Getting Started With Jenkins
In this step-by-step guide to getting off the ground with Jenkins, learn fundamentals that underpin CI/CD, how to create a pipeline, and when and where to use Jenkins.
Join the DZone community and get the full member experience.
Join For FreeJenkins has been a staple in software automation for over a decade due largely to its feature-rich tooling and adaptability. While many impressive alternatives have entered the space, Jenkins remains one of the vanguards. Despite its success, Jenkins can have a significant learning curve, and jumping into the vast world of Jenkins plugins and features can quickly become overwhelming.
In this article, we will break down that complexity by first understanding the fundamentals and concepts that underpin Jenkins. With that foundation, we will learn how to create a simple pipeline in Jenkins to build and test an application. Lastly, we will look at how to advance this simple example into a more complex project and explore some alternatives to Jenkins.
What Is Jenkins? Fundamentals and Concepts
Jenkins is a software automation service that helps us script tasks like builds. Of particular interest is Jenkins's ability to create a pipeline, or a discrete set of ordered tasks. Before we create a pipeline in Jenkins, we must first understand what a pipeline is and why it is useful. This understanding starts with a journey through the history of software development.
Big Bang Integration
Before automation, we were forced to manually build and test our applications locally. Once our local tests passed, we would commit our changes to a remote repository to integrate them with the changes made by other developers.
At a predetermined point — usually, as a release approached — the Quality Assurance (QA) team would take the code in our remote repository and test it. While our local tests may have passed before we committed them, and the local tests of other developers worked before they committed them, there was no guarantee that our combined changes would work. We would instead have to wait until QA tested everything together. This moment of truth was usually called the Big Bang. In the (likely) event that the tests failed, we would then have to hunt through all of the commits to see which one (or ones) was the culprit.
Continuous Integration
The process of running our tests and verifying our code after each commit is called Continuous Integration (CI). As the name implies, CI differs from Big Bang integration by continuously integrating code and verifying that it works.
The Big Bang integration approach may work for small projects or prototypes, but it is a massive hindrance for medium- or large-scale projects. Ideally, we want to know if our tests pass when we merge our code with the remote repository. This requires two main changes to our process:
- Automating tests
- Executing automated tests after each check-in
While automated tests could be created for a Big Bang project, they are not required. They are, however, required for our new process to work. It would be prohibitive to manually test the tests for any project with multiple commits per day. Instead, we need a test suite that can be run automatically, wherever and whenever necessary.
The second requirement is that our automated tests are run each time a commit is made to the remote repository. This requires that some service (external or co-located with our repository) check out the repository after each commit, run our tests, and report if the tests passed or failed. This process could be run periodically, but ideally, it should be run every time a commit is made so that we can trace exactly which commit caused our test suite to fail.
With CI, instead of waiting until some point in the future to see if our code works, we know at any given time whether our code works; what's more, we also know exactly when and where a failure originates when it stops working. CI is a massive leap forward in software automation. There are very few projects today that do not use some level of CI to ensure that each commit does not "break the build." While this is a great improvement, it is only a half-step relative to the process that our code traverses from commit to delivery.
Continuous Delivery
When we looked at our manual build process, we rightly saw an opportunity to automate the build and test stages of our process; but this is only a small part of the overall process. For most software, we do not just build and unit test; we also run higher-level tests (such as integration and system tests), deliver our final product to our customers, and a wide array of steps in between.
If we are following the mindset of CI, it begs the question:
Why not automate the entire business process, from build to delivery, and run each step in the process sequentially until our product is automatically delivered to the customer?
This revolutionary approach is called Continuous Delivery (CD). Like CI, CD continuously integrates our code as we make commits, but unlike CI, CD does not stop after unit tests are complete. Instead, CD challenges us to automate every step in our business process until the final product is automatically delivered to the customer.
This sequence of automated steps is called a pipeline. A pipeline consists of stages, which are groups of steps executed in parallel. For one stage to start, all the steps of the previous stage must complete successfully.
An example of a common CI/CD pipeline is illustrated below:

While the particular stages and steps of a CI/CD pipeline may vary, they all share a common definition: they are simple abstractions of the business process that a software product must complete before it is delivered to the customer. Even without CI/CD, every software delivery includes a delivery process; we execute the process manually. CI/CD does not introduce anything new to the process: it simply automates each stage so that the pipeline can be executed automatically. Learn more about CI/CD Software Design Patterns.
CI/CD is a very involved topic, and it can be overwhelming at first glance, but it can be summed up with a few main concepts:
- A pipeline is an abstraction of the business process we use to deliver a product.
- A pipeline is composed of an ordered set of stages.
- A stage is composed of a set of steps that are run in parallel.
- A stage cannot start executing until all of the steps in a previous stage have completed.
- A trigger is the first event in a pipeline that initiates the first stage in a pipeline (i.e., a commit to a repository).
- A pipeline is executed after every commit to a repository.
- The deliverable from a pipeline is not delivered to a customer unless all of the stages pass.
This last point is where CI/CD shines: We know that any artifact delivered to a customer is the last working artifact that successfully passes through the pipeline. Likewise, we know that any time a commit results in a passing artifact, it is automatically delivered to the customer (the customer does not have to wait for us to deliver it or wait for multiple commits to receive the latest delivery).
For more information on pipelines and CI/CD in general, see the following articles:
- "How To Build an Effective CI/CD Pipeline"
- "Continuous Test Automation Using CI/CD: How CI/CD Has Revolutionized Automated Testing"
CI/CD and Jenkins
At this point, we have a foundational understanding of what CI/CD is and why it is important. In our discussion of CI/CD, we left out one important point: what actually executes the pipeline? Whatever this remaining piece is, it must be capable of doing the following:
- Scan a remote repository for commits
- Clone the latest code from a repository
- Define a pipeline and its constituent stages using scripts and other automated mechanism
- Run the automated steps in the pipeline
- Report the status of a pipeline execution (e.g., pass or fail)
- Deliver the final artifacts to some internal or external location
This is where Jenkins comes in. Jenkins is an automation server that can be used to perform all of the steps above. While Jenkins is a very powerful automation service that can do more than just CI/CD (Jenkins can conceivably automate just about any process), it has the tools necessary to create a functional CI/CD pipeline and execute it after a commit to our repository.
Jenkins has a long history — and capturing all its ins and outs would consume volumes — but at its core, Jenkins is a powerful CI/CD tool used by many of the largest software companies. Its rich set of features and plugins, along with its time-tested reliability, has cemented it as a staple in the software automation community.
For more general information on Jenkins, see the official Jenkins documentation.
Jenkins Builds: Setting up a Pipeline
Our main goal in this tutorial is to set up a simple pipeline using Jenkins. While most Jenkins pipelines (or any pipeline in general) will include numerous, possibly complex stages, we will start by creating a minimally viable pipeline with a single stage. We will then split our single-stage pipeline into a two-stage pipeline. From there, we will examine how to use this simple pipeline as a starting point for a production-ready pipeline.
Setting up Jenkins
To set up Jenkins, we will need to complete three steps:
- Install Docker
- Build and run the Jenkins Docker container
- Configure Jenkins
Installing Docker
Before we install Docker, we need to create a DockerHub account. DockerHub is the Docker equivalent of GitHub and acts as a registry of preconfigured container images, such as Ubuntu, MongoDB, and Jenkins. We will use these preconfigured containers as a starting point for installing Jenkins, as well as a starting point for the projects that we build in Jenkins.
To create a DockerHub account:
- Navigate to the DockerHub Sign-Up page.
- Enter your email and desired username and password, or link to a Google or GitHub account.
- Submit your account information.
- Verify your account using the email sent to the email address entered above.
- Login to your new DockerHub account.
For our first Jenkins project, the default, Personal account will suffice since it allows us to download 200 containers every 6 hours (at the time of writing). If we were creating a Jenkins pipeline for a business product or a team project, we should look for an upgraded account, such as Pro or Business. For more information, see the Docker Pricing page. Review related documentation on how to health check your Docker Containers.
Once we have created a DockerHub account, we can install the Docker Desktop application. Docker Desktop is a visual application that allows us to buiu Docker images and start them as containers. Docker Desktop is supported on Windows, Mac, and Linux. For more information on how to install Docker Desktop on each of these platforms, see the following Docker pages:
Once Docker Desktop is installed, we need to log in to our DockerHub account to link it to our Docker Desktop installation:
- Open Docker Desktop.
- Click the Login link.
- Log in to DockerHub in the opened browser tab.
- Return to Docker Desktop after logging in.
- Accept the license agreement.
Once our account is linked, we are ready to pull the Docker Jenkins image and start the container.
Running the Jenkins Docker Container
With Docker now set up, we can create a new Jenkins image that includes all the necessary packages and run the image as a container. For this section, we will use the Windows setup process as an example. The setup process for macOS and Linux is similar but slightly different. For more information on setting up the Jenkins container on macOS or Linux, see Installing Jenkins with Docker on macOS and Linux.
First, we need to create a bridge network for Jenkins using the following command:
docker network create jenkinsNext, we need to run a docker:dinb image:
docker run --name jenkins-docker --rm --detach ^
--privileged --network jenkins --network-alias docker ^
--env DOCKER_TLS_CERTDIR=/certs ^
--volume jenkins-docker-certs:/certs/client ^
--volume jenkins-data:/var/jenkins_home ^
--publish 2376:2376 ^
docker:dindThe docker:dind (dind stands for Docker-in-Docker) is an image provided by Docker that allows us to run Docker inside a Docker container. We will need Docker to be installed inside our container to run our pipeline since Jenkins will start a new Docker container within the Jenkins container to execute the steps of our pipeline.
Next, we must create a Docker image based on the Jenkins image. This custom image includes all the features, such as the Docker CLI, that Jenkins needs to execute our pipeline. To create this image, we can save the following Dockerfile in the current directory:
FROM jenkins/jenkins:2.414.3-jdk17
USER root
RUN apt-get update && apt-get install -y lsb-release
RUN curl -fsSLo /usr/share/keyrings/docker-archive-keyring.asc \
https://download.docker.com/linux/debian/gpg
RUN echo "deb [arch=$(dpkg --print-architecture) \
signed-by=/usr/share/keyrings/docker-archive-keyring.asc] \
https://download.docker.com/linux/debian \
$(lsb_release -cs) stable" > /etc/apt/sources.list.d/docker.list
RUN apt-get update && apt-get install -y docker-ce-cli
USER jenkins
RUN jenkins-plugin-cli --plugins "blueocean docker-workflow"Once the Dockerfile has been saved, we can create a new image from it:
docker build -t myjenkins-blueocean:2.414.3-1 .This command names the new image myjenkins-blueocean (with a version of 2.414.3-1) and assumes the Dockerfile is in the current directory. Note that we can use any valid Docker image name that we wish. At the time of writing, a valid image name abides by the following criteria:
The [name] must be valid ASCII and can contain lowercase and uppercase letters, digits, underscores, periods, and hyphens. It cannot start with a period or hyphen and must be no longer than 128 characters.
Lastly, we can start our container using the following command:
docker run --name jenkins-blueocean --restart=on-failure --detach ^
--network jenkins --env DOCKER_HOST=tcp://docker:2376 ^
--env DOCKER_CERT_PATH=/certs/client --env DOCKER_TLS_VERIFY=1 ^
--volume jenkins-data:/var/jenkins_home ^
--volume jenkins-docker-certs:/certs/client:ro ^
--publish 8080:8080 --publish 50000:50000 myjenkins-blueocean:2.414.3-1We can confirm that our Jenkins container (named myjenkins-blueocean) is running by completing the following steps:
- Open Docker Desktop.
- Click the Containers tab on the left panel.
- Ensure that the
myjenkins-blueoceancontainer is running.
The running container will resemble the following in the Docker Desktop GUI:

At this point, our Jenkins container is ready. Again, the process for creating the Jenkins container for Mac and Linux is similar to that of Windows. For more information, see the following pages:
- Installing Jenkins with Docker on Windows
- Installing Jenkins with Docker on macOS and Linux (linked previously in this article)
Configuring Jenkins
Once the Jenkins container is running, we can access the Jenkins User Interface (UI) through our browser at http://localhost:8080. The Jenkins welcome screen will give us a prompt requesting the Administrator password. We can find this password and complete the Jenkins installation using the following steps:
- Open Docker Desktop.
- Click the Containers tab on the left panel.
- Click our running Jenkins container (
myjenkins-blueocean). - Click the Logs tab (this tab should open by default)
- Find the lines in the log that resemble the following:
In this example, the administrative password isPlain Text
2023-10-31 11:25:45 ************************************************************* 2023-10-31 11:25:45 ************************************************************* 2023-10-31 11:25:45 ************************************************************* 2023-10-31 11:25:45 2023-10-31 11:25:45 Jenkins initial setup is required. An admin user has been created and a password generated. 2023-10-31 11:25:45 Please use the following password to proceed to installation: 2023-10-31 11:25:45 2023-10-31 11:25:45 080be1abb4e04be59a0428a85c02c6e9 2023-10-31 11:25:45 2023-10-31 11:25:45 This may also be found at: /var/jenkins_home/secrets/initialAdminPassword 2023-10-31 11:25:45 2023-10-31 11:25:45 ************************************************************* 2023-10-31 11:25:45 ************************************************************* 2023-10-31 11:25:45 *************************************************************080be1abb4e04be59a0428a85c02c6e9. - Input this password into the Jenkins welcome page (located at http://localhost:8080).
- Click the Continue button.
- Click the Install Suggested Plugins button on the Customize Jenkins page.
- Wait for the Jenkins setup to complete.
- Enter a desired username, password, email, and full name.
- Click the Save and Continue button.
- Enter
http://localhost:8080/(the default value) on the Instance Configuration page. - Click the Save and Finish button.
- Click the Start using Jenkins button.
At this point, Jenkins is running and configured, and we are now ready to create our Jenkins pipeline. Note that we performed a very basic installation, and the installation we perform for a business project or a larger team will vary. For example, we may need additional plugins to allow our team to log in, or we may have additional security concerns — such as not running Jenkins on HTTP or on localhost:8080. For more information on how to set up a Jenkins container, see the Jenkins Docker Installation page.
Creating a Pipeline
Our next step is to create a pipeline to execute our build. Pipelines can be complex, depending on the business process being automated, but it's a good idea to start small and grow. In keeping with this philosophy, we will start with a simple pipeline: A single stage with a single step that runs mvn clean package to create an artifact. From there, we will divide the pipeline into two stages: a build stage and a test stage.
To accomplish this, we will:
- Install the Docker Pipeline plugin if it is not already installed.
- Add a Jenkinsfile to our project.
- Create a pipeline in Jenkins that uses our project.
- Configure our pipeline to build automatically when our project repository changes.
- Separate our single-stage pipeline into a build and test stage.
Installing the Pipeline Plugin
Sometimes, the Docker Pipeline plugin (which is needed to create our pipeline) may not be installed by default. To check if the plugin is installed, we must complete the following steps:
- Click Manage Jenkins in the left panel.
- Click the Plugins button under System Configuration.
- Click Installed plugins in the left panel.
- Search for
docker pipelinein the search installed plugins search field. - Ensure that the Docker Pipeline plugin is enabled.
If the Docker Pipeline plugin is installed, we can skip the installation process. If the plugin is not installed, we can install it using the following steps:
- Click Manage Jenkins in the left panel.
- Click the Plugins button under System Configuration.
- Click Available plugins in the left panel.
- Search for
docker pipelinein the search available plugins search field. - Check the checkbox for the Docker Pipeline plugin.
- Click the Install button on the top right.
- Wait for the download and installation to complete.
With the plugin installed, we can now start working on our pipeline.
Related Guide: How to Replace CURL in Scripts with the Jenkins HTTP Request Plugin.
Adding a Simple Jenkinsfile
Before we create our pipeline, we first need to add a Jenkinsfile to our project. A Jenkinsfile is a configuration file that resides at the top level of our repository and configures the pipeline that Jenkins will run when our project is checked out. A Jenkinsfile is similar to a Dockerfile but deals with pipeline configurations rather than Docker image configurations.
Note that this section will use the jenkins-example-project as a reference project. This repository is publicly available, so we can use and build it from any Jenkins deployment, even if Jenkins is deployed on our machine.
We will start with a simple Jenkinsfile (located in the root directory of the project we will build) that creates a pipeline with a single step (Build):
pipeline {
agent {
docker {
image 'maven:3.9.5-eclipse-temurin-17-alpine'
args '-v /root/.m2:/root/.m2'
}
}
stages {
stage('Build') {
steps {
sh 'mvn clean package'
}
}
}
}The agent section of a Jenkins file configures where the pipeline will execute. In this case, our pipeline will execute on a Docker container run from the maven:3.9.5-eclipse-temurin-17-alpine Docker image. The -v /root/.m2:/root/.m2 argument creates a two-way mapping between the /root/.m2 directory within the Docker container and the /root/.m2 directory within our Docker host. According to the Jenkins documentation:
This
argsparameter creates a reciprocal mapping between the/root/.m2directories in the short-lived Maven Docker container and that of your Docker host’s filesystem....You do this mainly to ensure that the artifacts for building your Java application, which Maven downloads while your Pipeline is being executed, are retained in the Maven repository after the Maven container is gone. This prevents Maven from downloading the same artifacts during successive Pipeline runs.
Lastly, we create our stages under the stages section and define our single stage: Build. This stage has a single step that runs the shell command mvn clean package. More information on the full suite of Jenkinsfile syntax can be found on the Pipeline Syntax page and more information on the mvn clean package command can be found in the Maven in 5 Minutes tutorial.
Creating the Pipeline
With our Jenkinsfile in place, we can now create a pipeline that will use this Jenkinsfile to execute a build. To set up the pipeline, we must complete the following steps:
- Navigate to the Jenkins Dashboard page (http://localhost:8080/).
- Click + New Item in the left panel.
- Enter a name for the pipeline (such as
Example-Pipeline). - Click Multibranch Pipeline.
- Click the OK button.
- Click Add Source under the Branch Sources section.
- Select GitHub.
- Enter the URL of the repository to build in the Repository HTTPS URL field (for example,
https://github.com/albanoj2/jenkins-example-project) - Click the Validate button.
- Ensure that the message
Credentials ok. Connected to [project-url]is displayed. - Click the Save button.
Saving the pipeline configuration will kick off the first execution of the pipeline. To view our latest execution, we need to navigate to the Example-Pipeline dashboard by clicking on the Example-Pipeline link in the pipeline table on the main Jenkins page (http://localhost:8080):
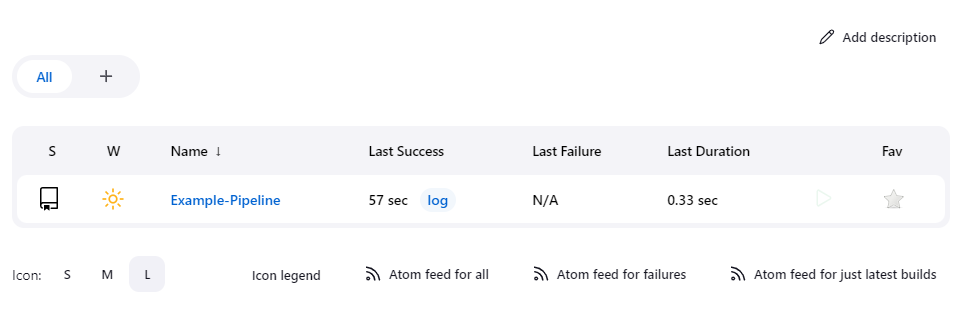
Jenkins structures its dashboard in a hierarchy that resembles the following:
Main Dashboard → Pipeline → Branch
In this case, Example-Pipeline is the page that displays information about our newly created pipeline. Within this page is a branch table with a row for each branch we track from our repository. In our case, we are only tracking the master branch, but if we tracked other branches, we would see more than one row for each of our branches:
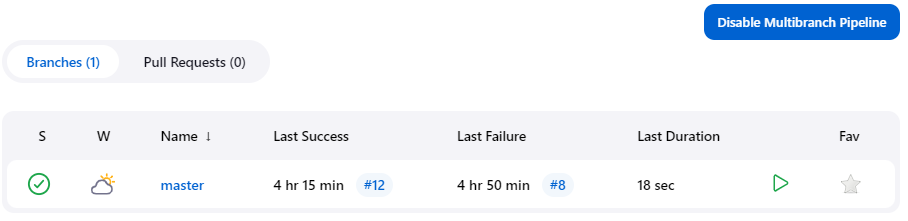
Each tracked branch is run according to the Jenkinsfile for that branch. Conceivably, the pipeline for one branch may differ from the pipeline for another (since their Jenkinsfiles may differ), so we should not assume that the execution of each pipeline under the Example-Pipeline pipeline will be the same.
We can also track Pull Requests (PR) in our repository similarly to branches: For each PR we track, a new row will be added to the PR table (accessed by clicking the Pull Requests link next to the Branches link above the table), which allows us to see the pipeline executions for each PR. For more information on tracking branches and PRs, see the Jenkins Pipeline Branches and Pull Requests page.
If we click on the master branch, the master branch page shows us that both stages of our pipeline (and, therefore, the entire pipeline) were completed successfully.
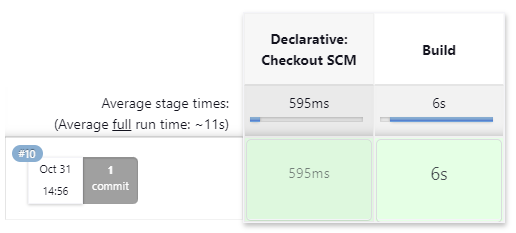
While we only definite a single stage (Build) in our pipeline, Jenkins will implicitly add a stage (Checkout SCM, or Software Configuration Management), which checks out our repository. Once the repository is checked out, Jenkins runs our pipeline stages against the local clone.
Running the Pipeline Automatically
By default, our pipeline will only be executed manually. To automatically execute the pipeline, we have two options:
- Scan the repository periodically
- Create a webhook
To scan the repository periodically, we can change the pipeline configuration:
- Navigate to the Jenkin Dashboard.
- Click the Example-Pipeline pipeline.
- Click the Configuration tab in the left panel.
- Check the
- Set the Interval to the desired amount.
- Click the Save button.
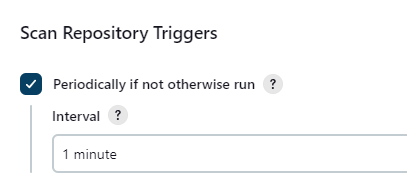
This will poll the repository periodically and execute the pipeline if a change is detected (if an execution was not otherwise started manually). Creating a webhook is more synchronized and does not require polling, but it does require a bit more configuration. For more information about how to set up a webhook for Jenkins and a GitHub repository, see how to add a GitHub webbook in your Jenkins pipeline.
Running Tests Separately
While a single-stage pipeline is a good starting point, it is unrealistic in production environments. To demonstrate a multi-stage pipeline, we will split our existing build stage into two stages: a build and a test stage. In our existing build stage, we built and tested our project using the mvn clean package command. With our two-stage pipeline, we will skip our tests in the build stage using the -DskipTests=true Maven flag and add a second stage that runs only our tests using the mvn test command.
Implementing this in our project results in the following Jenkinsfile:
pipeline {
agent {
docker {
image 'maven:3.9.5-eclipse-temurin-17-alpine'
args '-v /root/.m2:/root/.m2'
}
}
stages {
stage('Build') {
steps {
sh 'mvn clean package -DskipTests=true'
}
}
stage('Test') {
steps {
sh 'mvn test'
}
post {
always {
junit 'target/surefire-reports/*.xml'
}
}
}
}
}All but one of the changes to our Jenkinsfile is known: in addition to running mvn test, we also create a postprocessing step using the post section. In this section, we define a postprocessing step that is always run and tells the Jenkins JUnit Plugin where to look for our JUnit test artifacts. The JUnit Plugin is installed by default and gives us a visualization of the number of passed and failed tests over time. Related Tutorial: Publish Maven Artifacts to Nexus OSS Using Pipelines or Maven Jobs
When our next build runs (which should be picked up automatically due to our SCM trigger change), we see that a new stage, Test, has been added to our Example-Pipeline master page. Note that since our previous build did not include this stage, it is grayed out.

Looking at the top right of the same page, we see a graph of our tests over time. 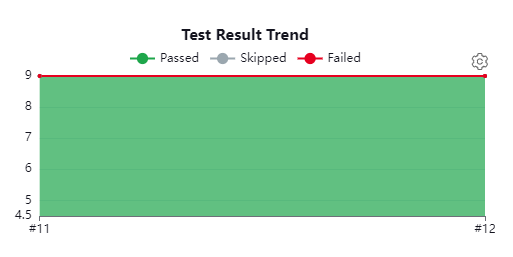
In our example project, there are nine tests, so our graph stays uniform at nine tests. If we only have one pipeline execution incorporating the JUnit Plugin, then we may not see this graph filled like above. As we run more executions, we will see the graph start to fill over time.
Jenkins Features: Extending the Jenkins Pipeline
The example pipeline we have created is a good starting point, but it is not realistic for medium- and large-scale applications, and it only scratches the surface of what Jenkins pipelines are capable of. As we start to build more sophisticated pipelines, we will begin to require more sophisticated features, such as:
- Deploying artifacts to artifact repositories
- Deploying Docker images to a container image repository
- Connecting to external services using credentials and authentication
- Using more advanced UIs, such as Blue Ocean
- Building and testing applications on different environments and operating systems
- Building and testing applications in parallel across multiple worker nodes
- Standing up complex test and deployment environments in Kubernetes
- Restricting access to designated administrators
The list of possibilities is nearly endless, but it suffices to say that realistic projects will need to build off the simple project we have created here and add more rich features and more complex tooling to accomplish their goals. The following resources are great places to start:
- Jenkins User Guide
- Jenkins: Build a Java app with Maven
- Jenkins: Blue Ocean
- Jenkins: Scaling Pipelines
- Jenkins: Security Jenkins
- "Building a Continuous Delivery Pipeline Using Jenkins"
Alternatives to Jenkins
Jenkins is a very powerful tool that has many advantages over its competitors, including:
- General automation tooling (not just CI/CD)
- A vast library of plugins
- The ability to manage multiple projects in a single location
- A wide user base and community knowledge
- Venerability and time-tested adoption
Despite that, it is important to know its alternatives and understand where they outshine Jenkins. The following is a list of Jenkins's most popular alternatives (not comprehensive) and some advantages they may have over Jenkins when building a pipeline:
- GitHub Actions: GitHub Actions is the GitHub implementation of CI/CD. The biggest advantage of Actions over Jenkins is that Actions is directly incorporated with GitHub. This means a pipeline built in Actions (known as a workflow) can be accessed in the same GitHub repository where our code, issues, and Wikis are located. This means we do not have to manage a separate Jenkins server and can access all of the data that supports our code in one location. While Jenkins has a wider range of plugins and integrations that can be used, GitHub Actions should be seriously considered if we are building a pipeline for code already stored in GitHub.
- GitLab CI/CD: Similar to GitHub Actions, GitLab CI/CD is the native pipeline builder for GitLab repositories. The advantages that GitLab CI/CD has over Jenkins are analogous to GitHub Actions's advantages: All of the tools surrounding our pipelines are located in the same application where our code is stored. GitLab CI/CD should be seriously considered when using GitLab as a remote repository. Learn how to auto deploy Spring Boot apps with GitLab CI/CD.
Other alternatives to Jenkins are also common and may be useful to explore when setting up a pipeline:
While Jenkins has many advantages, it is important to explore alternative options to see which CI/CD solution is the best for the task at hand. Read DZone's coverage of Jenkins VS Bamboo, and Jenkins VS Gitlab.
Conclusion
Jenkins has been a vanguard in software automation and CI/CD since its inception in 2011. Despite this success, jumping straight into Jenkins can quickly become overwhelming. In this article, we looked at the fundamentals of CI/CD and how we can apply those concepts to create a working pipeline in Jenkins. Although this is a good starting point, it only scratches the surface of what Jenkins is capable of. As we create more and more complex projects and want to deliver more sophisticated products, we can take the knowledge we learned and use it as a building block to deliver software efficiently and effectively using Jenkins. Tutorial: Docker, Kubernetes, and Azure DevOps
More Information
For more information on CI/CD and Jenkins, see the following resources:
- The Jenkins User Handbook
- Continuous Delivery by Jez Humble and David Farley
- ContinuousDelivery.com
- The Jenkins Website
Opinions expressed by DZone contributors are their own.
Comments