How To Address Relevancy Challenges in Retrieval Augmented Generation
In part 1, see how suboptimal embedding models, inefficient chunking strategies, and a lack of metadata filtering can make it hard to get relevant responses from your LLM.
Join the DZone community and get the full member experience.
Join For FreeBuilding generative AI applications that use retrieval augmented generation (RAG) can pose a host of challenges. Let’s look at troubleshooting RAG implementations that rely on vector databases to retrieve relevant context that’s then included in a prompt to a large language model to provide more relevant results.
We will break this process down into two main parts. The first, which we’ll address in this first article in the series, is the embedding pipeline, which populates the vector database with embeddings:
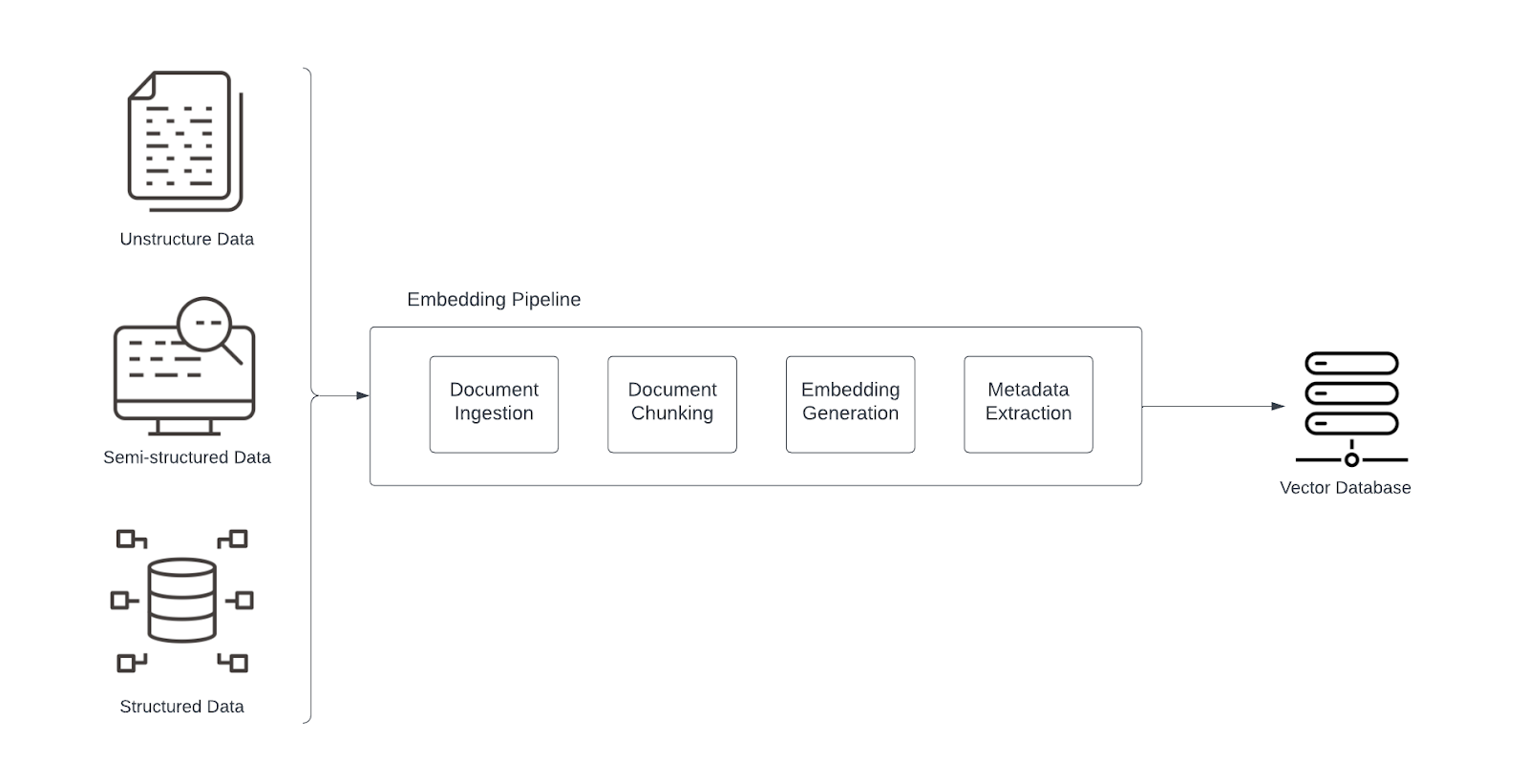
Here, we will consider three main areas that can lead to poor results: suboptimal embedding models, inefficient chunking strategies, and lack of metadata filtering. (In the upcoming article, we’ll look at the actual interaction with the LLM and examine some common problems that crop up there and can lead to poor results.)
Selecting an Appropriate Embedding Model
Your choice of an embedding model will have a significant impact on the overall relevance and usability of your RAG application. As such, it requires a nuanced understanding of each model’s capabilities and an analysis of how those capabilities align with your application’s requirements.
If you are relatively new to RAG and embeddings in general, one of the best resources you should be aware of is the MTEB (Massive Text Embedding Benchmark) embedding leaderboard. We focus on retrieval use cases in this post, but embeddings can, of course, be used for many other applications, including classification, clustering, and summarization. The leaderboard can help you identify the models that will perform best for your specific use case.
One of the most common reasons for poor RAG performance is that developers new to this space do a Google search to find examples of embedding generation. They often find samples that use embedding models such as Word2Vec, sBERT and RoBERTa that are poor choices for retrieval use cases. If you found this article because you’re debugging poor relevance results and you used something like sBERT to generate your embeddings, then we’ve likely identified the cause of your relevance problems.
If so, the next question you will likely have is which embedding models you can use to improve your similarity search results. Without knowing the particulars of your use case, the three we would recommend are:
1. text-embedding-ada-002 (Ada v2)
Ada v2 from OpenAI is probably the most common starting point for most RAG applications simply because so many developers start off with Open AI’s APIs. Ada v2 performs admirably in retrieval use cases and was built to handle different types of content, including text and code. With a maximum input sequence length of up to 8,192 tokens, it also allows you to create embeddings for much longer pieces of text than alternative models. This is both a blessing and a curse. Having a large sequence size simplifies the process of creating embeddings for more of your text content, and it allows the embedding model to identify relationships across words and sentences in a bigger body of text.
However, this also results in similarity searches that can become more fuzzy when comparing the similarity of two long documents when what you’re looking for is relevant chunks of context to facilitate the generation process.
There are two big drawbacks of Ada v2. The first is that it can’t be run locally. You must use OpenAI’s API to create the embedding. This can not only introduce bottlenecks for cases where you want to create embeddings for many pieces of content, but it also adds a cost of $0.0001 per 1,000 tokens. The second is that the embeddings created from the Open AI model are 1,536 dimensions each. If you are using a cloud vector database, this can considerably add to your vector storage costs.
When to choose: You want a simple solution that only requires an API call, you potentially need to vectorize large documents, and the cost is not an issue.
2. jina-embeddings-v2 (Jina v2)
Jina v2 is a new open source embedding model that gives you the same 8,000 input sequence support as Ada v2 and actually scores slightly better in retrieval use cases.
Jina v2 provides an antidote to the problems of Ada v2. It’s open source under Apache License 2.0 and can be run locally, which, of course, is also a drawback if you aren’t looking to run your own code to do this. It also produces an embedding vector with half the dimensions of Ada v2. So not only do you get slightly better retrieval performance on benchmark use cases, but you also get those improved results with lower storage and compute requirements from a vector database perspective.
When to choose: You want to use an open source solution and potentially need to vectorize large documents and are comfortable running embedding pipelines locally. You want to reduce vector database costs with lower-dimension embeddings.
3. bge-large-en-v1.5
bge-large-en-v1.5 is open sourced under the MIT license and is currently the top-ranked embedding model on the MTEB leaderboard for retrieval use cases. With a smaller input sequence, it will require you to give more thought to your chunking strategy, but ultimately provides the best all-around performance for retrieval use cases.
When to choose: You want to use an open source solution and are willing to spend more time on chunking strategies to stay within the input size limitations. You are comfortable running embedding pipelines locally. You want the best-performing embedding model for retrieval use cases.
While outside the scope of this article, you might want to dig deeper into the 15 benchmarks in the MTEB leader board to identify the one that most closely resembles your specific situation. While there are definitely patterns in terms of how well various embedding models perform across the different benchmarks, there are often specific models that stand out in each. If you need to further refine your embedding selection, this is a possible area of further investigation.
Optimizing Your Chunking Strategy
The segmentation or “chunking” of input text is a pivotal factor that significantly influences the relevance and accuracy of the generated output. Various chunking strategies offer unique advantages and are suited for specific types of tasks. Here, we delve into these methodologies and provide guidelines for their application, incorporating some key considerations:
Fixed-Length Chunking
- When to Use: Unless your content itself is highly structured and of fixed length, you usually want to rely on a more useful chunking strategy like the ones that follow.
- Technical Consideration: While very simple to implement, this chunking strategy is generally going to lead to poor results in RAG applications.
- Additional Insight: If you are using a fixed-length strategy with your RAG application and having trouble retrieving relevant context, you should consider switching to a different chunking approach.
Sentence-Level Chunking
- When to Use: This strategy is effective when each sentence in the input text is rich in meaning and context. It allows the model to concentrate on the intricacies within each sentence, thereby generating more coherent and contextually relevant responses. You’ll rarely rely on sentence-level chunking for RAG use cases.
- Technical Consideration: Sentence-level chunking often involves tokenization based on sentence boundaries, which can be achieved using natural language processing (NLP) libraries.
- Additional Insight: Sentence-level chunking can be particularly useful when you’re searching for specific statements, such as in a transcript of a meeting where you’re trying to find semantically similar statements to a given piece of text.
Paragraph-Level Chunking
- When to Use: Employ this strategy when the input text is organized into distinct sections or paragraphs, each encapsulating a separate idea or topic. This enables the model to focus on the relevant information within each paragraph.
- Technical Consideration: Identifying paragraph boundaries usually involves detecting newline characters or other delimiters that signify the end of a paragraph.
- Additional Insight: Paragraph-level chunking can be useful when you have documents that cover many different aspects of the same topic. For example, a page of product documentation might introduce a product feature, explain when to use it, talk about how to configure it, and give examples of different configurations. Using paragraph-level chunking can help you identify the most relevant part of the document to provide to the LLM as context.
Content-Aware Chunking
- When to Use: Opt for this strategy when the relevance of specific sections within the text is paramount. For instance, in legal documents, segmenting the text based on clauses or sections can yield more context-specific responses.
- Technical Consideration: This approach may require advanced NLP techniques to understand the semantic boundaries within the text.
- Additional Insight: Content-aware chunking is especially useful when dealing with structured or semi-structured data, as specific chunks can be combined with metadata filtering for more precise retrieval. For example, in a legal document, you might want to extract all warranty or indemnification clauses, and when you store embeddings for chunks in a vector database, you can use metadata to make it easier to search for content of a given type when building a RAG use case.
Recursive Chunking
- When to Use: Recursive chunking divides data into smaller and smaller pieces using a hierarchical approach. For example, when chunking a text document, you might divide the text into paragraphs first, then into sentences and finally, words. Once the data has been divided into the first set of chunks, you can then recursively apply the chunking process to each of the smaller chunks, repeating until you reach the smallest chunk size you’re interested in.
- Technical Consideration: Implementing recursive chunking might involve a multilevel parsing strategy where chunks are further divided into sub-chunks based on additional criteria. If you’re using LangChain, its recursive implementation is a bit simpler than what is described here.
- Additional Insight: This approach enables the model to understand context at multiple levels, from high-level themes to detailed nuances, making it particularly useful for complex documents like academic papers, technical manuals, or legal contracts. This brings flexibility benefits since similarity searches can identify similar text for both broader and shorter queries. However, this also means that there is a possibility that similar chunks from the same source document could end up being overrepresented in similarity searches as well, especially if you opt for a longer overlap between chunks in your text splitter configuration.
As a general approach, before you try chunking up a big corpus and vectorizing it, you should consider doing some ad-hoc experimentation with your data. Manually inspect the documents you would want to retrieve for a given query, identify the chunks that represent the ideal context you would want to provide the LLM, and then experiment with chunking strategies to see which one gives you the chunks you feel would be most relevant for the LLM to have.
Context Window Consideration
The available context window of an LLM is an important factor in selecting a chunking strategy. If the context window is small, you’ll need to be more selective in the chunks you feed into the model to ensure that the most relevant information is included. Conversely, a larger context window allows for more flexibility, enabling the inclusion of additional context that may enhance the model’s output, even if not all of it is strictly necessary.
By experimenting with these chunking strategies and taking these considerations into account, you can evaluate their impact on the relevance of the generated outputs. The key is to align the chosen strategy with the specific requirements of your RAG application, preserve the semantic integrity of the input, and offer a comprehensive understanding of the context. This will enable you to find the right chunking process for optimal performance.
Metadata Filtering
As the number of embeddings in your search index grows, approximate nearest neighbors (ANN) become less helpful when looking for relevant context to include in your prompts. Let’s say you have indexed embeddings for 200 articles in your knowledge base. If you can identify the top nearest neighbor with an accuracy of 1%, you are likely to find pretty relevant results because 1% represents the top two articles out of those 200, and you’re going to get one of those two.
Now consider a search index containing every article on Wikipedia. That would amount to approximately 6.7 million articles. If your nearest neighbor is in the top 1% of most similar articles, that means that you’re getting one of the 67,000 most similar articles. With a corpus like Wikipedia, this means that you could still end up being very far off the mark.
Metadata filtering gives you a way to narrow down the pieces of content by first filtering the documents and then applying the nearest neighbor algorithm. In cases where you're dealing with a large number of possible matches, this initial pre-filtering can help you narrow the possible options before retrieving the nearest neighbors.
Coming up next, we’ll dive into the interaction with the LLM and examine some common problems that can lead to poor results.
Published at DZone with permission of Chris Latimer. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments