How to Read Graph Database Benchmarks (Part I)
This article introduces basic knowledge about graph databases, graph computing, and analytics to help readers interpret benchmark testing reports.
Join the DZone community and get the full member experience.
Join For FreeThe main goal of this article is to introduce basic knowledge about graph databases, graph computing, and analytics, help readers interpret benchmark testing reports, and validate if the results are correct and sensible.
Basic Knowledge
There are two main types of data operations in any graph database:
- Meta-data Operation: An operation against vertex, edge, or their attributes. There are mainly four types of meta operations, specifically CURD (Create, Update, Read or Delete).
- High-dimensional Data Operation: By saying “high-dimensional,” we are referring to high-dimensional data structures in the resulting datasets, for instance, a group of vertices or edges, a network of paths, a subgraph, or some mixed types of sophisticated results out of graph traversal — essentially, heterogeneous types of data can be mixed and assembled in one batch of result, therefore, making an examination of such result both exciting and perplexing.
High-dimensional data manipulation poses a key difference between graph databases and other types of DBMS; we’ll focus on examining this unique feature of graph DB across the entire article.
Three main types of high-dimensional data operations are frequently encountered in most benchmark testing reports:
- K-Hop: K-hop query against a certain vertex will yield all vertices that are exactly K-hop away from the source vertex in terms of shortest-path length. K-hop queries have many variations, such as filtering by a certain edge direction, vertex, or edge attribute. A special kind of K-hop query runs against all vertices of the entire graph; it is also considered a graph algorithm.
- Path: Path queries have many variations; shortest-path queries are most used, with template-based path queries, circle-finding path queries, automatic-networking queries, auto-spread queries, etc.
- Graph Algorithm: Graph algorithms essentially are the combination of meta-data, K-hop, and path queries. There are rudimentary algorithms like degrees, but there are highly sophisticated algorithms like Louvain, and there are extremely complex, in terms of computational complexity, algorithms such as Betweenness-Centrality or full-graph K-hop, mainly when K is much larger than one.
Most benchmark reports are reluctant to disclose how high-dimensional data operations are implemented, and this vagueness has created lots of trouble for readers to understand graph technology better. We now clarify; there are ONLY three types of implementations in terms of how to graph data is traversed:
- BFS (Breadth First Search): Shortest Path, K-hop queries are typically implemented using the BFS method. It’s worth clarifying that you may use DFS to implement, say, shortest path finding. Still, in most real-world applications, particularly with large volumes of data, BFS is guaranteed to be more efficient and logically more straightforward than DFS.
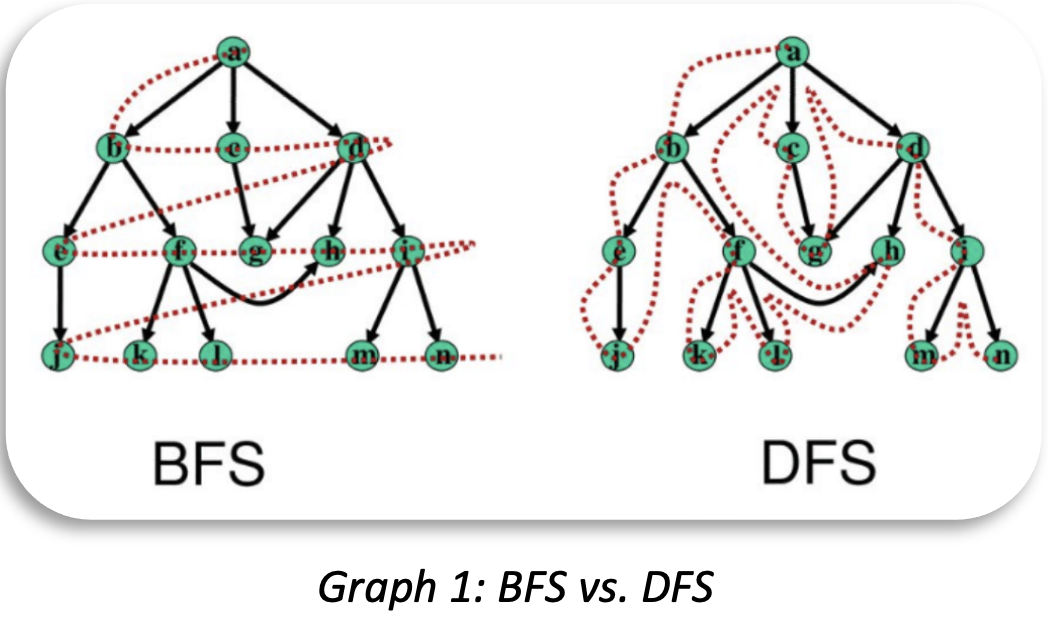
- DFS (Depth First Search): Queries like circle finding, auto-networking, template-based path queries, and random walks desire to be implemented using the DFS method. If you find it hard to understand the difference between BFS and DFS, refer to the below diagram and a college textbook on Graph Theory.
- Combination of Both (BFS + DFS): There are scenarios where both BFS and DFS are applied, such as template-based K-hop queries, customized graph algorithms, etc.
Graph one illustrates the traversal difference between BFS and DFS. In short, under BFS mode, if qualified first-hop neighbors are not all visited first, the access to any second-hop neighbor will not start, and traversal will continue until all data(neighbors) are seen hop after hop. Based on such a description, it’s not hard to tell that if a certain K-hop or shortest-path query only returns a pre-defined limited number of neighbors or paths (say, 1 or 10), it’s guaranteed that the query implementation is wrong! Because you do NOT know the total number of qualified neighbors or paths beforehand.
Typical Benchmark Datasets
There are three types of datasets for graph system benchmarking:
- Social or Road Network Dataset: Typical social network datasets like Twitter-2010 and Amazon0601 have been commonly used for graph database benchmarking. There are also road network or web-topology-based datasets used in academic benchmarks such as UC Berkeley’s GAP.
- Synthetic Dataset: HPC (High-Performance Computing) organization Graph-500 has published some synthetic datasets for graph system benchmarks. International standard organization LDBC (Linked Data Benchmark Council) also uses data-generating tools to create synthetic social-network datasets for benchmarking purposes.
- Financial Dataset: The latest addition to the family of graph benchmark datasets is a financial dataset; most are found in private and business-oriented setups because the data are often based on real transactions. There are several public datasets, such as Alimama’s e-commerce dataset and LDBC’s FB (FinBench) dataset, which is being drafted and to be released toward the end of 2022 (to replace the LDBC’s SNB dataset, which does NOT reflect real-world financial business challenges in terms of data topology and complexity).
As graph databases and computing technologies and products continue to evolve, it’s not hard to see that more graph datasets will emerge and better reflect real-world scenarios and business challenges.
Twitter-2010 (42 Million vertices, 1.47 Billion edges, sized at 25GB, downloadable) is commonly used in benchmarking; we’ll use it as a level playing field to explain how to interpret a benchmark report and how to validate results in the report.
Before we start, let’s get ourselves familiar with a few concepts in graph data modeling by using the Twitter dataset as an example:
- Directed Graph: Every edge has a unique direction; in Twitter, an advantage is composed of a starting vertex and an ending vertex, which map to the two IDs separated by TAB on each line of the data file, and the significance of the edge is that it indicates the starting vertex (person) follows the ending vertex (person). When modeling the edge in a graph database, the edge will be constructed twice, the first time as StartingVertex --> EndingVertex, and the second time as EndingVertex <--
- StartinVertex (a.k.a, the inverted edge), this is to allow traversing the edge from either direction. If the inverted edge is not constructed, queries’ results will inevitably be wrong (We’ll show you how later).
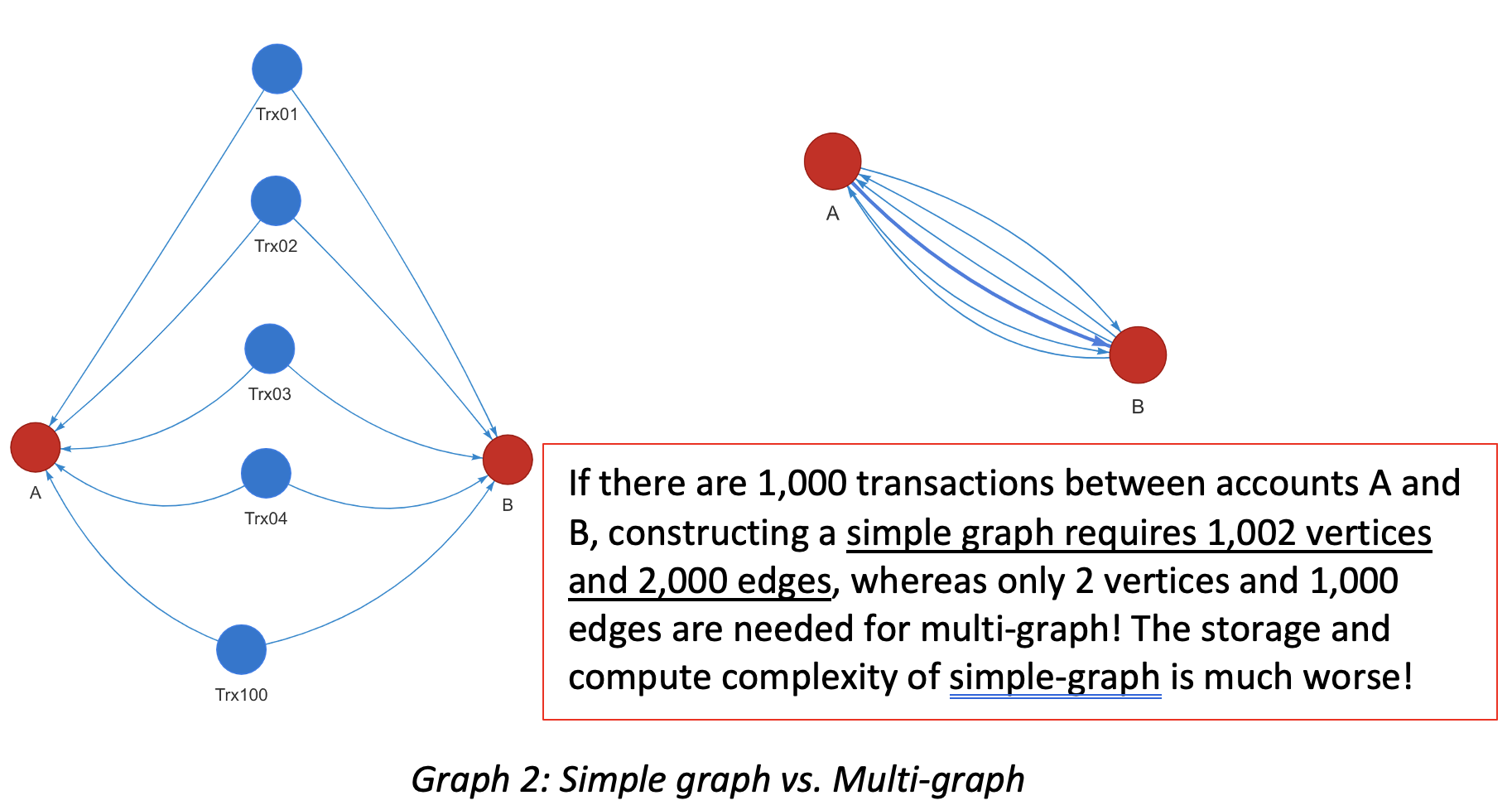
- Simple-graph vs. Multi-graph: If there are more than two edges of the same kind between a pair of vertices in either direction, it’s a multi-graph. Otherwise, it’s a simple graph. Twitter and all social network datasets are considered simple graphs because it models a following simple relationship between the users. In financial scenarios, assuming user accounts are vertices and transactions are edges, there could be many transactions between two accounts and many edges. Some graph databases are designed to be simple-graph instead of multi-graph; this will create lots of problems in terms of data modeling efficiency and query results correctness.
- Node-Edge Attributes: Twitter data does NOT carry any node or edge attribute other than the designated direction of the edge. This differs from the transactional graph in financial scenarios, where both node and edge may have many attributes, so filtering, sorting, aggregation, and attribution analysis can be done with the help of these attributes. There are so-called graph database systems that do NOT support filtering by node or edge attributes, which are considered impractical and lack commercial values.
Report Interpretation
Generally speaking, there are at least five parts of a graph database benchmark report:
- Testing Bed/Environment: Software and hardware environment, testing datasets, etc.
- Data Ingestion: Volume data loading, database startup time, etc.
- Query Performance: Queries against meta-data, K-hop, shortest path, algorithm, etc.
- Real-time Update: Modification to graph data’s topology (meta-data), then query against the updated data to validate results.
- Feature Completeness and Usability: Support API/SDK for secondary development, GQL, management and monitoring, system maintenance toolkits and disaster recovery, etc.
Most benchmark reports would cover the first three parts but not the fourth or fifth parts — the fourth part reflects if the subject database is more of the OLTP/HTAP type or OLAP focused, with the main difference lying in the capability to process dynamically changing datasets. If a graph system claims to be capable of OLTP/HTAP, it must allow data to be updated and queried all the time instead of functioning as a static data warehouse like Apache Spark, or data projections must be finished first before queries can be run against the just-finished static projection as Neo4j does.
Testing Bed
Almost all graph database products are built on X86 architecture as X86–64 CPU-powered servers dominate the server marketplace. The situation has recently changed given the rise of ARM due to its simplistic RISC (instead of X86’s CISC), therefore, greener design. There is a growing number of commodity PC servers based on ARM CPUs nowadays. However, only two graph database vendors are known to natively support ARM-64 CPU architecture; they are Ultipa and ArangoDB, while other vendors tend to use virtualization or emulation methods which tend to be dramatically slower than the native method.
The core hardware configurations are CPU, DRAM, external storage, and network bandwidth. The number of CPU cores is most critical, as more cores mean potentially higher parallelism and better system throughput. Most testing beds settle on 16-core and 256GB configuration; however, not all graph systems can leverage multiple cores for accelerated data processing; for instance, even enterprise edition Neo4j leverages up to 4-vCPU in terms of parallelization. If another system can leverage 16-vCPU, the performance gain would be at least 400%.
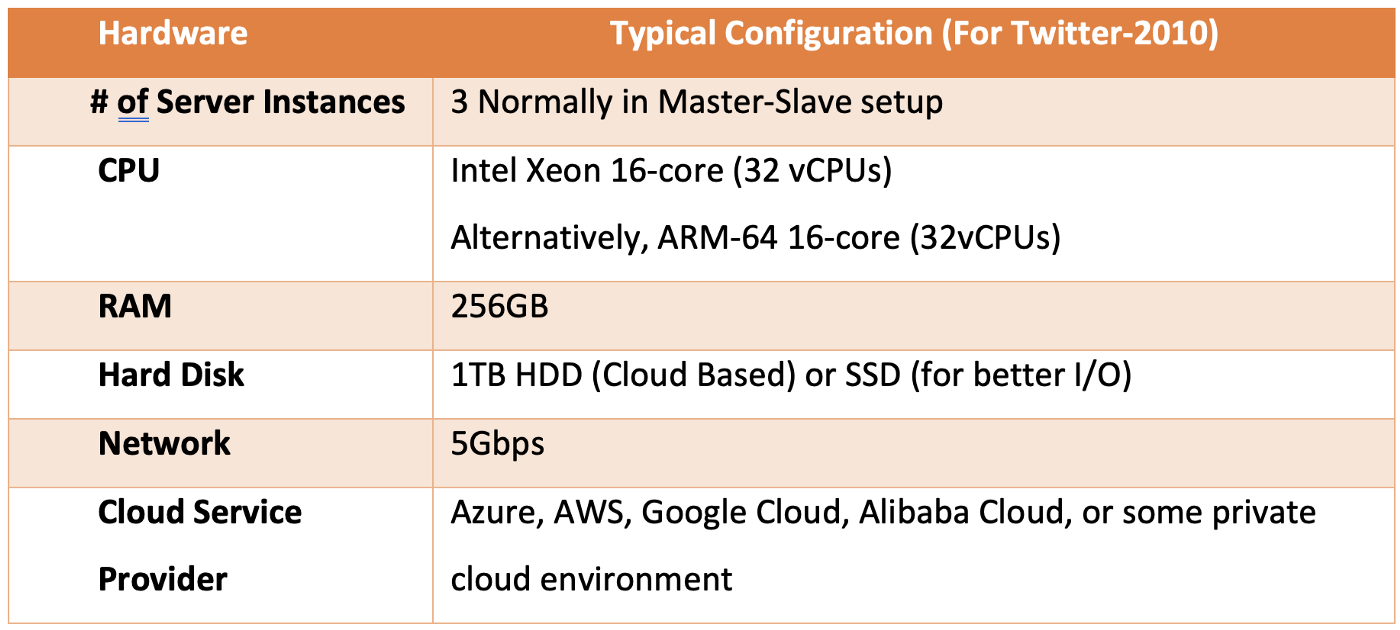
The table above illustrates typical hardware configurations for graph system benchmarking. It’s worthwhile pointing out that graph database is computing first, unlike RDBMS, Data Warehouse, or Data Lake systems which are storage first, and compute is the second class citizen attached to the storage engine. In another word, traditional DBMS addresses I/O-intensive challenges first, while graph system solves computing-intensive challenges first. While both challenges may intersect, a performance-oriented graph database should set both computing and storage as its first-class citizens.
The software environment is trivial as all known graph systems settle on Linux OS and leverage container and virtualization technologies for encapsulation and isolation.
Data Ingestion
Data ingestion has a few indicators to watch out for:
- Dataset volume, topological complexity (or density)
- Ingestion time
- Storage space
Data volume concerns the total number of vertices and edges, plus complexity (or density), which is normally calculated using the following formula (for directed simple graph):
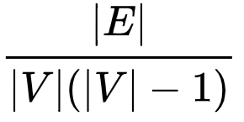
Where |V| annotates the total number of vertices, and |E| for the total number of edges. Per this formula, the highest possible density of a simple graph is one. However, as we pointed out earlier, most real-world graphs are NOT simple-graph, but multi-graphs, meaning multiple edges may exist between any two vertices. Therefore it makes more sense to use the vertex-to-edge ratio (|E|/|V|) as a “density” indicator. Taking Twitter-2010 as an example, its ratio is 35.25 (while density is 0.000000846). For any graph dataset with a ratio higher than 10, deep traversal against the dataset poses as great challenge due to exponentially growing complexity, for instance, 1-hop = 10 neighboring vertices, 2-hop = 100 vertices, 3-hop = 1,000 vertices, and 10-hop = 10,000,000,000.
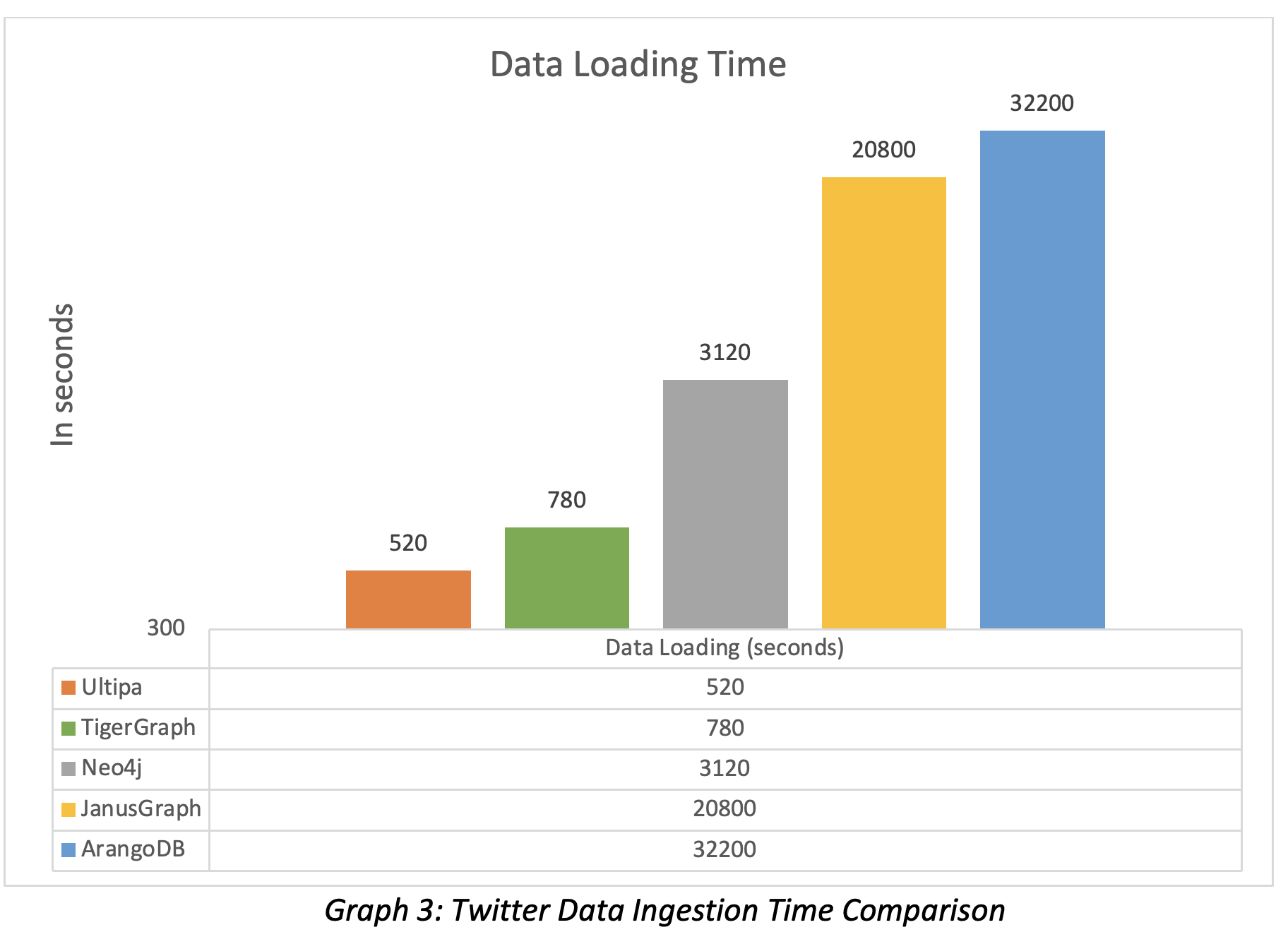
Ingestion time and storage usage show how soon can a graph database load the entire dataset and how much storage space it uses on the filesystem. Clearly, for loading time, the shorter, the better. Storage space is less of a concern nowadays as storage is super cheap; different database systems may have quite different storage mechanisms in terms of replication, sharding, partitioning, normalization, and other techniques that may affect computing efficiency and high availability. The table below shows the data ingestion performance of different graph DBMS.

Note that Tigergraph stores each edge unidirectionally instead of bidirectionally; this alone saves 50% storage space, but it’s incorrect. If Tigergraph were to store properly, it would occupy at least 24GB. If a system only stores an edge unidirectionally, it would generate incorrect results for queries like K-hop, Path, or algorithm, and we’ll get to that later.
Query Performance
There are mainly three types of graph queries:
- Query for Neighbors: also known as K-hop.
- Path: Shortest path queries are commonly used for simplicity (ease of comparison).
- Algorithm: Commonly benchmarked algorithms include PageRank, Connected Component, LPA, and Similarity. Some performance-oriented graph databases also benchmark the Louvain community detection algorithm, which is considered more complex and challenging.
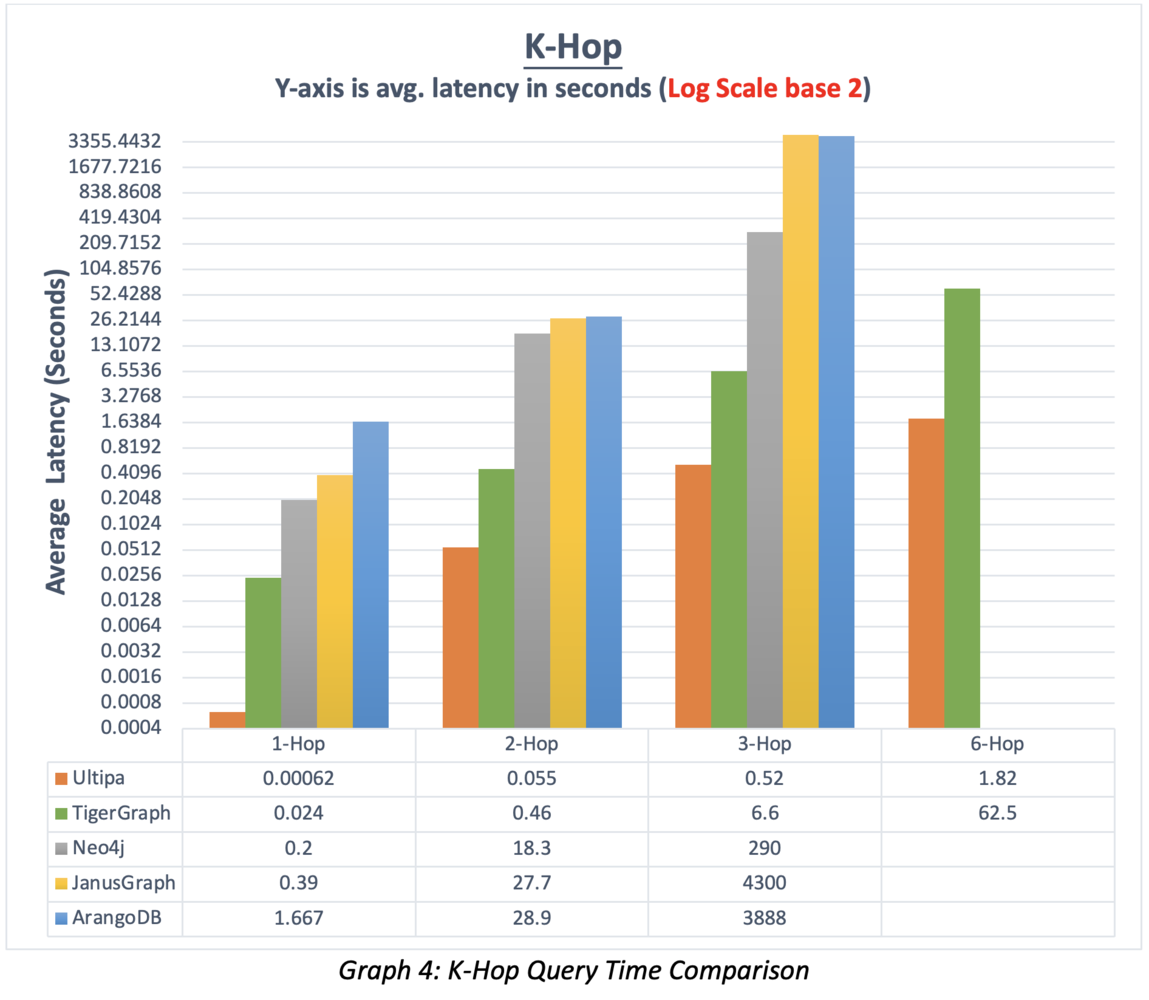
K-Hop measures query latency at different depths. Taking Twitter-2010 as an example, it makes sense to measure the performance of 1-Hop and 6-Hop. Most databases can handle 1-hop without problem, but 2-hop and beyond are much more challenging; very few systems can return beyond 3-hop. If a system can finish 6-hop (considered deep traversal) within 10 seconds, it’s considered a real-time graph database because 6-hop traversal of most vertices of the Twitter dataset would basically touch base with 95% of all 1.5 billion edges and vertices, which translates to the computing power of traversing over 150 million nodes and edges every second.
For any given dataset and any designated starting vertex, the K-hop query result is deterministic. Therefore, all benchmarking systems should return the exact result. Common mistakes with K-hop are:
- DFS instead of DFS for traversal (wrongful implementation).
- No deduplication (redundant and incorrect results).
- Partial traversal (violation of the definition of K-hop).
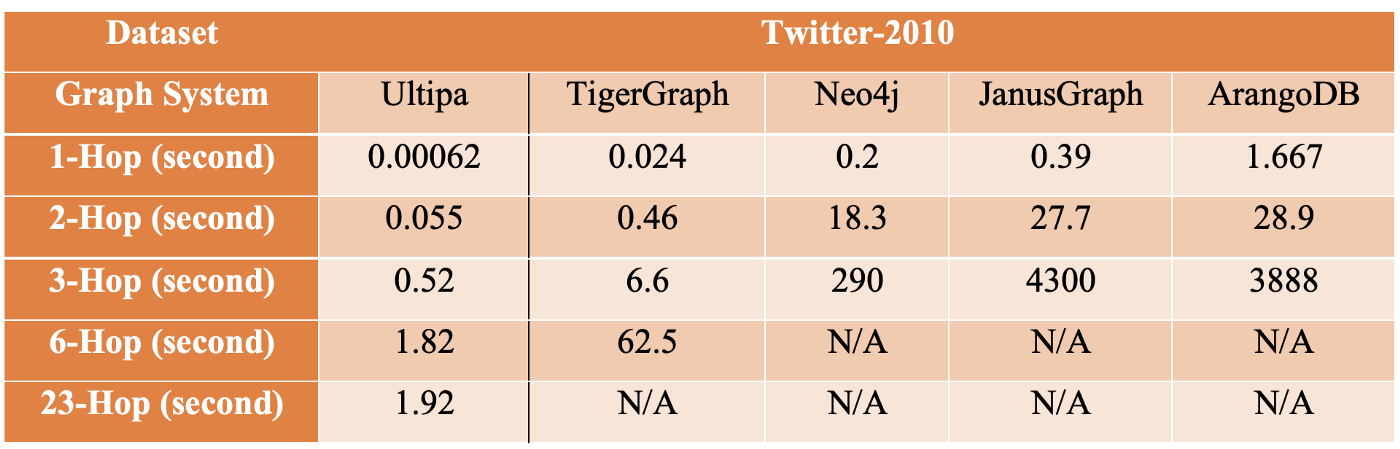
Note, Ultipa Graph is the only system that has published its ultra-deep traversal results, vertices having neighbors that are 23-hop away, which reflects the system’s capability to deeply penetrate data in real-time while other systems may take hours or even days to complete, or never finish.
Shortest-Path query is considered a special form of K-hop query; the difference lies in fixing both the starting vertex and ending vertex and finding all possible paths in between. Note that in a dense dataset like Twitter-2010, there are possibly millions of shortest paths between a pair of vertices. Only three graph database vendors have published their benchmark results against Twitter, but Ultipa is the only vendor that has published the exact number of paths, as shown in the below table. Some vendors return with only one shortest path, which is both ridiculously wrong and problematic. In many real-world scenarios, such as anti-money laundering paths, and transactional networks, it’s imperative to locate all shortest paths between two parties as soon as possible.

Graph Algorithm reflects a graph DMBS’ computing power in terms of mass data processing. The number of supported graph algorithms and running speed directly tell a system’s capability and feature completeness. Many graph DBMSes are based on some graph computing engine or framework, which can only handle static datasets; once the dataset is modified, a new projection (loading data into DRAM, comparable to ETL) has to be constructed before the graph algorithms can be relaunched. This is the case for Apache Spark GraphX and Neo4j GDS; the ETL process may take a rather long time, which should be included in the algorithm running time.
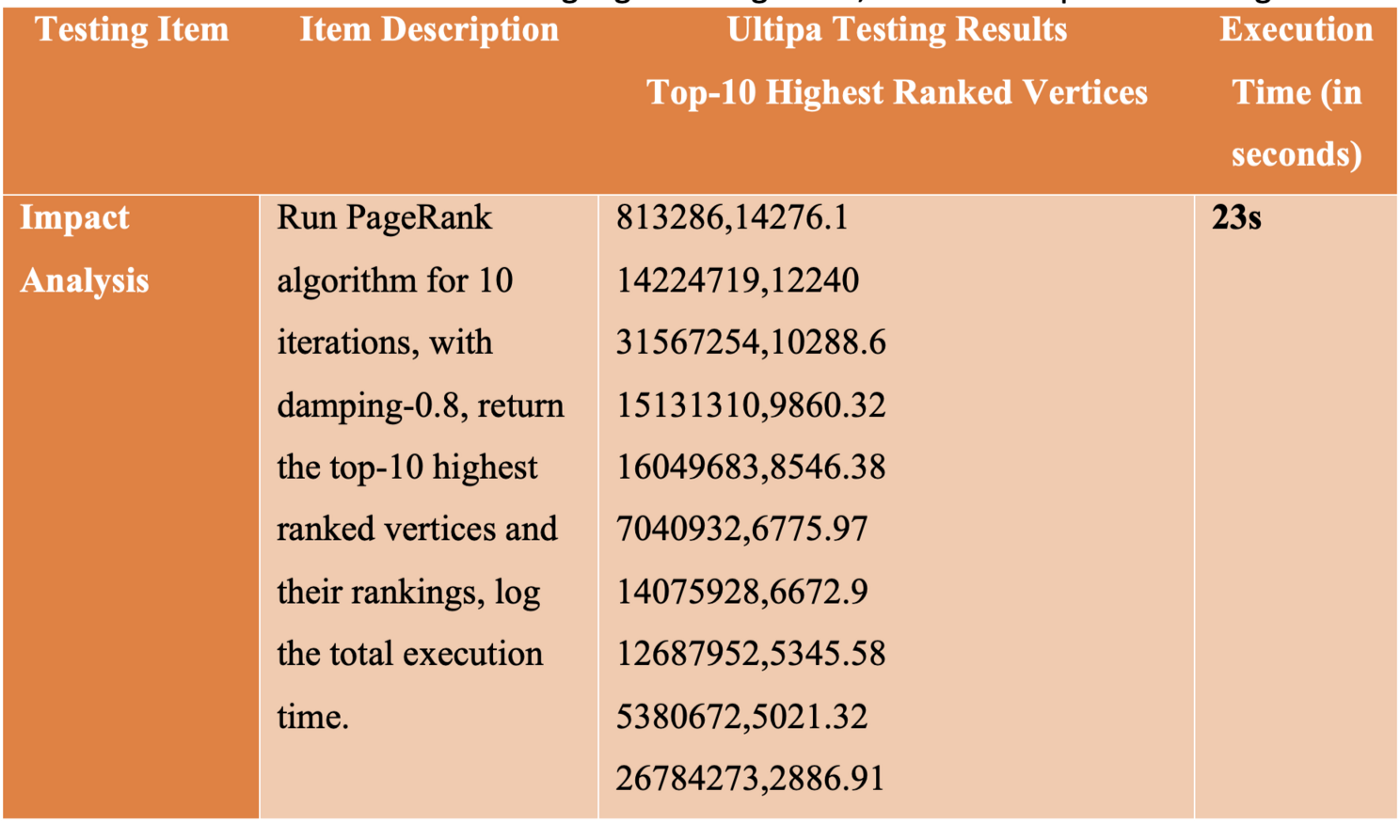
PageRank is the most famous graph algorithm, taking its name from Google co-founder Larry Page. It’s the web search engine’s core ranking algorithm and one of the 1st algorithms that have been crafted to run parallelly on large-scale distributed systems due to its simple iteration logic and BSP-friendly design. The algorithm running results conveniently tell the ranking (importance) of each vertex (entity) compared with the rest of the dataset. For commercial-grade implementation, there are also features like database write-back, filesystem write-back, streaming write-back, results in ranking, etc.
The two essential features of PageRank to watch out for:
- PageRank must run against the entire dataset, not partially.
- Results should be fully ranked and return Top-N as needed.
We noticed that some graph DBMS only calculates against a partial dataset; this is a direct violation of the definition of PageRank, which is to iterate through the entire dataset. Neo4j GDS is a typical example that allows the algorithm to run against, say, 1,000 vertices if the input parameter provided has a limit of 1,000. Taking Twitter-2010 as an example, the result would be 100% wrong because running against 1,000 vertices is only 0.000025% of the entire dataset. On the other hand, if the results are not ranked, it’s up to the business layer (application layer) to do the ranking, which clearly isn’t acceptable. Most graph DBMS benchmarking results do not touch base on these issues.
The table below lists the benchmarking logics of PageRank and a list of top-10 returning vertices:
LPA (Label Propagation Algorithm) is a classic community-detection algorithm; it propagates predefined labels across all vertices iteratively until a stable state is achieved. Compared to PageRank, LPA is computationally more complex and returns a total number of communities per vertex-label aggregation. There are also various write-back options to look at when invoking LPA.
Louvain community detection algorithm is computationally more complex than LPA and iterates through all vertices repeatedly to calculate the maximum modularity of the entire dataset. Very few graph DBMS vendors prefer to benchmark Louvain on a dataset larger than 100 million nodes and edges. The original Louvain algorithm was implemented using C++, yet in a sequential fashion, on a typical billion-scale dataset, it would require 2.5 hours to finish; if this is to be done in Python, it will last at least a few hundred hours (weeks). Ultipa is the only vendor that has published Louvain’s benchmark results on a dataset sized over one billion.


Real-Time Updates
There are two types of update operations in graph DBMS:
- Meta-data oriented (TP): The operation only affects meta-data like vertex, edge, or attribute field(s). From a traditional DBMS perspective, this is a typical TP operation (ACID). In graph DBMS, this also means the topology of the graph changes, such as inserting or deleting a node, an edge, or changing an attribute that may affect query results.
- TP+AP operation: This refers to combo operations, where first a meta-data operation is conducted then an AP type of query is launched. This is common with many real-time BI or decision-making-related scenarios, such as online fraud detection, where a new transaction or loan application shows up, and a series of graph-based network and behavior analyses follow the suite.
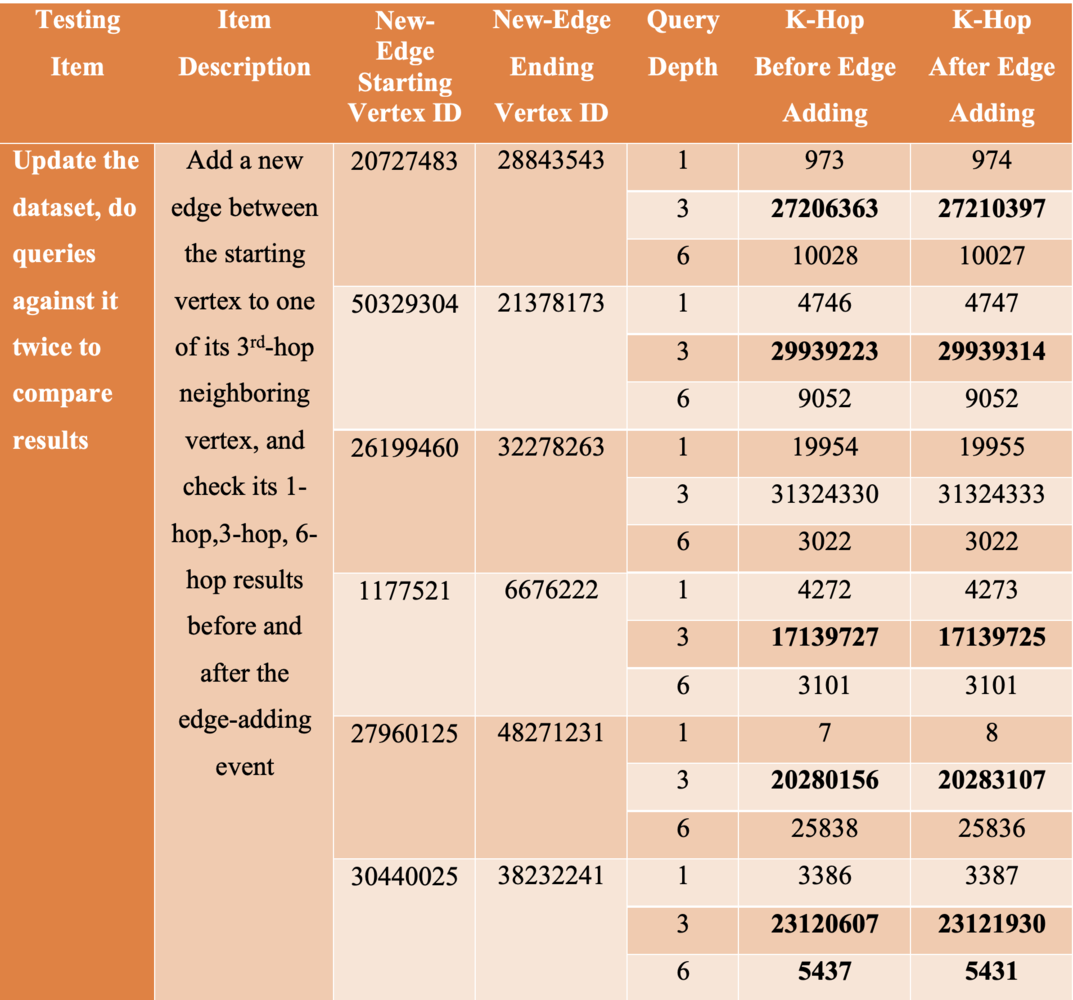
It is not uncommon that some graph systems use caching mechanisms to pre-calculate and store-aside results, which do NOT change accordingly after the data contents are changed. To validate if a graph database system can update data contents and allow for accurate data querying in real-time, we create a new edge connecting the provided starting vertex with one of its third-hop neighboring vertexes and compare the 1-to-3-to-6 Hop results before and after the edge is inserted.
The table below shows how the K-hop results change before and after the edge-insertion event. If a system does NOT have the capacity to handle dynamically changing graph data, the K-hop results will stay put (and wrong).
In the second part of this article, we’ll introduce a mechanism to validate the benchmark results; remember that graph DBMS is white-box and explainable AI; we’ll show you how everything can be explained in a white-box fashion in the second part. Stay tuned.
Published at DZone with permission of Ricky Sun. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments