Graphs, Analytics, and Generative AI: The Year of the Graph Newsletter
Graphs, analytics, and Generative AI. An account of the different ways graphs and AI mingle, plus industry and research news.
Join the DZone community and get the full member experience.
Join For FreeIs a generative AI preamble necessary for a newsletter focused on Knowledge Graphs, Graph Databases, Graph Analytics, and Graph AI? Normally, it should not be. However, the influence of generative AI on the items included in this issue was overwhelming. There is a simple explanation for that.
It's been a year since Generative AI burst into the mainstream with the release of ChatGPT. Notwithstanding a rather spotty record both in terms of technical performance and accuracy as well as in terms of business reliability, there's no denying that Generative AI has captured the attention of executives worldwide.
Mentions of “generative AI” on earnings calls have skyrocketed since ChatGPT made its debut, rising from 28 in Q4’22 to 2,081 in Q3’23 — a 74x increase. With the majority of companies being at an early stage in their AI journey, executives feel the pressure to act amid the generative AI rush.
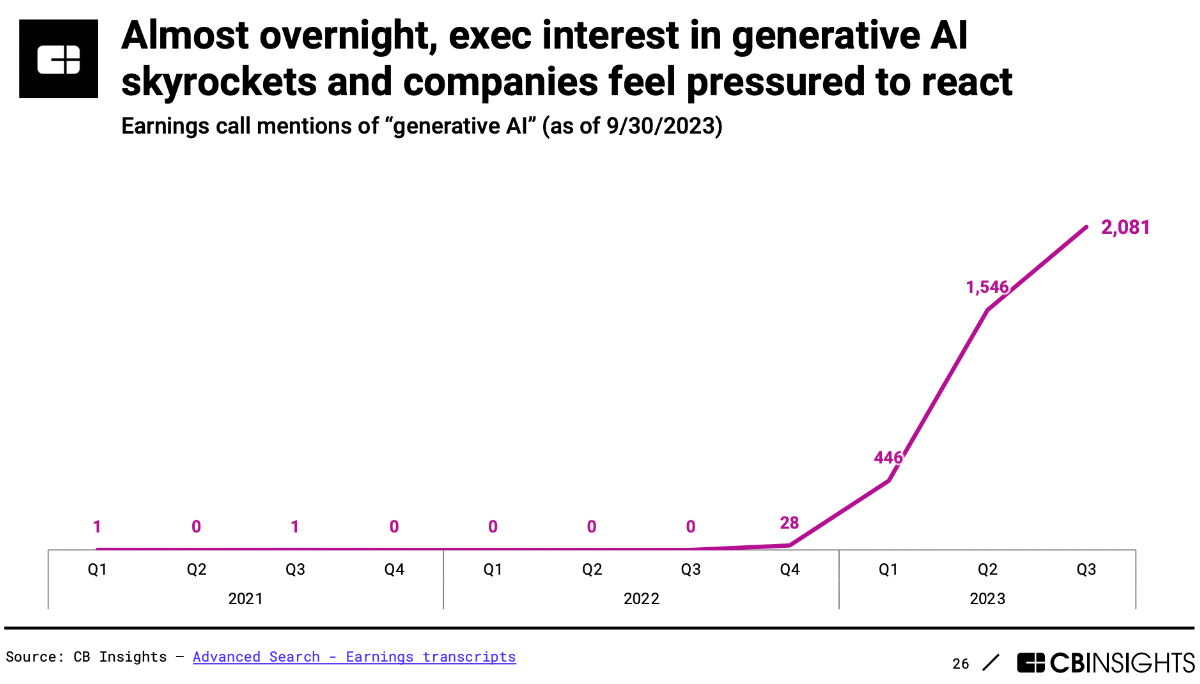
What this means is that generative AI has tremendous mindshare. Adoption is expected to grow 36% YoY 2030 according to Forrester, and more than 100M people in the US alone will use generative AI next year. Therefore, vendors are looking to position their products accordingly.
Played right, this can be more than a marketing scheme. There are ways in which graphs and generative AI can complement each other, leading to responsible enterprise decisions with knowledge-enriched Generative AI.
Vectors, Graphs, and RAG
RAG stands for Retrieval Augmented Generation. It's a technique through which Large Language Models like ChatGPT can be instructed to use specific background knowledge to contextualize their processing. This offers a conversational interface to proprietary data, making LLMs applicable to business scenarios that require this.
RAG is the main reason why the interest in vector databases has skyrocketed in the last year. Like all machine learning models, LLMs work with vectors. Therefore, having a vector database to store information and feed it to LLMs seems like a reasonable choice for RAG. However, it's not the only one. In fact, as people like Damien Benveniste argue, Graph Databases may be a better choice for RAG.
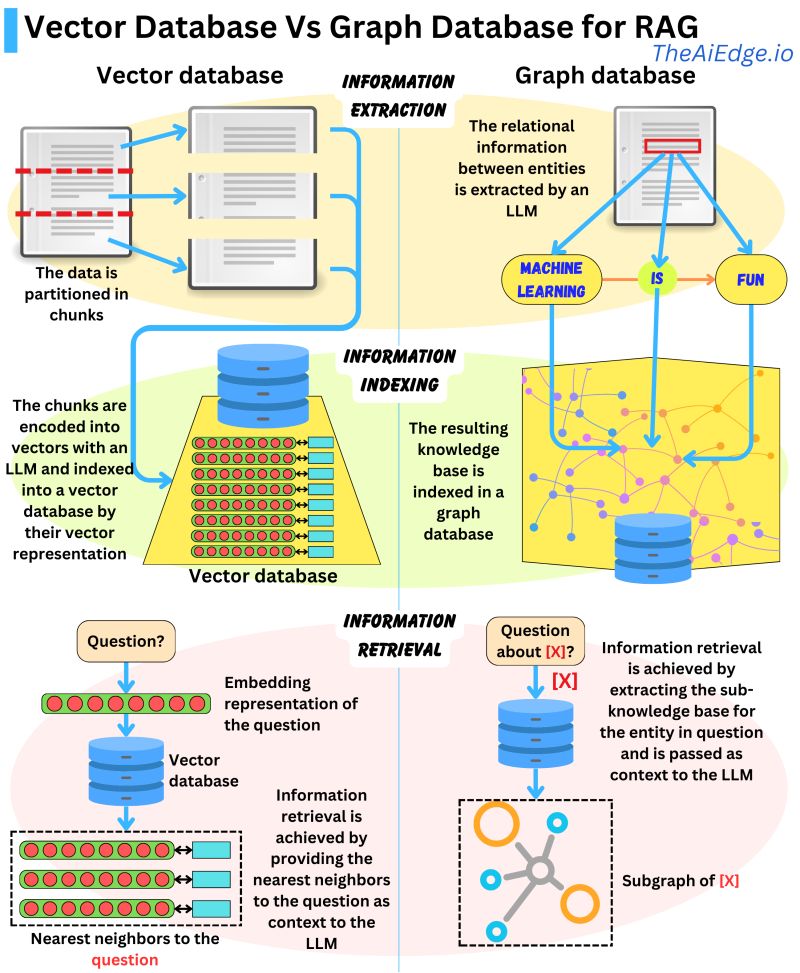
Using graphs, the relationships between the different entities in the text can be extracted and used to construct a knowledge base of the information contained within the text. An LLM is good at extracting that kind of triplet information: [ENTITY A] -> [RELATIONSHIP] -> [ENTITY B]
Once the information is parsed, it can be stored in a graph database. The information stored is the knowledge base, not the original text. For information retrieval, the LLM needs to come up with an Entity query related to the question to retrieve the related entities and relationships. The retrieved information is much more concise and to the point than in the case of vector databases.
Graph Databases Riding the RAG Wave
RAG is an alternative to fine-tuning LLMs, which seems less demanding and more immediately applicable. What's more, it can be offered by vendors whose core competency is data management.
Since they already have a footprint in organizations, data management vendors can do the heavy lifting of integrating with LLMs. It's a win-win: executives get to check their gen AI boxes, and vendors get to expand their offering, catching the buzz and keeping clients happy.
This is the reason why we're seeing graph database vendors adding vector capabilities to their products. Neo4j was the first one to include vector capabilities in its offering in August 2023. The idea is to combine the best of both worlds as part of the roadmap newly appointed Neo4j CPO Sudhir Hasbe announced in July 2023.
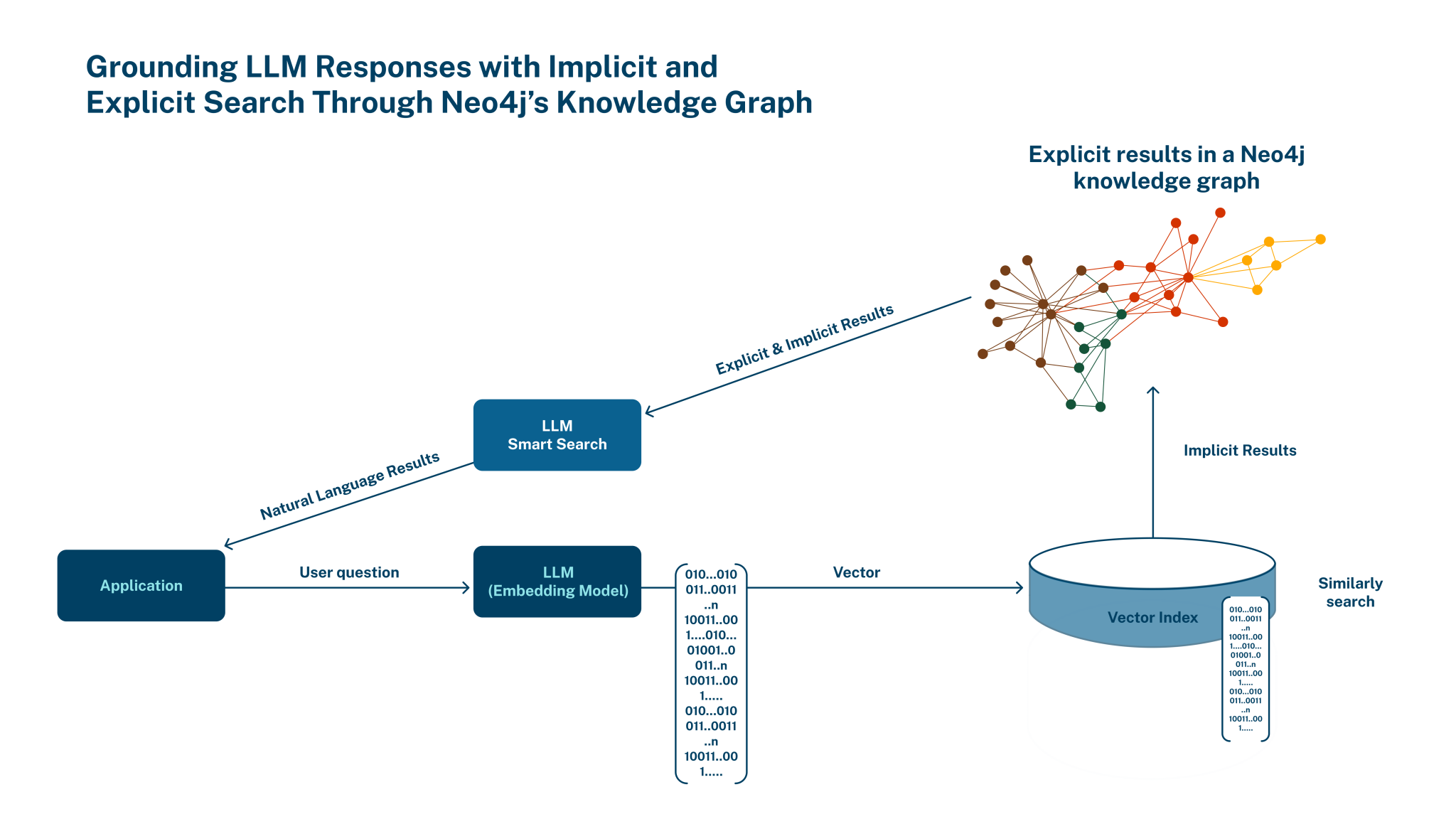
Graph Analytics Meets HPC
Neo4j and Amazon Neptune seem to have been on similar trajectories. Another thing that both vendors unveiled in the last few months is new analytics engines, leveraging parallelism to achieve speedup in processing in graph analytics scenarios previously underserved.
As Hasbe shared, for Neo4j's new analytics engine, typical examples are analytical queries that traverse most of the graph data. The parallel runtime is specifically designed to address these analytical queries.
The new Neptune Analytics engine is geared towards three use cases. First, ephemeral analytics. These are workflows where customers just need to spin up a graph really quickly, run some analysis, and turn it off.
Second, low-latency analytical queries. That involves established machine learning pipelines with feature tables to perform real-time predictions. The third use case is building GenAI applications. Being able to perform vector similarity search when storing embeddings on Neptune analytics means it’s much easier to translate natural language questions into graph queries.

To power their new analytics engines, both teams seem to have borrowed a page from high-performance computing (HPC). Neo4j's implementation was directly inspired by the research paper "Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age."
While we don't have specific pointers for Amazon Neptune's implementation, Amazon Neptune General Manager Brad Bebee acknowledged certain similarities. Both teams see a broad subset of graph customers and graph use cases.
Both teams have members who are familiar with the literature and techniques coming from (HPC) processing of large-scale graphs. Parallel processing and memory optimization techniques are things that are well-understood in the HPC community.
Graph Database Entries and Exits
Even though Neo4j and Amazon are well-established in the graph database space, there is lots of action in this space beyond these two. Most vendors are working on positioning themselves in the generative AI landscape and/or adding conversational interfaces to their products.
But that does not mean that generative AI is all there is out there — there are other use cases as well. Aerospike Graph is a new entry in the graph database market, aiming to tackle complex problems at scale.
Aerospike started out as a key-value store. Eventually, the initial offering expanded to include the document model (JSON) as well as a SQL interface via Starburst. The graph was the next step, with adoption being reportedly customer-driven.
A team was built for Aerospike Graph, including Apache TinkerPop founder Marko Rodriguez and key contributors to the project. They helped Aerospike create a graph layer that interfaces with the core engine in a way that scales out horizontally in a shared-nothing architecture.

Coincidentally, it was only a few days after Aerospike Graph’s official unveiling that another database vendor with a similar profile who had recently entered the graph database market announced its exit.
In 2019, Redis introduced its graph database, citing similar reasoning: they wanted to offer performance and scalability. In 2023, they wound down RedisGraph, saying:
“Many analyst reports predicted that graph databases would grow exponentially. However, based on our experience, companies often need help to develop software based on graph databases. It requires a lot of new technical skills, such as graph data modeling, query composition, and query optimization. As with any technology, graph databases have their limitations and disadvantages.
This learning curve is steep. Proof-of-concepts can take much longer than predicted, and the success rate can be low relative to other database models. For customers and their development teams, this often means frustration. For database vendors like Redis, this means that the total pre-sales (as well as post-sales) investment is very high relative to other database models”.
Scoping and Building Knowledge Graphs
Building knowledge graphs is supposedly a huge and terrifying project, as Mike Dillinger notes. But that perception is mostly coming from software engineers who think that a knowledge graph has to be enormous.
Tech organizations are overflowing with engineering managers who think (or expect) that engineers can do anything and everything. And there are precious few product managers who are familiar enough with knowledge graphs to frame knowledge graph building in terms that managers and engineers can grok and buy into.
The end result is that organizations don't implement crucial but unfamiliar tech, like knowledge graphs. Contrary to widespread assumptions, Dillinger adds, creating and curating knowledge graphs is not an inherently manual process, even if quality management requires expert review. He shares some of the latest research efforts for assisted knowledge graph creation.

The topic of assisted knowledge graph creation has received renewed attention in the last few months, again owing to the generative AI momentum. There are good reasons for this. LLMs can assist in converting any text into a graph of concepts, as Rahul Nayak goes to show.
One such effort that has drawn lots of attention is MechGPT, a language model specifically fine-tuned for constructing knowledge graphs. MechGPT first breaks down texts into small chunks. Each chunk is fed to a general-purpose LLM that generates question-answer pairs summarizing key concepts.
- Bonus track 1: Yejin Choi in conversation with Bill Gates, summarized by Jesús Barrasa. Α combination of LLMs (magic but opaque / subsymbolic) with knowledge graphs (explicit / symbolic) is the path forward.
- Bonus track 2: Prompting an LLM with an ontology to drive Knowledge Graph extraction from unstructured documents by Peter Lawrence.
Ontology Modeling for Knowledge Graphs With SHACL
What is an ontology? That may seem like a trivial question for people familiar with knowledge graphs, but as Kurt Cagle goes to show, it is not. Cagle defines an ontology as a set of schemas that collectively establish the shape of the data held within a named graph. Others may prefer different definitions.
Holger Knublauch writes that in the world of knowledge graphs, an ontology is a domain model defining classes and properties. Classes are the types of entities (instances) in the graph, and properties are the attributes and relationships between them. Ontologies define the structure of graphs and allow tools to make more sense of them.
Either way, there seems to be convergence around the notion of using SHACL, the SHApes Constraint Language, for Ontology Modeling. Prior to the introduction of SHACL, knowledge graph validation would mostly be manual or reliant on OWL (Web Ontology Language) constraints. OWL constraints, however, are counter-intuitive.

Knublauch followed up on his SHACL tutorial with Part 2 on Qualified Cardinality Constraints. and Part 3 on SPARQL-based Constraints. Radostin Nanov has also written a SHACL guide in 3 parts: Learning how SHACL can tame unruly data graphs, applying SHACL to data and handling the output, and the internals of a SHACL engine. And Ivo Velitchkov with Veronika Heimsbakk maintain a Wiki on SHACL.
- Bonus track 1:A Landscape of Ontologies Standards Landscape. This report presents a curated collection of ontologies that are highly relevant to ICT domains and vertical sectors, considering their maturity, prominence, and suitability for representing linked data in the semantic web. Ontologies can contribute to Explainable AI, too.
- Bonus tracks 2 and 3: SPARQLing anything and a SPARQL Wiki.
Applied Graph AI Use Cases From DeepMind
DeepMind has been one of the forerunners of Graph AI. In the last few months, DeepMind has shared more details about their use of Graph AI in a couple of high-impact use cases.
In a paper published in Science, DeepMind introduces GraphCast, a state-of-the-art AI model able to make medium-range weather forecasts with unprecedented accuracy. GraphCast predicts weather conditions up to 10 days in advance more accurately and much faster than the industry gold-standard weather simulation system.
GraphCast is a weather forecasting system based on machine learning and Graph Neural Networks (GNNs), which are a particularly useful architecture for processing spatially structured data. DeepMind has open-sourced the model code for GraphCast, enabling scientists and forecasters around the world to benefit billions of people in their everyday lives.
DeepMind GNoME is a GNN-based system that discovered 2.2M new crystal structures including about 380k stable structures. Novel functional materials enable fundamental breakthroughs across technological applications from clean energy to information processing. Graph neural networks trained at scale can reach unprecedented levels of generalization, improving the efficiency of materials discovery by an order of magnitude.
