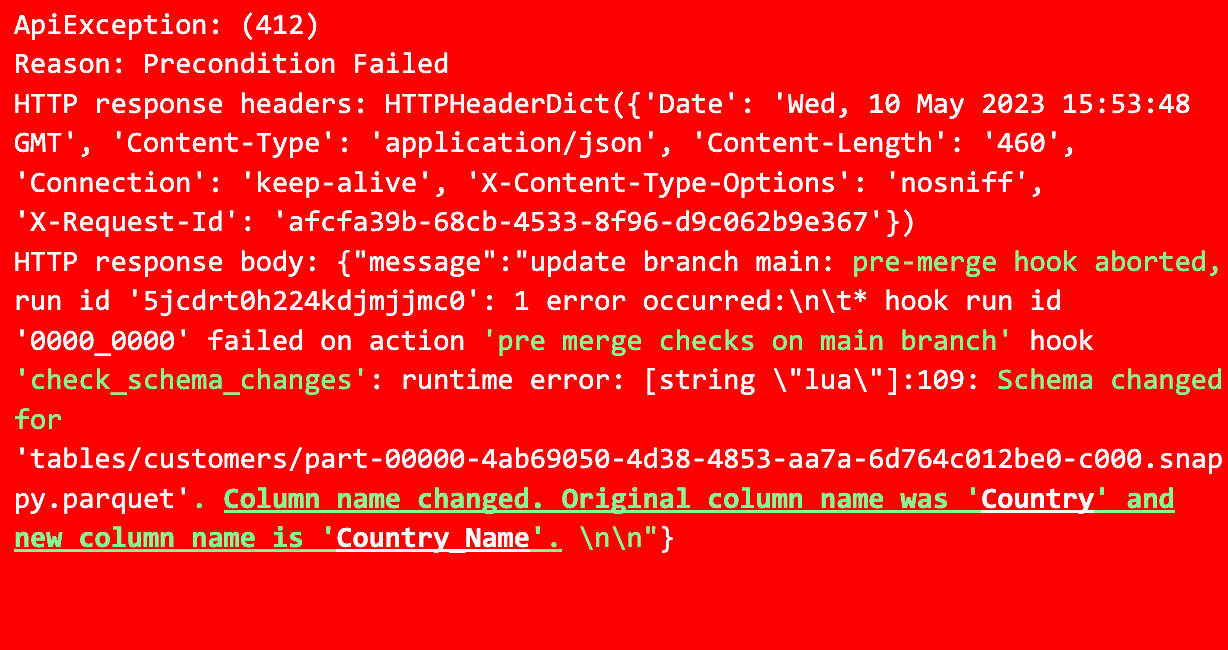
From the lakeFS UI, we can navigate to the repository and select the "Actions" option. Next, we click on the failed action's Run ID, pick "pre merge checks on main branch," expand check_schema_changes, and view the error message.
Wrap Up
Due to the heterogeneous and raw nature of the stored data, schema validation on a data lake is critical but difficult. Managing schema evolution, data transformations, and compatibility checks across multiple formats means that every data practitioner needs some pretty powerful methodologies and tools.
The decentralized nature of data lakes, where numerous users and systems can edit data, complicates schema validation even further. Validation of schemas is critical for data governance, integration, and reliable analytics.
Solutions like the pre-merge hook I showed above help verify schema files before merging them into the production branch. It comes in handy for guaranteeing data integrity and preventing incompatible schema changes from being merged into the main branch. And it adds an additional layer of quality control, keeping data more consistent.
Opinions expressed by DZone contributors are their own.
Comments