Streaming in Mule 4: Processing Large Data Sets
The fundamental task of MuleSoft is to integrate different systems. We will explore leveraging Streaming in Mule 4 to process large datasets.
Join the DZone community and get the full member experience.
Join For FreeMule is a lightweight enterprise service bus and integration framework provided by MuleSoft. The platform is Java-based and hence makes use of the JVM for process execution. It is the fundamental task in MuleSoft to integrate different systems, and there are scenarios where we take data from one system, then process it, and finally load it into another system (ETL), where these source and end systems can be Database, Salesforce, SFTP/FTP or Files. There can be various approaches we can adopt to achieve the above goal. But when processing a reasonable amount of data, one of the concerns designers and developers need to address is the potential of retrieving an enormous number of results in a single load session because if the size of the data being loaded into the JVM Heap Memory exceeds its size, we get the memory out of bound exception, our
application crashes, and the process execution fails.
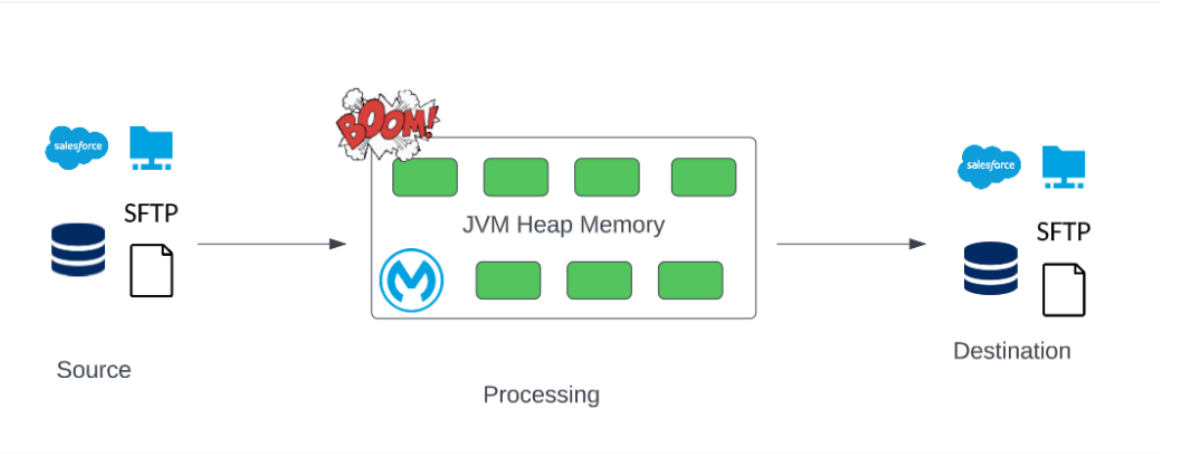
Some Conventional Solutions
To address the problem we encountered in the above scenario, we can make use of the following logic:
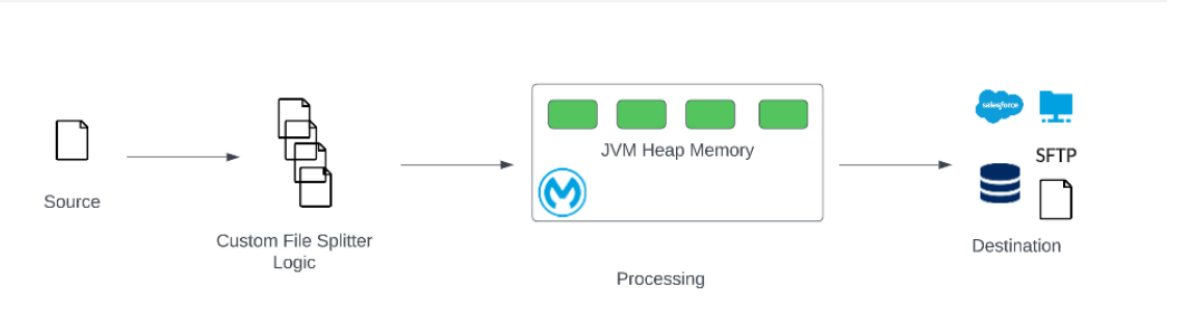
1. Custom File Splitter
Suppose we have a large file, say 10GB CSV, so it is obvious if this amount of data is loaded into the memory, the application would crash owing to storage considerations. What we can do is use a custom Java Logic or even a file splitter exe file to split the file into smaller volumes of data so that it is accommodatable in the memory and the process execution succeeds.
2. Pagination
Let's explain this technical concept using layman's terms. Suppose we search a particular phrase on Google, and it displays “some million number of records in some seconds.” But it doesn’t show them in one go. Instead, it splits the records into pages, say 0-10 records on Page 1, 10-20 records on Page 2, and so on. This essentially is pagination. If we are reading data from DB, we can process it using pagination logic so as to retrieve the records in batches of set size again to satisfy the need to be able to accommodate it in the memory.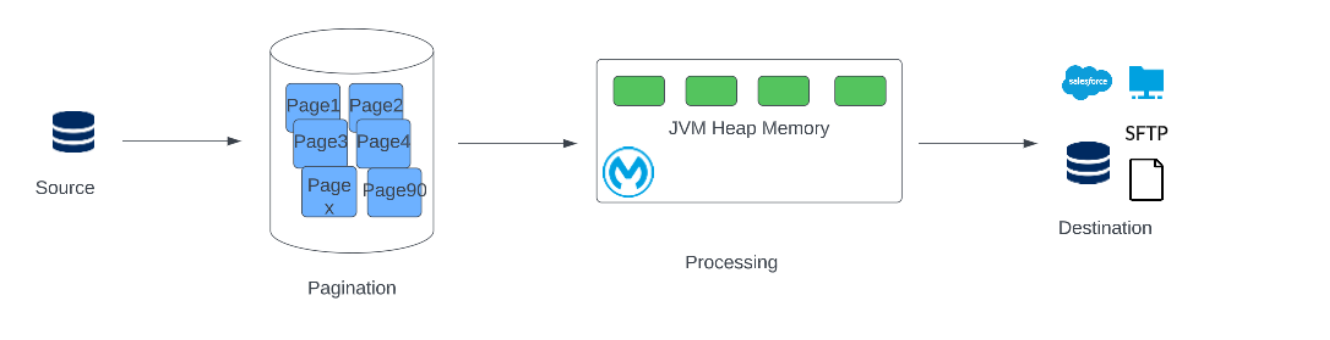
Pagination makes use of offset and limit (these terms are specific to MySQL, oracle DB has offset and fetchNext), where the offset is the initial record from which the retrieval is to be started, and the limit is the number of records to be fetched in one go.
Some Considerations
Initially, it looks like the above solutions might effectively address our problems. But, it is not always a good idea to use a custom splitter for file processing. Also, pagination leads to the same problem of heap memory overflow when there are a large number of concurrent requests, thus leading our application to crash. For example, We have a SAPI that retrieves 100 records from the DB (that has 10,000 records) as per the pagination logic, but at the same time, it has an SLA to serve up to 100 requests per second. This 100 req per second X 100 records = 10,000 records which might again lead to a memory exception. Therefore, we came up with the Streaming logic to solve the problem of processing large data sets.
What Is Streaming?
Streaming is the process where we refer to the data as its bytes arrive at the flow rather than scanning and loading the entire document to index it. Streaming speeds up the processing of large documents without overloading the data into memory. It helps to process a large set of data with low resource consumption in an efficient manner.
As we have a cursor that points to the instance of data being processed, the whole data is not loaded into the memory, so, essentially, there is a very slight chance that this would lead to the heap memory being overloaded. This cursor is encapsulated in a stream, an object which is at the core of the concept of streaming.
Types of Streaming in Mule 4
There are three types of Streams in Mule 4:
1. Non Repeatable Stream (available in Mule 3 also)
2. Repeatable In-Memory Stream
3. Repeatable File Stored Stream
The latter two are new to Mule 4 and hence exclusive to it.
Stream vs. Iterable
We will notice that while enabling the repeatable streaming for various connectors, we will see two different entities: Streams and Iterables.
We will notice that while enabling repeatable streaming for various connectors, we will see two different entities: Streams and Iterables.
They correlate to the concept of binary streaming and object streaming.
- Binary Streaming: Binary streams have no understanding of the data structure in their stream. This is typical of the HTTP, File, Sockets, and SFTP modules.
![Binary Streaming]()
- Object Streaming: Object streams are effectively Object iterables. They are configurable for operations that support paging like the Database select operation or the Salesforce query operation.
![Object Streaming]()


Salesforce and Database have data in them with an inherent structure of their own. The data in them is stored in the form of objects and records; hence they are output in the form of iterable, but the CSV file’s output would only be calculated by the size of the data output by it.
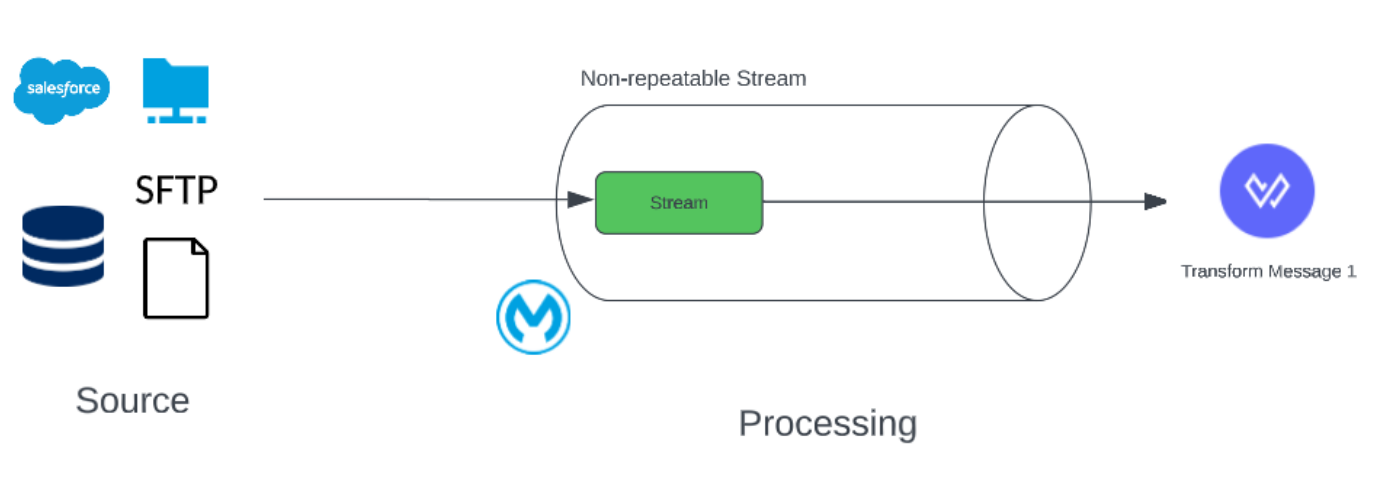
Non-Repeatable Stream
1. Cannot be read more than once
2. Cannot be consumed simultaneously
3. Very performant but needs careful treatment
a. No additional memory buffers
b. No I/O operations (disk-based buffers)
4. Suitable for processing large streams
Real-Life Example
Suppose me and my friend are standing by the side of a river; my friend is farther away from me. So if one fish (depiction of data) is coming in the stream of the river and we want to cook it (depiction of processing), then if I grab the fish first and cook it, the same won’t be available to my friend to be picked and cooked.
This essentially is the concept of Non- Repeatable streaming. Once the data is processed or consumed by one of the processors, it won't be available to another subsequent processor for consumption.
If we consume the data once and we try to write it to another file, we would see an empty file being created with no data inside.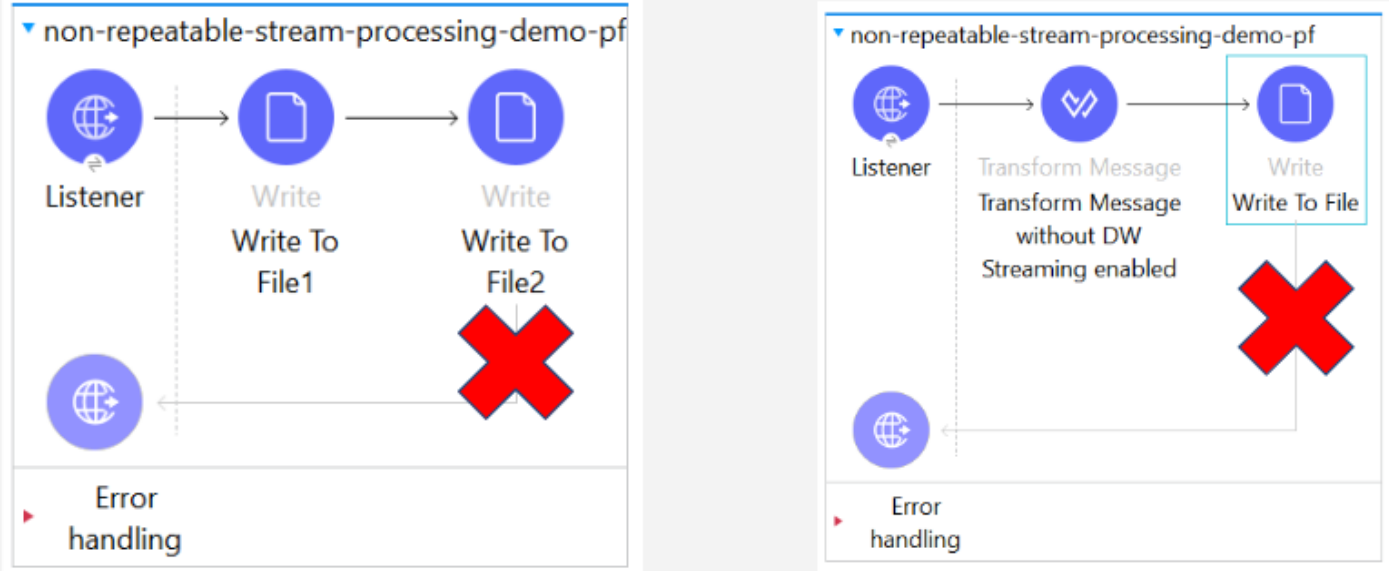
Also, the data cannot be consumed simultaneously:
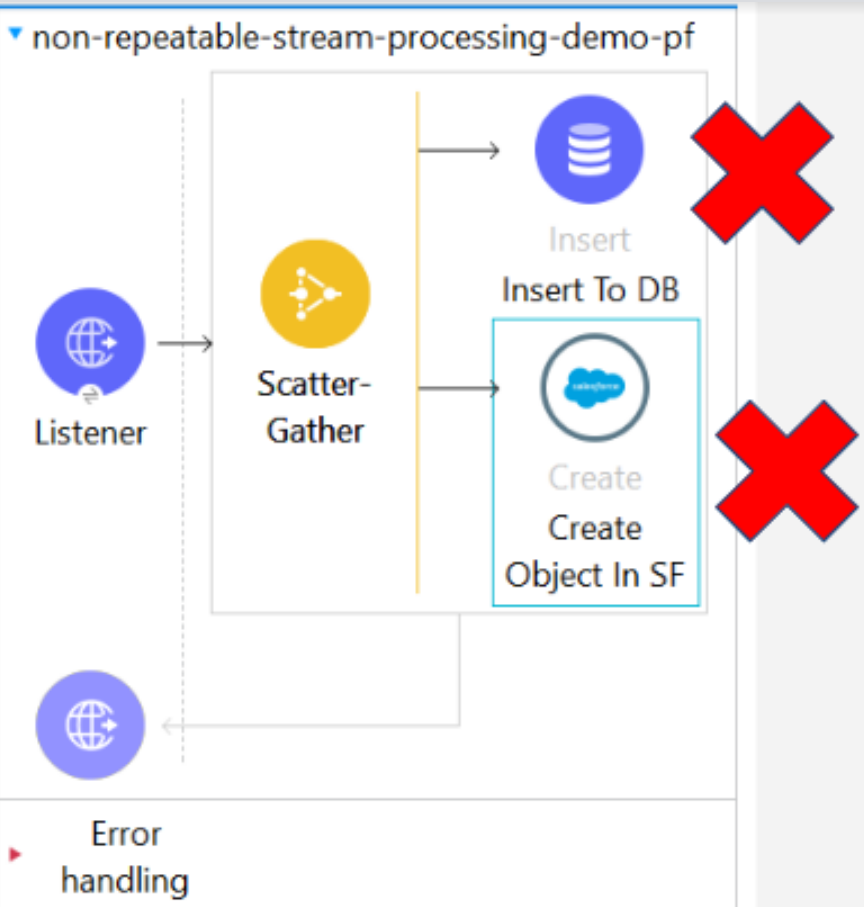
- The multiple threads of scatter gather that constitute parallel processing won’t be able to consume the data simultaneously; hence we would see an error come up stating the same.
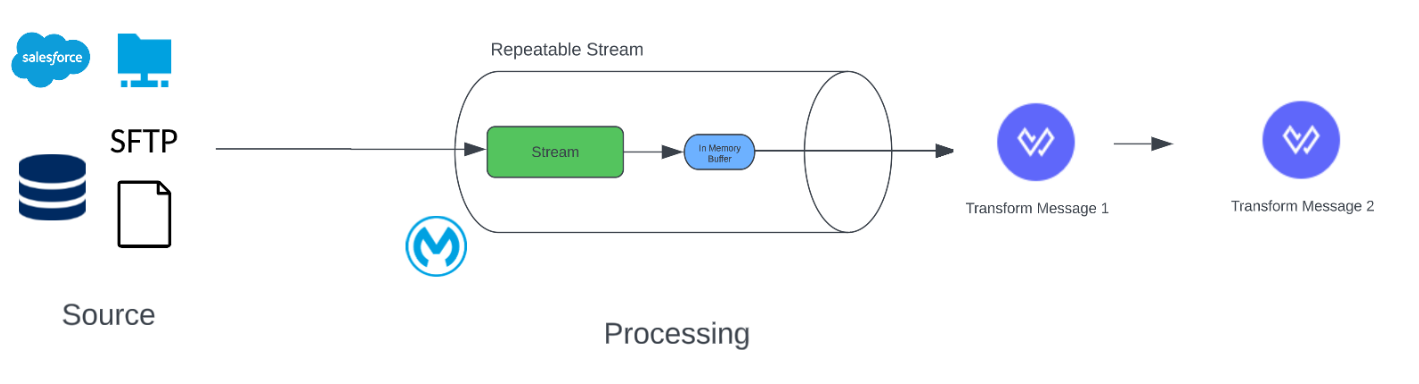
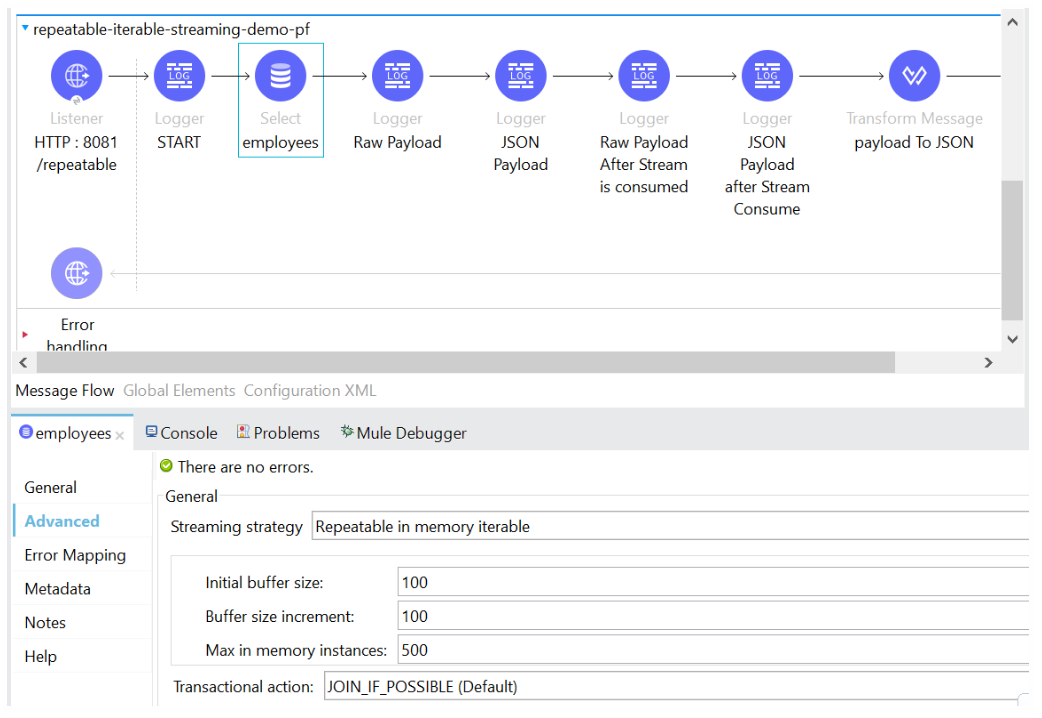
Repeatable In-Memory Stream
- This streaming strategy is a bit different from others. In this, the data will be stored in memory (heap memory); it will not be stored in disk space.
- If you pass payload more than heap size, it will throw memory out of bound exception.
Various Terminologies
 ● initialBufferSize: The initial size of the in-memory buffer
● initialBufferSize: The initial size of the in-memory buffer
● bufferSizeIncrement: The rate at which the buffer increases.
● maxInMemorySize: The maximum buffer size after which the memory out of bound exception will be thrown
● bufferUnit: The unit of measurement for the buffer size value.
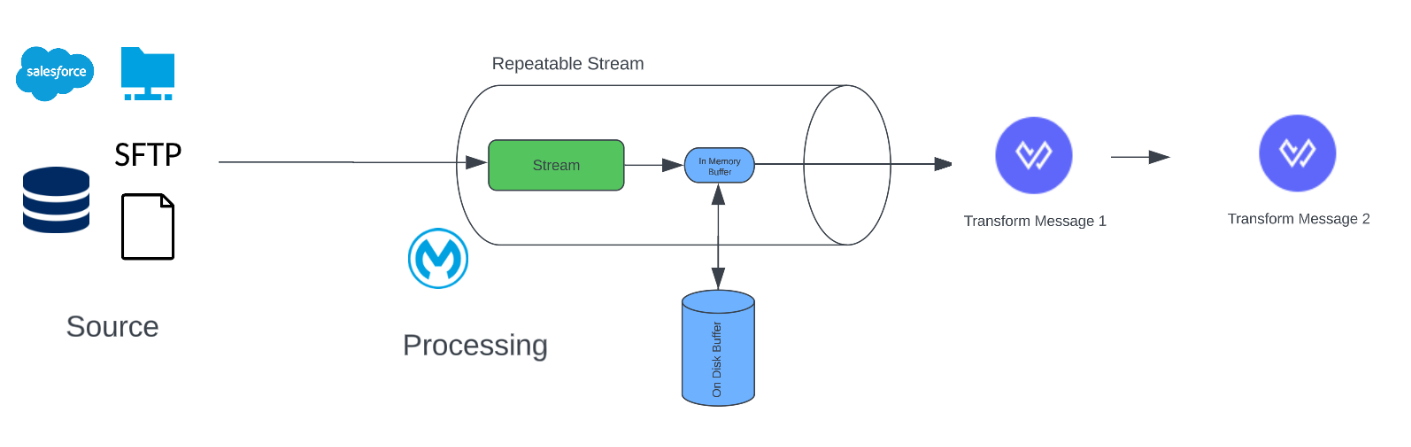
![buffer size]() Repeatable File Stored Stream
Repeatable File Stored Stream
 Repeatable File Stored Stream
Repeatable File Stored Stream- In reality, for 0.1 vCore there is 8GB of memory available. What MuleSoft provides to us is 512 MB as Heap memory. After 512 MB is full, data will be stored in the disk storage using the “Kryo” Serializer, which is the remaining memory (8GB – 512MB (some installations let us assume 1.5 GB)).
- When using the file-store repeatable stream strategy, customize the buffer size inMemorySize to your use case to optimize performance.
- Configure a larger buffer size to avoid the number of times Mule needs to write the buffer on disk. This increases performance, but it also limits the number of concurrent requests your application can process because it requires additional memory.
- Configure a smaller buffer size to decrease memory load at the expense of response time.
![Repeatable File Stored Stream]()
- This writing to a temporary file on the disk is taken care of by the Kryo Serialzer. Mule 4 makes use of this serializer instead of the conventional Java serializer because it’s much faster and hence efficient than it because the objects being serialized here don’t need to implement the serializable class as in the Java serializer.
- But Kryo might not also be able to serialize some objects. A typical case is a POJO containing an org.apache.xerces.jaxp.datatype.XMLGregorianCalendarImpl, which is in use in the NetSuite or Microsoft Dynamics CRM connectors.
Demo 1: Difference Between Repeatable and Non-Repeatable Streaming![non-repeatable demo]()
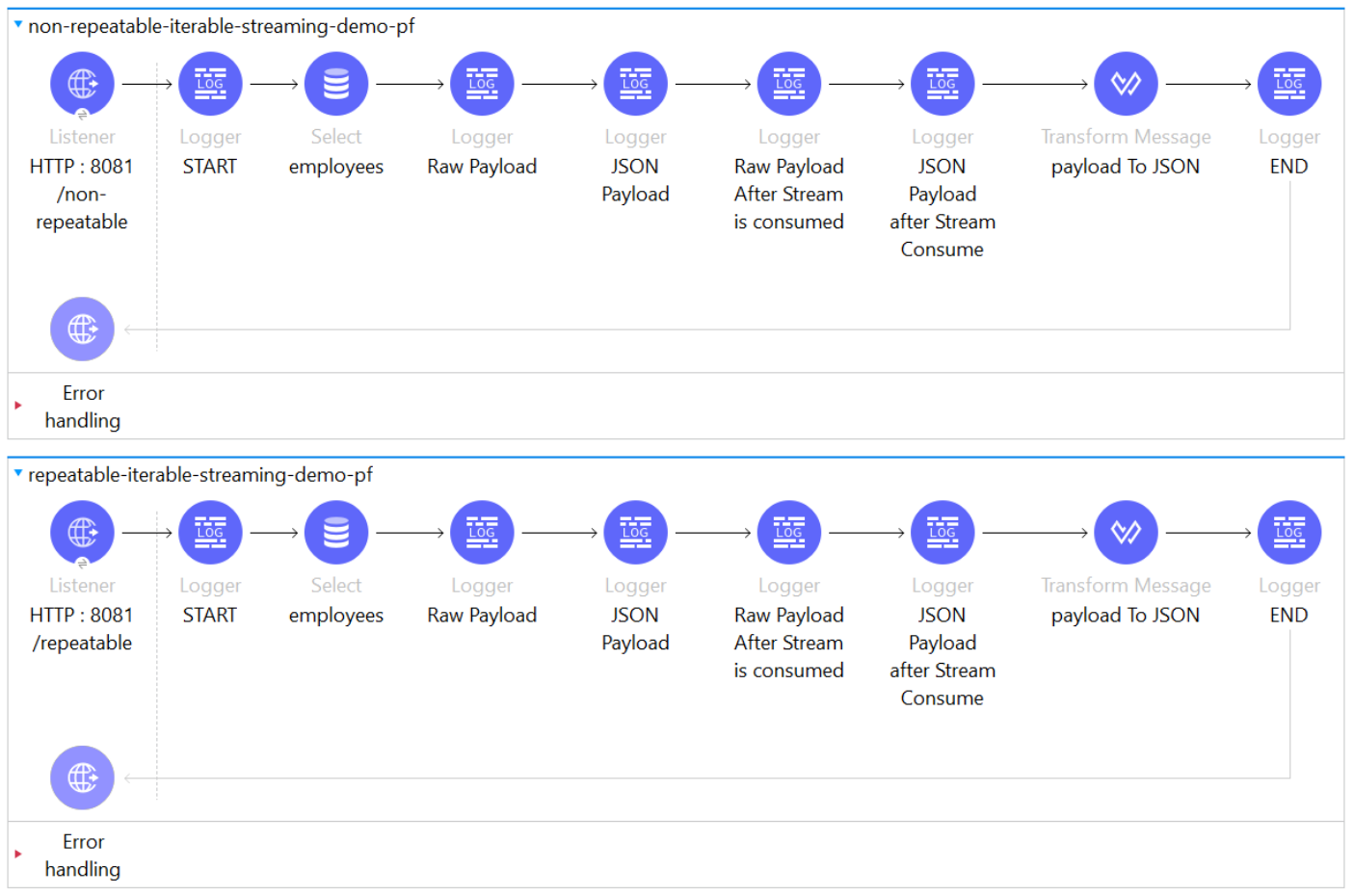
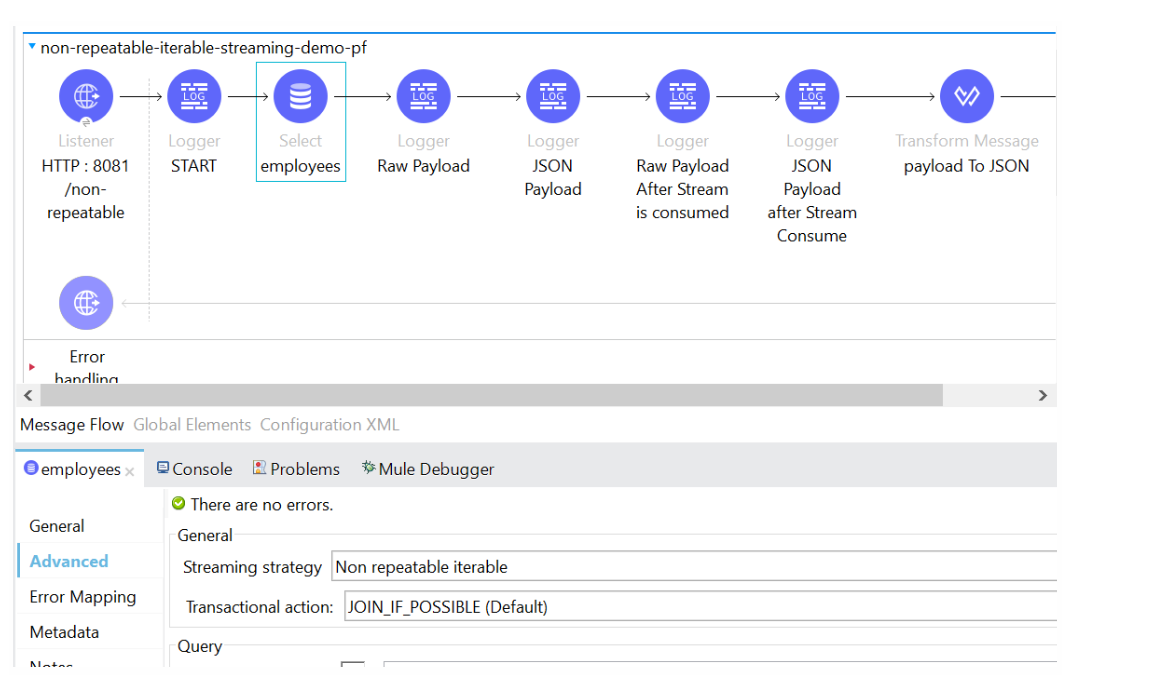
- We will be making use of the DB connectors to demonstrate the above concept
- We have two flows that are virtually the same flow only difference is that the first flow has the Streaming Strategy as Non-repeatable iterable, and the second flow has the Streaming Strategy as the Repeatable In-memory iterable configured in the DB Select Connector.
![non-repeatable-iterable]()
Now coming to the functionality part:
- We have a logger that prints the Raw Payload (w/o any transformation)
- We then have a logger that transforms the payload into JSON format (which would consume the stream)
- These are followed by the same set of loggers again to print the raw payload as well as the JSON payload.
Let’s analyze the logs rendered by both flow one by one, when triggered via POSTMAN, to note the difference b/w both the streaming strategies:
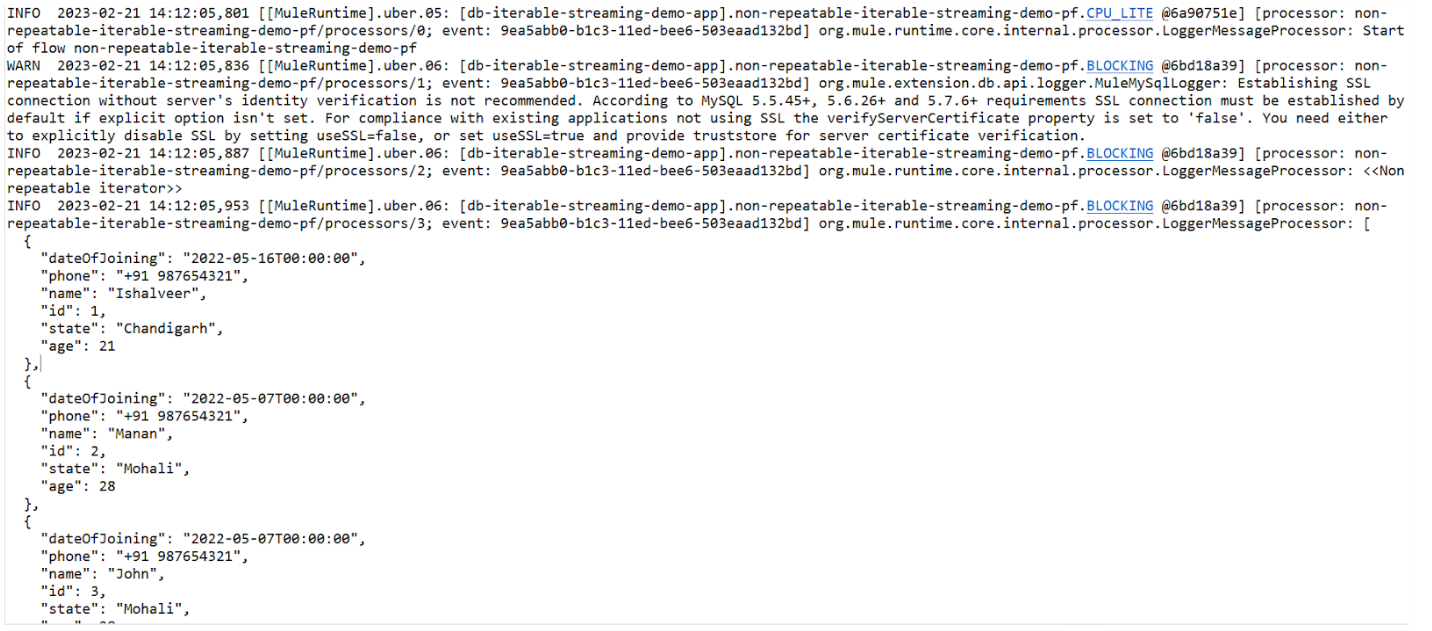

We see that on logging the raw payload, we get << Non-repeatable iterable>>. On logging the JSON payload, once we get the array of objects of records in the database, but the second time we do so, we get an empty array highlighting the fact that the stream had been consumed once and wasn’t available for consumption again.
Also, in the payload, we have the closed key that had the value false when the stream wasn’t consumed, but when it was consumed, the flag was turned to true,
Now let’s trigger the second flow to show repeatable streaming:
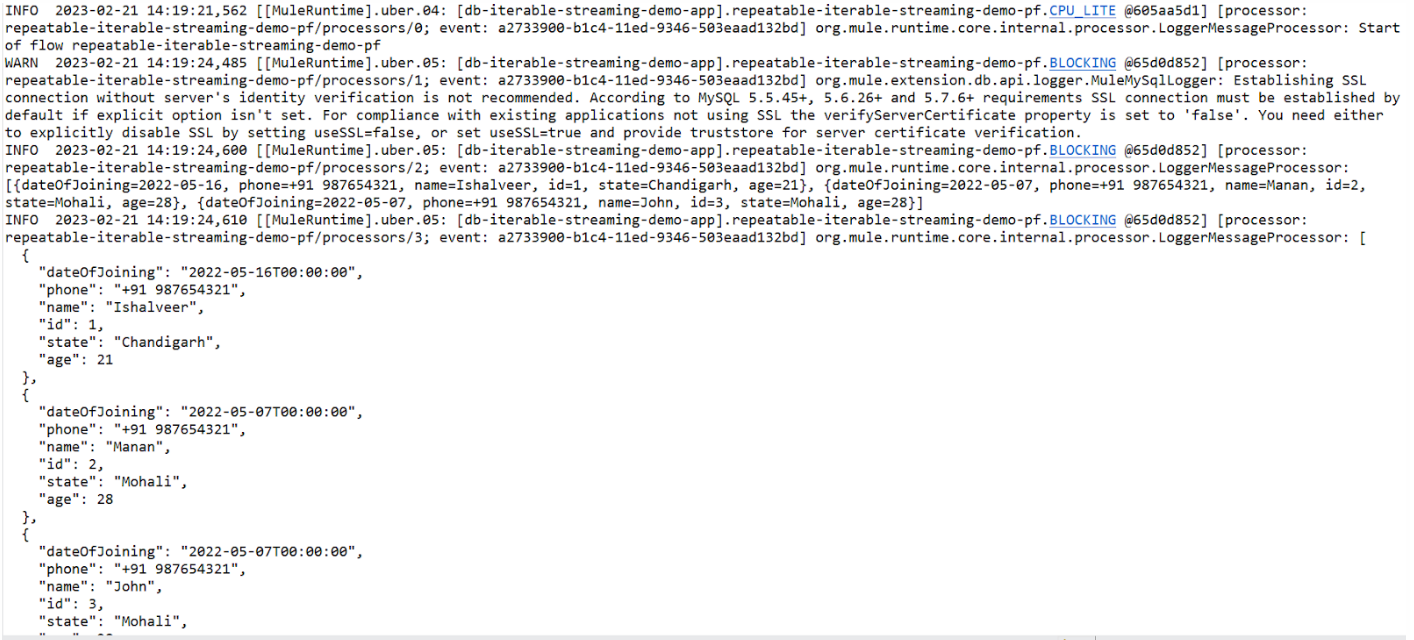
 We see that the array of objects of records from DB is printed twice, showing that it is available for consumption by subsequent processors.
We see that the array of objects of records from DB is printed twice, showing that it is available for consumption by subsequent processors.
Demo 2: Difference Between Repeatable In-memory and Repeatable File Stored Streaming
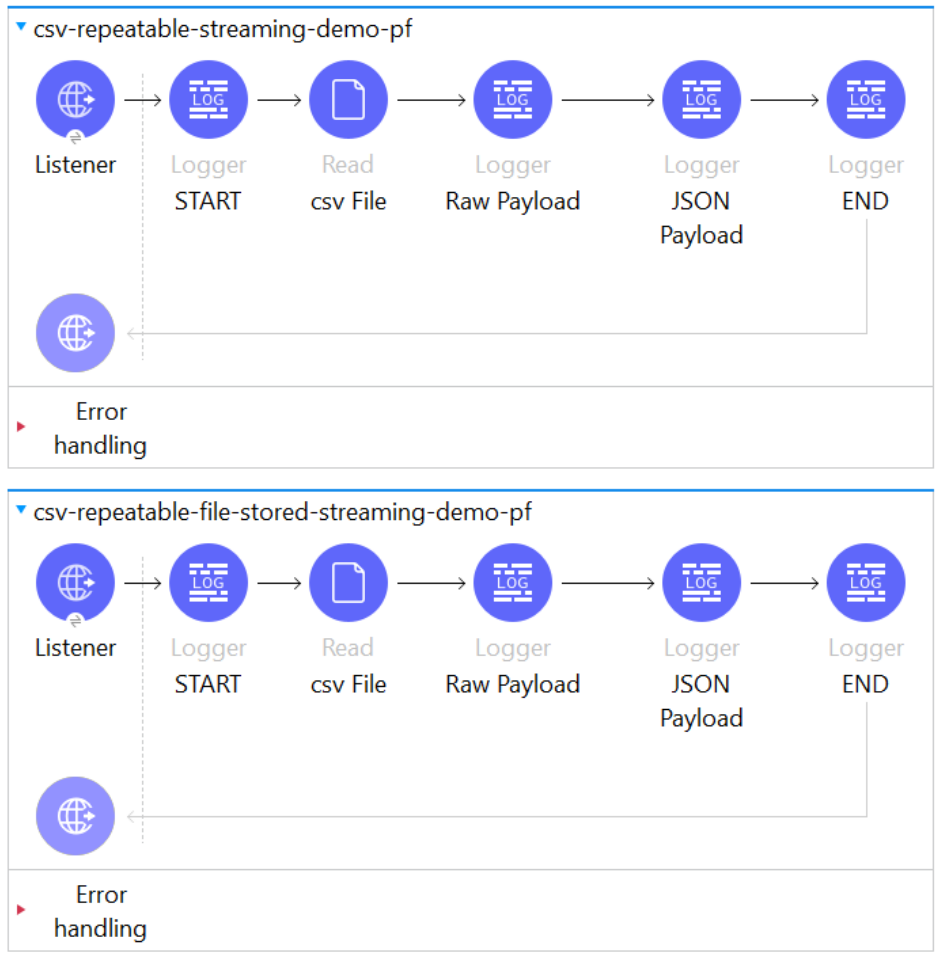
- We will be making use of the File Read Connectors to demonstrate the above concept.
- We have two flows that are virtually the same flow only difference is that the first flow has the Streaming Strategy as a Repeatable In-memory stream, and the second flow has the Streaming Strategy as the Repeatable file-stored stream configured in the File Read Connector.
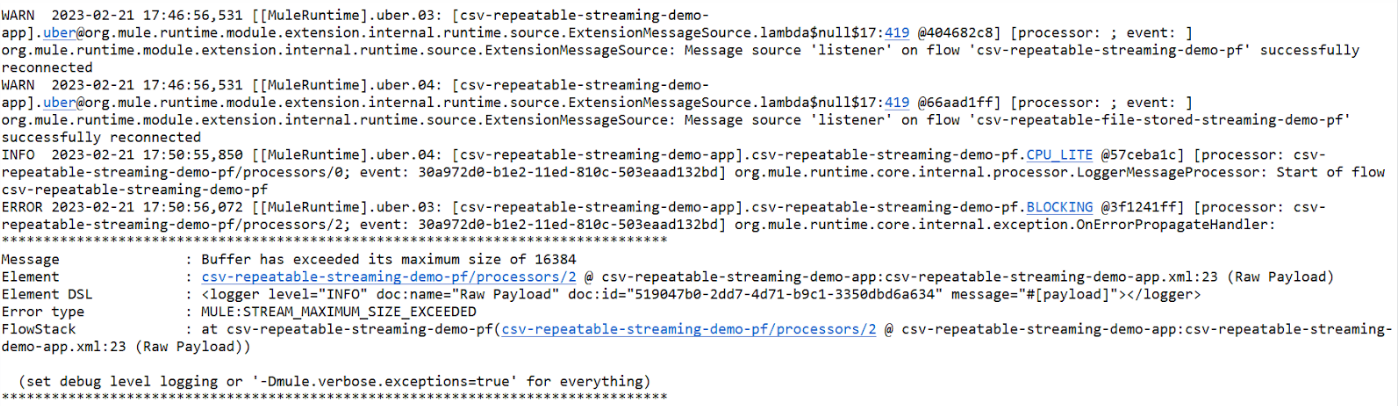
- In the first flow, while configuring the Repeatable in-memory stream, the Max Buffer Size has intentionally been kept as 16 KB with the Initial Buffer Size as 8 KB and Buffer Increment Size as 8 KB. This is done so that when processing a CSV file consisting of 1100 records of size 55 KB will lead to Heap memory being overloaded.
- This is depicted in the error below when the flow is triggered via POSTMAN.
![Error]()
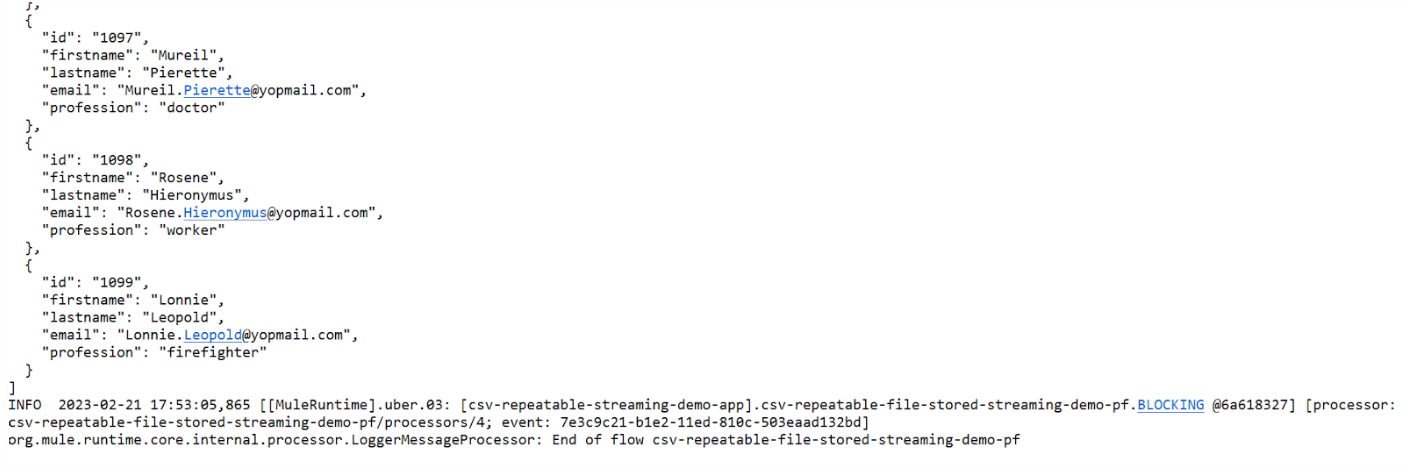
Moving on to the second flow, where the streaming strategy is a Repeatable File Stored Stream when triggered via POSTMAN, we will successfully execute the flow, hence demonstrating the convenience of a Repeatable File Stored Stream.
This sums up the three types of Streaming we have in Mule 4.
Published at DZone with permission of Ishalveer Singh Randhawa. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments