Rust and ScyllaDB for Big Data
The IT industry is constantly evolving, including big data processing. ScyllaDB is a new player promising unprecedented performance and benchmark results.
Join the DZone community and get the full member experience.
Join For FreeDo you ever wonder about a solution that you know or you wrote is the best solution, and nothing can beat that in the years to come? Well, it’s not quite how it works in the ever-evolving IT industry, especially when it comes to big data processing. From the days of Apache Spark and the evolution of Cassandra 3 to 4, the landscape has witnessed rapid changes. However, a new player has entered the scene that promises to dominate the arena with its unprecedented performance and benchmark results. Enter ScyllaDB, a rising star that has redefined the standards of big data processing.
The Evolution of Big Data Processing
To appreciate the significance of ScyllaDB, it’s essential to delve into the origins of big data processing. The journey began with the need to handle vast amounts of data efficiently. Over time, various solutions emerged, each addressing specific challenges. From the pioneering days of Hadoop to the distributed architecture of Apache Cassandra, the industry witnessed a remarkable evolution. Yet, each solution presented its own set of trade-offs, highlighting the continuous quest for the perfect balance between performance, consistency, and scalability. You can check here at the official website for benchmarks and comparisons with Cassandra and Dynamo DB.
Understanding the Big Data Processing and NoSQL Consistency
Big data processing brought about a paradigm shift in data management, giving rise to NoSQL databases. One of the pivotal concepts in this realm is eventual consistency, a principle that allows for distributed systems to achieve availability and partition tolerance while sacrificing strict consistency. This is closely tied to the CAP theorem, which asserts that a distributed system can achieve only two out of three: Consistency, Availability, and Partition Tolerance. As organizations grapple with the complexities of this theorem, ScyllaDB has emerged as a formidable contender that aims to strike an optimal balance between these factors. You can learn more about the CAP Theorem in this video.
Fine-Tuning Performance and Consistency With ScyllaDB
ScyllaDB enters the arena with a promise to shatter the conventional limits of big data processing. It achieves this by focusing on two critical aspects: performance and consistency. Leveraging its unique architecture, ScyllaDB optimizes data distribution and replication to ensure minimal latency and high throughput. Moreover, it provides tunable consistency levels, enabling organizations to tailor their database behavior according to their specific needs. This flexibility empowers users to strike a harmonious equilibrium between data consistency and system availability, a feat that was often considered challenging in the world of big data.
The Rust Advantage
ScyllaDB provides support for various programming languages, and each has its strengths. However, one language that stands out is Rust. Rust’s focus on memory safety, zero-cost abstractions, and concurrency. Its robustness significantly reduces common programming errors, bolstering the overall stability of your application.
When evaluating the choice of programming language for your project, it’s essential to consider the unique advantages that Rust brings to the table, alongside other supported languages like Java, Scala, Node.js, and more. Each language offers its own merits, allowing you to tailor your solution to your specific development needs.
One Last Word About “ScyllaDB and Rust Combination”
Scylla with Rust brings together the performance benefits of the Scylla NoSQL database with the power and capabilities of the Rust programming language. Just as Apache Spark and Scala or Cassandra and Java offer synergistic combinations, Scylla’s integration with Rust offers a similar pairing of a high-performance database with a programming language known for its memory safety, concurrency, and low-level system control.
Rust’s safety guarantees make it a strong choice for building system-level software with fewer risks of memory-related errors. Combining Rust with Scylla allows developers to create efficient, safe, and reliable applications that can harness Scylla’s performance advantages for handling large-scale, high-throughput workloads. This pairing aligns well with the philosophy of leveraging specialized tools to optimize specific aspects of application development, akin to how Scala complements Apache Spark or Java complements Cassandra. Ultimately, the Scylla and Rust combination empowers developers to build resilient and high-performance applications for modern data-intensive environments.
Demo Time
Imagine handling a lot of information smoothly. I’ve set up a way to do this using three main parts. First, we keep making new users. Then, we watch this data using a Processor, which can change it if needed. Lastly, we collect useful insights from the data using Analyzers. This setup is similar to how popular pairs like Apache Spark and Scala or Cassandra and Java work together. We’re exploring how Scylla, a special database, and Rust, a clever programming language, can team up to make this process efficient and safe.
