Observations on Cloud-Native Observability: A Journey From the Foundations of Observability to Surviving Its Challenges at Scale
Understand each team's responsibility, discover how to tackle observability challenges, and learn AI's role in the future of cloud-native observability.
Join the DZone community and get the full member experience.
Join For FreeEditor's Note: The following is an article written for and published in DZone's 2024 Trend Report, Cloud Native: Championing Cloud Development Across the SDLC.
Cloud native and observability are an integral part of developer lives. Understanding their responsibilities within observability at scale helps developers tackle the challenges they are facing on a daily basis. There is more to observability than just collecting and storing data, and developers are essential to surviving these challenges.
Observability Foundations
Gone are the days of monitoring a known application environment, debugging services within our development tooling, and waiting for new resources to deploy our code to. This has become dynamic, agile, and quickly available with auto-scaling infrastructure in the final production deployment environments.
Developers are now striving to observe everything they are creating, from development to production, often owning their code for the entire lifecycle. The tooling from days of old, such as Nagios and HP OpenView, can't keep up with constantly changing cloud environments that contain thousands of microservices. The infrastructure for cloud-native deployments is designed to dynamically scale as needed, making it even more essential for observability platforms to help condense all that data noise to detect trends leading to downtime before they happen.
Splintering of Responsibilities in Observability
Cloud-native complexity not only changed the developer world but also impacted how organizations are structured. The responsibilities of creating, deploying, and managing cloud-native infrastructure have split into a series of new organizational teams.
Developers are being tasked with more than just code creation and are expected to adopt more hybrid roles within some of these new teams. Observability teams have been created to focus on a specific aspect of the cloud-native ecosystem to provide their organization a service within the cloud infrastructure. In Table 1, we can see the splintering of traditional roles in organizations into these teams with specific focuses.
Table 1. Who's who in the observability game
| Team | Focus | maturity goals |
|---|---|---|
| DevOps |
Automation and optimization of the app development lifecycle, including post-launch fixes and updates | Early stages: developer productivity |
| Platform engineering | Designing and building toolchains and workflows that enable self-service capabilities for developers | Early stages: developer maturity and productivity boost |
| CloudOps | Provides organizations proper (cloud) resource management, using DevOps principles and IT operations applied to cloud-based architectures to speed up business processes | Later stages: cloud resource management, costs, and business agility |
| SRE | All-purpose role aiming to manage reliability for any type of environment; a full-time job avoiding downtime and optimizing performance of all apps and supporting infrastructure, regardless of whether it's cloud native | Early to late stages: on-call engineers trying to reduce downtime |
| Central observability team | Responsible for defining observability standards and practices, delivering key data to engineering teams, and managing tooling and observability data storage | Later stages, owning:
|
To understand how these teams work together, imagine a large, mature, cloud native organization that has all the teams featured in Table 1:
- The DevOps team is the first line for standardizing how code is created, managed, tested, updated, and deployed. They work with toolchains and workflow provided by the platform engineering team. DevOps advises on new tooling and/or workflows, creating continuous improvements to both.
- A CloudOps team focuses on cloud resource management and getting the most out of the budgets spent on the cloud by the other teams.
- An SRE team is on call to manage reliability, avoiding downtime for all supporting infrastructure in the organization. They provide feedback for all the teams to improve tools, processes, and platforms.
- The overarching central observability team sets the observability standards for all teams to adhere to, delivering the right observability data to the right teams and managing tooling and data storage.
Why Observability Is Important to Cloud Native
Today, cloud native usage has seen such growth that developers are overwhelmed by their vast responsibilities that go beyond just coding. The complexity introduced by cloud-native environments means that observability is becoming essential to solving many of the challenges developers are facing.
Challenges
Increasing cloud native complexity means that developers are providing more code faster and passing more rigorous testing to ensure that their applications work at cloud native scale. These challenges expanded the need for observability within what was traditionally the developers' coding environment. Not only do they need to provide code and testing infrastructure for their applications, they are also required to instrument that code so that business metrics can be monitored.
Over time, developers learned that fully automating metrics was overkill, with much of that data being unnecessary. This led developers to fine tune their instrumentation methods and turn to manual instrumentation, where only the metrics they needed were collected.
Another challenge arises when decisions are made to integrate existing application landscapes with new observability practices in an organization. The time developers spend manually instrumenting existing applications so that they provide the needed data to an observability platform is an often overlooked burden.
New observability tools designed to help with metrics, logs, and traces are introduced to the development teams — leading to more challenges for developers. Often, these tools are mastered by few, leading to siloed knowledge, which results in organizations paying premium prices for advanced observability tools only to have them used as if one is engaging in observability as a toy.
Finally, when exploring the ingested data from our cloud infrastructure, the first thing that becomes obvious is that we don't need to keep everything that is being ingested. We need the ability to have control over our telemetry data and find out what is unused by our observability teams.
There are some questions we need to answer about how we can:
- Identify ingested data not used in dashboards, alerting rules, nor touched in ad hoc queries by our observability teams
- Control telemetry data with aggregation and rules before we put it into expensive, longer-term storage
- Use only telemetry data needed to support the monitoring of our application landscape
Tackling the flood of cloud data in such a way as to filter out the unused telemetry data, keeping only that which is applied for our observability needs, is crucial to making this data valuable to the organization.
Cloud Native at Scale
The use of cloud-native infrastructure brings with it a lot of flexibility, but when done at scale, the small complexities can become overwhelming. This is due to the premise of cloud native where we describe how our infrastructure should be set up, how our applications and microservices should be deployed, and finally, how it automatically scales when needed. This approach reduces our control over how our production infrastructure reacts to surges in customer usage of an organization's services.
Empowering Developers
Empowering developers starts with platform engineering teams that focus on developer experiences. We create developer experiences in our organization that treat observability as a priority, dedicating resources for creating a telemetry strategy from day one. In this culture, we're setting up development teams for success with cloud infrastructure, using observability alongside testing, continuous integration, and continuous deployment.
Developers are not only owning the code they deliver but are now encouraged and empowered to create, test, and own the telemetry data from their applications and microservices. This is a brave new world where they are the owners of their work, providing agility and consensus within the various teams working on cloud solutions.
Rising to the challenges of observability in a cloud native world is a success metric for any organization, and they can't afford to get it wrong. Observability needs to be front of mind with developers, considered a first-class citizen in their daily workflows, and consistently helping them with challenges they face.
Artificial Intelligence and Observability
Artificial intelligence (AI) has risen in popularity within not only developer tooling but also in the observability domain. The application of AI in observability falls within one of two use cases:
- Monitoring machine learning (ML) solutions or large language model (LLM) systems
- Embedding AI into observability tooling itself as an assistant
The first case is when you want to monitor specific AI workloads, such as ML or LLMs. They can be further split into two situations that you might want to monitor, the training platform and the production platform.
Training infrastructure and the process involved can be approached just like any other workload: easy-to-achieve monitoring using instrumentation and existing methods, such as observing specific traces through a solution. This is not the complete monitoring process that goes with these solutions, but out-of-the-box observability solutions are quite capable of supporting infrastructure and application monitoring of these workloads.
The second case is when AI assistants, such as chatbots, are included in the observability tooling that developers are exposed to. This is often in the form of a code assistant, such as one that helps fine tune a dashboard or query our time series data ad hoc. While these are nice to have, organizations are very mindful of developer usage when inputting queries that include proprietary or sensitive data. It's important to understand that training these tools might include using proprietary data in their training sets, or even the data developers input, to further train the agents for future query assistance.
Predicting the future of AI-assisted observability is not going to be easy as organizations consider their data one of their top valued assets and will continue to protect its usage outside of their control to help improve tooling. To that end, one direction that might help adoption is to have agents trained only on in-house data, but that means the training data is smaller than publicly available agents.
Cloud-Native Observability: The Developer Survival Pattern
While we spend a lot of time on tooling as developers, we all understand that tooling is not always the fix for the complex problems we face. Observability is no different, and while developers are often exposed to the mantra of metrics, logs, and traces for solving their observability challenges, this is not the path to follow without considering the big picture.
The amount of data generated in cloud-native environments, especially at scale, makes it impossible to continue collecting all data. This flood of data, the challenges that arise, and the inability to sift through the information to find the root causes of issues becomes detrimental to the success of development teams. It would be more helpful if developers were supported with just the right amount of data, in just the right forms, and at the right time to solve issues. One does not mind observability if the solution to problems are found quickly, situations are remediated faster, and developers are satisfied with the results. If this is done with one log line, two spans from a trace, and three metric labels, then that's all we want to see.
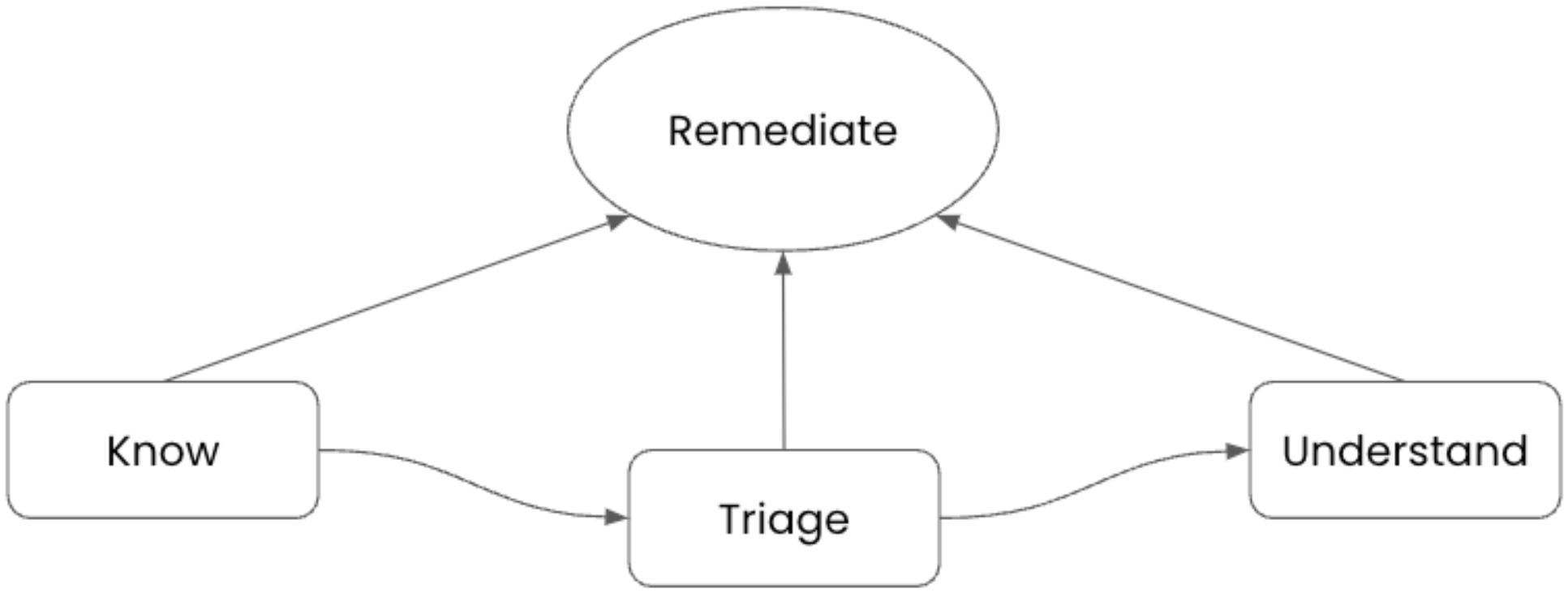
To do this, developers need to know when issues arise with their applications or services, preferably before it happens. They start troubleshooting with data that has been determined by their instrumented applications to succinctly point to areas within the offending application. Any tooling allows the developer who's investigating to see dashboards reporting visual information that directs them to the problem and potential moment it started. It is crucial for developers to be able to remediate the problem, maybe by rolling back a code change or deployment, so the application can continue to support customer interactions. Figure 1 illustrates the path taken by cloud native developers when solving observability problems. The last step for any developer is to determine how issues encountered can be prevented going forward.
Figure 1. Observability pattern
Conclusion
Observability is essential for organizations to succeed in a cloud native world. The splintering of responsibilities in observability, along with the challenges that cloud-native environments bring at scale, cannot be ignored. Understanding the challenges that developers face in cloud native organizations is crucial to achieving observability happiness. Empowering developers, providing ways to tackle observability challenges, and understanding how the future of observability might look are the keys to handling observability in modern cloud environments.
DZone Refcard resources:
- Full-Stack Observability Essentials by Joana Carvalho
- Getting Started With OpenTelemetry by Joana Carvalho
- Getting Started With Prometheus by Colin Domoney
- Getting Started With Log Management by John Vester
- Monitoring and the ELK Stack by John Vester
This is an excerpt from DZone's 2024 Trend Report,
Cloud Native: Championing Cloud Development Across the SDLC.
Read the Free Report
Opinions expressed by DZone contributors are their own.
Comments