How I Converted Regular RDBMS Into Vector Database To Store Embeddings
In this article, I'll walk you through how to convert a regular RDBMS into a fully featured Vector database to store Embeddings for developing GenerativeAI applications.
Join the DZone community and get the full member experience.
Join For FreeIn today's Generative AI world, Vector database has become one of the integral parts while designing LLM-based applications. Whether you are planning to build an application using OpenAI or Google's Generative AI or you are thinking to solve use cases like designing a recommendation engine or building a computer vision (CV) or Vector database, would be an important component to consider.
What Is Vector Database and Why Are They Different Than the Traditional Database?
In the machine learning world, Vector or Embeddings represent the numerical or mathematical representation of data, which can be text, images, or media contents (Audio or Video). LLM from OpenAI or others can transform the regular data into Vector Embeddings with high-level multi-dimensions and store them in the vector space. These numerical forms help determine the semantic meaning among data or identify patterns or clustering, or draw relationships. Regular columnar-based RDBMS or NoSQL databases are not equipped to store Vector Embeddings data with multi-dimensions and efficiently scaling if needed. This is where we need a Vector database, which is a special kind of database that is designed to handle and store this kind of Embeddings data and, at the same time, offers high performance and scalability.
During data retrieval or index search, the traditional database returns results that exactly match the query, whereas the Vector database uses algorithm such as Kth-Nearest Neighbor (K-NN) or Approximate Nearest Neighbor (A-NN) to find similar vectors in the same dimensions or having shortest distance by applying cosine algorithm and return results having similar results. This helps solve use cases such as finding similar images among sets of photos taken, building a recommendation engine based on certain usage, or identifying patterns among a pool of huge datasets.
As you can see Vector database comes with the capability to efficiently store and search vector data which is essential to design and build AI applications using the Large Language Models (LLM). We have many Vector database(s) in the form of On-Premise usages like Redis Enterprise or Milvus or SAAS offerings like Pinecone. In this article, we will explore the most popular RDBMS, Postgres, and how we can convert it into a full fledge Vector database capable of performing with other Enterprise grade popular Vector database(s).
How To Convert the Postgres Into a Vector Database?
Postgres is one of the popular RDBMS, which is open source but has a performance similar to many Enterprise grade RDBMS. It has been in the market for a long time, dominating with its performance, ease to use, and robustness.
The open-source community has built an extension called pgvector which, when installed and activated, can turn regular Postgres installation to have the compatibility to support Generative AI application development by storing and indexing Embeddings generated by any LLMs having any dimensions. The best part is not only the Embeddings data, but the regular data also can be stored and indexed in the same database. Pgvector uses the exact and approximate nearest neighbors algorithms while querying the data, so sometimes it outperforms other databases.
Below is the Docker compose file I used to spin off a Postgress docker version already packaged with pgvector extension built into it. In the Docker compose, I also added Pgadmin as the DB client so that you can access your database.
version: '3.8'
services:
db:
container_name: pgVectorDB
image: ankane/pgvector:latest
restart: always
environment:
POSTGRES_DB: dzone
POSTGRES_USER: pguser
POSTGRES_PASSWORD: secret_password
ports:
- "5432:5432"
volumes:
- postgres-data:/var/lib/postgresql/data
pgadmin:
container_name: pgadmin4_container
image: dpage/pgadmin4
restart: always
environment:
PGADMIN_DEFAULT_EMAIL: admin@admin.com
PGADMIN_DEFAULT_PASSWORD: root
ports:
- "5050:80"
volumes:
postgres-data: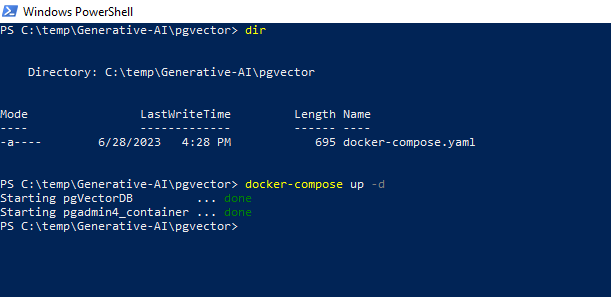
Fig 1: Docker compose command to run the Postgres with pgvector.
Fig 2: PGAdmin client (accessible through port 5050)
Once the Postgres running server is added, use the following SQL command to enable the vector extension:
CREATE EXTENSION IF NOT EXISTS vector;Conclusion
In this article, we explored how we can use the power of the open-source community to launch a scalable yet robust, high-performing vector database based on a traditional RDBMS system. If you are a data science engineer or software engineer or just designing or exploring solutions for your next AI-based project, then Postgres with pgvector would definitely help to solve some use cases such as similarity search, recommendation engine, and anomaly detection. We also demonstrated how Postgres with pgvector extension can seamlessly be installed and configured using simple tools like Docker compose and integrate with the existing microservice framework.
Opinions expressed by DZone contributors are their own.
Comments