Data Management in Complex Systems
Learn the reasons to use application databases and explicit publishing of data in your architecture, and how to manage growth in your data scope and size.
Join the DZone community and get the full member experience.
Join For FreeThis is an article from DZone's 2022 Database Systems Trend Report.
For more:
Read the Report
It is somewhat of a cliché to consider the data in your systems as far more valuable than the actual applications that compose it. Those applications are updated, mutated, retired, and replaced, but the data persists. For many enterprises, that data is their most important asset. It used to be simple. You had the database for the organization. There was only one place where everything the organization did and knew was stored, and it was what you went to for all needs. One database to administer, monitor, optimize, backup, etc. — to rule the entire organization’s data needs.
As the organization grew, there was ever more data and therefore more needs and requirements added to the database. At some point, you hit the absolute limits of what you can do. You cannot work with a single database anymore; you must break your systems and your database into discrete components. In this article, I’m going to discuss how you can manage the growth in your data scope and size.
The Death of the Shared Database: Why We Can't Get a Bigger Machine
While not commonplace, it’s by far not uncommon to work with databases in the terabyte range with billions of records these days. So what is the problem? The issue isn’t with the technical limitations of a particular database engine. It is the organizational weight of throwing everything (including at least two kitchen sinks and a birthday cake) into a single database. At one company that I worked with, the database had a bit over 30,000 tables in it, for example. The number of views and stored procedures were much higher. We won’t talk about the number of triggers.
None of the tooling for working with the database expected to deal with this number of tables. Connecting to the database through any GUI tool would often cause the tool to freeze for minutes at a time while it read the schema descriptions for a short eternity. Absolutely no one actually had an idea of what was going on inside that database, but the data and the processes around it were critical to the success of the organization. The only choice was to either stagnate in place or start breaking the database apart into manageable chunks.
That was many years ago, and the industry landscape has changed. Today, when thinking about data, we have so many more concerns to juggle, such as:
- Personal data belonging to a European citizen, which means that any data associated with them must also physically reside in the EU and is subject to GDPR rules.
- Healthcare information (directly or indirectly), which has a whole new set of rules to follow (e.g., HIPAA, HITECH, or ENISA rulings).
Concerns such as data privacy and provenance are far more important, like being able to audit and analyze who accesses a particular data item and why it can be a hard requirement in many fields. The notion of one bucket in which all the information in the organization resides is no longer viable.
Another important sea change was common architectural patterns. Instead of a single monolithic system to manage everything in the organization, we now break apart our systems into much smaller components. Those components have different needs and requirements, are released on different schedules, and use different technologies. The sheer overhead of trying to coordinate between all of those teams when you need to make a change is a big barrier when you want to make changes in your system. The cost of coordination across so many teams and components is simply too high.
Instead of using a single shared database, the concept of independent application databases is commonly used. This is an important piece of a larger architectural concept. You’ll encounter that under the terms microservices and service-oriented architecture, typically.
The Application Database as an Implementation Decision
One of the most important distinctions between moving from a single shared database to a set of applications databases is that we aren’t breaking apart the shared database. A proper separation at the database level is key. A set of shared databases will have the exact same coordination issues, with too many cooks in the kitchen. Application databases, when properly separated, will benefit us by allowing us to choose the best database engine for each task, localizing change, and reducing the overhead in communicating changes. The downside of this approach is that we’ll have more systems to support in production.
Let’s talk in more depth about the distinction between shared databases and application databases. It’s easy to make the mistake, as you can see in Figure 1, for example:
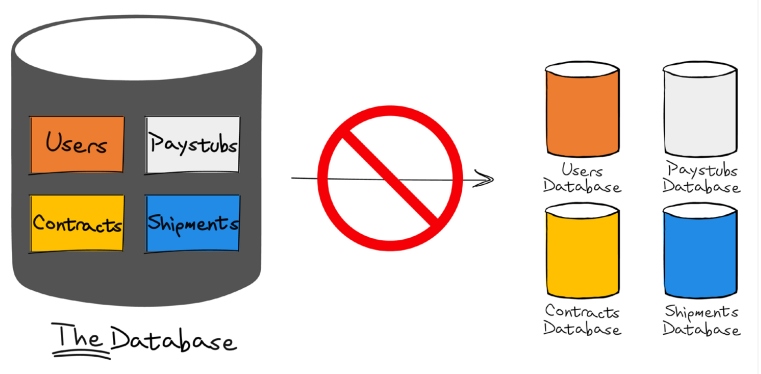
Figure 1: The wrong migration path from single shared database to multiple (still shared) databases
While a shared database is something that you implement because there isn’t another option, an application database is an internal choice and isn’t meant to be accessible to anyone but the application. In the same sense that we have encapsulation in object-oriented programming, with private variables that hide our state, the application database is very explicitly a concern of no one outside of the application. I feel quite strongly in the matter.
