Personalized Customer Engagement Leveraging Knowledge Graphs for Grounding LLMs
This article will cover a Gen-AI application for email engagement customer scenarios using Knowledge Graph grounding on LLMs.
Join the DZone community and get the full member experience.
Join For FreeGenerative AI, with Large Language Models (LLMs) proved a powerful catalyst by pacing up the race of Artificial Intelligence across industries by enabling systems process, understand, generate, and manipulate human language in a way that was previously thought to be beyond the reach of machines.One amazing business application of Gen-AI in real-world enterprises applications is the customer engagement through generating personalized content that could effectively target customer, impress them and ultimately driving more revenues.Personalized Customer Experience is a powerful tool enterprises are leveraging today to create more tailored engagement for the customers through various engagement channels like emails, SMS, Phone, address, applications and advertising. If we can blend in the use-cases of generative-AI, that would be delivering true value of personalized experiences. In this article, We will cover a gen-AI application for Email engagement Customer scenario using Knowledge Graph grounding on LLMs.

Retrieval-Augmented Generation(RAG) refers to the technique of grounding the LLMs with factual, accurate and contextual data from knowledge sources to retrieve more quality responses. This greatly helps in overcoming the hallucinations and bias.
Prompt is a text-based input that you provide to initiate a conversation with the Open Gen-AI systems like ChatGPT, Cohere…
Grounding enriches the prompt by adding more context, scope, details and history of the customer journey with the enterprise to improve and provide more tailored and accurate personalized customer content. Research on LLMs shows that the quality of their response depends on the quality of the prompt provided to them.
In addition, Enterprises can also leverage grounding adding data masking/de-masking techniques and zero data retention policies on prompts to adhere to customer data protection and privacy policies.
Building LLMs Ground-Up Is Expensive for Enterprises
