High-Load Systems: Overcoming Challenges in Social Network Development
Explore how to master high-load systems with custom solutions, caching, scalable architecture, and continuous optimization to handle millions of users.
Join the DZone community and get the full member experience.
Join For FreeHello, my name is Alexander Kolobov. I worked as a team lead at VK, one of the biggest social networks, where I led teams of up to 10 members, including SEO specialists, analysts, and product manager. As a developer, I designed, developed, and maintained various features for the desktop and mobile web versions of a social network across backend, frontend, and mobile application APIs. My experience includes:
- Redesigning the social network interface for multiple user sections
- Completely rewriting network widgets for external sites
- Maintaining privacy settings for closed profiles and the content archiving function
- Overhauling the backend and frontend of the mail notification system, handling millions of emails daily
- Creating a system for conducting NPS/CSI surveys that covered the two largest Russian social networks
In this article, I am going to talk about high-load systems and the challenges they bring. I want to touch upon the following aspects:
- What is high-load?
- High-load challenges and requirements
- Technologies vs challenges
We’ll briefly discuss how to define if a system is high-load or not, and then we’ll talk about how high loads change system requirements. Based on my experience, I’ll highlight what approaches and technologies can help overcome high-load challenges.
What Is High-Load?
Let’s begin with the definition. What systems can we call high-load? A system is considered “high-load” if it meets several criteria:
- High request volume: Handles millions of requests daily
- Large user base: Supports millions of concurrent users
- Extensive data management: Manages terabytes or even petabytes of data
- Performance and scalability: Maintains responsiveness under increasing loads
- Complex operations: Performs resource-intensive calculations or data processing
- High reliability: Requires 99.9% or higher uptime
- Geographical distribution: Serves users across multiple locations with low latency
- Concurrent processing: Handles numerous concurrent operations
- Load balancing: Distributes traffic efficiently to avoid bottlenecks
High-Load or Not?
Basically, we can already call a system high-load if it meets these benchmarks:
- Resource utilization: >50%
- Availability: >99.99%
- Latency: 300ms
- RPS (Requests Per Second): >10K
One more thing I want to mention is that if I were to give a one-sentence definition of what a high-load system is, I would say: it is when usual methods for processing requests, storing data, and managing infrastructure are no longer enough, and there is a need to create custom solutions.
VK Social Network: A High-Load Example
Let’s take a look at VK social network loads. Here is what the system had to process already a couple of years ago:
- 100 million monthly active users (MAU)
- 100 million posts and content creations per day
- 9 billion post views per day
- 20,000 servers
These numbers result in the following performance metrics:
- Resource utilization: >60%
- Availability: >99.94%
- Latency: 120ms
- RPS: 3M
So we can definitely call VK loads high.
High-Load Challenges
Let’s take a step further and look at the difficulties the management of such systems entails. The main challenges are:
- Performance: Maintaining fast response times and processing under high load conditions
- Data management: Storing, retrieving, and processing large volumes of data effectively
- Scalability: Providing that scalability is possible at any stage
- Reliability: Ensuring the system remains operational and available despite high traffic and potential failures
- Fault tolerance: Building systems that can recover from failures and continue to operate smoothly
External Solutions Risks
Apart from the challenges, high-load systems bring certain risks, and that is why we have to question some of the traditional tools. The main issues with external solutions are:
- They are designed for broad application, not highly specialized tasks.
- They may have vulnerabilities that are difficult to address quickly.
- They can fail under high loads.
- They offer limited control.
- They may have scalability limitations.
The main issue with external solutions is that they are not highly specialized; instead, they are designed for broad market applicability. And it often comes at the expense of performance. There is also an issue with security: on the one hand, external solutions are usually well-tested due to their large user base, but on the other hand, fixing identified issues quickly and precisely is challenging. Updating to a fixed version might lead to compatibility problems.
External solutions also require ongoing tweaking and fixing, which is very difficult (unless you are a committer of that solution). And finally, they may not scale effectively.
High-Load Structure Requirements
Naturally, with growing loads, reliability, data management, and scaling requirements are increasing:
- Downtime is unacceptable: In the past, downtime for maintenance was acceptable; users had lower expectations and fewer alternatives. Today, with the vast availability of online services and the high competition among them, even short periods of downtime can lead to significant user dissatisfaction and negatively affect Net Promoter Score.
- Zero data loss ensured by cloud services: Users previously kept backups, but now cloud services must ensure zero data loss.
- Linear scaling: While systems were once planned in advance, there’s now a need for them to scale linearly at any moment due to possible explosive audience growth.
- Ease of maintenance: In a competitive environment, it’s essential to launch features quickly and frequently.
According to the "five nines" standard (99.999% uptime), which is often referenced in the tech industry, only about 5 minutes of downtime per year are considered acceptable.
Technologies vs Challenges
Further on, we’ll discuss some possible ways how to overcome these challenges and meet the high-load requirements. Let’s look at how VK's social network grew and gradually transformed its architecture and adopted or created technologies that suited the scale and new requirements.
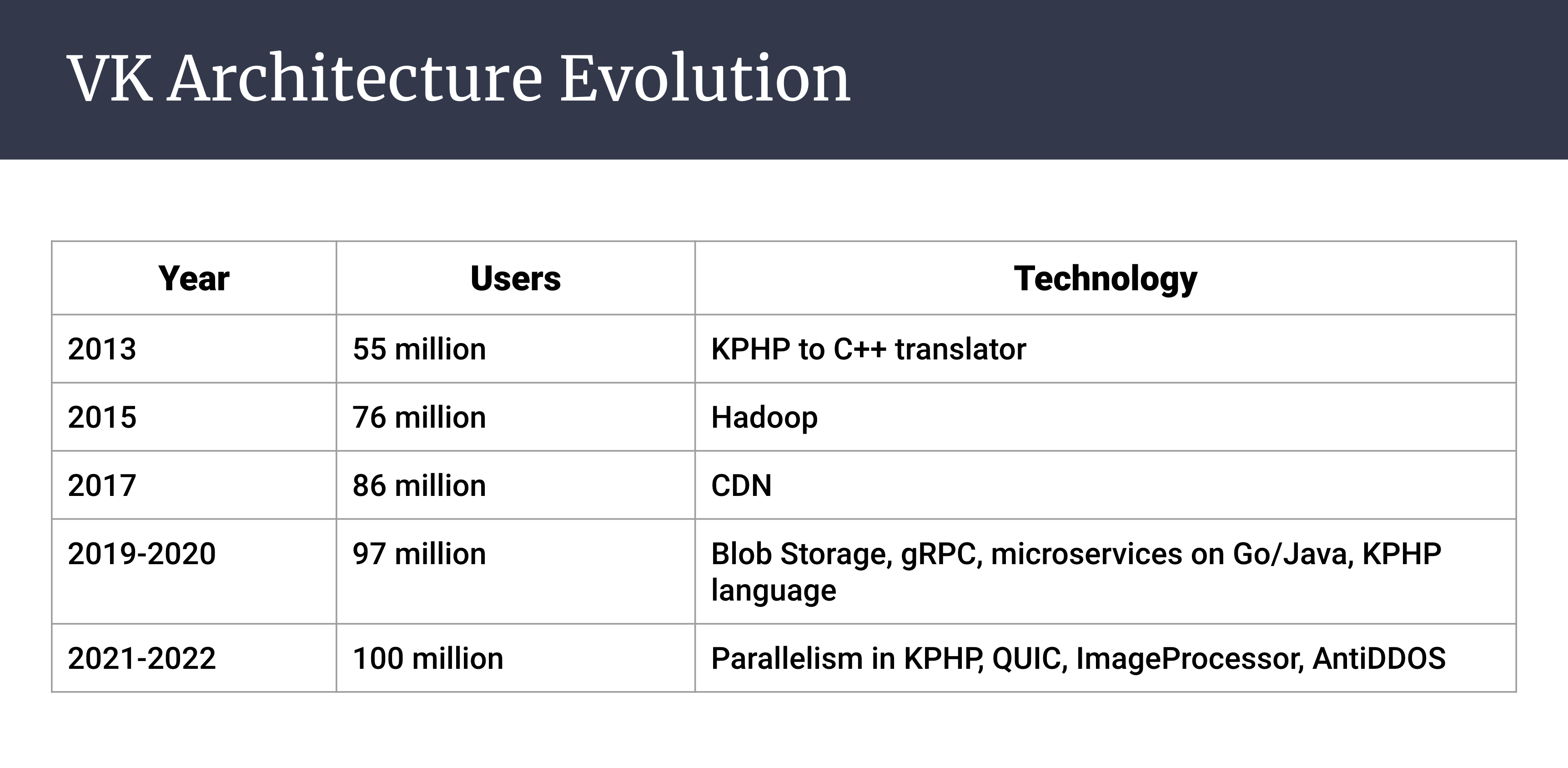
VK Architecture Evolution
- 2013 (55 million users): KPHP to C++ translator
- 2015 (76 million users): Hadoop
- 2017 (86 million users): CDN
- 2019-2020 (97 million users): Blob Storage, gRPC, microservices on Go/Java, KPHP language
- 2021-2022 (100 million users): Parallelism in KPHP, QUIC, ImageProcessor, AntiDDOS
So, what happened? As the platform’s popularity grew, attracting a larger audience, numerous bottlenecks appeared, and optimization became a necessity:
- The databases could no longer keep up
- The project’s codebase became too large and slow
- The volume of user-generated content also increased, creating new bottlenecks
Let’s dive into how we addressed these challenges.
Data Storage Solutions
In normal-sized projects, traditional databases like MySQL can meet all your needs. However, in high-load projects, each need often requires a separate data storage solution.
As the load increased, it became crucial to switch to custom, highly specialized databases with data stored in simple, fast, low-level structures.
In 2009, when relational databases couldn’t efficiently handle the growing load, the team started developing their own data storage engines. These engines function as microservices with embedded databases written in C and C++. Currently, there are about 800 engine clusters, each responsible for its own logic, such as messages, recommendations, photos, hints, letters, lists, logs, news, etc. For each task needing a specific data structure or unusual queries, the C team creates a new engine.
Benefits of Custom Engines
The custom engines proved to be much more efficient:
- Minimal structuring: Engines use simple data structures. In some cases, they store data as nearly bare indexes, leading to minimal structuring and processing at the reading stage. This approach increases data access and processing speed.
- Efficient data access: The simplified structure allows for faster query execution and data retrieval.
- Fast query execution: Custom-tailored queries can be optimized for specific use cases.
- Performance optimization: Each engine can be fine-tuned for its specific task.
- Scalability: We also get more efficient data replication and sharding. Reliance on master/slave replication and strict data-level sharding enables horizontal scaling without issues.
Heavy Caching
Another crucial aspect of our high-load system is caching. All data is heavily cached, often precomputed in advance.
Caches are sharded, with custom wrappers for automatic key count calculation on the code level. In large systems like ours, caching moves from merely improving performance as the main goal to reducing load on the backend.
The benefits of this caching strategy include:
- Precomputed data: Many results are calculated ahead of time, reducing response times.
- Automatic code-level scaling: Our custom wrappers help manage cache size efficiently.
- Reduces load on the backend: By serving pre-computed results, we significantly decrease the workload on our databases.
KPHP: Optimizing Application Code
The next challenge was optimizing the application code. It was written in PHP and became too slow, but changing the language was impossible with millions of lines of code in the project.
This is where KPHP came into play. The goal of the KPHP compiler is to transform PHP code into C++. Simply put, the compiler converts PHP code to C++. This approach boosts performance without the extensive problems associated with rewriting the entire codebase.
The team started improving the system from bottlenecks, and for them, it was the language, not the code itself.
KPHP Performance
- 2-40 times faster in synthetic tests
- 10 times faster in production environments
In real production environments, KPHP proved to be from 7 to 10 times faster than standard PHP.
KPHP Benefits
KPHP was adopted as the backend of VK. By now it supports PHP 7 and 8 features, making it compatible with modern PHP standards. Here are some key benefits:
- Development convenience: Allows fast compilation and efficient development cycles
- Support for PHP 7/8: Keeps up with modern PHP standards
- Open Source Features:
- Fast compilation
- Strict typing: Reduces bugs and improves code quality
- Shared memory: For efficient memory management
- Parallelization: Multiple processes can run simultaneously
- Coroutines: Enables efficient concurrent programming
- Inlining: Optimizes code execution
- NUMA support: Enhances performance on systems with Non-Uniform Memory Access
Noverify PHP Linter
To further enhance code quality and reliability, we implemented the Noverify PHP linter. This tool is specifically designed for large codebases and focuses on analyzing git diffs before they are pushed.
Key features of Noverify include:
- Indexes approximately 1 million lines of code per second
- Analyzes about 100,000 lines of code per second
- Can also run on standard PHP projects
By implementing Noverify, we’ve significantly improved our code quality and caught potential issues before they made it into production.
Microservices Architecture
As our system grew, we also partly transitioned to a microservices architecture to accelerate time to market. This shift allowed us to develop services in various programming languages, primarily Go and Java, with gRPC for communication between services.
The benefits of this transition include:
- Improved time to market: Smaller, independent services can be developed and deployed more quickly.
- Language flexibility: We can develop services in different languages, choosing the best tool for each specific task.
- Greater development flexibility: Each team can work on their service independently, speeding up the development process.
Addressing Content Storage and Delivery Bottlenecks
After optimizing databases and code, we began breaking the project into optimized microservices, and the focus shifted to addressing the most significant bottlenecks in content storage and delivery.
Images emerged as a critical bottleneck in the social network. The problem is that the same image needs to be displayed in multiple sizes due to interface requirements and different platforms: mobile with retina/non-retina, web, and so on.
Image Processor and WebP Format
To tackle this challenge, we implemented two key solutions:
- Image processor: We eliminated pre-cut sizes and instead implemented dynamic resizing. We introduced a microservice called Image Processor that generates required sizes on the fly.
- WebP format: We transitioned to serving images in WebP format. This change was very cost-effective.
The results of switching from JPEG to WebP were significant:
- 40% reduction in photo size
- 15% faster delivery time (50 to 100 ms improvement)
These optimizations led to significant improvements in our content delivery system. It’s always worth identifying and optimizing the biggest bottlenecks for better performance.
Industry-Wide High-Load Solutions
While the choice of technologies is unique for each high-load company, many approaches overlap and demonstrate effectiveness across the board. We’ve discussed some of VK’s strategies, and it’s worth noting that many other tech giants also employ similar approaches to tackle high-load challenges.
- Netflix: Netflix uses a combination of microservices and a distributed architecture to deliver content efficiently. They implement caching strategies using EVCache and have developed their own data storage solutions.
- Yandex: As one of Russia’s largest tech companies, Yandex uses a variety of in-house databases and caching solutions to manage its search engine and other services. I cannot but mention ClickHouse here, a highly specialized database developed by Yandex to meet its specific needs. This solution proved to be so fast and efficient that it is now widely used by others. Yandex created an open-source database management system that stores and processes data by columns rather than rows. Its high-performance query processing makes it ideal for handling large volumes of data and real-time analytics.
- LinkedIn: LinkedIn implements a distributed storage system called Espresso for its real-time data needs and leverages caching with Apache Kafka to manage high-throughput messaging.
- Twitter (X): X employs a custom-built storage solution called Manhattan, designed to handle large volumes of tweets and user data.
Conclusion
Wrapping up, let’s quickly revise what we’ve learned today:
- High-load systems are applications built to support a large number of users or transactions at the same time and they require excellent performance and reliability.
- The challenges of high-load systems include limits on scalability, reliability issues, performance slowdowns, and complicated integrations.
- High-load systems have specific requirements: preventing data loss, allowing fast feature updates, and keeping downtime to a minimum.
- Using external solutions can become risky under high loads, so often there is a need to go for custom solutions.
- To optimize a high-load system, you need to identify the key bottlenecks and then find ways to approach them. This is where the optimization begins.
- High-load systems rely on effective scalable data storage with good caching, compiled languages, distributed architecture, and good tooling.
- There are no fixed rules for creating a high-load application; it’s always an experimental process.
Remember, building and maintaining high-load systems is a complex task that requires continuous optimization and innovation. By understanding these principles and being willing to develop custom solutions when necessary, you can create robust, scalable systems capable of handling millions of users and requests.
Opinions expressed by DZone contributors are their own.
Comments