When you write code, you know that directly working with the private state of other objects is wrong. You may be violating invariants; you will complicate future maintenance and development. This has been hammered down so much that most developers have an almost instinctual reluctance to do so. The exact same occurs when you directly touch another application’s database, but that is an all-too-common occurrence.
In some cases, I resorted to encrypting all the names of the tables and columns in my database to make it obvious that you are not supposed to be looking into my database. The application database is the internal concern of the application, no one else. The idea is simple. If any entity outside of the application needs some data, they need to ask the application for that. They must not go directly into the application’s database to figure things out. It’s the difference between asking "Who are you talking to" and going over all their call logs and messages. In theory this is a great approach, but you need to consider that your application is rarely the application for the system. You have to integrate with the rest of the ecosystem. The question is how you do that.
If the system described here sounds familiar, it's because you have likely heard about it before. It began as part of DCOM/ COBRA systems, then it was called service-oriented architecture, and nowadays it's referred to as microservices.
Let’s assume that the application that deals with shipping in our system needs to access some customer data to complete its tasks. How would it go about getting that data? When using a shared database, query the customers' tables directly. When the team that owns the customers’ application needs to add a column, or refactor the data, your system will be broken. There is no encapsulation or separation between them. The path of direct dependencies on another team’s implementation details leads to ruin, stagnation, and ever-increasing complexity. I’m not a fan, if you can’t tell.
Working With Global Data
Alternatively, the shipping application can (through a published service interface) ask the application that owns the customers’ data to fetch the details it needs. This is usually done through RCP calls from one application to the other. The issue here is that this creates a strong tie between the two applications. If the customers' application is down for maintenance, the shipping application will not work. Compound that with a few dozen such applications and their interdependencies, and you have a recipe for a gridlock. We need to consider a better way to approach this situation.
My recommendation is to go about the whole process in the other direction. Instead of the shipping application querying the customers’ application for relevant data, we’ll inverse things. As part of the service interface of the customers’ application, we can decide what kind of information we want to make public to the rest of the organization.
It is important to note that the data we publish is absolutely part of the service contract. We do not provide direct access to our database. The application should publish its data to the outside world. That can be a daily CSV file uploaded to an FTP site or a GraphQL endpoint to choose two very different technologies and semantics.
I included CSV over FTP specifically to point out that the way this data share is done is not relevant. What matters is that there is an established way for the data to be published from the application because a key aspect of this architectural style is that we don’t query for the data at the time we need it. Instead, we ingest that into our own systems. I hope it is clear why the shipping application won’t just open an FTP connection to the customers’ daily CSV dump file to find some details. In the same sense, it shouldn’t be querying the GraphQL endpoint as part of its normal routine.
Instead, we have an established mechanism whereby the customers’ data (that the customers’ application has made public to the rest of the organization) is published. That is ingested by other applications in the system and when they need to query on customers’ details, they can do that from their own systems. You can see how this looks like in Figure 2.

Figure 2: The customers’ application publishing data for use by the shipping application
In each application, the data may be stored and represented in a different manner. In each case, that would be whatever is optimal for their scenarios.
The publishing application can also work with the data in whatever manner they choose. The service boundary between the database and the manner in which the data is published allow the freedom to modify internal details without having to coordinate with external systems.
Another option is to have a two-stage process, as shown in Figure 3. Instead of the customers’ application sending its updates to the shipping application, the customers’ application will send it to the organization data lake. In this manner, each application is sending the data they wish to make public to a central location. And other applications can copy the data they need from the data lake to their own database.
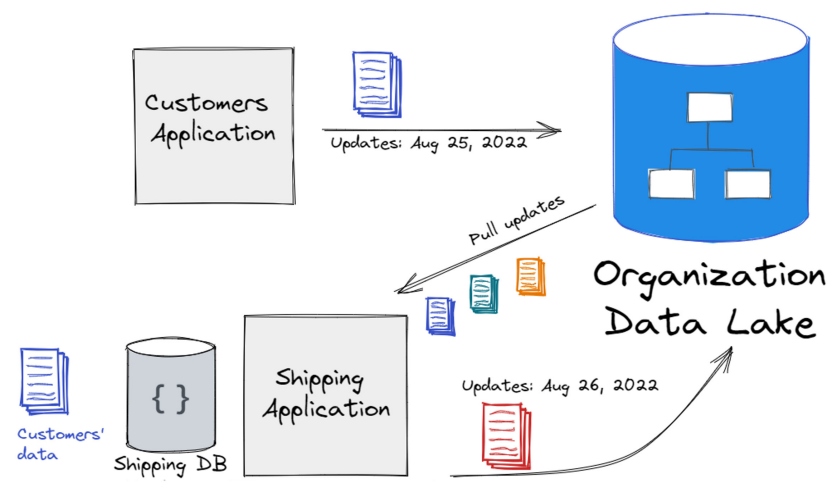
Figure 3: Publishing to a data lake from each application and pulling data to each application
The end result is a system where the data is shared, but without the temporal dependencies between applications and services. It also ensures the boundary between different teams and systems. As long as the published interfaces remain the same, there is no need for coordination or complexity.
Applying This Architecture Style in the Real World
Let's dive into some concrete advice on how to apply this architectural approach. You can publish the data globally by emitting events on a service bus or by publishing daily files. You can publish the data for a specific scenario, such as an ETL process from the customers’ database to the shipping’s database. The exact how doesn’t matter, as long as we have the proper boundary in place and we can change how we do it without incurring global coordination costs.
This style of operation only works when we need to reference data or make decisions on data where consistency isn’t relevant. This approach is not relevant if we need to make or coordinate changes to the data. A great example of a scenario where consistency doesn’t matter is looking up the customer’s name from their ID. If we have the old name, that isn’t a major issue. It will fix itself shortly, and we don’t make decisions based on the customer's name. At the same time, we can run all our computations and work completely locally within the scope of the application, which is a great advantage.
Consistency matters when we need to make a decision or modify the data. For example, in the shipping scenario, if we need to charge for overweight shipping, we need to ensure that the customer has sufficient funds in their account (and we need to deduct the shipping amount). In this case, we cannot operate on our own data. We don’t own the funds in the account, after all. Nor are we able to directly change it. In such a case, we need to go to the customers’ application and ask to deduct those funds and raise an error if there are insufficient funds. Note that we want the shipping process to fail if the customer cannot pay for it.
Our applications are no longer deployed to a single server or even a single data center. It is common today to have applications that run on edge systems (such as mobile applications or IoT devices). Pushing all that data to our own systems may cause us to store a lot of data. This architecture style of data encapsulation and publishing only the details we want to expose to other parties plays very well in this scenario.
Instead of having to replicate all the information to a central location, we can store the data in the edge and accept just enough data from the edge devices to be able to make decisions and operate the global state of the system. Among other advantages, this approach keeps the user in control of all of their data, which I consider a major plus.
Closing Thoughts
There are a few reasons to use application databases and explicit publishing of data in your architecture. First, it means that the operations are running with local resources and minimal coordination. That, in turn, means that the operations are going to be faster and more reliable. Second, it reduces the coordination overhead across the board, meaning that we can deploy and change each application independently as the need arises.
Finally, it means that we can choose the best option for each scenario independently. Instead of catering for the lowest common denominator, we can select the best of breed for each option. For example, we can use a document database to store shipping manifest but throw the historical data into a data lake.
Each one of the applications is independent and isolated from one another, and we can make the best technical choice for each scenario without having to consider any global constraints. The result is a system that is easier to change, composed of smaller components (hence simpler to understand), and far more agile.
This is an article from DZone's 2022 Database Systems Trend Report.
For more:
Read the Report
Opinions expressed by DZone contributors are their own.
Comments