Enhancing Performance With Data Modeling: Techniques and Best Practices for Optimization in Snowflake
Explore advanced data modeling techniques, focusing on star schema, snowflake schema, and hybrid approaches.
Join the DZone community and get the full member experience.
Join For FreeSnowflake is a powerful cloud-based data warehousing platform known for its scalability and flexibility. To fully leverage its capabilities and improve efficient data processing, it's crucial to optimize query performance.
Understanding Snowflake Architecture
Let’s briefly cover Snowflake architecture before we deal with data modeling and optimization techniques. Snowflake’s architecture consists of three main layers:
- Storage layer: Where data is stored in a compressed format
- Compute layer: Provides the computational resources for querying and processing data
- Cloud services layer: Manages metadata, security, and query optimization
Effective data modeling is a crucial design activity in optimizing data storage, querying performance, and overall data management in Snowflake. Snowflake cloud architecture allows us to design and implement various data modeling methodologies. Each of the methodologies offers a unique benefit depending on the business requirement.
The current article explores advanced data modeling techniques and focuses on a star schema, snowflake schema, and hybrid approaches.
What Is Data Modeling?
Data modeling structures the data in a way that supports efficient storage and retrieval. Snowflake is a cloud-based data warehouse that provides a scalable platform for implementing complex data models that cater to various analytical needs. Effective data modeling ensures optimized performance, easy to maintain, and streamlined data processing.
What Is Star Schema?
The star schema is the most popular data modeling technique used in data warehousing. It consists of a central fact table connected to multiple dimension tables. Star schema is known for its simplicity and ease of use, making it a preferred choice for all analytical applications.
Structure of Star Schema
- Fact table: Contains quantitative data and metrics; It records transactions or events that typically include foreign keys to dimension tables.
- Dimension tables: Contains descriptive attributes related to the fact data; it provides the context of the fact dataset that you analyze and helps in filtering, grouping, and aggregating data.
Example
Let’s analyze sales data.
- Fact Table:
sales
CREATE OR REPLACE TABLE sales (
sale_id INT,
product_id INT,
customer_id INT,
date_id DATE,
amount DECIMAL
);- Dimension Tables:
products,customers,dates
CREATE OR REPLACE TABLE products (
product_id INT,
product_name STRING,
category STRING
);
CREATE OR REPLACE TABLE customers (
customer_id INT,
customer_name STRING,
city STRING
);
CREATE OR REPLACE TABLE dates (
date_id DATE,
year INT,
month INT,
day INT
);- To find the total sales amount by product category:
SELECT p.category, SUM(s.amount) AS total_sales
FROM sales s
JOIN products p ON s.product_id = p.product_id
GROUP BY p.category;What Is Snowflake Schema?
The snowflake schema is the normalized form of the star schema. It further organizes dimension tables into multiple related tables (which are hierarchical) to design and implement the snowflake schema. This method helps reduce data redundancy and improves data integrity.
Structure of Snowflake Schema
- Fact table: It is similar to the star schema.
- Normalized dimension tables: Dimension tables are split into sub-dimension tables, resulting in a snowflake schema.
Example
The above example used for star schema is further expanded to snowflake schema as below:
- Fact Table:
sales(same as in the star schema) - Dimension Tables:
CREATE OR REPLACE TABLE products (
product_id INT,
product_name STRING,
category_id INT
);
CREATE OR REPLACE TABLE product_categories (
category_id INT,
category_name STRING
);
CREATE OR REPLACE TABLE customers (
customer_id INT,
customer_name STRING,
city_id INT
);
CREATE OR REPLACE TABLE cities (
city_id INT,
city_name STRING
);
CREATE OR REPLACE TABLE dates (
date_id DATE,
year INT,
month INT,
day INT
);- To find the total sales amount by
city:
SELECT c.city_name, SUM(s.amount) AS total_sales
FROM sales s
JOIN customers cu ON s.customer_id = cu.customer_id
JOIN cities c ON cu.city_id = c.city_id
GROUP BY c.city_name;Hybrid Approaches
Hybrid data modeling combines elements of both the star and snowflake schemas to balance performance and normalization. This approach helps address the limitations of each schema type and is useful in complex data environments.
Structure of Hybrid Schema
- Fact table: Similar to star and snowflake schemas.
- Dimension tables: Some dimensions may be normalized (Snowflake style) while others are denormalized (star style) to balance between normalization and performance.
Example
Combining aspects of both schemas:
- Fact Table:
sales - Dimension Tables:
CREATE OR REPLACE TABLE products (
product_id INT,
product_name STRING,
category STRING
);
CREATE OR REPLACE TABLE product_categories (
category_id INT,
category_name STRING
);
CREATE OR REPLACE TABLE customers (
customer_id INT,
customer_name STRING,
city_id INT
);
CREATE OR REPLACE TABLE cities (
city_id INT,
city_name STRING
);
CREATE OR REPLACE TABLE dates (
date_id DATE,
year INT,
month INT,
day INT
);In this hybrid approach, products use denormalized dimensions for performance benefits, while product categories remain normalized.
- To analyze total sales by product category:
SELECT p.category, SUM(s.amount) AS total_sales
FROM sales s
JOIN products p ON s.product_id = p.product_id
GROUP BY p.category;Best Practices for Data Modeling in Snowflake
- Understand the data and query patterns: Choose the schema that best fits your organizational data and typical query patterns.
- Optimize for performance: De-normalize where performance needs to be optimized and use normalization to reduce redundancy and improve data integrity.
- Leverage Snowflake features: By utilizing Snowflake capabilities, such as clustering keys and materialized views, we could enhance the performance and manage large datasets efficiently.
The advanced data modeling feature of Snowflake involves selecting the appropriate schema methodology —star, snowflake, or hybrid — to optimize data storage and improve query performance.
Each schema has its own and unique advantages:
- The star schema for simplicity and speed
- The snowflake schema for data integrity and reduced redundancy
- Hybrid schemas for balancing both aspects
By understanding and applying these methodologies effectively, organizations can achieve efficient data management and derive valuable insights from their data journey.
Performance Optimization in Snowflake
To leverage the capabilities and ensure efficient data processing, it's crucial to optimize query performance and understand the key techniques and best practices to optimize the performance of Snowflake, focusing on clustering keys, caching strategies, and query tuning.
What Are Clustering Keys?
Clustering keys help in determining the physical ordering of data within tables, which can significantly impact query performance when dealing with large datasets. Clustering keys help Snowflake efficiently locate and retrieve data by reducing the amount of scanned data. These help in filtering data on specific columns or ranges.
How to Implement Clustering Keys
- Identify suitable columns: Choose columns that are frequently used in filter conditions or join operations. For example, if your queries often filter by
order_date, it’s a good candidate for clustering. - Create a table with Clustering Keys:
CREATE OR REPLACE TABLE sales (
order_id INT,
customer_id INT,
order_date DATE,
amount DECIMAL
)
CLUSTER BY (order_date);The sales table is clustered by the order_date column.
3. Re-clustering: Data distribution alters over a period necessitating reclustering. The RECLUSTER command can be used to optimize clustering.
ALTER TABLE sales RECLUSTER;
Caching StrategiesSnowflake has various caching mechanisms to enhance query performance. We have 2 types of caching mechanisms: result caching and data caching.
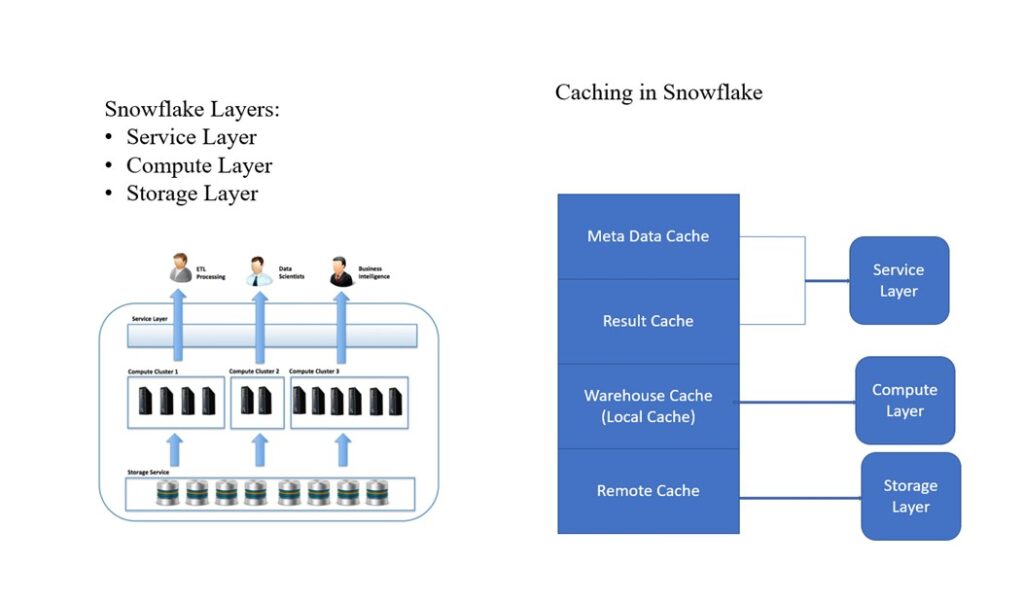
Result Caching
Snowflake caches the results of queries in the memory to avoid redundant computations. If the same query is submitted to run again with the same parameters, Snowflake can return the cached result instantly.
Best Practices for Result Caching
- Ensure queries are written in a consistent manner to take advantage of result caching.
- Avoid unnecessary complex computations if the result has been cached.
Data Caching
Data caching occurs at the compute layer. When a query accesses data, it’s cached in the local compute node’s memory for faster retrievals.
Best Practices for Data Caching
- Use warehouses appropriately: Use dedicated warehouses for high-demand queries to ensure sufficient caching resources.
- Scale warehouses: Increase the size of the compute warehouse if you experience performance issues due to insufficient caching to avoid disk spillage.
What Is Disk Spillage?
Disk spillage, also known as disk spilling, occurs when data that would normally fit into a system's memory (RAM) exceeds the available memory capacity, forcing the system to temporarily store the excess data on disk storage. This process is common in various computing environments, including databases and large-scale data processing systems.
Types of Spillage
- Memory overload: When an application or database performs operations that require more memory than is available, it triggers disk spillage.
- Temporary storage: To handle the excess data, the system writes the overflow to disk storage. This usually involves creating temporary files or using swap space.
- Performance impact: Disk storage is significantly slower than RAM. Therefore, disk spillage can lead to performance degradation because accessing data from disk is much slower compared to accessing it from memory.
- Use cases: Disk spillage often occurs in scenarios like sorting large datasets, executing complex queries, or running large-scale analytics operations.
- Management: Proper tuning and optimization can mitigate the effects of disk spillage. This might involve increasing available memory, optimizing queries, or leveraging more efficient algorithms to reduce the need for disk storage.
What Is Query Tuning?
Query tuning optimizing SQL queries to reduce execution time and resource consumption.
Optimize SQL Statements
- Use proper joins: Prefer
INNER JOINoverOUTER JOIN, if possible
SELECT a.*, b.*
FROM orders a
INNER JOIN customers b ON a.customer_id = b.customer_id;2. Avoid SELECT *: Select only the necessary columns to reduce data processing.
SELECT order_id, amount
FROM sales
WHERE order_date >= '2023-01-01';3. Leverage window functions: Use window functions for calculations that must be performed across rows.
SELECT order_id, amount,
SUM(amount) OVER (PARTITION BY customer_id) AS total_amount
FROM sales;
Analyze Query Execution Plans
Use the QUERY_HISTORY view to analyze query performance and identify bottlenecks.
SELECT *
FROM TABLE(QUERY_HISTORY())
WHERE QUERY_TEXT ILIKE '%sales%'
ORDER BY START_TIME DESC;Use Materialized Views
Materialized views store the results of complex queries and can be refreshed periodically. They improve performance for frequently accessed and complex queries.
CREATE OR REPLACE MATERIALIZED VIEW mv_sales_summary AS
SELECT order_date, SUM(amount) AS total_amount
FROM sales
GROUP BY order_date;Monitoring and Maintenance
Continuous monitoring and maintenance are vital for performance optimization. Review and optimize clustering keys, analyze query performance, and adjust warehouse sizes based on query loads.
Key Tools for Monitoring
- Snowflake’s Query Profile: Provides insights into query execution
- Resource
- Monitors: Help track compute resource usage and manage costs
Optimizing performance in Snowflake involves the effective use of clustering keys, strategic caching, and meticulous query tuning. By implementing the above techniques and best practices, organizations can enhance query performance, reduce resource consumption, and achieve efficient data processing.
Continuous monitoring and proactive maintenance can ensure sustained performance and scalability in the Snowflake environment.
Final Thoughts
By understanding and applying the methodologies discussed above on data models and query optimizations, organizations can achieve efficient data management and derive valuable insights throughout the data journey.
Opinions expressed by DZone contributors are their own.
Comments