A Deep-Learning Approach to Search for Similar Homes
In this article, take a look at an example of how to search for homes using deep learning and Milvus.
Join the DZone community and get the full member experience.
Join For FreeProject Background
Technological innovation is changing the way people conduct real estate transactions. Proptech has built up increasing momentum in the property sector in recent years and we are now seeing Artificial Intelligence play a key role in how people make their decisions to buy or sell.
Picking out those optimal houses that can be sold quickly out of the vast and bewildering number of properties on the market is a crucial and challenging task for housing platforms and their agents. So, how can unstructured data such as house plans and other general information be searched and filtered more efficiently? This is the key question which many tech companies are now trying to answer.
In this case study, we examine how Beike.com approaches housing searches and recommendations. Beike.com is a leading online real estate brokerage platform similar to Zillow or Realtor.com. Clearly, traditional databases have no means of processing unstructured data such as images, recorded speech, or natural language. However, with the introduction of Artificial Intelligence, there are no limits to what can be embedded in a database. By mapping unstructured data onto multidimensional vectors (i.e. embedding) the data is then easily available for analysis using vector search tools.
Import Milvus
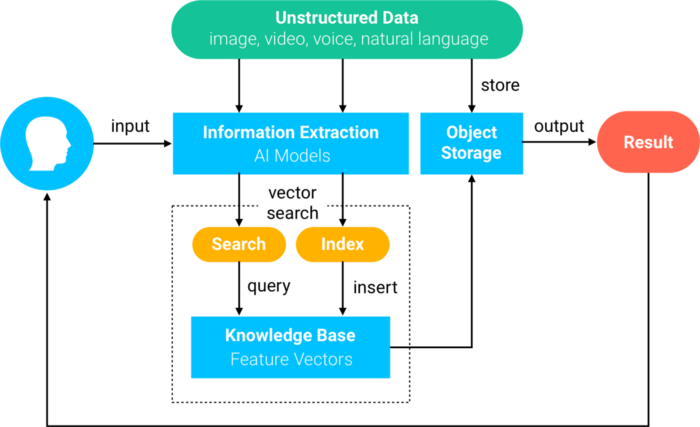
Milvus supports vectors converted by multiple AI models and provides corresponding search and analysis services. Its services include image processing, computer vision, natural language processing, speech recognition, recommendation systems, and new drug discovery amongst others. The general implementation process is as follows:
-
Deep learning models are used to convert unstructured data into feature vectors and import them into the Milvus library.
-
Milvus stores and indexes the feature vectors.
-
When it receives a vector query from the user, Milvus provides a result that matches the input vector.
Once a particular house has been selected, Milvus can then search for other potential homes with similar parameters. The diagram below shows the steps through which this search can carry out:
- Information about the original house is inputted into the system. This can include features such as floor plan, area, outline, and orientation. Then, a machine learning model is used to extract four collections of feature vectors from this information.
- These four collections are used to perform similarity searches in the Milvus library. The result for each collection of vectors indicates the level of similarity between the original house and matching houses according to corresponding features.
- The search results using the four collections of vectors are compared and the optimum recommended houses are outputted.
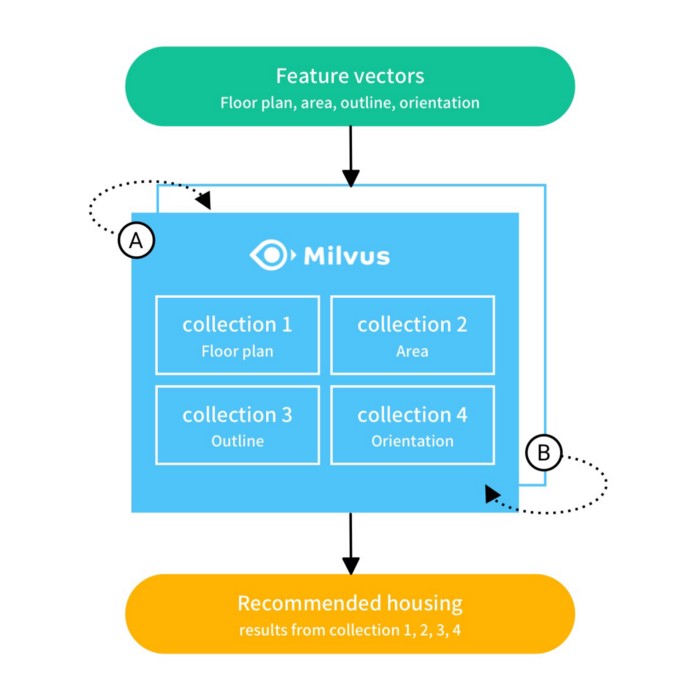
In the figure above, the system adopts A/B table switching to update data on T+1. In other words, Milvus stores the data of T days in Table A and imports updated data of previous T days in Table B on T+1. Because of this, the system is not affected when data is updated.
With the help of Milvus, Beike Vector Search Platform has been able to implement the high-performance analysis of a massive quantity of feature vectors, taking advantage of the advanced algorithms and high computing power that Milvus offers.
Milvus is capable of searching through 3 million units of data in a standalone environment with an average response time of only 113 ms. Milvus also supports distributed cluster solutions. Beike Vector Search Platform uses Kubernetes to deploy a distributed Milvus cluster, offering performance comparable to that of a standalone solution with the potential for horizontal scalability and extensive availability.
Introduction to the House Recommendation System
The house recommendation system employs a similarity-based strategy for producing recommendations. Once a user seems to show interest in a particular house they will then receive recommendations for similar houses. Essentially, recommendation algorithms have as their core the calculation of similarity, whether it is the similarity of users or of items. A brief introduction of the system's similarity recommendation algorithm follows:
- Fundamental Idea
The system identifies houses which are similar to those the user is interested in and then recommends those with the highest degree of similarity.
- Algorithms
Milvus supports a range of methods for calculating similarity, including Euclidean distance, cosine distance, and Tanimoto coefficient. In the process of recommending housing, we use cosine distance.
- Steps
- Collect user preferences
Convert information about the user's favorite houses into feature vectors for future processing.
- Search for similar houses
Calculate the cosine distance between the user's favorite houses and other properties. Recommend a sorted list of similar houses.
- Implementation
The house recommendation system follows the same principles as the previously mentioned house search system and likewise offers a high degree of speed and accuracy when retrieving lists of similarity results and recommending houses.
Conclusion
Beike search platform mainly deals with housing searches and recommendation services. Currently, Beike employs a file search platform based on ElasticSearch, a graph database based on Dgraph, and a vector search platform based on Milvus. Beike began to explore vector searches at the end of last year. In the field of AI, feature vectors are a common data format, and, when presented with a fast-growing unstructured mass of data, a feature vector similarity search engine becomes essential for processing and sorting. The future is going to see a skyrocketing demand for vector search capability with vector search engines becoming a massive growth area.
Lastly, don't forget to visit us at https://github.com/milvus-io/milvus. Any feedback or *star* is greatly appreciated!
Opinions expressed by DZone contributors are their own.
Comments