Enterprises thrive to induce, inject LLMS into their mission-critical applications. They understand the potential value they could benefit across a wide range of customer scenarios. Building LLMs, collecting all data, cleansing, storing, modeling, training and fine-tuning the models is quite expensive and cumbersome for them. Rather, they could use the open-AI systems available in the industry responsibly with appropriate grounding and masking techniques to overcome issues around data leaks, hallucinations, and compliance.
Example: Personalized Customer Email Engagement
Let us analyze an example of how well the grounded prompt improves a personalized recommendation E-Mail for a customer.
Assume an Enterprise Atagona.com trying to send a custom E-Mail to all of its qualified customers with few personalized product recommendations. Lets observe the generated responses from OpenAI with both basic vs grounded prompts.
Scenario-1
Basic prompt: Generate a short email adding coupons on recommended products to customer.
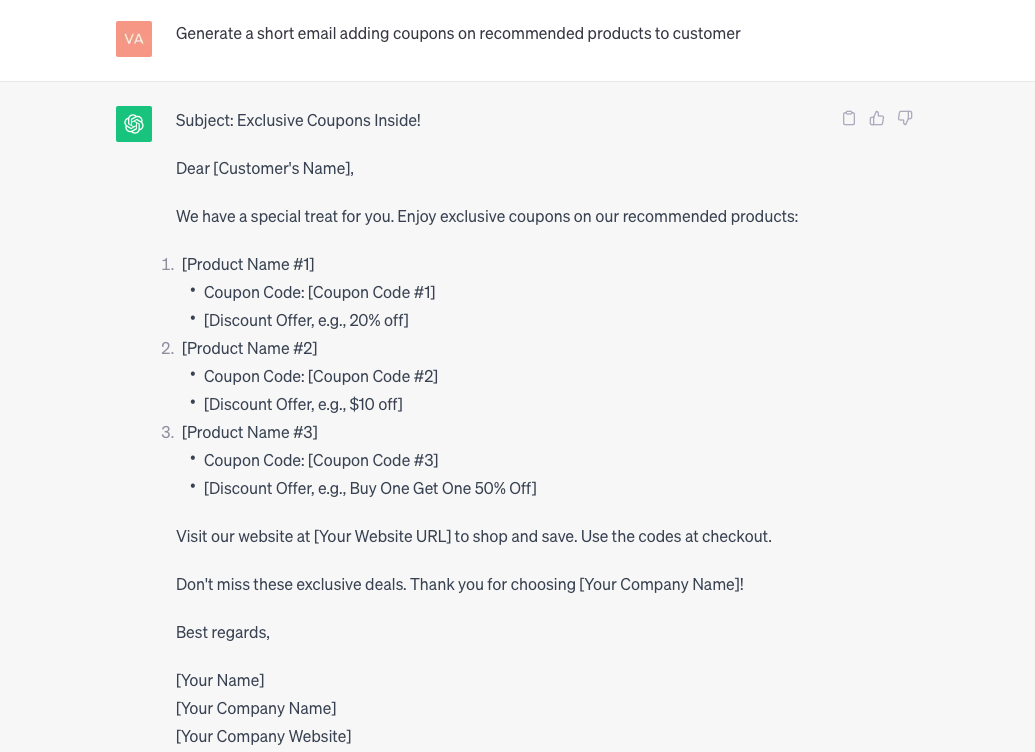
This response generated for a basic prompt by ChatGPT is very generic, non-contextualized, and raw and seems like more of a template. This needs to be further updated/mapped with the right enterprise customer data which is expensive. We are not leveraging generative AI to full stretch here as there is no detailed information/metadata provided around the prompt. Let’s see how this could be automated with data grounding techniques.
Scenario-2
Say, suppose the enterprise already holds the enterprise customer data and an intelligent recommendation system that can generate coupons and recommendations for the customers, we could very well ground the above prompt by enriching it with the right metadata so that the generated email text from chatGPT would be exactly same as how we want it to be automated to E-Mail to the customer without manual intervention.Let’s assume our grounding engine is going to obtain the right enrichment metadata from customer data and update the prompt as below. Let’s see how the chatGPT response for the grounded prompt would be.
Grounded Prompt: Generate a short email adding below coupons and products to customer Taylor and wish him a happy holiday season from Team Aatagona:
- Atagona.comWinter Jacket Mens — [atagona jackets] — 20% off
- Rodeo Beanie Men’s — [atagona beanies] — 15% off
Image from OpenAI-ChatGPTWOWiee!!! A personalized E-Mail message with personalized product recommendations!!
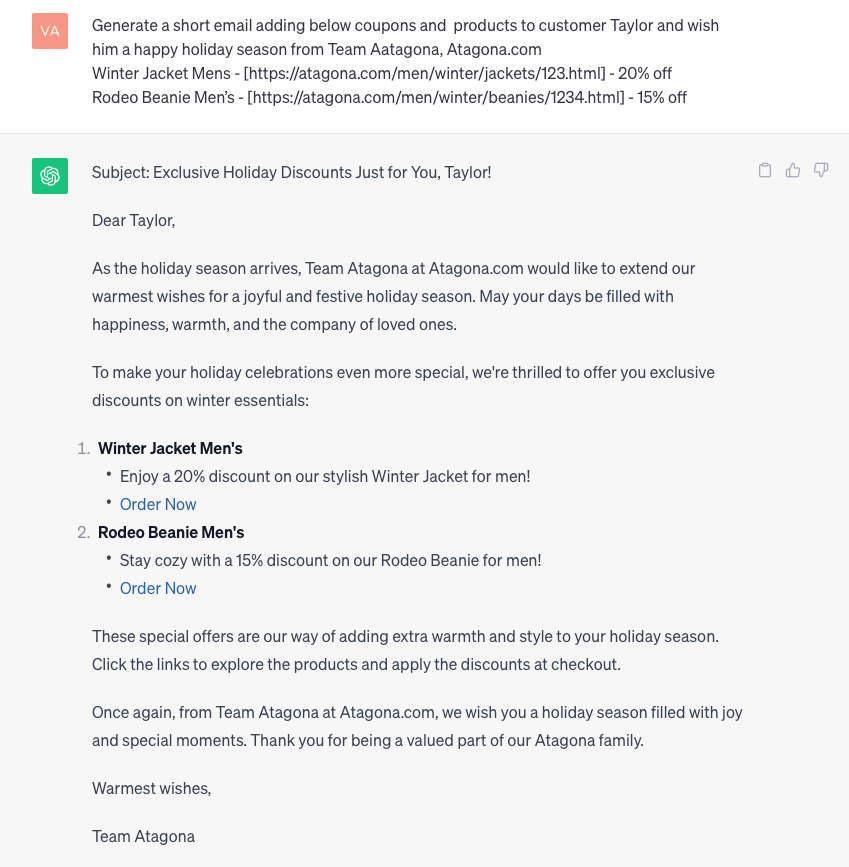 Image from OpenAI-ChatGPTWOWiee!!! A personalized E-Mail message with personalized product recommendations!!
Image from OpenAI-ChatGPTWOWiee!!! A personalized E-Mail message with personalized product recommendations!!This response generated with the grounded prompt is perfect, exactly how the enterprise would want the customer to be notified with. It generated message with details like season, appropriate wishes, personalized products, their links, deals, addressing customer with the name etc. This justifies being truly personalized.How can Enterprises achieve Data Grounding?Two frontrunners for Grounding LLMsThere are multiple ways to ground the data in enterprise systems and a combination of these techniques could be used for effective data grounding and prompt generation specific to the use case. The two primary contenders as potential solutions for implementing retrieval augmented generation(grounding) are:
- Application Data|Knowledge graphs
- Vector embeddings and semantic searchUsage of these solutions would depend really on the use case, and the type of grounding you want to apply. For example, vector stores responses can be inaccurate and vague and are relevant to unstructured data whereas knowledge graphs would return precise, accurate, and also stored in a human-readable format and are relevant on structured data.In this blog, let’s take a look at a sample software design on how this can be achieved with enterprise application data graphsEnterprise Knowledge|Data graphsEnterprise Knowledge graphs enable graph-based search on customer data sources, allowing users to explore information through linked concepts of nodes as entities and edges as relationships among entities.Comparison with Vector DatabasesChoosing the grounding solution would be use-case-specific. However, there are multiple advantages with graphs over vectors like:

High-Level Design
Let us see on a very high level how the system can look for an enterprise that uses knowledge graphs and open LLMs for grounding.
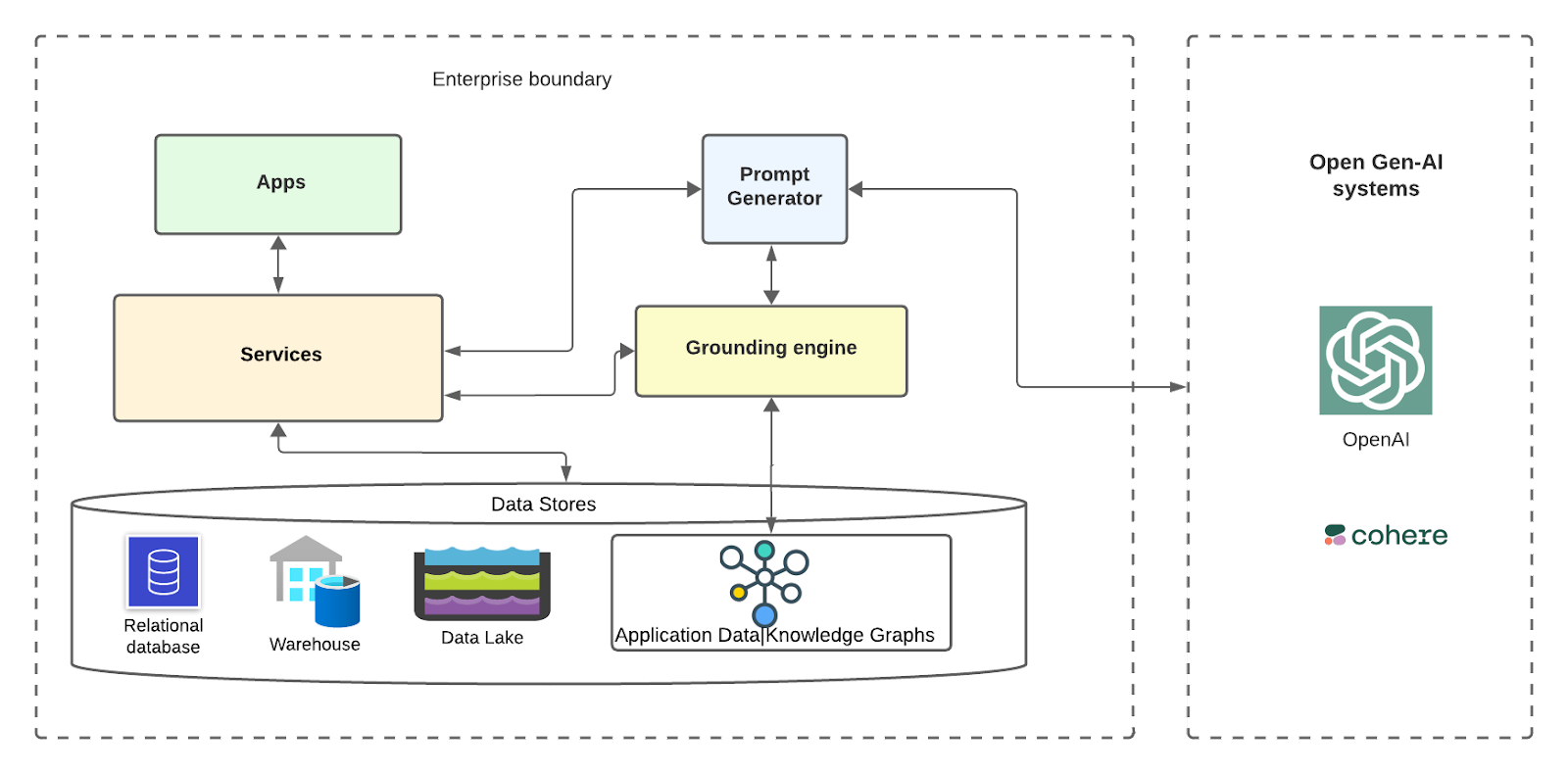
The base layer is the storage where enterprise customer data and metadata are stored across various types of databases, data warehouses, and data lakes. There can be a service building the data knowledge graphs out of this data and storing it in a graph db. There can be numerous enterprise services|micros services in a distributed cloud native world that would interact with these data stores. Above these services could be various applications that would leverage the underlying infra.
Apps for leveraging Gen-AI, can integrate with APIs from OpenAI systems by properly grounding the prompts via prompt generator, grounding engine and knowledge graphs. Grounding engine can further have multiple components which we cover in the flow below.
The Flow: Scenario Decoded!

- Enterprise Workflow application wants to send a personalized email to the customer with the content generated by open Gen-AI systems by sending a grounded prompt with customer contextualized data.
- The workflow application would send a request to its backend service to obtain the email text leveraging GenAI systems.
- Backend service would route the service to a prompt generator service, which in turn routes to a grounding engine.
- The grounding engine grabs all right metadata of the customer from one of its services and retrieves the customer data knowledge graph
- The grounding engine traverses the graph across the nodes and relevant relationships extracts the ultimate information required, masks the PII (Personal data) and sends it back to the prompt generator
- The prompt generator adds the grounded data with the pre-existing template for the use case and sends the grounded prompt to the open AI systems that the enterprise chooses to integrate with(eg: OpenAI/Cohere)
- Open Gen-AI systems return a much more relevant and contextualized response to the enterprise.
- Grounding engine demasks the response, passes it through the data compliance engine for filtering the response for any bias, unwanted data before sending back to workflow application.
- Workflow application automatically sends the response to the customer via E-Mail.
Coming to the Knowledge graph modeling, Let’s break into two parts to understand in detail: Data modeling and Graph modeling.
1. Data Modeling
Assume we have structured data stored across tables that hold data for all entities involved. For the above personalized customer email engagement scenario, we can have 4 tables to hold:
- Customers details
- Product details
- CustomerInterests(Clicks) Engagement data for personalized recommendations
- ProductDiscounts detail
Enterprises would collect all of this data ingested from multiple data sources and updated regularly to effectively reach customers. Links between tables could be analogous to the foreign key relations in relational world.

2. Knowledge Graph Modeling
The above entities or tables data could be modeled as graph nodes and join between tables as edges or relationships between entities. Sample graph representation for couple of records in a graph format could be visualized as below.
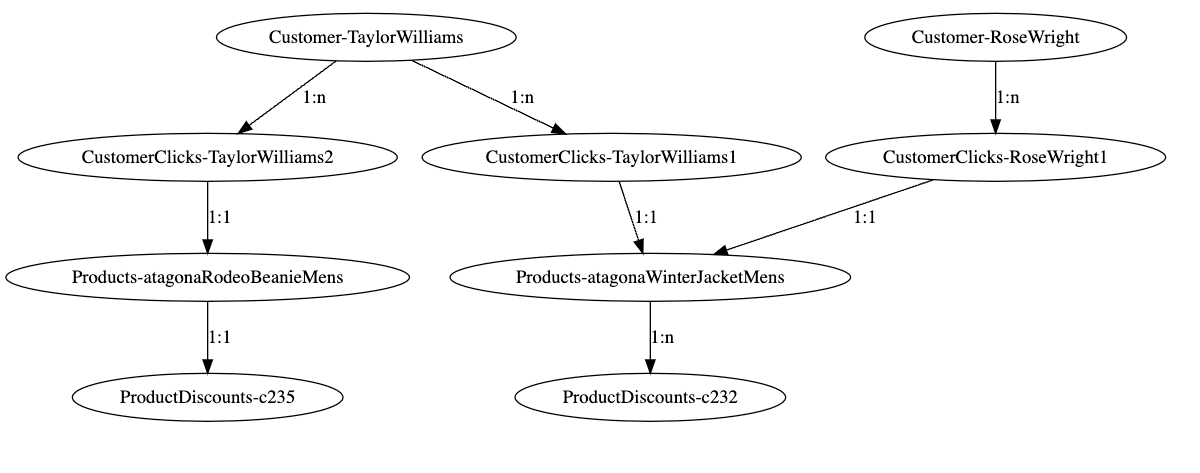
From the above graph visualizer, we can see how customer nodes are related to various products based on their clicks engagement data and further to the discounts nodes. It’s easy for the grounding service to query these customer graphs, traverse these nodes through relationships, and obtain the required information around discounts eligible to respective customers very performantly in a graph query language.
In the above grounded prompt scenario, Traversing through the graph from customer node ‘Taylor Williams’ would solve the problem for us and fetch the right product recommendations along with the eligible discounts.
public class KnowledgeGraphNode implements Serializable {
private final GraphNodeType graphNodeType;
private final GraphNode nodeMetadata;
}
public interface GraphNode {
}
public class CustomerGraphNode implements GraphNode {
private final String name;
private final String customerId;
private final String phone;
private final String emailId;
}
public class ClicksGraphNode implements GraphNode {
private final String customerId;
private final int clicksCount;
}
public class ProductGraphNode implements GraphNode {
private final String productId;
private final String name;
private final String category;
private final String description;
private final int price;
}
public class ProductDiscountNode implements GraphNode {
private final String discountCouponId;
private final int clicksCount;
private final String category;
private final int discountPercent;
private final DateTime startDate;
private final DateTime endDate;
}
public class KnowledgeGraphRelationship implements Serializable {
private final RelationshipCardinality Cardinality;
}
public enum RelationshipCardinality {
ONE_TO_ONE,
ONE_TO_MANY
}A sample graph node and relationship JAVA POJOs for the above could look similar to the one below.
public class KnowledgeGraphNode implements Serializable {
private final GraphNodeType graphNodeType;
private final GraphNode nodeMetadata;
}
public interface GraphNode {
}
public class CustomerGraphNode implements GraphNode {
private final String name;
private final String customerId;
private final String phone;
private final String emailId;
}
public class ClicksGraphNode implements GraphNode {
private final String customerId;
private final int clicksCount;
}
public class ProductGraphNode implements GraphNode {
private final String productId;
private final String name;
private final String category;
private final String description;
private final int price;
}
public class ProductDiscountNode implements GraphNode {
private final String discountCouponId;
private final int clicksCount;
private final String category;
private final int discountPercent;
private final DateTime startDate;
private final DateTime endDate;
}
public class KnowledgeGraphRelationship implements Serializable {
private final RelationshipCardinality Cardinality;
}
public enum RelationshipCardinality {
ONE_TO_ONE,
ONE_TO_MANY
}A sample raw graph in this scenario could look like below.
1 [label="Customer-TaylorWilliams" nodeType="Customer" name="Taylor Williams" customerId="TaylorWilliams" phone="123–456–7890" emailId="william.johnson@williamTrade.com"];
2 [label="CustomerClicks-TaylorWilliams1" nodeType="CustomerClicks" customerId="TaylorWilliams" productId="333" clicksCount="3" ];
3 [label="CustomerClicks-TaylorWilliams2" nodeType="CustomerClicks" customerId="TaylorWilliams" productId="335" clicksCount="2" ];
4 [label="Products-atagonaWinterJacketMens" nodeType="Products" productId="333" name="atagonaWinterJacketMens" category="w-1" description="Atagona Winter Jacket Mens"];
5 [label="Products-atagonaRodeoBeanieMens" nodeType="Products" productId="335" name="atagonaRodeoBeanieMens" category="w-2" description="Atagona Rodeo Beanie Mens"];
6 [label="ProductDiscounts-c232" nodeType="ProductDiscounts" discountCouponId="c232" clicksCount="3" category="w-1" discountPercent="15" startDate="2023–10–22T21:13:05Z" endDate="2023–12–28T21:13:05Z"];
7 [label="ProductDiscounts-c235" nodeType="ProductDiscounts" discountCouponId="c235" clicksCount="2" category="w-1" discountPercent="10" startDate="2023–10–22T21:13:05Z" endDate="2023–12–28T21:13:05Z"];
8 [label="Customer-RoseWright" nodeType="Customer" name="Rose Wright" customerId="RoseWright" phone="121–456–7890" emailId="rose.wright@williamTrade.com"];
9 [label="CustomerClicks-RoseWright1" nodeType="CustomerClicks" customerId="RoseWright" productId="333" clicksCount="3" ];
1 -> 2 [label="1:n" cardinality="OneToMany" ];
1 -> 3 [label="1:n" cardinality="OneToMany" ];
2 -> 4 [label="1:1" cardinality="OneToOne" ];
3 -> 5 [label="1:1" cardinality="OneToOne" ];
4-> 6 [label="1:n" cardinality="OneToMany" ];
5 -> 7 [label="1:1" cardinality="OneToOne" ];
8 -> 9 [label="1:n" cardinality="OneToMany" ];
9 -> 4 [label="1:1" cardinality="OneToOne" ];
}3. Popular Graph Stores in Industry
There are numerous graph stores available in the market that can suit enterprise architectures.
Neo4j, TigerGraph, Amazon Neptune, Stardog, and OrientDB are widely adopted as graph databases.
A new paradigm of Graph Data Lakes is here, which doesn’t require materialization in graph format in graph db rather enables graph queries on tabular data (structured data in lakes, warehouses, and lakehouses). This is achieved with new solutions listed below, without the need to hydrate or persist data in graph data stores, leveraging Zero-ETL.
- PuppyGraph(Graph Data Lake)
- Timbr.ai
Compliance and Ethical Considerations
Data Protection: Enterprises would need to be very responsible about storing and using customer data adhering to GDPR and other PII compliance. Data stored needs to be governed and cleansed before processing and reusing for insights or applying AI.
Hallucinations and Reconciliation: Enterprises can also add reconciling services that would take care of identifying misinformation in data, trace back the pathway of the query, and make corrections to it, which can help improve LLM accuracy. With knowledge graphs, since the data stored is transparent and human-readable, this should be relatively easy to achieve.
Restrictive Retention policies: To adhere to data protection and prevent misuse of customer data, while interacting with open LLM systems, it is very important to have zero retention policies so the external systems enterprises interact with would not hold the requested prompt data for any further analytical, business purposes.
Summary
Gen-AI has opened up a great deal of opportunities to leverage in wide range of domains, specially to B2B, B2C enterprise scenarios. Capturing this opportunity with utmost responsibility is the key to Success. Personalized Customer Journeys discussed above is one such great example. Enterprise Grounding lays foundation on how these systems can be utilized with context and compliance. Grounding with Knowledge Graphs opens doors and solves these interesting challenges by finding fine balance with the shortcomings like hallucinations, bias we have today with Gen-AI.
Published at DZone with permission of Sudheer Kandula. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments