Pivoting Database Systems Practices to AI: Create Efficient Development and Maintenance Practices With Generative AI
Explore how AI can revolutionize modern database development and maintenance through automation, real-time AI applications, and more.
Join the DZone community and get the full member experience.
Join For FreeEditor's Note: The following is an article written for and published in DZone's 2024 Trend Report, Database Systems: Modernization for Data-Driven Architectures.
Modern database practices enhance performance, scalability, and flexibility while ensuring data integrity, consistency, and security. Some key practices include leveraging distributed databases for scalability and reliability, using cloud databases for on-demand scalability and maintenance, and implementing NoSQL databases for handling unstructured data. Additionally, data lakes store vast amounts of raw data for advanced analytics, and in-memory databases speed up data retrieval by storing data in main memory. The advent of artificial intelligence (AI) is rapidly transforming database development and maintenance by automating complex tasks, enhancing efficiency, and ensuring system robustness.
This article explores how AI can revolutionize development and maintenance through automation, best practices, and AI technology integration. The article also addresses the data foundation for real-time AI applications, offering insights into database selection and architecture patterns to ensure low latency, resiliency, and high-performance systems.
How Generative AI Enables Database Development and Maintenance Tasks
Using generative AI (GenAI) for database development can significantly enhance productivity and accuracy by automating key tasks, such as schema design, query generation, and data cleaning. It can generate optimized database structures, assist in writing and optimizing complex queries, and ensure high-quality data with minimal manual intervention. Additionally, AI can monitor performance and suggest tuning adjustments, making database development and maintenance more efficient.
Generative AI and Database Development
Let's review how GenAI can assist some key database development tasks:
- Requirement analysis. The components that need additions and modifications for each database change request are documented. Utilizing the document, GenAI can help identify conflicts between change requirements, which will help in efficient planning for implementing change requests across dev, QA, and prod environments.
- Database design. GenAI can help develop the database design blueprint based on the best practices for normalization, denormalization, or one big table design. The design phase is critical and establishing a robust design based on best practices can prevent costly redesigns in the future.
- Schema creation and management. GenAI can generate optimized database schemas based on initial requirements, ensuring best practices are followed based on normalization levels and partition and index requirements, thus reducing design time.
- Packages, procedures, and functions creation. GenAI can help optimize the packages, procedures, and functions based on the volume of data that is processed, idempotency, and data caching requirements.
- Query writing and optimization. GenAI can assist in writing and optimizing complex SQL queries, reducing errors, and improving execution speed by analyzing data structures based on data access costs and available metadata.
- Data cleaning and transformation. GenAI can identify and correct anomalies, ensuring high-quality data with minimal manual intervention from database developers.
Generative AI and Database Maintenance
Database maintenance to ensure efficiency and security is crucial to a database administrator's (DBA) role. Here are some ways that GenAI can assist critical database maintenance tasks:
- Backup and recovery. AI can automate back-up schedules, monitor back-up processes, and predict potential failures. GenAI can generate scripts for recovery scenarios and simulate recovery processes to test their effectiveness.
- Performance tuning. AI can analyze query performance data, suggest optimizations, and generate indexing strategies based on access paths and cost optimizations. It can also predict query performance issues based on historical data and recommend configuration changes.
- Security management. AI can identify security vulnerabilities, suggest best practices for permissions and encryption, generate audit reports, monitor unusual activities, and create alerts for potential security breaches.
- Database monitoring and troubleshooting. AI can provide real-time monitoring, anomaly detection, and predictive analytics. It can also generate detailed diagnostic reports and recommend corrective actions.
- Patch management and upgrades. AI can recommend optimal patching schedules, generate patch impact analysis reports, and automate patch testing in a sandbox environment before applying them to production.
Enterprise RAG for Database Development
Retrieval augmented generation (RAG) helps in schema design, query optimization, data modeling, indexing strategies, performance tuning, security practices, and back-up and recovery plans. RAG improves efficiency and effectiveness by retrieving best practices and generating customized, context-aware recommendations and automated solutions. Implementing RAG involves:
- Building a knowledge base
- Developing retrieval mechanisms
- Integrating generation models
- Establishing a feedback loop
To ensure efficient, scalable, and maintainable database systems, RAG aids in avoiding mistakes by recommending proper schema normalization, balanced indexing, efficient transaction management, and externalized configurations.
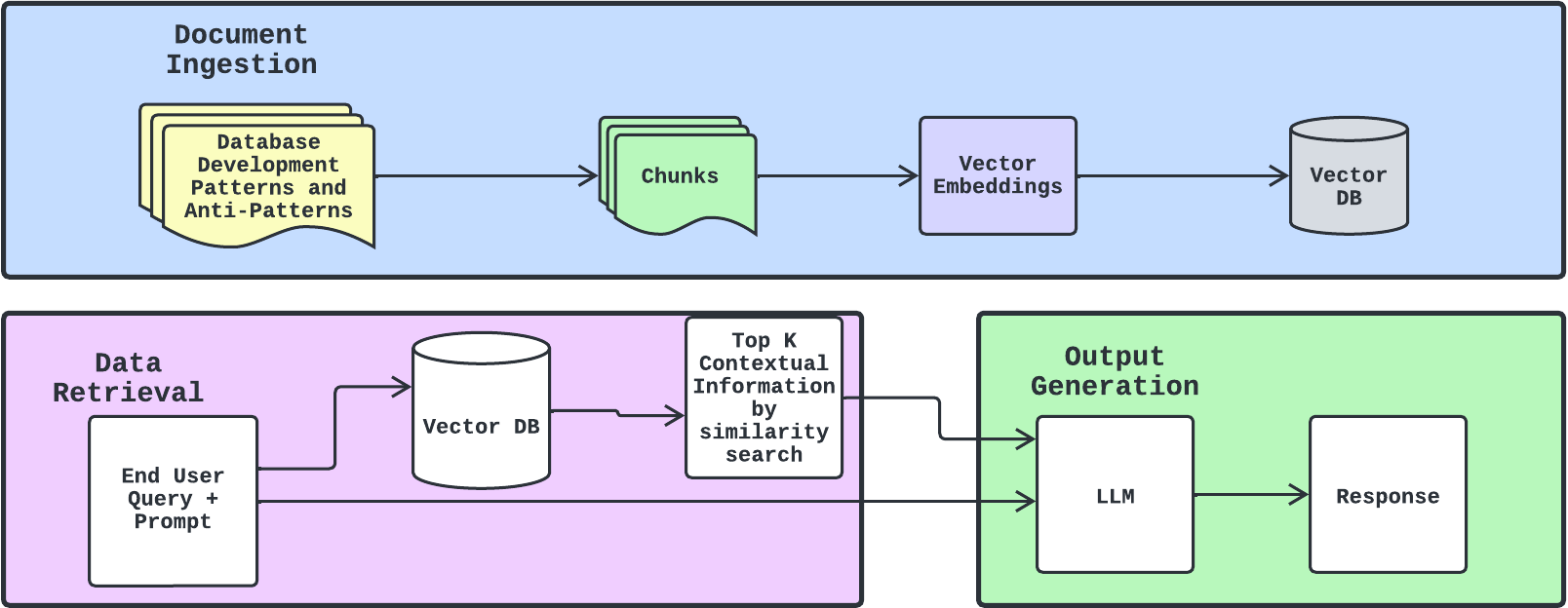
RAG Pipeline
When a user query or prompt is input into the RAG system, it first interprets the query to understand what information is being sought. Based on the query, the system searches a vast database or document store for relevant information. This is typically accomplished using vector embeddings, where both the query and the documents are converted into vectors in a high-dimensional space, and similarity measures are used to retrieve the most relevant documents.
The retrieved information, along with the original query, is fed into a language model. This model uses both the input query and the context provided by the retrieved documents to generate a more informed, accurate, and relevant response or output.
Figure 1. Simple RAG pipeline
Vector Databases for RAG
Vector databases are tailored for high-dimensional vector operations, making them perfect for similarity searches in AI applications. Non-vector databases, however, manage transactional data and complex queries across structured, semi-structured, and unstructured data formats. The table below outlines the key differences between vector and non-vector databases:
Table 1. Vector databases vs. non-vector databases
|
Feature |
Vector Databases |
Non-Vector Databases |
|
Primary use case |
Similarity search, machine learning, AI |
Transactional data, structured queries |
|
Data structure |
High-dimensional vectors |
Structured data (tables), semi-structured data (JSON), unstructured data (documents) |
|
Indexing |
Specialized indexes for vector data |
Traditional indexes (B-tree, hash) |
|
Storage |
Vector embeddings |
Rows, documents, key-value pairs |
|
Query types |
k-NN (k-nearest neighbors), similarity search |
CRUD operations, complex queries (joins, aggregations) |
|
Performance optimization |
Optimized for high-dimensional vector operations |
Optimized for read/write operations and complex queries |
|
Data retrieval |
Nearest neighbor search, approximate nearest neighbor (ANN) search |
SQL queries, NoSQL queries |
When taking the vector database route, choosing a suitable vector database involves evaluating: data compatibility, performance, scalability, integration capabilities, operational considerations, cost, security, features, community support, and vendor stability.
By carefully assessing these aspects, one can select a vector database that meets the application's requirements and supports its growth and performance objectives.
Vector Databases for RAG
Several vector databases in the industry are commonly used for RAG, each offering unique features to support efficient vector storage, retrieval, and integration with AI workflows:
- Qdrant and Chroma are powerful vector databases designed to handle high-dimensional vector data, which is essential for modern AI and machine learning tasks.
- Milvus, an open-source and highly scalable database, supports various vector index types and is used for video/image retrieval and large-scale recommendation systems.
- Faiss, a library for efficient similarity search, is widely used for large-scale similarity search and AI inference due to its high efficiency and support for various indexing methods.
These databases are chosen based on specific use cases, performance requirements, and ecosystem compatibility.
Vector Embeddings
Vector embeddings can be created for diverse content types, such as data architecture blueprints, database documents, podcasts on vector database selection, and videos on database best practices for use in RAG. A unified, searchable knowledge base can be constructed by converting these varied forms of information into high-dimensional vector representations. This enables efficient and context-aware retrieval of relevant information across different media formats, enhancing the ability to provide precise recommendations, generate optimized solutions, and support comprehensive decision-making processes in database development and maintenance.
Figure 2. Vector embeddings
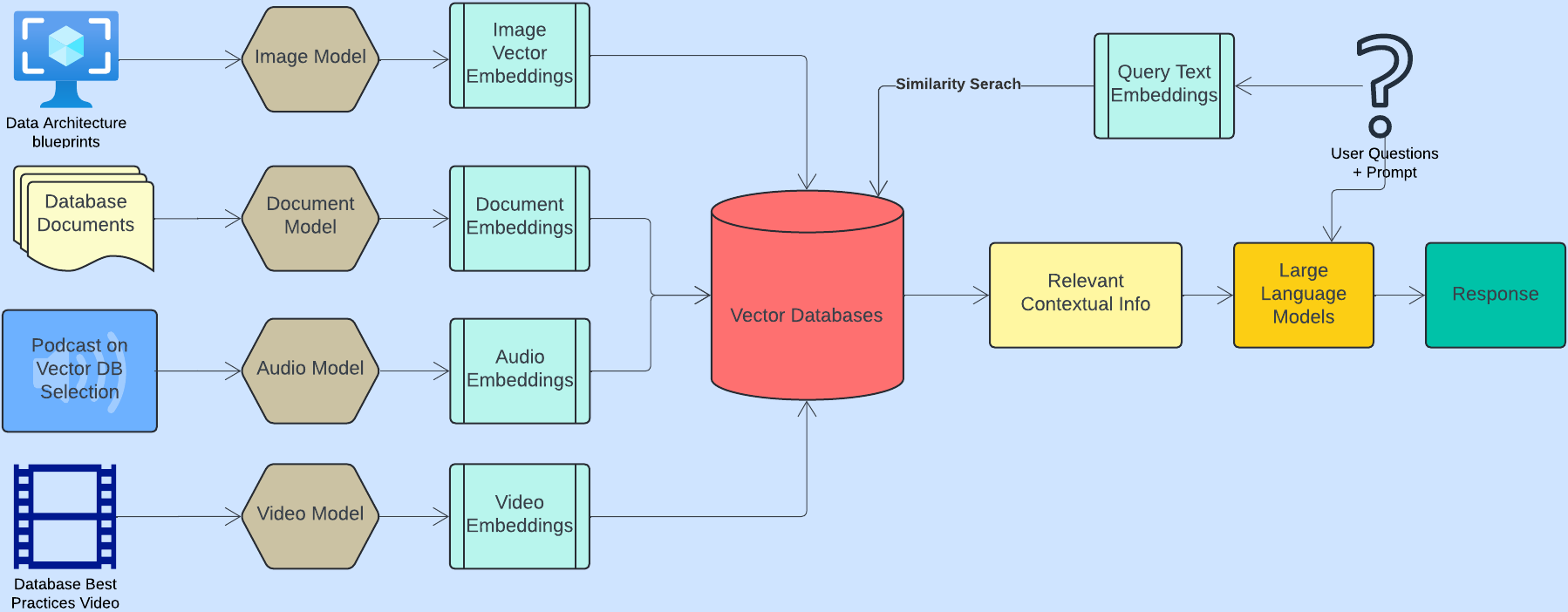
Vector Search and Retrieval
Vector search and retrieval in RAG involve converting diverse data types (e.g., text, images, audio) into high-dimensional vector embeddings using machine learning models. These embeddings are indexed using techniques like hierarchical navigable small world (HNSW) or ANN to enable efficient similarity searches.
When a query is made, it is also converted into a vector embedding and compared against the indexed vectors using distance metrics, such as cosine similarity or Euclidean distance, to retrieve the most relevant data. This retrieved information is then used to augment the generation process, providing context and improving the relevance and accuracy of the generated output. Vector search and retrieval are highly effective for applications such as semantic search, where queries are matched to similar content, and recommendation systems, where user preferences are compared to similar items to suggest relevant options. They are also used in content generation, where the most appropriate information is retrieved to enhance the accuracy and context of the generated output.
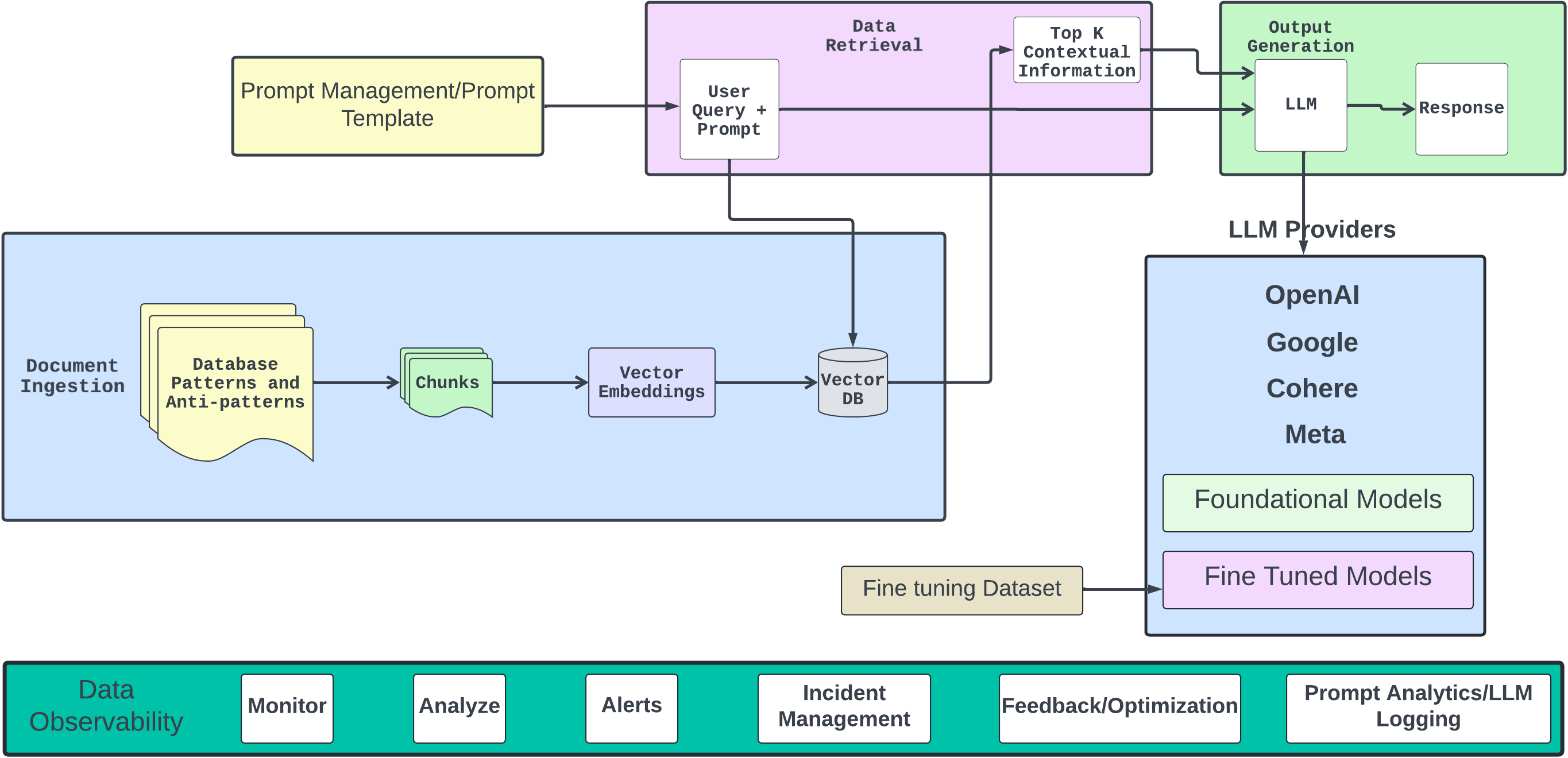
LLMOps for AI-Powered Database Development
Large language model operations (LLMOps) for AI-powered database development leverages foundational and fine-tuned models, effective prompt management, and model observability to optimize performance and ensure reliability. These practices enhance the accuracy and efficiency of AI applications, making them well suited for diverse, domain-specific, and robust database development and maintenance tasks.
Foundational Models and Fine-Tuned Models
Leveraging large, pre-trained GenAI models offers a solid base for developing specialized applications because of their training on diverse datasets. Domain adaptation involves additional training of these foundational models on domain-specific data, increasing their relevance and accuracy in fields such as finance and healthcare.
A small language model is designed for computational efficiency, featuring fewer parameters and a smaller architecture compared to large language models (LLMs). Small language models aim to balance performance with resource usage, making them ideal for applications with limited computational power or memory. Fine-tuning these smaller models on specific datasets enhances their performance for particular tasks while maintaining computational efficiency and keeping them up to date. Custom deployment of fine-tuned small language models ensures they operate effectively within existing infrastructure and meet specific business needs.
Prompt Management
Effective prompt management is crucial for optimizing the performance of LLMs. This includes using various prompt types like zero-shot, single-shot, few-shot, and many-shot and learning to customize responses based on the examples provided. Prompts should be clear, concise, relevant, and specific to enhance output quality.
Advanced techniques such as recursive prompts and explicit constraints help ensure consistency and accuracy. Methods like chain of thought (COT) prompts, sentiment directives, and directional stimulus prompting (DSP) guide the model toward more nuanced and context-aware responses.
Prompt templating standardizes the approach, ensuring reliable and coherent results across tasks. Template creation involves designing prompts tailored to different analytical tasks, while version control manages updates systematically using tools like Codeberg. Continuous testing and refining of prompt templates further improve the quality and relevance of generated outputs.
Model Observability
Model observability ensures models function optimally through real-time monitoring, anomaly detection, performance optimization, and proactive maintenance. By enhancing debugging, ensuring transparency, and enabling continuous improvement, model observability improves AI systems' reliability, efficiency, and accountability, reducing operational risks and increasing trust in AI-driven applications. It encompasses synchronous and asynchronous methods to ensure the models function as intended and deliver reliable outputs.
Generative AI-Enabled Synchronous Observability and AI-Enabled Asynchronous Data Observability
Using AI for synchronous and asynchronous data observability in database development and maintenance enhances real-time and historical monitoring capabilities. Synchronous observability provides real-time insights and alerts on database metrics, enabling immediate detection and response to anomalies. Asynchronous observability leverages AI to analyze historical data, identify long-term trends, and predict potential issues, thus facilitating proactive maintenance and deep diagnostics. Together, these approaches ensure robust performance, reliability, and efficiency in database operations.
Figure 3. LLMOps for model observability and database development
Conclusion
Integrating AI into database development and maintenance drives efficiency, accuracy, and scalability by automating tasks and enhancing productivity. In particular:
- Enterprise RAG, supported by vector databases and LLMOps, further optimizes database management through best practices.
- Data observability ensures comprehensive monitoring, enabling proactive and real-time responsiveness.
- Establishing a robust data foundation is crucial for real-time AI applications, ensuring systems meet real-time demands effectively.
- Integrating generative AI into data architectures and database selections, analytics layer building, data cataloging, data fabric, and data mesh development will increase automation and optimization, leading to more efficient and accurate data analytics.
The benefits of leveraging AI in database development and maintenance will allow organizations to continuously improve performance and their database's reliability, thus increasing value and stance in the industry.
Additional resources:
- Getting Started With Vector Databases by Miguel Garcia, DZone Refcard
- Getting Started With Large Language Models by Tuhin Chattopadhyay, DZone Refcard
This is an excerpt from DZone's 2024 Trend Report, Database Systems: Modernization for Data-Driven Architectures.
Read the Free Report
Opinions expressed by DZone contributors are their own.
Comments