Backpressure in Distributed Systems
Learn more about backpressure, a technique in distributed systems to prevent overload and cascading failures by controlling the flow of requests.
Join the DZone community and get the full member experience.
Join For FreeAn unchecked flood will sweep away even the strongest dam.
– Ancient Proverb
The quote above suggests that even the most robust and well-engineered dams cannot withstand the destructive forces of an unchecked and uncontrolled flood. Similarly, in the context of a distributed system, an unchecked caller can often overwhelm the entire system and cause cascading failures. In a previous article, I wrote about how a retry storm has the potential to take down an entire service if proper guardrails are not in place. Here, I'm exploring when a service should consider applying backpressure to its callers, how it can be applied, and what callers can do to deal with it.
Backpressure
As the name itself suggests, backpressure is a mechanism in distributed systems that refers to the ability of a system to throttle the rate at which data is consumed or produced to prevent overloading itself or its downstream components. A system applying backpressure on its caller is not always explicit, like in the form of throttling or load shedding, but sometimes also implicit, like slowing down its own system by adding latency to requests served without being explicit about it. Both implicit and explicit backpressure intend to slow down the caller, either when the caller is not behaving well or the service itself is unhealthy and needs time to recover.
Need for Backpressure
Let's take an example to illustrate when a system would need to apply backpressure. In this example, we're building a control plane service with three main components: a frontend where customer requests are received, an internal queue where customer requests are buffered, and a consumer app that reads messages from the queue and writes to a database for persistence.
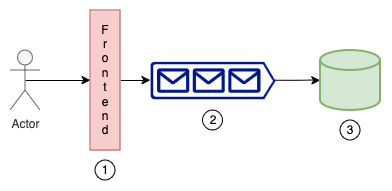
Figure 1: A sample control plane
Producer-Consumer Mismatch
Consider a scenario where actors/customers are hitting the front end at such a high rate that either the internal queue is full or the worker writing to the database is busy, leading to a full queue. In that case, requests can't be enqueued, so instead of dropping customer requests, it's better to inform the customers upfront. This mismatch can happen for various reasons, like a burst in incoming traffic or a slight glitch in the system where the consumer was down for some time but now has to work extra to drain the backlog accumulated during its downtime.
Resource Constraints and Cascading Failures
Imagine a scenario where your queue is approaching 100% of its capacity, but it's normally at 50%. To match this increase in the incoming rate, you scale up your consumer app and start writing to the database at a higher rate. However, the database can't handle this increase (e.g., due to limits on writes/sec) and breaks down. This breakdown will take down the whole system with it and increase the Mean Time To Recover (MTTR). Applying backpressure at appropriate places becomes critical in such scenarios.
Missed SLAs
Consider a scenario where data written to the database is processed every 5 minutes, which another application listens to keep itself up-to-date. Now, if the system is unable to meet that SLA for whatever reason, like the queue being 90% full and potentially taking up to 10 minutes to clear all messages, it's better to resort to backpressure techniques. You could inform customers that you're going to miss the SLA and ask them to try again later or apply backpressure by dropping non-urgent requests from the queue to meet the SLA for critical events/requests.
Backpressure Challenges
Based on what's described above, it seems like we should always apply backpressure, and there shouldn't be any debate about it. As true as it sounds, the main challenge is not around if we should apply backpressure but mostly around how to identify the right points to apply backpressure and the mechanisms to apply it that cater to specific service/business needs.
Backpressure forces a trade-off between throughput and stability, made more complex by the challenge of load prediction.
Identifying the Backpressure Points
Find Bottlenecks/Weak Links
Every system has bottlenecks. Some can withstand and protect themselves, and some can't. Think of a system where a large data plane fleet (thousands of hosts) depends on a small control plane fleet (fewer than 5 hosts) to receive configs persisted in the database, as highlighted in the diagram above. The big fleet can easily overwhelm the small fleet. In this case, to protect itself, the small fleet should have mechanisms to apply backpressure on the caller. Another common weak link in architecture is centralized components that make decisions about the whole system, like anti-entropy scanners. If they fail, the system can never reach a stable state and can bring down the entire service.
Use System Dynamics: Monitors/Metrics
Another common way to find backpressure points for your system is to have appropriate monitors/metrics in place. Continuously monitor the system's behavior, including queue depths, CPU/memory utilization, and network throughput. Use this real-time data to identify emerging bottlenecks and adjust the backpressure points accordingly. Creating an aggregate view through metrics or observers like performance canaries across different system components is another way to know that your system is under stress and should assert backpressure on its users/callers. These performance canaries can be isolated for different aspects of the system to find the choke points. Also, having a real-time dashboard on internal resource usage is another great way to use system dynamics to find the points of interest and be more proactive.
Boundaries: The Principle of Least Astonishment
The most obvious things to customers are the service surface areas with which they interact. These are typically APIs that customers use to get their requests served. This is also the place where customers will be least surprised in case of backpressure, as it clearly highlights that the system is under stress. It can be in the form of throttling or load shedding. The same principle can be applied within the service itself across different subcomponents and interfaces through which they interact with each other. These surfaces are the best places to exert backpressure. This can help minimize confusion and make the system's behavior more predictable.
How to Apply Backpressure in Distributed Systems
In the last section, we talked about how to find the right points of interest to assert backpressure. Once we know those points, here are some ways we can assert this backpressure in practice:
Build Explicit Flow Control
The idea is to make the queue size visible to your callers and let them control the call rate based on that. By knowing the queue size (or any resource that is a bottleneck), they can increase or decrease the call rate to avoid overwhelming the system. This kind of technique is particularly helpful where multiple internal components work together and behave well as much as they can without impacting each other. The equation below can be used anytime to calculate the caller rate. Note: The actual call rate will depend on various other factors, but the equation below should give a good idea.
CallRate_new = CallRate_normal * (1 - (Q_currentSize / Q_maxSize))
Invert Responsibilities
In some systems, it's possible to change the order where callers don't explicitly send requests to the service but let the service request work itself when it's ready to serve. This kind of technique gives the receiving service full control over how much it can do and can dynamically change the request size based on its latest state. You can employ a token bucket strategy where the receiving service fills the token, and that tells the caller when and how much they can send to the server. Here is a sample algorithm the caller can use:
# Service requests work if it has capacity
if Tokens_available > 0:
Work_request_size = min (Tokens_available, Work_request_size _max) # Request work, up to a maximum limit
send_request_to_caller(Work_request_size) # Caller sends work if it has enough tokens
if Tokens_available >= Work_request_size:
send_work_to_service(Work_request_size)
Tokens_available = Tokens_available – Work_request_size
# Tokens are replenished at a certain rate
Tokens_available = min (Tokens_available + Token_Refresh_Rate, Token_Bucket_size)Proactive Adjustments
Sometimes, you know in advance that your system is going to get overwhelmed soon, and you take proactive measures like asking the caller to slow down the call volume and slowly increase it. Think of a scenario where your downstream was down and rejected all your requests. During that period, you queued up all the work and are now ready to drain it to meet your SLA. When you drain it faster than the normal rate, you risk taking down the downstream services. To address this, you proactively limit the caller limits or engage the caller to reduce its call volume and slowly open the floodgates.
Throttling
Restrict the number of requests a service can serve and discard requests beyond that. Throttling can be applied at the service level or the API level. This throttling is a direct indicator of backpressure for the caller to slow down the call volume. You can take this further and do priority throttling or fairness throttling to ensure that the least impact is seen by the customers.
Load Shedding
Throttling points to discarding requests when you breach some predefined limits. Customer requests can still be discarded if the service faces stress and decides to proactively drop requests it has already promised to serve. This kind of action is typically the last resort for services to protect themselves and let the caller know about it.
Conclusion
Backpressure is a critical challenge in distributed systems that can significantly impact performance and stability. Understanding the causes and effects of backpressure, along with effective management techniques, is crucial for building robust and high-performance distributed systems. When implemented correctly, backpressure can enhance a system's stability, reliability, and scalability, leading to an improved user experience. However, if mishandled, it can erode customer trust and even contribute to system instability. Proactively addressing backpressure through careful system design and monitoring is key to maintaining system health. While implementing backpressure may involve trade-offs, such as potentially impacting throughput, the benefits in terms of overall system resilience and user satisfaction are substantial.
Opinions expressed by DZone contributors are their own.
Comments