Understanding RLAIF: A Technical Overview of Scaling LLM Alignment With AI Feedback
RLAIF uses AI feedback to train AI, scaling alignment, reducing human reliance, and costs, and enabling continuous improvement.
Join the DZone community and get the full member experience.
Join For FreeWith recent achievements and attention to LLMs and the resultant Artificial Intelligence “Summer,” there has been a renaissance in model training methods aimed at getting to the most optimal, performant model as quickly as possible. Much of this has been achieved through brute scale — more chips, more data, more training steps. However, many teams have been focused on how we can train these models more efficiently and intelligently to achieve the desired results.
Training LLMs typically include the following phases:

- Pretraining: This initial phase lays the foundation, taking the model from a set of inert neurons to a basic language generator. While the model ingests vast amounts of data (e.g., the entire internet), the outputs at this stage are often nonsensical, though not entirely gibberish.
- Supervised Fine-Tuning (SFT): This phase elevates the model from its unintelligible state, enabling it to generate more coherent and useful outputs. SFT involves providing the model with specific examples of desired behavior, and teaching it what is considered "helpful, useful, and sensible." Models can be deployed and used in production after this stage.
- Reinforcement Learning (RL): Taking the model from "working" to "good," RL goes beyond explicit instruction and allows the model to learn implicit preferences and desires of users through labeled preference data. This enables developers to encourage desired behaviors without needing to explicitly define why those behaviors are preferred.
- In-context learning: Also known as prompt engineering, this technique allows users to directly influence model behavior at inference time. By employing methods like constraints and N-shot learning, users can fine-tune the model's output to suit specific needs and contexts.
Note this is not an exhaustive list, there are many other methods and phases that may be incorporated into idiosyncratic training pipelines
Introducing Reward and Reinforcement Learning
Humans excel at pattern recognition, often learning and adapting without conscious effort. Our intellectual development can be seen as a continuous process of increasingly complex pattern recognition. A child learns not to jump in puddles after experiencing negative consequences, much like an LLM undergoing SFT. Similarly, a teenager observing social interactions learns to adapt their behavior based on positive and negative feedback – the essence of Reinforcement Learning.
Reinforcement Learning in Practice: The Key Components
- Preference data: Reinforcement Learning in LLMs typically require multiple (often 2) example outputs and a prompt/input in order to demonstrate a ‘gradient’. This is intended to show that certain behaviors are preferred relative to others. As an example, in RLHF, human users may be presented with a prompt and two examples and asked to choose which they prefer, or in other methods, they may be presented with an output and asked to improve on it in some way (where the improved version will be captured as the ‘preferred’ option).
- Reward model: A reward model is trained directly on the preference data. For a set of responses to a given input, each response can be assigned a scalar value representing its ‘rank’ within the set (for binary examples, this can be 0 and 1). The reward model is then trained to predict these scalar values given a novel input and output pair. That is, the RM is able to reproduce or predict a user’s preference
- Generator model: This is the final intended artifact. In simplified terms, during the Reinforcement Training Process, the Generator model generates an output, which is then scored by the Reward Model, and the resultant reward is fed back to the algorithm which decides how to mutate the Generator Model. For example, the algorithm will update the model to increase the odds of generating a given output when provided a positive reward and do the opposite in a negative reward scenario.
In the LLM landscape, RLHF has been a dominant force. By gathering large volumes of human preference data, RLHF has enabled significant advancements in LLM performance. However, this approach is expensive, time-consuming, and susceptible to biases and vulnerabilities.
This limitation has spurred the exploration of alternative methods for obtaining reward information at scale, paving the way for the emergence of RLAIF – a revolutionary approach poised to redefine the future of AI development.
Understanding RLAIF: A Technical Overview of Scaling LLM Alignment With AI Feedback
The core idea behind RLAIF is both simple and profound: if LLMs can generate creative text formats like poems, scripts, and even code, why can't they teach themselves? This concept of self-improvement promises to unlock unprecedented levels of quality and efficiency, surpassing the limitations of RLHF. And this is precisely what researchers have achieved with RLAIF.
As with any form of Reinforcement Learning, the key lies in assigning value to outputs and training a Reward Model to predict those values. RLAIF's innovation is the ability to generate these preference labels automatically, at scale, without relying on human input. While all LLMs ultimately stem from human-generated data in some form, RLAIF leverages existing LLMs as "teachers" to guide the training process, eliminating the need for continuous human labeling.
Using this method, the authors have been able to achieve comparable or even better results from RLAIF as opposed to RLHF. See below the graph of ‘Harmless Response Rate’ comparing the various approaches:
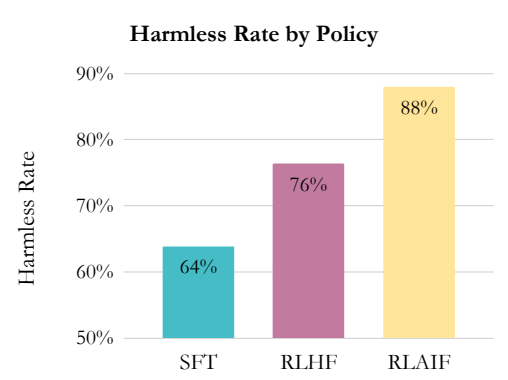
To achieve this, the authors developed a number of methodological innovations.
- In-context learning and prompt engineering: RLAIF leverages in-context learning and carefully designed prompts to elicit preference information from the teacher LLM. These prompts provide context, examples (for few-shot learning), and the samples to be evaluated. The teacher LLMs output then serves as the reward signal.
- Chain-of-thought reasoning: To enhance the teacher LLM's reasoning capabilities, RLAIF employs Chain-of-Thought (CoT) prompting. While the reasoning process itself isn't directly used, it leads to more informed and nuanced preference judgments from the teacher LLM.
- Addressing position bias: To mitigate the influence of response order on the teacher's preference, RLAIF averages preferences obtained from multiple prompts with varying response orders.
To understand this a little more directly, imagine the AI you are trying to train as a student, learning and improving through a continuous feedback loop. And then imagine an off-the-shelf AI, that has been through extensive training already, as the teacher. The teacher rewards the student for taking certain actions, coming up with certain responses, and so on, and punishes it otherwise. The way it does this is by ‘testing’ the student, by giving it quizzes where the student must select the optimal response. These tests are generated via ‘contrastive’ prompts, where the teacher generates slightly variable responses by slightly varying prompts in order to generate the responses.
For example, in the context of code generation, one prompt might encourage the LLM to generate efficient code, potentially at the expense of readability, while the other emphasizes code clarity and documentation. The teacher then assigns its own preference as the ‘ground truth’ and asks the Student to indicate what it thinks is the preferred output. By comparing the students’ responses under these contrasting prompts, RLAIF assesses which response better aligns with the desired attribute.
The student, meanwhile, aims to maximize the accumulated reward. So every time it gets punished, it decides to change something about itself so it doesn’t make a mistake again, and get punished again. When it is rewarded, it aims to reinforce that behavior so it is more likely to reproduce the same response in the future. In this way, over successive quizzes, the student gets better and better and punished less and less. While punishments never go to zero, the Student does converge to some minimum which represents the optimal performance it is able to achieve. From there, future inferences made by the student are likely to be of much higher quality than if RLAIF was not employed.
The evaluation of synthetic (LLM-generated) preference data is crucial for effective alignment. RLAIF utilizes a "self-rewarding" score, which compares the generation probabilities of two responses under contrastive prompts. This score reflects the relative alignment of each response with the desired attribute. Finally, Direct Preference Optimization (DPO), an efficient RL algorithm, leverages these self-rewarding scores to optimize the student model, encouraging it to generate responses that align with human values. DPO directly optimizes an LLM towards preferred responses without needing to explicitly train a separate reward model.
RLAIF in Action: Applications and Benefits
RLAIF's versatility extends to various tasks, including summarization, dialogue generation, and code generation. Research has shown that RLAIF can achieve comparable or even superior performance to RLHF, while significantly reducing the reliance on human annotations. This translates to substantial cost savings and faster iteration cycles, making RLAIF particularly attractive for rapidly evolving LLM development.
Moreover, RLAIF opens doors to a future of "closed-loop" LLM improvement. As the student model becomes better aligned through RLAIF, it can, in turn, be used as a more reliable teacher model for subsequent RLAIF iterations. This creates a positive feedback loop, potentially leading to continual improvement in LLM alignment without additional human intervention.
So how can you leverage RLAIF? It’s actually quite simple if you already have an RL pipeline:
- Prompt set: Start with a set of prompts designed to elicit the desired behaviors. Alternatively, you can utilize an off-the-shelf LLM to generate these prompts.
- Contrastive prompts: For each prompt, create two slightly varied versions that emphasize different aspects of the target behavior (e.g., helpfulness vs. safety). LLMs can also automate this process.
- Response generation: Capture the responses from the student LLM for each prompt variation.
- Preference elicitation: Create meta-prompts to obtain preference information from the teacher LLM for each prompt-response pair.
- RL pipeline integration: Utilize the resulting preference data within your existing RL pipeline to guide the student model's learning and optimization.
Challenges and Limitations
Despite its potential, RLAIF faces challenges that require further research. The accuracy of AI annotations remains a concern, as biases from the teacher LLM can propagate to the student model. Furthermore, biases incorporated into this preference data can eventually become ‘crystallized’ in the teacher LLM which makes it difficult to remove afterward. Additionally, studies have shown that RLAIF-aligned models can sometimes generate responses with factual inconsistencies or decreased coherence. This necessitates exploring techniques to improve the factual grounding and overall quality of the generated text.
Addressing these issues necessitates exploring techniques to enhance the reliability, quality, and objectivity of AI feedback.
Furthermore, the theoretical underpinnings of RLAIF require careful examination. While the effectiveness of self-rewarding scores has been demonstrated, further analysis is needed to understand its limitations and refine the underlying assumptions.
Emerging Trends and Future Research
RLAIF's emergence has sparked exciting research directions. Comparing it with other RL methods like Reinforcement Learning from Execution Feedback (RLEF) can provide valuable insights into their respective strengths and weaknesses.
One direction involves investigating fine-grained feedback mechanisms that provide more granular rewards at the individual token level, potentially leading to more precise and nuanced alignment outcomes. Another promising avenue explores the integration of multimodal information, incorporating data from images and videos to enrich the alignment process and foster a more comprehensive understanding within LLMs. Drawing inspiration from human learning, researchers are also exploring the application of curriculum learning principles in RLAIF, gradually increasing the complexity of tasks to enhance the efficiency and effectiveness of the alignment process.
Additionally, investigating the potential for a positive feedback loop in RLAIF, leading to continual LLM improvement without human intervention, represents a significant step towards a more autonomous and self-improving AI ecosystem.
Furthermore, there may be an opportunity to improve the quality of this approach by grounding feedback in the real world. As an example, if the agent were able to execute code, perform real-world experiments, or integrate with a robotic system to ‘instantiate’ feedback in the real world to capture more objective feedback, it would be able to capture more accurate, and reliable preference information without losing scaling advantages.
However, ethical considerations remain paramount. As RLAIF empowers LLMs to shape their own alignment, it's crucial to ensure responsible development and deployment. Establishing robust safeguards against potential misuse and mitigating biases inherited from teacher models are essential for building trust and ensuring the ethical advancement of this technology. As mentioned previously, RLAIF has the potential to propagate and amplify biases present in the source data, which must be carefully examined before scaling this approach.
Conclusion: RLAIF as a Stepping Stone To Aligned AI
RLAIF presents a powerful and efficient approach to LLM alignment, offering significant advantages over traditional RLHF methods. Its scalability, cost-effectiveness, and potential for self-improvement hold immense promise for the future of AI development. While acknowledging the current challenges and limitations, ongoing research efforts are actively paving the way for a more reliable, objective, and ethically sound RLAIF framework. As we continue to explore this exciting frontier, RLAIF stands as a stepping stone towards a future where LLMs seamlessly integrate with human values and expectations, unlocking the full potential of AI for the benefit of society.
Opinions expressed by DZone contributors are their own.
Comments