A Comprehensive Guide to Generative AI Training
Detailed technical guide covering the complete lifecycle of LLM development, from raw text pre-training through instruction tuning to human alignment.
Join the DZone community and get the full member experience.
Join For FreeLarge language models (LLMs) have impacted natural language processing (NLP) by introducing advanced applications such as text generation, summarization, and conversational AI. Models like ChatGPT use a specific neural architecture called a transformer to predict the next word in a sequence, learning from enormous text datasets through self-attention mechanisms.
This guide breaks down the step-by-step process for training generative AI models, including pre-training, fine-tuning, alignment, and practical considerations.
Overview of the Training Pipeline
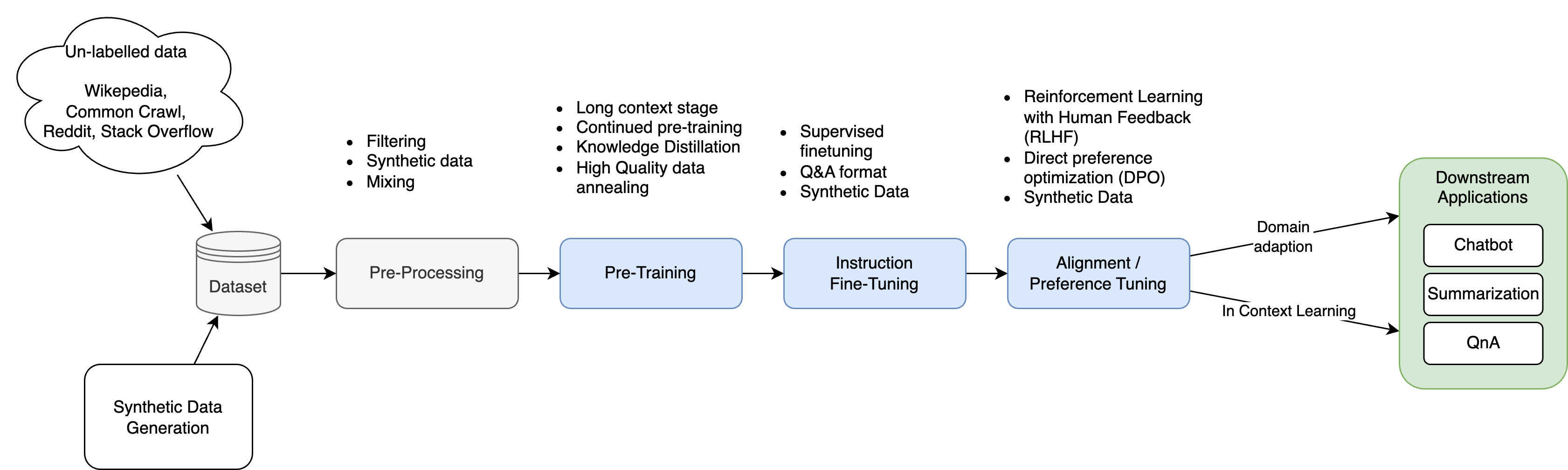
The training pipeline for LLMs is a structured, multi-phase process designed to enhance linguistic understanding, task-specific capabilities, and alignment with human preferences.
- Data collection and preprocessing. Vast text data from diverse sources is collected, cleaned, tokenized, and normalized to ensure quality. High-quality, domain-specific data improves factual accuracy and reduces hallucinations.
- Pre-training. This is the foundational stage where the model learns general language patterns through self-supervised learning, a technique for the model to teach itself patterns in text without needing labeled examples. Take, for example, next token prediction. This phase relies on massive datasets and transformer architectures to build broad linguistic capabilities.
- Instruction fine-tuning. The model is trained on smaller, high-quality input-output datasets to specialize in specific tasks or domains. This instruction tuning step ensures more accurate and contextually appropriate outputs.
- Model alignment. Reinforcement learning from human feedback (RLHF) refines the model’s behavior:
- Reward model training. Human evaluators rank outputs to train a reward model.
- Policy optimization. The LLM is iteratively optimized to align with human preferences, ethical considerations, and user expectations.
- Evaluation and iterative fine-tuning. The model is tested on unseen data to evaluate metrics like accuracy and coherence. Further fine-tuning may follow to adjust hyperparameters or incorporate new data.
- Downstream application adaptation. The trained LLM is adapted for real-world applications (e.g., chatbots, content generation) through additional fine-tuning or integration with task-specific frameworks.
This pipeline transforms LLMs from general-purpose models into specialized tools capable of addressing diverse tasks effectively.
1. Pre-Training
Pre-training is the foundational stage in the development of LLMs, where a model learns general language patterns and representations from vast amounts of text data. This phase teaches the model grammar rules, contextual word relationships, and basic logical patterns (e.g., cause-effect relationships in text), thus forming the basis for its ability to perform diverse downstream tasks.
How Pre-Training Works
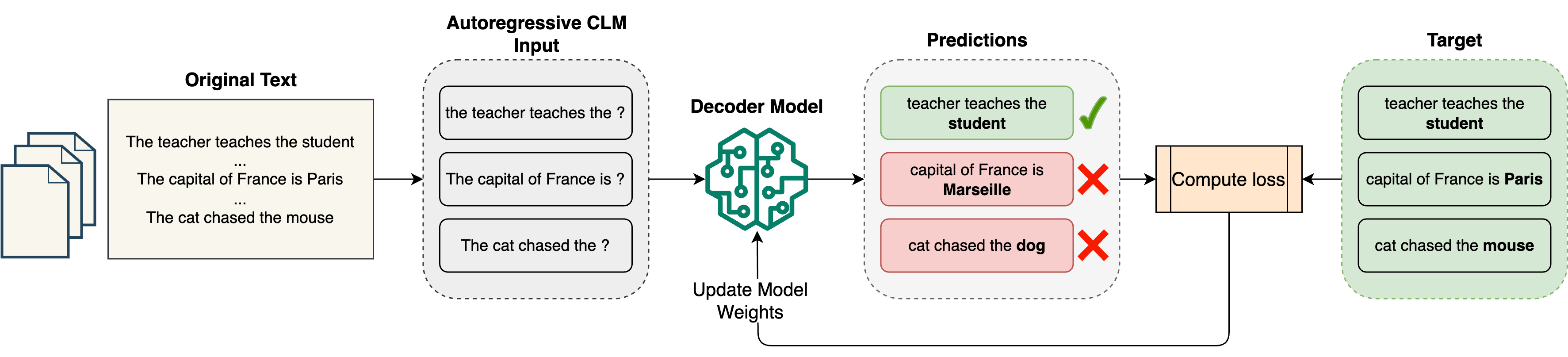
Objective
The primary goal of pre-training is to enable the model to predict the next token in a sequence. This is achieved through causal language modeling (CLM), which is a way to teach the model to predict what comes next in a sentence. In this step, the model learns to generate coherent and contextually relevant text by looking only at the past tokens.
Datasets
Pre-training requires massive and diverse datasets sourced from books, articles, websites, and other publicly available content. Popular datasets include Common Crawl, Wikipedia, The Pile, and BookCorpus. These datasets are often cleaned and normalized to ensure high-quality input with techniques like deduplication and tokenization applied during preprocessing. Long-context data is curated to increase the context length of the model.
Pre-Training Process
- The model learns to predict the next token in a sequence through causal language modeling.
- The model predictions are compared to actual next words using a cross-entropy loss function, which measures the model performance during training.
- Model parameters are continuously adjusted to minimize prediction errors or loss until the model reaches an acceptable accuracy level.
- The pre-training phase requires significant computational resources, often utilizing thousands of GPU hours across distributed systems to process the massive datasets needed for effective training.
This is a self-supervised learning approach where the model learns patterns directly from raw text without manual labels. Thus, eliminating costly human annotations by having the model predict next tokens.
In the following example, we use a GPT 2 model, which was pre-trained on a very large corpus of English data in a self-supervised fashion with no humans labeling them in any way.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load the model and tokenizer
model = AutoModelForCausalLM.from_pretrained("gpt2")
tokenizer = AutoTokenizer.from_pretrained("gpt2")
input_text = "The capital of France is"
# Tokenize the input text
model_inputs = tokenizer([input_text], return_tensors="pt")
# Run inference on the pretrained model and decode the output
generated_ids = model.generate(**model_inputs, max_new_tokens=25, do_sample=True)
print(tokenizer.batch_decode(generated_ids)[0])As expected, the model is able to complete the sentence "The capital of France is" by iteratively predicting the next token as per its pre-training.
The capital of France is the city of Paris which is more prosperous than the other capitals in ...However, when phrased as a question, i.e., "What is the capital of France?" the model fails to produce the correct result because, at this stage of the training, it can't follow instructions yet.
text2 = "What is the capital of France?"
model_inputs = tokenizer([text2], return_tensors="pt")
generated_ids = model.generate(**model_inputs, max_new_tokens=25, do_sample=True)
print(tokenizer.batch_decode(generated_ids)[0])Output:
What is the capital of France? In our opinion we should be able to count the number of people in France today. The government has made this a big priority
Benefits of Pre-Training
- Broad language understanding. By training on diverse data, pre-trained models develop a comprehensive grasp of language structures and patterns, enabling them to generalize across various tasks.
- Efficiency. Pre-trained models can be fine-tuned for specific tasks with smaller labeled datasets, saving time and resources compared to training models from scratch for each task.
- Performance. Models that undergo pre-training followed by fine-tuning consistently outperform those trained solely on task-specific data due to their ability to leverage knowledge from large-scale datasets.
2. Instruction Fine-Tuning
Instruction fine-tuning is a specialized training technique that transforms general-purpose LLMs into responsive, instruction-following systems. Here, the model is trained on specific tasks like answering questions or summarizing text. By training models on curated (instruction, output) pairs, this method aligns LLMs' text generation capabilities with human-defined tasks and conversational patterns.
The training (instruction, output) sample looks like this:
Instruction: What is the capital of Germany?
Response: The capital of Germany is Berlin.
In the following example, we load the Gemma 2 LLM model from Google, which is instruction-tuned on a variety of text generation tasks, including question answering, summarization, and reasoning.
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# Load Gemma 2 2b instruct model
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-2b-it")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2-2b-it")
# Tokenize input
input_text = "What is the capital of France?"
input_ids = tokenizer(input_text, return_tensors="pt")
# Run model inference and decode output
outputs = model.generate(**input_ids, max_new_tokens=25, do_sample=True)
print(tokenizer.decode(outputs[0]))This fine-tuned model is able to follow the following instructions:
What is the capital of France? The capital of France is Paris.How Instruction Fine-Tuning Works
Objective
Instruction fine-tuning bridges the critical gap between an LLM's fundamental next-word prediction capability and practical task execution by teaching models to understand and follow natural language instructions. This process transforms general-purpose LLMs into responsive, instruction-following systems that consistently follow user commands like "Summarize this article" or "Write a Python function for X."
Supervised Learning
Unlike pre-training, which uses self-supervised learning on unlabeled data, instruction fine-tuning employs supervised learning with labeled instruction-output pairs. The process involves:
- Using explicit instruction-response pairs for training
- Updating model weights to optimize for instruction following
- Maintaining the model's base knowledge while adapting response patterns
Dataset
The instruction dataset consists of three key components:
- Instruction – natural language command or request
- Input – optional context or examples
- Output – desired response demonstrating correct task execution
Instruction: Find the solution to the quadratic equation.
Context: 3x² + 7x - 4 = 0
Response: The solution of the quadratic equation is x = -4 and x = 1/3.These datasets can be created through manual curation by domain experts, synthetic generation using other LLMs, or conversion of existing labeled datasets into instruction format.
Fine-Tuning Techniques
Two primary approaches dominate instruction fine-tuning:
- Full model fine-tuning updates all model parameters, offering better performance for specific tasks at the cost of higher computational requirements.
- Lightweight adaptation methods (like LoRA) modify small parts of the model instead of retraining everything, significantly reducing memory requirements.
Benefits of Instruction Fine-Tuning
- Enhanced task generalization. Models develop meta-learning capabilities, improving performance on novel tasks without specific training.
- Reduced prompt engineering. Fine-tuned models require fewer examples in prompts, making deployment more efficient.
- Controlled output: Enables precise customization of response formats and styles.
- Better instruction following. Bridges the gap between model capabilities and user expectations.
3. Alignment Tuning
Alignment or preference tuning is a critical phase in training Large Language Models (LLMs) to ensure the model avoids harmful or biased responses. This step goes beyond improving performance on specific tasks - it focuses on making models safer, more helpful, and user-aligned by incorporating human feedback or predefined guidelines.
Why Alignment Is Necessary
Pre-trained LLMs are trained on massive datasets from the internet, which may contain biases, harmful content, or conflicting information. Without alignment, these models might give answers that are offensive and misleading. Alignment tuning filters harmful outputs (e.g., biased or dangerous content) using human feedback to ensure responses comply with safety guidelines.
Following is an example from OpenAI's GPT-4 System Card showing the safety challenges that arise from the non-aligned "GPT-4 (early)" model.

The GPT-4 system card highlights the importance of fine-tuning the model using RLHF to align the model responses with human preferences for helpfulness and harmlessness. It mitigates unsafe behavior and prevents the model from generating harmful content and biases.
Key Methods for Alignment
The following diagram from the DPO paper illustrates the most commonly used methods:
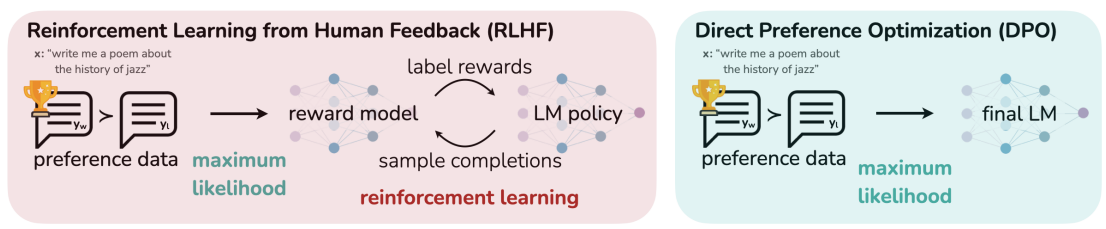
Reinforcement Learning from Human Feedback (RLHF)
RLHF is a machine learning technique designed to align LLMs with human values, preferences, and expectations. By incorporating human feedback into the training process, RLHF enhances the model's ability to produce outputs that are coherent, useful, ethical, and aligned with user intent. This method has been crucial for making generative models like ChatGPT and Google Gemini safer and more reliable.
The RLHF process consists of three main steps:
| Step | Description | Outcome |
|---|---|---|
| Human Feedback | Annotators rank outputs for relevance/ethics | Preference dataset creation |
| Reward Model | Trained to predict human preferences | Quality scoring system |
| Policy Optimization | LLM fine-tuned via reinforcement learning (e.g., PPO) | Aligned response generation |
- Collecting human feedback
- Human annotators evaluate model-generated outputs by ranking or scoring them based on criteria such as relevance, coherence, and accuracy.
- Pairwise comparisons are commonly used, where annotators select the better response between two options.
- This feedback forms a "preference dataset" that reflects human judgment.
- Training a reward model
- A reward model is trained using the preference dataset to predict how well a given response aligns with human preferences.
- The reward model assigns a scalar reward score (say 0 to 10) to outputs based on human preferences to train the LLM to prioritize high-scoring responses.
- Fine-tuning with reinforcement learning
- The LLM is fine-tuned using reinforcement learning algorithms like Proximal Policy Optimization (PPO) which teaches an AI to improve gradually rather than making dramatic changes all at once.
- The reward model guides this process by providing feedback on generated outputs, enabling the LLM to optimize its policy for producing high-reward responses.
Direct Preference Optimization (DPO)
Direct Preference Optimization (DPO) is an emerging training method designed to align LLMs with human preferences. It serves as a simpler and more efficient alternative to RLHF, bypassing the need for complex reinforcement learning algorithms like Proximal Policy Optimization (PPO). Instead, DPO skips reward modeling by directly training the LLM on human-ranked responses.
The preference data generation process remains the same, as highlighted in the RLHF method above. The DPO process consists of:
- Direct optimization
- Unlike RLHF, which trains a reward model and uses reinforcement learning, DPO directly fine-tunes the LLM to produce outputs that maximize alignment with the ranked preferences.
- This is achieved by directly training the model to favor high-ranked responses and avoid low-ranked ones.
- Model training. The optimization process adjusts the model’s parameters to prioritize generating responses that align with human preferences, without requiring iterative policy updates as in RLHF.
Model alignment has been successfully applied across various domains:
- Conversational AI. Aligning chatbots with user expectations for tone, relevance, and ethical standards.
- Content generation. Optimizing models for tasks like summarization or creative writing based on user-defined quality metrics.
- Ethical AI development. Ensuring models adhere to guidelines for fairness, safety, and inclusivity without extensive computational overhead.
Conclusion
This guide shows you the nuts and bolts of LLM training. Are you ready to dive in? Many open-source models and datasets are waiting for you to experiment with and adapt them to solve your specific problems.
Opinions expressed by DZone contributors are their own.
Comments