Set Up Scylla DB
services:
scylla:
image: scylladb/scylla
ports:
- "9042:9042"
environment:
- SCYLLA_CLUSTER_NAME=scylladb-bigdata-demo
- SCYLLA_DC=dc1
- SCYLLA_LISTEN_ADDRESS=0.0.0.0
- SCYLLA_RPC_ADDRESS=0.0.0.0Create a Data Generator, Processor, and Analyzer
mkdir producer processor analyzer
cargo new producer
cargo new processor
cargo new analyzerProducer
[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let uri = std::env::var("SCYLLA_CONTACT_POINTS")
.unwrap_or_else(|_| "127.0.0.1:9042".to_string());
let session = SessionBuilder::new()
.known_node(uri)
.compression(Some(Compression::Snappy))
.build()
.await?;
// Create the keyspace if It doesn't exist
session
.query(
"CREATE KEYSPACE IF NOT EXISTS ks WITH REPLICATION = \
{'class' : 'SimpleStrategy', 'replication_factor' : 1}",
&[],
)
.await?;
// Use the keyspace
session
.query("USE ks", &[],)
.await?;
// toTimestamp(now())
// Create a Table if doesn't exist
session
.query("CREATE TABLE IF NOT EXISTS ks.big_data_demo_table (ID UUID PRIMARY KEY, NAME TEXT , created_at TIMESTAMP)", &[],)
.await?;
loop {
let id = Uuid::new_v4();
let name = format!("User{}", id);
let name_clone = name.clone();
session
.query(
"INSERT INTO ks.big_data_demo_table (id, name, created_at) VALUES (?, ?, toTimestamp(now()))",
(id, name_clone),
)
.await?;
println!("Inserted: ID {}, Name {}", id, name);
let delay = rand::thread_rng().gen_range(1000..5000); // Simulate data generation time
sleep(Duration::from_millis(delay)).await;
}
}Processor
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let uri = std::env::var("SCYLLA_CONTACT_POINTS")
.unwrap_or_else(|_| "127.0.0.1:9042".to_string());
let session = SessionBuilder::new()
.known_node(uri)
.compression(Some(Compression::Snappy))
.build()
.await?;
let mut last_processed_time = SystemTime::now();
loop {
// Calculate the last processed timestamp
let last_processed_str = last_processed_time
.duration_since(SystemTime::UNIX_EPOCH)
.expect("Time went backwards")
.as_secs() as i64; // Convert to i64
let query = format!(
"SELECT id, name FROM ks.big_data_demo_table WHERE created_at > {} ALLOW FILTERING", last_processed_str);
// Query data
if let Some(rows) = session
.query(query, &[])
.await?
.rows{
for row in rows{
println!("ID:");
if let Some(id_column) = row.columns.get(0) {
if let Some(id) = id_column.as_ref().and_then(|col| col.as_uuid()) {
println!("{}", id);
} else {
println!("(NULL)");
}
} else {
println!("Column not found");
}
println!("Name:");
if let Some(name_column) = row.columns.get(1) {
if let Some(name) = name_column.as_ref().and_then(|col| col.as_text()) {
println!("{}", name);
} else {
println!("(NULL)");
}
} else {
println!("Column not found");
}
// Update the last processed timestamp
last_processed_time = SystemTime::now();
// Perform your data processing logic here
}
};
// Add a delay between iterations
tokio::time::sleep(Duration::from_secs(10)).await; // Adjust the delay as needed
}
}Analyzer
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let uri = std::env::var("SCYLLA_CONTACT_POINTS")
.unwrap_or_else(|_| "127.0.0.1:9042".to_string());
let session = SessionBuilder::new()
.known_node(uri)
.compression(Some(Compression::Snappy))
.build()
.await?;
let mut total_users = 0;
let mut last_processed_time = SystemTime::now();
loop {
// Calculate the last processed timestamp
let last_processed_str = last_processed_time
.duration_since(SystemTime::UNIX_EPOCH)
.expect("Time went backwards")
.as_secs() as i64; // Convert to i64
let query = format!(
"SELECT id, name, created_at FROM ks.big_data_demo_table WHERE created_at > {} ALLOW FILTERING", last_processed_str);
// Query data
if let Some(rows) = session
.query(query, &[])
.await?
.rows{
for row in rows{
println!("ID:");
if let Some(id_column) = row.columns.get(0) {
if let Some(id) = id_column.as_ref().and_then(|col| col.as_uuid()) {
total_users += 1;
if total_users > 0 {
println!("Active Users {}, after adding recent user {}", total_users, id);
}
} else {
println!("(NULL)");
}
} else {
println!("Column not found");
}
println!("Name:");
if let Some(name_column) = row.columns.get(1) {
if let Some(name) = name_column.as_ref().and_then(|col| col.as_text()) {
println!("{}", name);
} else {
println!("(NULL)");
}
} else {
println!("Column not found");
}
// Update the last processed timestamp
last_processed_time = SystemTime::now();
// Perform your data processing logic here
}
};
// Add a delay between iterations
tokio::time::sleep(Duration::from_secs(10)).await; // Adjust the delay as needed
}
}Now, Let's Run the Docker Compose
docker compose up -dValidate the POD state directly in VS Code with the Docker plugin.
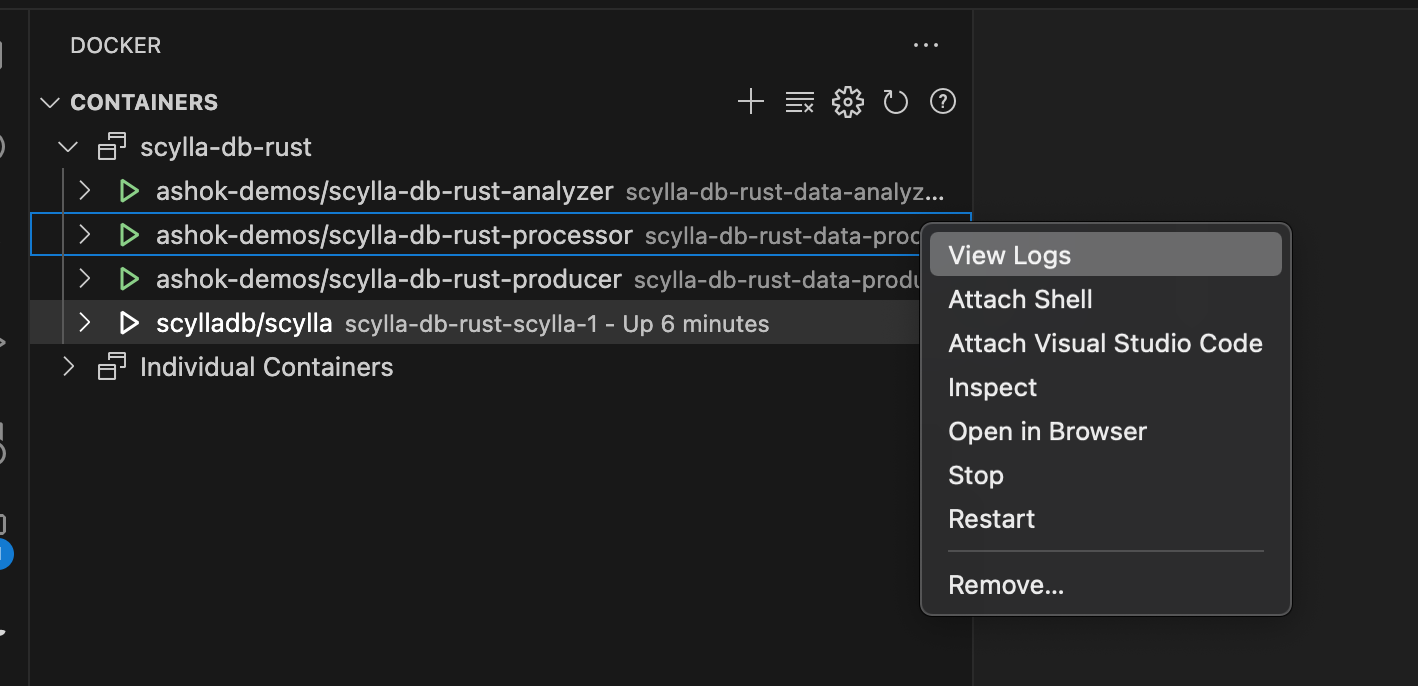
 Let us attach the logs in VS Code.
Let us attach the logs in VS Code.
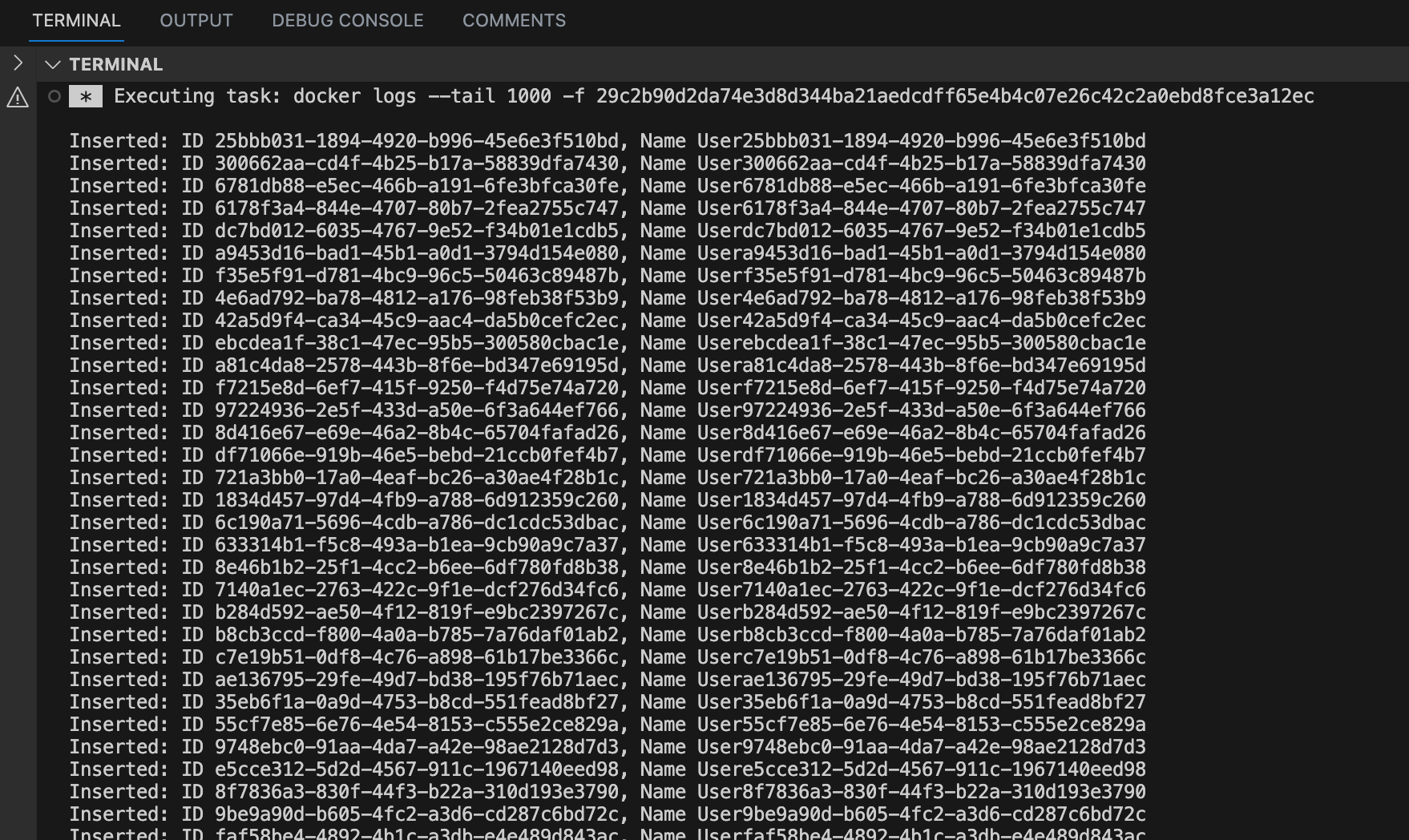
You should see the output below.
 Producer
Producer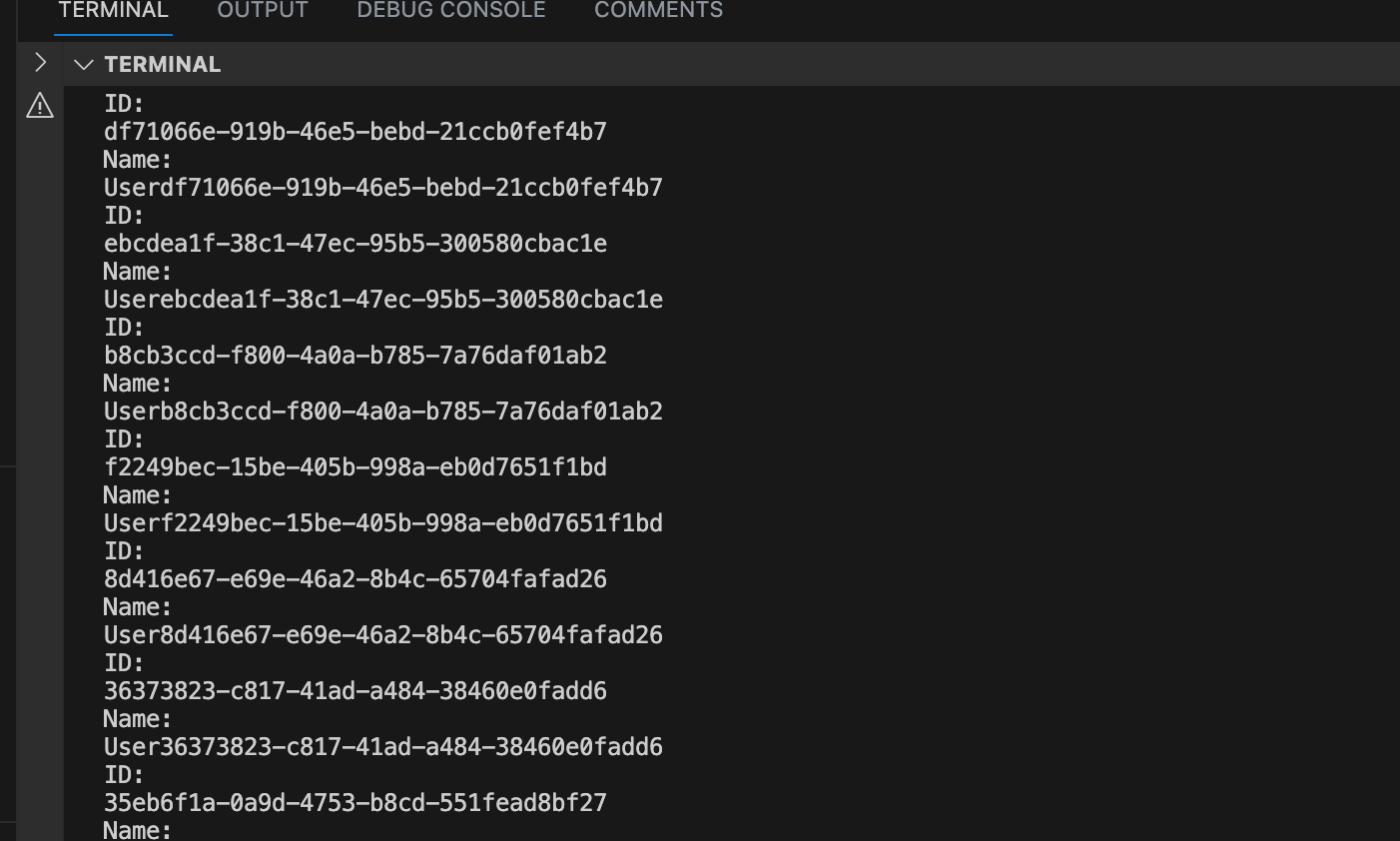
Summary
A New Chapter in Big Data Processing
In the relentless pursuit of an ideal solution for big data processing, ScyllaDB emerges as a trailblazer that combines the lessons learned from past solutions with a forward-thinking approach. By reimagining the possibilities of performance, consistency, and language choice, ScyllaDB showcases how innovation can lead to a new era in the realm of big data. As technology continues to advance, ScyllaDB stands as a testament to the industry’s unwavering commitment to elevating the standards of data processing and setting the stage for a future where excellence is constantly redefined.
That’s all for now, Happy Learning!
Published at DZone with permission of Ashok Gudise. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments