A Developer's Guide to Modern Queue Patterns
Queue patterns help build reliable distributed systems. They manage data flow, handle failures, and scale processing effectively.
Join the DZone community and get the full member experience.
Join For FreeIn today’s distributed systems, queues serve as the backbone of reliable, scalable architectures. They’re not just simple data structures — they’re powerful tools that help manage system load, ensure reliability, and maintain data consistency across complex distributed applications. This comprehensive guide explores the most important queue patterns that solve real-world problems in modern software architecture.
The Basics: What’s a Queue?
Think of a queue like a line at a coffee shop. People join the line at one end and get served at the other end, following the First-In-First-Out (FIFO) principle. In software, queues work the same way - they store messages or tasks that need to be processed in order. However, modern queue implementations go far beyond this simple concept, offering sophisticated features for handling complex scenarios.
A queue provides several key benefits in distributed systems:
- Decoupling of components
- Load leveling and buffering
- Asynchronous processing
- Improved system resilience
- Better scalability
- Predictable system behavior under load
Essential Queue Patterns
1. Dead Letter Queue (DLQ)
Dead Letter Queues are the safety nets of distributed systems. When messages can’t be processed successfully, they’re moved to a DLQ for analysis and potential reprocessing. This pattern is crucial for maintaining system reliability and debugging issues in production.
Implementation Considerations
Main Queue Configuration:
- Max retry attempts: 3
- Retry delay: Exponential backoff
- Failed message destination: DLQ
- Message metadata: Original queue, timestamp, error details
DLQ Handler:
- Alert on new messages
- Store failure context
- Provide retry mechanism
- Track failure patterns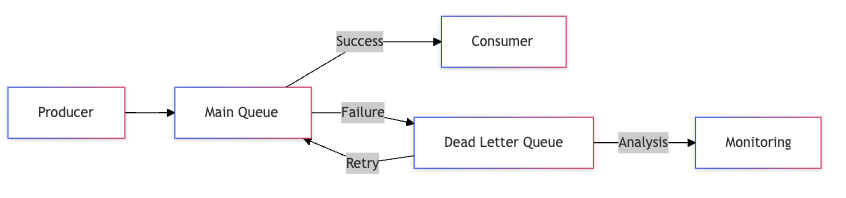
Real-World Applications
- Payment processing systems moving failed transactions to manual review
- E-commerce order processing where item validation fails
- Data integration pipelines handling malformed data
- Message transformation services dealing with unexpected formats
Best Practices for DLQ
- Always include original message metadata
- Implement automated monitoring and alerting
- Create tools for message inspection and reprocessing
- Set up retention policies based on business needs
- Track common failure patterns for system improvement
2. Priority Queue
Priority queues ensure critical messages are processed first, making them essential for systems where timing and message importance vary significantly. They help maintain service quality under load by ensuring important tasks don’t get stuck behind less critical ones.
Structure and Implementation
Queue Levels:
Critical (Priority 1):
- System alerts
- Emergency notifications
- Critical user operations
High (Priority 2):
- User-facing operations
- Time-sensitive tasks
- Financial transactions
Normal (Priority 3):
- Regular operations
- Background tasks
- Batch processing
Low (Priority 4):
- Analytics
- Reporting
- Data archiving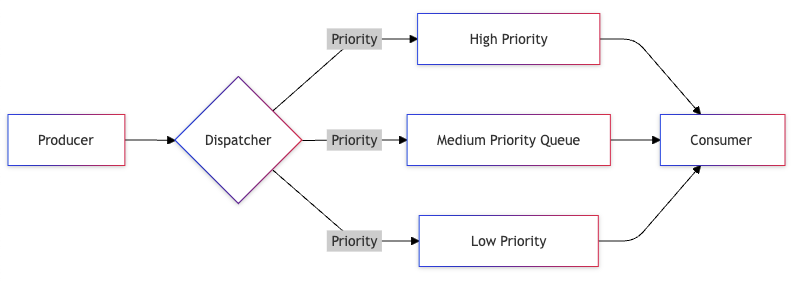
Key Considerations
- Dynamic priority adjustment based on waiting time
- Priority inheritance for related messages
- Resource allocation across priority levels
- Starvation prevention for low-priority messages
- Monitoring and alerting per priority level
Implementation Strategies
- Multiple physical queues with priority-based polling
- Single queue with priority-based message selection
- Hybrid approach with priority batching
- Dynamic consumer scaling based on priority loads
3. Delay Queue
Delay queues provide powerful scheduling capabilities, enabling systems to process messages at specific times in the future. They’re essential for building time-based features and implementing sophisticated retry mechanisms.
Common Use Cases
- Scheduled notifications and reminders
- Delayed order processing (pre-orders, scheduled deliveries)
- Cool-down periods after specific actions
- Time-based workflow transitions
- Scheduled system maintenance tasks
Implementation Approaches
Message Structure:
{
payload: <message content>,
processAfter: <timestamp>,
attempts: <retry count>,
backoffStrategy: <exponential/linear/custom>
}
Queue Management:
- Sorted by processing time
- Regular polling for due messages
- Efficient message retrieval
- Handle timezone considerations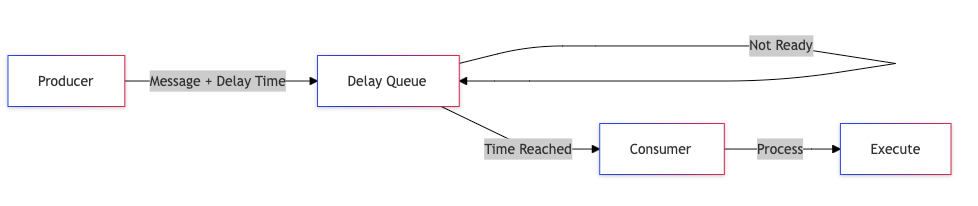
Advanced Features
- Message rescheduling
- Batch scheduling
- Recurring schedules
- Priority-based delayed processing
- Time window restrictions
4. Fan-Out Queue
Fan-out queues enable parallel processing and system decoupling by distributing messages to multiple consumers. This pattern is crucial for building scalable, maintainable systems where one event triggers multiple independent actions.
Architecture Components
Publisher:
- Message validation
- Routing logic
- Delivery guarantees
Exchange/Router:
- Message duplication
- Consumer management
- Routing rules
Consumers:
- Independent processing
- Error handling
- Scale independently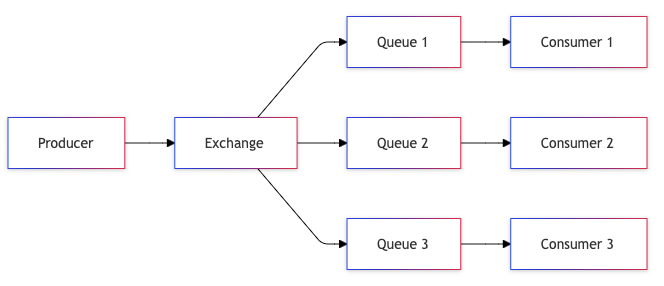
Implementation Considerations
- Message ordering requirements
- Partial failure handling
- Consumer scaling strategies
- Monitoring and tracking
- Resource management
Real-World Examples
- Social media post distribution to followers
- Multi-channel notification systems
- Data replication across services
- Event-driven analytics and logging
- Cross-service workflow orchestration
5. Work Pool Pattern
The Work Pool pattern enables efficient parallel processing by distributing tasks across multiple workers. This pattern is essential for scaling systems and maintaining consistent performance under varying loads.
Detailed Implementation
Pool Management:
- Worker registration
- Health monitoring
- Load balancing
- Task distribution
Worker Configuration:
- Processing capacity
- Specialization
- Resource limits
- Retry behavior
Task Handling:
- Priority support
- Progress tracking
- Result aggregation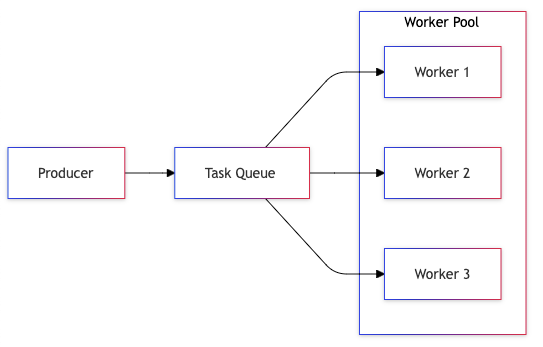
Advanced Features
- Dynamic worker scaling
- Specialized worker pools
- Work stealing algorithms
- Resource-aware distribution
- Progress monitoring and reporting
Real-World Applications
- Image/video processing pipelines
- Batch data processing
- Report generation
- Data import/export operations
- Distributed calculations
Best Practices
1. Message Idempotency
Idempotency is crucial for reliable message processing. Here’s how to implement it effectively:
Key Strategies
- Use unique message identifiers
- Maintain processing history
- Implement deduplication logic
- Handle partial processing
- Design for concurrent processing
Implementation Example
Message Processing:
1. Generate unique message ID
2. Check processing history
3. Apply idempotency key
4. Process message
5. Record completion
6. Handle duplicates2. Queue Monitoring
Comprehensive monitoring ensures system health and performance. Essential metrics to track:
System-Level Metrics
- Queue depth and growth rate
- Processing throughput
- Error rates and patterns
- Consumer health and scaling
- Resource utilization
Business-Level Metrics
- Processing latency
- Message age distribution
- Priority level statistics
- Business impact metrics
- SLA compliance
3. Smart Retry Logic
Implement sophisticated retry mechanisms for reliable message processing:
Retry Strategies
Basic Exponential:
1st: 5 seconds
2nd: 25 seconds
3rd: 125 seconds
Advanced Pattern:
- Initial delay: 1s
- Max delay: 1 hour
- Jitter: ±10%
- Max attempts: Business-specific
- Circuit breaker integrationConsiderations
- Business requirements
- Resource constraints
- Downstream system capacity
- Error types and handling
- Monitoring and alerting
4. Message TTL Management
Effective Time-to-Live (TTL) policies ensure system health:
Implementation Guidelines
- Business-driven TTL values
- Different TTLs per message type
- Automated cleanup processes
- TTL extension mechanisms
- Archival strategies
Best Practices
- Regular TTL review
- Monitoring and alerting
- Cleanup automation
- Policy documentation
- Stakeholder communication
Conclusion
Queue patterns are fundamental building blocks of modern distributed systems. They provide powerful solutions for common distributed computing challenges while enabling scalability, reliability, and maintainability. When implementing these patterns, consider your specific use case, scalability requirements, and maintenance capabilities. Start with simple implementations and evolve based on real usage patterns and requirements.
Remember that successful queue implementation requires careful consideration of:
- System requirements and constraints
- Scalability needs
- Maintenance capabilities
- Monitoring and observability
- Business continuity requirements
By understanding and correctly implementing these patterns, you can build robust, scalable systems that effectively handle real-world complexity while maintaining system reliability and performance.
Opinions expressed by DZone contributors are their own.
Comments