Building Robust ML Systems: Best Practices for Production
The blog delves into practical tips and techniques for transitioning from an ML concept to a robust, operational product.
Join the DZone community and get the full member experience.
Join For FreeIn recent years, Machine Learning (ML) has propelled software systems into new realms of capability. From revolutionizing medical assistance and personalized recommendations to enabling chatbots and self-driving cars, ML has become a cornerstone of modern technology.
Despite these advancements, the path from an ML concept to a fully operational product is riddled with obstacles. Crafting an accurate model is challenging enough, but productionising it into a successful, robust product requires more than just a well-trained algorithm. The more critical aspects of building a scalable infrastructure, ensuring continuous monitoring, automated retraining, and data wrangling are often overlooked.
This blog outlines some best practices to keep in mind while turning an ML idea into a reliable product, addressing the often-overlooked challenges and providing insights into building a sustainable ML-driven solution. While there are simply too many variables at play depending on the use case, we will focus on some key aspects.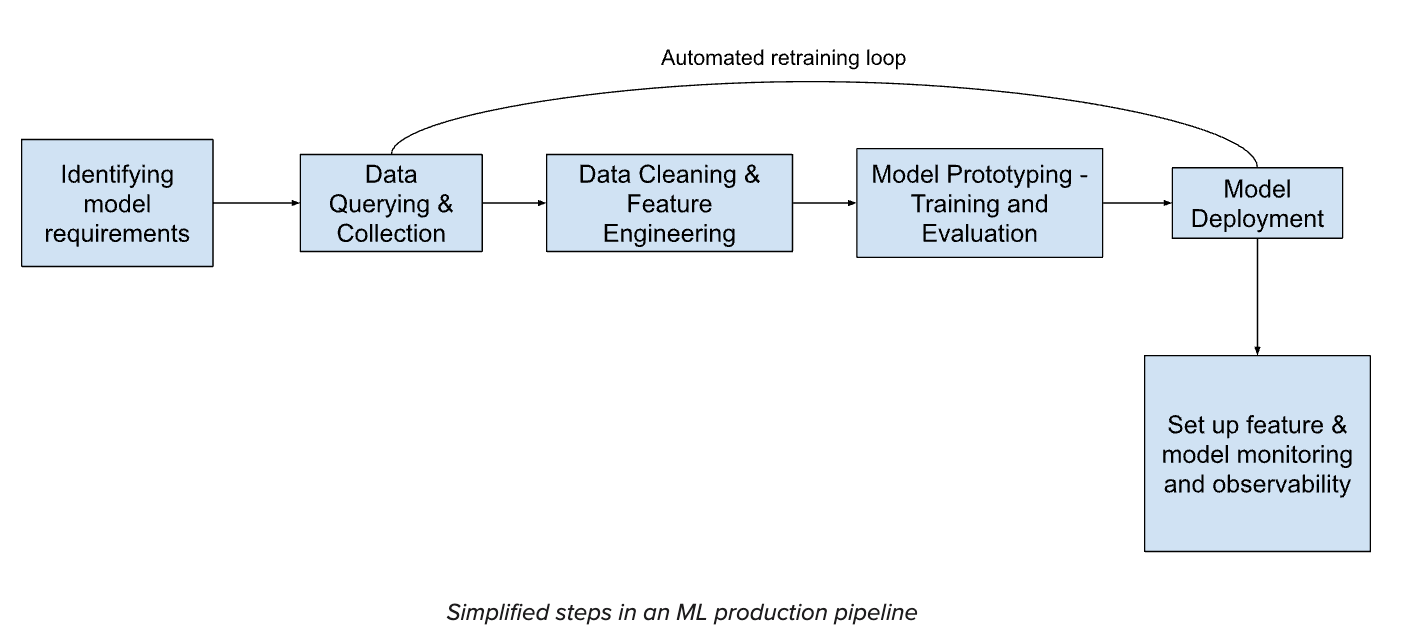
Setting Goals
Before embarking on model development and deployment, it is crucial to establish goals for the overall system and comprehend the model's objective within that system. Given that the ML model typically serves as a component of a larger system, it is essential to recognize that model accuracy is not the sole priority. While accurate predictions are vital for many applications of ML in production systems, over-investing in model accuracy — such as by adding new features, training on more data, or employing a more complex model — can be costly. Further, understanding the overall product requirements, as well as latency and memory constraints, often limits the available model design choices. Often, other system components, such as incorporating explainability into the product or additional human oversight, can alleviate many issues arising from inaccurate predictions.
Data Quality
Data is a core component of model training, and its quality largely determines the accuracy of predictions. Effective data cleaning and feature engineering, such as removing outliers, normalizing values, using word embeddings, or employing more complex and domain-specific techniques, are critical steps to ensure the model is trained on high-quality data. It is essential to apply these wrangling techniques consistently during both offline training and online inference to maintain parity and ensure the model's performance remains robust in production.
In production environments, a significant concern is the potential for data distribution to change over time, which may no longer align with the training data used during offline analysis. This phenomenon, known as data drift, can severely impact the model's predictive performance. Acquiring representative and generalizable training data is inherently challenging, making it crucial to implement dynamic data collection as part of the production pipeline. This can be achieved by storing data in a database or fetching it through queries, allowing the model to evolve and adapt to new data over time.
To address data drift effectively, it is necessary to implement robust feature drift detection and monitoring mechanisms. These systems should be capable of identifying shifts in data distribution promptly, enabling timely interventions to recalibrate the model.
Model Deployment
Model deployment and serving, transition an ML model from offline development to a live production environment, a critical step to ensure the model functions as intended and addresses the challenges it was designed to solve. After developing, saving, and testing the model offline, the high-level steps for serving include:
- Writing inference functions to load the model, encode features from requests, and invoke the model to generate responses.
- Creating a Docker file to define all runtime dependencies and the serving script.
- Building, running, and deploying the model locally or in the cloud.
Despite its apparent simplicity, this process involves numerous design decisions and trade-offs based on system requirements, model characteristics, component interactions, and organizational DevOps practices. Commonly, model inference is provided as a microservice, accessible via remote procedure calls, which allows for scalability and ease of model updates in case of frequent experimentation. Alternatively, models can also be embedded as client-side libraries, which may be suitable for applications requiring low-latency predictions. Ensuring that the deployment strategy aligns with the overall system architecture and business objectives is crucial.
Observability/Testing in Production
Once the model has been deployed, it is extremely essential to set up observability and testing in production to ensure that the model is accurate enough for practical use. Offline evaluation is often overly optimistic, and online performance is usually much lower. Therefore, it is necessary to establish monitoring pipelines that evaluate both model and business metrics to proactively catch data and concept drifts, feature mismatches, and model degradation. Degraded model outputs can inject a negative feedback loop in training, where low-quality outputs are used to retrain the model, accumulating errors over time.
For monitoring and evaluation, production data serves as the ultimate unseen test data. For example, when data drift occurs, production data will always reflect the most recent relevant distribution. By evaluating model accuracy in production, we can obtain an accurate picture of whether our model generalizes well. Before deploying models fully into production, it is also common practice to set up shadow execution, where the model makes predictions on production data, but those predictions are not actually used in decision-making.
This approach is used solely for model evaluation to catch unforeseen issues. For instance, shadow evaluations are often employed in autonomous driving systems to compare the autonomous system's proposed actions against those of a human. This practice helps ensure that the model performs reliably and safely in real-world scenarios.
Automated Retraining
In ML-enabled systems, it is crucial to design with the expectation that the model will require frequent updates. As improved feature engineering techniques or optimized hyperparameters are identified, or when new library updates are available, the model should be updated accordingly. Moreover, the model should be refreshed whenever new training data is obtained, particularly from production data as data distributions or labels evolve over time, necessitating regular retraining to maintain accuracy. Automating the pipeline streamlines these updates by eliminating manual errors and ensuring a robust infrastructure. This automation can be achieved by implementing a retraining Directed Acyclic Graph (DAG) in Airflow, which will kick off a pipeline running all the stages from data collection and feature engineering to model training and deployment on a scheduled basis.
Conclusion
In conclusion, developing and deploying ML models in production environments is a multifaceted yet essential process for the effective utilization of ML technology. This process encompasses several critical steps, including design, model development, containerization, and continuous monitoring and maintenance; and various challenges related to infrastructure, scalability, latency, etc. may arise. However, with meticulous planning and the appropriate tools and methodologies for deployment, testing, and monitoring, these challenges can be effectively addressed. This will not just ensure the seamless operation of ML models, but also enhance their ability to solve real-world problems.
Opinions expressed by DZone contributors are their own.
Comments