- Bonus track: Combinatorial optimization and reasoning with Graph Neural Networks. A conceptual review of recent key advancements in this emerging field, aiming at optimization and machine learning researchers by DeepMind's Petar Veličković et.al.
Graph Levels of Detail
Graph-based data is ubiquitous in enterprise, across the industry verticals, and increasingly needed for machine learning use cases. Graph technologies are available, though not quite as widely used yet in comparison with relational databases. Even so, interest in knowledge graph practices has grown recently due to AI applications, given the benefits of leveraging graphs and language models together.
A frequent concern is that graph data gets represented at a low level, which tends to make queries more complicated and expensive. There are few mechanisms available — aside from visualizations — for understanding knowledge graphs at different levels of detail. That is to say, how can we work with graph data in more abstract, aggregate perspectives?
 >
>
While we can run queries on graph data to compute aggregate measures, we don’t have programmatic means of “zooming out” to consider a large graph the way that one zooms out when using an online map. This leaves enterprise applications, which by definition must contend with the inherently multiscale nature of large-scale systems, at a distinct disadvantage for leveraging AI applications.
Paco Nathan presents a survey of related methods to date for level-of-detail abstractions in graphs, along with indications for future work.
Graph and Large Language Models Research
Wrapping up with a collection of research on various aspects of combining graphs with large language models. Paco Nathan also lists a collection of research efforts to combine Graph ML with Language Models here.
IEEE researchers present a roadmap for unifying large language models and knowledge graphs. Their roadmap consists of three general frameworks. KG-enhanced LLMs, LLM-augmented KGs, and synergized LLMs + KGs. Cf. the previous YotG issue here.
Similarly, researchers from The Hong Kong University of Science and Technology (Guangzhou), The Chinese University of Hong Kong and Tsinghua University present a survey of graph meets large language model. They propose a taxonomy, which organizes existing methods into three categories based on the role (i.e., enhancer, predictor, and alignment component) played by LLMs in graph-related tasks.
Researchers from ETH Zurich, Cledar, and the Warsaw University of Technology introduce Graph of Thoughts (GoT): a framework that advances prompting capabilities in large language models (LLMs) beyond those offered by paradigms such as Chain-of Thought or Tree of Thoughts (ToT). Tony Seale summarizes the approach.
Michael Galkin et.al. present ULTRA, a single pre-trained reasoning model for Knowledge Graph reasoning. ULTRA can generalize to new KGs of arbitrary entity and relation vocabularies, which serves as a default solution for any KG reasoning problem. Researchers from Monash and Griffith present Reasoning on Graphs (RoG), a method that synergizes LLMs with KGs to enable faithful and interpretable reasoning.
A growing number of experts from across the industry, including academia, database companies, and industry analyst firms, like Gartner, point to Knowledge Graphs as a means for improving LLM response accuracy. To evaluate this claim, data.world researchers came up with a new benchmark that examines the positive effects that a Knowledge Graph can have on LLM response accuracy in the enterprise.

The benchmark compared LLM-generated answers to answers backed by a Knowledge Graph via data stored in a SQL database. Findings point towards a significant improvement in the accuracy of responses when backed by a Knowledge Graph, in every tested category.
A*Net is a scalable, inductive, and interpretable path-based Graph Neural Network on Knowledge Graphs. It can be used to make ChatGPT more factual by equipping it with knowledge graph reasoning tools. It's open source and integrated with ChatGPT.
Google Research presents Talk Like a Graph: Encoding Graphs for Large Language Models. A comprehensive study of encoding graph-structured data as text for consumption by LLMs.
Jure Leskovac et.al. introduce an end-to-end deep learning approach to directly learn on data spread across multiple tables called Relational Deep Learning. The core idea is to view relational tables as a heterogeneous graph, with a node for each row in each table and edges specified by primary-foreign key relations.
Published at DZone with permission of George Anadiotis. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments