Step-by-Step Reasoning Can Fix Madman Logic in Vision AI
LlamaV-o1 outperforms Gemini-1.5-Flash and Claude-3.5-Sonnet on pattern recognition by explaining its reasoning process step by step.
Join the DZone community and get the full member experience.
Join For FreeVision AI models have a flaw. When shown a medical scan, they might correctly diagnose a condition while citing anatomically impossible reasons. Or they might solve a geometry problem with the right answer but skip essential theorems and rely on made-up ones instead. These models reach correct conclusions through reasoning that makes no sense.
The Gap in Visual Reasoning Models
This hints at a deeper problem. Current models don’t really think through visual problems — they pattern-match their way to answers. The LlamaV-o1 team discovered this by doing something simple: they forced their model to show its work. The results revealed that most visual reasoning errors don’t come from failing to see what’s in an image. They come from skipping key logical steps between seeing and concluding.
This gap between seeing and reasoning matters. A model that gets the right answer through wrong reasoning is like a student who memorizes solutions without understanding the principles. It will fail unpredictably when faced with new problems.
The solution turns out to require rethinking how we train these models. Today’s standard approach gives a model an image and question, then trains it to predict the correct answer. This works well enough to pass many benchmarks. But it’s like teaching a student to recognize answer patterns without understanding the underlying concepts, like training to answer physics problems by memorizing flashcards with the problem on the front and a single number, the answer, on the back.
LlamaV-o1’s Training Approach
LlamaV-o1, the top new vision question-answering paper on AIModels.fyi today, takes a different path. The training process is divided into two stages. In Stage 1, the model is trained simultaneously on summarization and caption generation using samples from the PixMo and Geo170K datasets. Stage 2 then builds upon this foundation to handle detailed reasoning and final answer generation using the Llava-CoT dataset.
Each reasoning step must be explicit and verifiable, so the model can’t take shortcuts. This mirrors the chain of thought approach common in many language models.

Figure 1 shows how LlamaV-o1 outperforms Gemini-1.5-Flash and Claude-3.5-Sonnet on a pattern recognition task from VRC-Bench. Claude-3.5-Sonnet picks “none of the options” but doesn’t fully match the observed logic. Gemini-1.5-Flash also shows weaker coherence. LlamaV-o1 identifies the correct option (D) by following the pattern, proving its stronger reasoning ability.
There are three key technical advances in this paper that I think are worth pointing out. First is the introduction of VRC-Bench, a comprehensive benchmark specifically designed to evaluate multi-step reasoning tasks. Second, is a novel metric that assesses visual reasoning quality at the granularity of individual steps. And, third is the curriculum learning approach with beam search optimization.

Figure 2 highlights the variety of tasks in VRC-Bench, each requiring step-by-step reasoning. The examples span geometry (calculating angles with linear pairs), chemistry (identifying ethane from its molecular structure), chart analysis (pie charts for global energy reserves), art recognition (identifying historical paintings), sports classification, medical diagnosis (classifying tissue types), and advertisement analysis (extracting product names). Each task forces the model to explain its logical steps, from understanding the prompt to arriving at the answer.
Let’s start by talking about curriculum learning with explicit reasoning supervision. The model trains in stages, mastering basic visual perception before attempting complex reasoning. At each stage, it must generate specific intermediate outputs — like describing what it sees, identifying relevant elements for the current question, and explaining each logical step. The training data contains over 4,000 manually verified reasoning steps to ensure the model learns valid reasoning patterns.
The second advance is an efficient implementation of beam search during inference. While generating each reasoning step, the model keeps track of multiple possible next steps rather than committing to the first one it thinks of. Most models avoid this due to computational costs. For example, Llava-CoT has linear scaling (O(n)) based on model calls. LlamaV-o1 improves upon this with a simplified beam search that achieves constant scaling (O(1)) while still exploring alternative reasoning paths effectively.
These mechanisms work together — curriculum learning teaches the model how to break down problems, while beam search helps it find valid reasoning paths efficiently. The result is a model that thinks more systematically without becoming impractically slow.
And then innovation three comes last — to test this approach properly, the team had to build a new kind of benchmark. Their VRC-Bench presents problems across eight domains, from basic visual tasks to complex medical diagnoses. But unlike standard benchmarks that check only final answers, VRC-Bench verifies each reasoning step. A model can’t pass by accident.
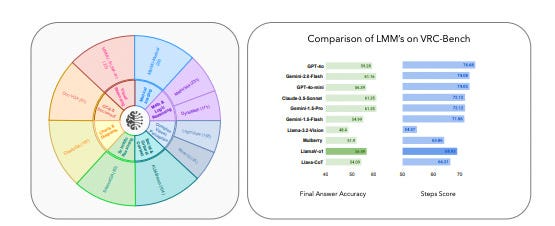
Figure 3 shows the new Visual ReasoningChain-Bench (VRC-bench), which spans math (MathVista, LogicVista), science (Science-QA), visual tasks (Blink-IQ-Test), medical imaging (MMMU-Medical), culture (ALM-Bench), documents (Doc-VQA), and charts (Chart-VQA). The bar chart compares final answer accuracy and reasoning quality across a bunch of models.
The results expose something fundamental about how AI systems learn to think. When forced to show their reasoning, most current models reveal alarming gaps where they skip necessary logical steps. LlamaV-o1 makes fewer such jumps, and when it fails, it usually fails at specific reasoning steps rather than producing mysteriously wrong conclusions.
Conclusion
I think this combination points to something important about the future of AI systems. Most current work focuses on making models faster or more accurate at producing answers. But I suspect that for truly complex tasks — the kind humans solve through careful reasoning — we’ll need models that can think methodically through each step. LlamaV-o1’s architecture suggests this might be possible without the huge computational costs many feared.
The approach will need testing beyond visual reasoning. Safety-critical domains like medical diagnosis or engineering seem like natural next steps to me — areas where we care more about reliable reasoning than speed. I wouldn’t be surprised if the techniques pioneered here end up being more valuable for their careful reasoning capabilities than for their computer vision advances.
What do you think? Let me know on Discord or in the comments. I’d love to hear what you have to say.
Published at DZone with permission of Mike Young. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments