Have LLMs Solved the Search Problem?
LLMs, while strong in content generation, need techniques like semantic chunking and vector embeddings to address the search problem in complex data environments.
Join the DZone community and get the full member experience.
Join For FreeThe advent of large language models (LLMs) has catalyzed a paradigm shift in information retrieval and human-computer interaction. These models, trained on vast corpora of text and optimized for predictive linguistic tasks, have demonstrated substantial efficacy in responding to queries, summarizing textual content, and generating contextually relevant information.
However, despite their impressive generative capabilities, LLMs do not inherently resolve the complexities of search and retrieval in structured and unstructured data landscapes. Instead, they require augmentation with advanced techniques such as semantic chunking, vector embeddings, and context-aware personalization to optimize precision and recall.
This article examines the inherent limitations of LLMs in addressing the search problem, highlighting the disconnect between content generation and retrieval efficacy. It explores strategies to enhance their utility within search architectures through sophisticated indexing, ranking, and contextual filtering methodologies. We will take a case study approach to illustrate what happens behind the scenes when using LLMs for information retrieval.
Case Study: A Restaurant Owner's Query
Consider a user in Seattle, Washington, researching the policies for opening a restaurant in New York. They seek information on wages, working hours, and licensing requirements. Now, imagine developing an LLM-based chatbot to assist restaurant owners across the U.S., requiring policy details from multiple states and counties.
The Disparity Between Content Generation and Retrieval
A principal challenge in enterprise search systems is the asymmetry between content creation and user-centric information retrieval. Technical documents, corporate policies, and domain-specific knowledge bases often reside in heterogeneous, unstructured formats, making efficient retrieval difficult. While LLMs can extract and synthesize insights from such corpora, their reliance on probabilistic token sequencing rather than deterministic indexing mechanisms introduces variability and inconsistency in result precision.
Traditional search architectures leverage metadata-driven indexing, keyword-based retrieval heuristics, and relevance-ranking algorithms to enhance document discoverability. In contrast, LLMs prioritize fluency and contextual coherence over strict factual retrieval, often resulting in hallucinations — responses that, while syntactically plausible, may be factually inaccurate or semantically misaligned with user intent.
LLMs Are Stateless by Design
A key aspect of LLMs is their stateless nature: they do not retain the memory of past interactions beyond a single input-output exchange. Each query is processed independently unless the conversational context is explicitly provided within the input prompt.
Yet, applications like ChatGPT and Claude appear to remember the context. This is achieved through techniques at the application layer, such as:
- Conversation history inclusion. Passing prior interactions in the prompt to maintain context.
- External API. Integrating real-time data sources for updated information.
- Session-based architectures. Implementing logic to track and manage conversations.
- Personalization. Storing user attributes to tailor responses.
At the core, LLMs themselves do not retain past conversations. Instead, the application must provide a relevant historical context within each prompt. Various optimizations, such as summarizing prior conversations instead of including the entire history, can enhance efficiency. For now, we can assume that the application owner passes three major inputs to LLM:
- Latest user query
- User attributes to the user for personalization
- Conversation history
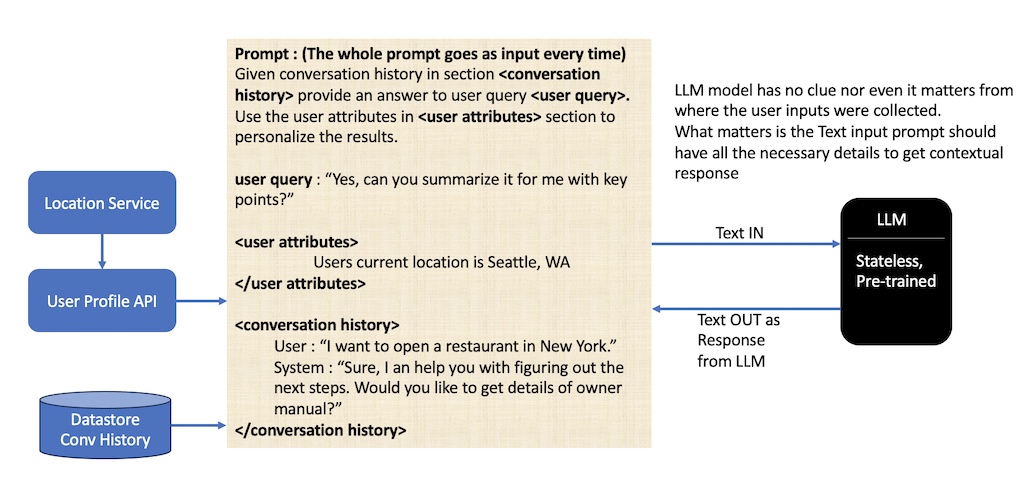
Moving Towards Search: How RAG Becomes Relevant in Search
In the above design, if only three inputs (user query, user attributes, and conversation history) are passed, the LLM relies solely on its pre-trained knowledge, which may not include the latest policy updates. To address this, a fourth input — the relevant policy document — is required. This is where retrieval-augmented generation (RAG) comes into play:
- Retrieve. Fetch the latest policy document from a source such as AWS S3 or a database.
- Augment. Incorporate the retrieved content into the prompt.
- Generate. Use the augmented prompt to generate a response, ensuring the LLM prioritizes real-time, factual information over pre-trained knowledge.
The key aspect of RAG is directing the LLM to rely on the retrieved document rather than outdated training data, thereby significantly improving the relevance and accuracy of responses.
In the current design, if only three inputs — user query, user attributes, and conversation history — are passed, the LLM relies solely on its pre-trained knowledge. While it may have encountered relevant policies during training, its responses risk being outdated and even incorrect, as they reflect the policy’s status at the time of training rather than real-time updates.
To ensure accuracy, a fourth input — the relevant policy document — must be introduced. Since LLMs are stateless, they do not retain prior knowledge beyond a session. To incorporate real-time policies, the system must download, parse, and format the document before passing it into the prompt. This structured approach ensures responses are based on current policies rather than outdated training data.
By explicitly directing the LLM to rely on retrieved documents, RAG bridges the gap between search and generation, transforming the LLM into a dynamic, real-time knowledge system rather than a static information repository. The following shows an updated prompt, including the policy document as another input to LLM.

What Is the Context Window Hard Limitation of LLMs?
LLMs have a fixed context length due to computational and memory constraints. The context window of an LLM refers to the maximum number of tokens (words, subwords, or characters, depending on the model) that the model can process in a single input prompt. This includes both the input text and the generated output. The size of the context window is a hard limitation imposed by the model architecture; for example, GPT-4 has a 128K limit, while Claude Sonnet has a 200K limit.
If an input exceeds this limit, it must be truncated or processed using techniques like:
- Sliding windows. Keeping recent tokens and discarding older ones.
- Summarization. Condensing past interactions to fit within the limit.
- Memory augmentation. Using external storage (e.g., vector databases) to retrieve relevant past interactions dynamically and
- Picking relevant chunks of documents. When RAG is used, the trick is to pick the most relevant parts from documents to fit into the context length.
How to Search Across Documents When Combined Size Exceeds Document Context Window
Several advanced methodologies must be integrated into the retrieval pipeline to address the limitations of LLMs in searching across a large set of documents for RAG scenarios.
We follow the following architecture to solve this problem in major enterprise-level chatbot applications:
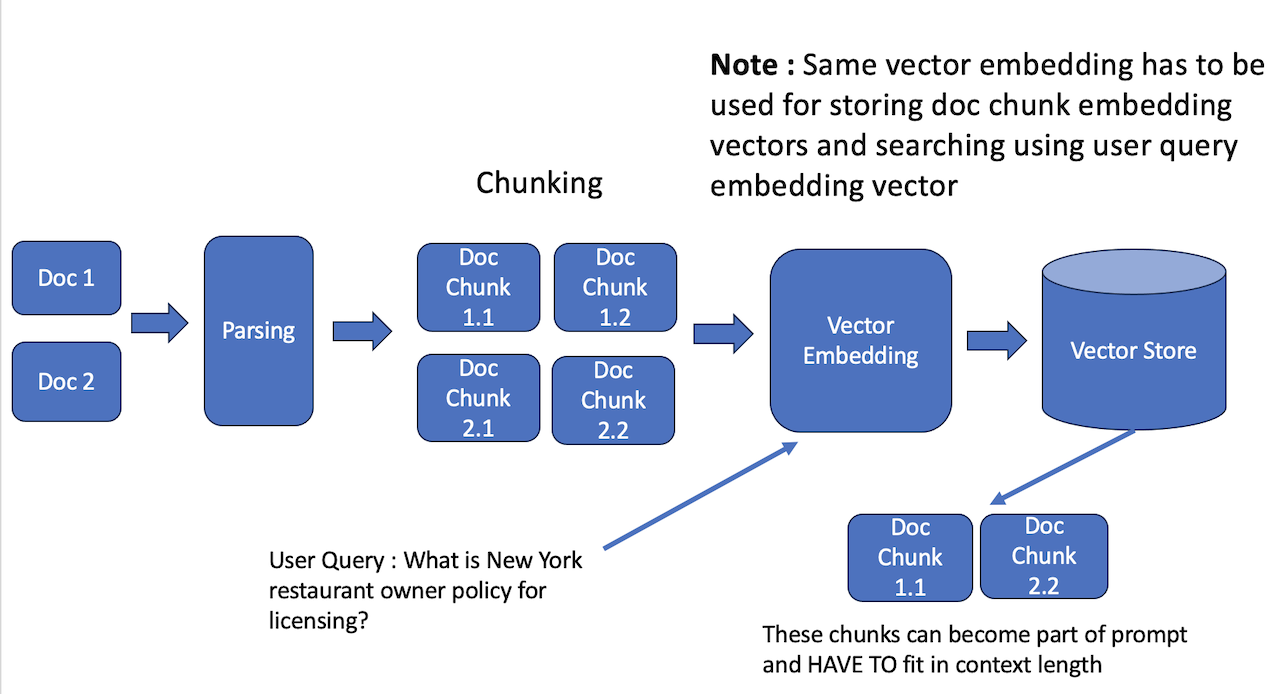
1. Advanced Parsing for Multi-Format Data Extraction
Enterprise knowledge bases often comprise a diverse array of document formats, including plaintext (.txt), markup (.md, .html), structured data (.csv, .xlsx), formatted reports (.pdf, .docx), and at times, even in the form of images. Robust parsing techniques must be employed to extract and normalize data across these formats to facilitate seamless retrieval.
For example, LLMs are used to do semantic parsing of documents to get information from images, too, if we want to make that information part of the search. Hybrid parsing approaches, combining rule-based extraction with AI-driven text structuring, can significantly enhance document accessibility.
2. Chunking for Contextual Granularity
Decomposing extensive textual corpora into semantically meaningful units enhances retrievability and contextual coherence. Various chunking methodologies include, details of which are out of the scope of this document and would be covered separately
- Fixed-length segmentation. Splitting text at predefined token thresholds (e.g., 300 tokens) to ensure uniform retrievability.
- Overlapping chunking. Maintaining a degree of content overlap to preserve contextual continuity between consecutive chunks.
- Hierarchical chunking. Structuring text into nested segments to facilitate multi-tiered retrieval granularity.
- Semantic clustering. Aggregating text based on lexical similarity and conceptual coherence rather than arbitrary token limits.
3. Vector Embeddings and High-Dimensional Search Optimization
LLMs can generate dense vector representations of textual data, enabling similarity-based retrieval through high-dimensional vector search methodologies. Key advantages include:
- Enhanced semantic matching of queries to relevant documents
- Context-aware ranking of search results through neural relevance scoring
- Adaptive personalization based on user-specific interaction histories
- Multi-modal retrieval, integrating textual and non-textual data sources
5. Re-Ranking Mechanisms for Precision Optimization
To ensure that retrieved results align with user intent, sophisticated re-ranking strategies must be employed. Effective re-ranking methodologies include:
- TF-IDF and BM25 scoring. Statistical weighting techniques to prioritize term relevance.
- Neural relevance models. Machine learning-based ranking mechanisms that adaptively optimize search output ordering.
- Hybrid retrieval architectures. Synergizing keyword indexing with vector-based retrieval for comprehensive ranking optimization.
6. Contextual Personalization via User Profiling
Incorporating user-specific attributes, such as role, location, and access level, refines search result accuracy. The system retrieves the most pertinent documents and ranks them based on user-specific attributes, ensuring relevance and compliance with access privileges. LLMs can tailor responses to the individual user’s contextual framework by leveraging dynamic user profiling, thereby enhancing search efficacy.
Toward a Hybrid Search Framework: The Convergence of LLMs and Traditional Retrieval Systems
To fully harness the capabilities of LLMs in search, a hybrid retrieval architecture that integrates semantic vector indexing with AI-driven ranking models is imperative. The following enhancements are key to refining this hybrid paradigm:
- Domain-specific fine-tuning. Custom LLM training on specialized corpora to improve domain-specific accuracy.
- Dynamic search filters. Context-aware filtering that adjusts retrieval constraints based on user intent and metadata parameters.
- Multi-modal integration. Extending search capabilities beyond text to encompass structured data, tabular content, and visual information.
- Prompt optimization strategies. Implementing caching, response routing, and query pre-processing to minimize generative latency and hallucination risks.
Other Patterns Used to Make the Semantic Search Better
The following advanced techniques should be integrated to enhance the retrieval phase in a RAG-based search system. By incorporating these strategies, RAG-based search systems enhance retrieval accuracy, contextual relevance, and response efficiency, making them more reliable for real-world applications.
Domain-Specific Embeddings
Generic embeddings may not capture the nuances of specialized fields such as medicine, law, or finance. By training embeddings on domain-specific corpora, we ensure that vector representations align more closely with relevant terminology, context, and semantics. This improves the accuracy of similarity-based retrieval, making search results more precise and contextually appropriate.
Advanced Parsing
Many enterprise knowledge bases contain diverse document formats, such as PDFs, spreadsheets, HTML pages, and scanned images. Extracting structured information from these formats requires AI-powered parsing techniques, including Optical Character Recognition (OCR) for scanned documents, rule-based extraction for tabular data, and NLP-based structuring for unstructured text. Proper parsing ensures that information remains accessible and searchable, regardless of format.
Dynamic Filters
Search precision can be significantly improved by applying dynamic filtering mechanisms based on metadata, user intent, and contextual constraints. For example, filters can be applied based on users' location, date ranges, document types, or access permissions, ensuring that the retrieved results are highly relevant and personalized. These filters refine search outputs and reduce noise in results.
Tabular Data and Image Processing
Traditional search systems struggle with non-textual data such as tables, charts, and images. Converting tabular data into structured embeddings allows retrieval models to recognize patterns and relationships within data points. Similarly, image-to-text models and multimodal embeddings enable search systems to process and retrieve relevant visual content, expanding search capabilities beyond traditional text-based methods.
Ranking and Re-Ranking
Once documents are retrieved, they must be ranked to prioritize the most relevant ones. Combining traditional ranking techniques like BM25 and TF-IDF with neural re-ranking models improves result ordering. Hybrid ranking strategies ensure that search results align with semantic intent, reducing reliance on keyword matching alone and increasing accuracy in complex search queries.
Prompt Caching and Routing
Repeatedly querying large language models for similar requests is inefficient. Prompt caching is a new technique in LLM frameworks that stores frequently used queries and responses, significantly reducing computation costs and latency. Additionally, prompt routing directs queries through the most appropriate retrieval pipeline, optimizing resource usage and improving response times. This ensures that users receive faster, more relevant results while maintaining efficiency.
Conclusion
While LLMs have introduced transformative advancements in search capabilities, they have not yet obviated the necessity for structured retrieval frameworks. The integration of semantic chunking, vector-based indexing, dynamic user profiling, and sophisticated ranking heuristics remains critical to enhancing search precision. Organizations seeking to leverage LLMs for enterprise search must adopt a multi-faceted approach that combines the generative strengths of AI with the deterministic rigor of traditional search methodologies.
Ultimately, the evolution of search will likely converge on a hybrid paradigm — one where LLMs augment rather than replace established retrieval techniques. Through ongoing refinement and strategic augmentation, LLMs can be effectively leveraged to create a more intuitive, context-aware, and accurate search experience, mitigating their inherent limitations and unlocking new frontiers in information retrieval.
Opinions expressed by DZone contributors are their own.
Comments