Optimizing Filtered Vector Search in MyScale
By combining the strengths of ClickHouse and the proprietary MSTG algorithm, MyScale offers a powerful solution for complex, large-scale vector searches.
Join the DZone community and get the full member experience.
Join For FreeVector search looks for similar vectors or data points in a dataset based on their vector representations. However, pure vector search is rarely sufficient in real-world scenarios. Vectors usually come with metadata, and users often need to apply one or more filters to this metadata. That makes filtered vector search come into play.
Filtered vector search is becoming increasingly vital for intricate retrieval scenarios. You can apply a filtering mechanism to filter out the undesired vectors beyond the top-k/range of multi-dimensional embeddings.
In this blog, we first discuss the technical challenges of implementing filtered vector search. Then, we provide a solution by considering how MyScale optimizes filtered vector search using our proprietary algorithm, MSTG, together with ClickHouse for fast filtering on structural data.
Technical Challenges of Implementing Filtered Vector Search
With the increasing diversity of data types within large datasets in modern applications, choosing the appropriate filtered vector search approach and vector indexing algorithm really matters for enhancing the quality of search results and providing more accurate search outcomes. Now, let's dive into each of these challenges.
Pre-Filtering vs. Post-Filtering
Based on when the filtering occurs in the vector search process, the filtered search can be categorized either as pre- or post-filtering, as illustrated in the figure below.
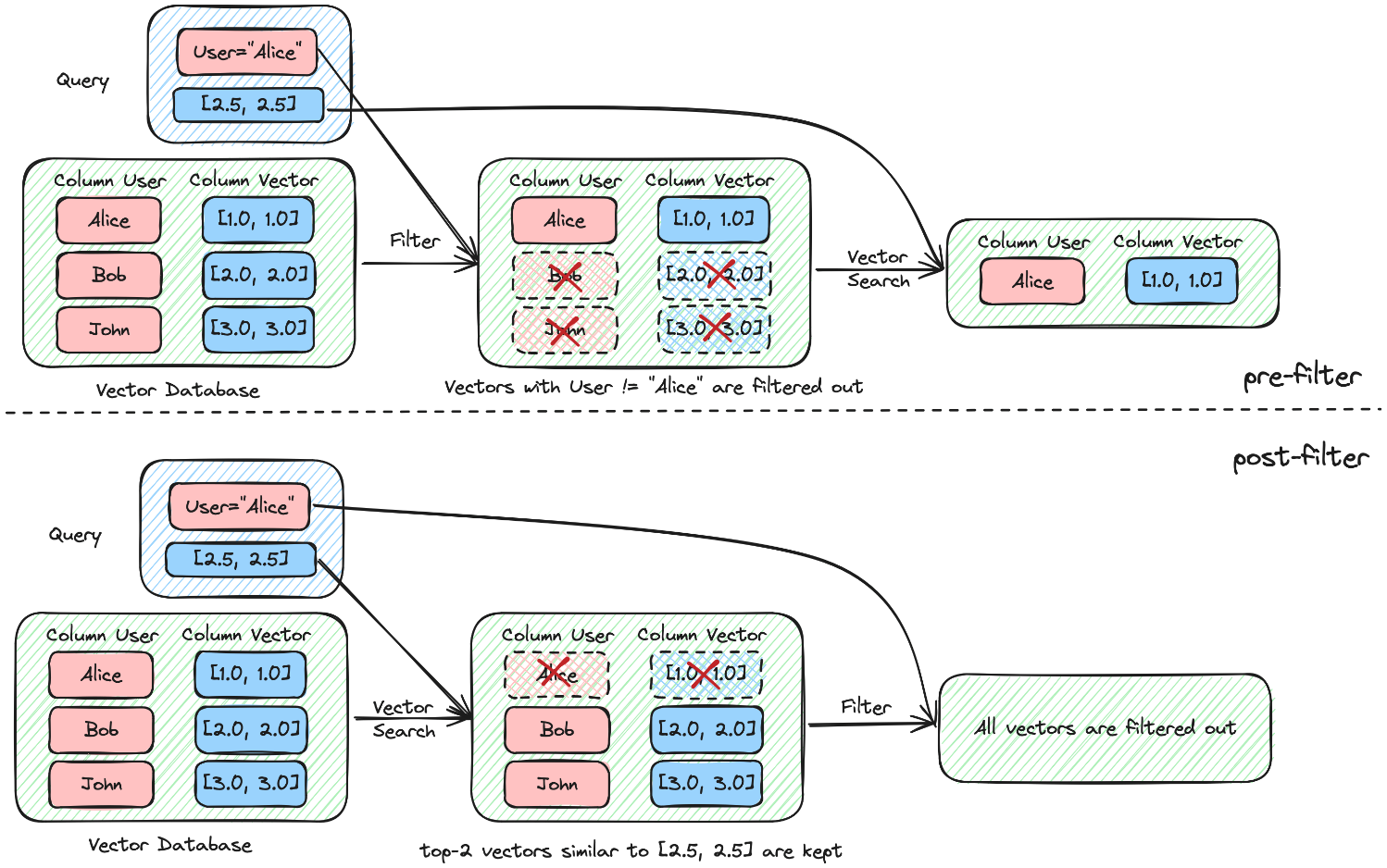
When using pre-filtering, we obtain the expected output ("Alice", [1.0, 1.0]). However, post-filtering does not yield any results.
Pre-Filtering
Pre-filtering vector search is a technique that involves the initial screening of potential matches before conducting the main vector search query on a dataset. The purpose is to narrow down the search space and eliminate ineligible or unnecessary results at an early stage, improving the efficiency and accuracy of the subsequent vector search. This method is particularly beneficial in scenarios where the dataset is large and computational resources need to be used judiciously.
Consider a scenario where you have a vast database of images, and you want to retrieve images that closely match a given query image. Instead of conducting a detailed vector search on the entire image dataset, you can pre-filter potential candidates based on simple features like color histograms, aspect ratios, or low-level descriptors. For instance, you might pre-filter images that have similar color distributions or shapes to the query image.
To sum it up, pre-filtering is a strategic approach to enhance the overall performance of similarity searches by intelligently narrowing down the scope of the search operation.
Note: Pre-filtering is always used in MyScale's filtered search implementation.
Post-Filtering
Unlike pre-filtering, which occurs before the main vector search, post-filtering is a technique in which a pure vector search query is executed on a dataset, and then, after obtaining the initial results, additional filtering or refinement steps are applied. However, this method comes with certain limitations and drawbacks that can affect the efficiency and accuracy of the search results. These results can be unpredictable due to the filter being applied to a reduced set of outcomes. In cases where the filter is highly restrictive, targeting only a small percentage of data points relative to the dataset's size, there is the potential for zero matches in the initial vector search.
Popular vector databases such as PostgreSQL/pgvector and OpenSearch have adopted this approach, leading to low filtered search accuracy, as shown in our previous blog (opens new window.
Why HNSW Underperforms for Filtered Search
Although popular graph algorithms such as HNSW perform well for unfiltered vector searches, their performance may drop significantly for filtered vector searches.
Let's first define the filter-ratio of a filtered vector search as follows:

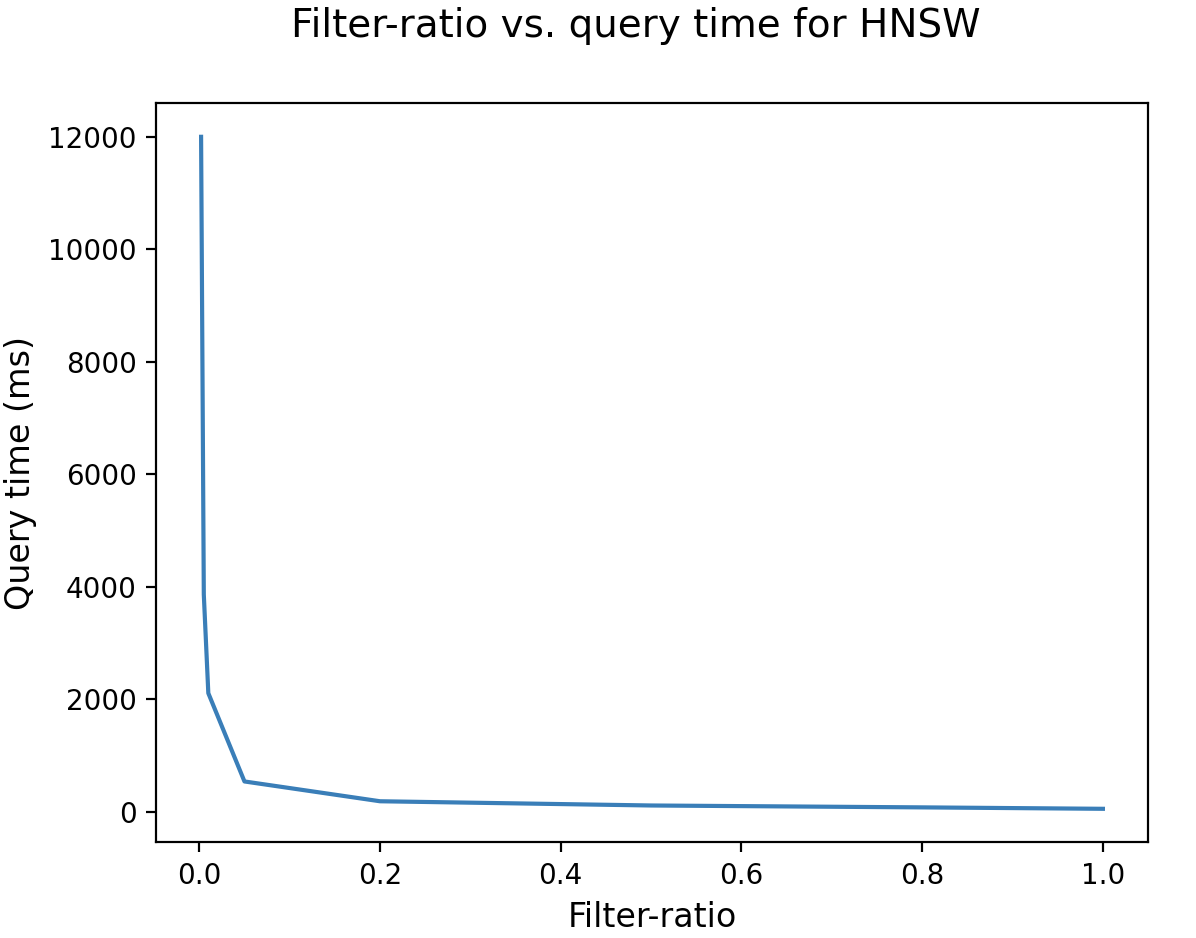
When the filter ratio is low, the filtering becomes very restrictive. As shown in the figure below, the HNSW algorithm performs poorly in this case, taking several seconds when the filter-ratio is below 1%:
Let's analyze why HNSW underperforms when the filter ratio is low by first looking at its search process. During this vector search, the base level's node search is the most time-consuming process. Like the node search in most graph algorithms, HNSW uses a candidate set to store the nodes to visit and a top-candidate set to store the potential top nodes. The conditions for terminating the search include:
- The number of top candidates already meets the algorithm requirement, and
- If the maximum distance between the top candidates and the query vector is less than the minimum distance between the candidate set and the query vector.
In contrast to the ordinary vector search process, HNSW-with-filtered-search will check whether the node is in the selected set before adding it to the potential top candidates' list.
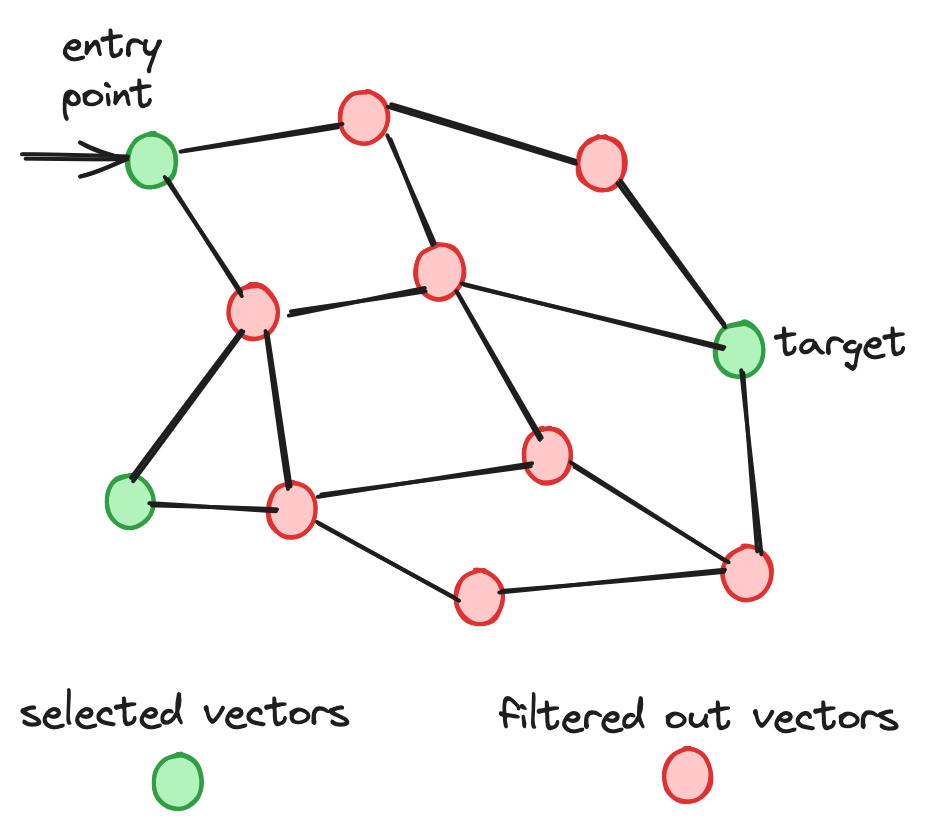
The low filter ratio poses a significant challenge for the index in identifying a sufficient number of top candidates. This limitation leads to extensive node traversal. Additionally, the challenge is compounded by the difficulty in traversing the graph efficiently to locate the filtered nearest neighbors.
A common optimization technique for filtered vector search using HNSW is to switch to brute-force search when the filter ratio falls below a specific threshold. However, this approach is not what we recommend, as it is impractical for large-scale vectors, such as databases containing hundreds of millions or even billions of vectors. Under these circumstances, even a 1% filter ratio requires computing the distances between the query vector and millions of vectors in the database.
Advanced Filtered Vector Search in MyScale
Since we identified the issue, let's work towards a solution. MyScale is a SQL vector database that combines a fast SQL execution engine (based on ClickHouse) with the proprietary Multi-scale Tree Graph (MSTG) algorithm for fast-filtered search. This section explores our rationale for building MyScale on ClickHouse, renowned as the fastest open-source analytical database, and explains our enhancements to the vector algorithm for efficient filtered search. These optimizations have contributed to a high-performance, flexible, and robust filtered vector search capability in MyScale.
Note: MyScale is an integrated vector database with full SQL support.
Harnessing ClickHouse for Filtered Vector Search
Choosing ClickHouse as the foundation for MyScale was driven by its proven efficiency in handling large-scale data. ClickHouse's superior data scanning speed was key to this decision — critical for performant filtered vector searches. The following designs have greatly enhanced its efficiency:
- Column-oriented storage: Unlike traditional row-oriented databases, ClickHouse stores data in columns, making reading and processing data faster. This design is mainly beneficial to aggregate functions and filters, as it efficiently reads only the necessary columns from the disk, reducing I/O operations.
- Vectorized query execution: ClickHouse processes data in batches, not row by row. This vectorized approach allows it to perform operations on multiple data points simultaneously, significantly speeding up query execution. This is particularly advantageous for filtered vector searches on extensive datasets.
- Advanced indexing: ClickHouse employs sophisticated indexing techniques, like skip indexes. The database quickly skips over irrelevant data blocks during a query, resulting in faster filtering as the database spends less time scanning unrelated data.
- Parallel processing: ClickHouse's architecture supports parallel processing, enabling it to distribute the workload across multiple cores and nodes. This parallelization is crucial for handling large-scale queries and filters efficiently, ensuring high performance even with large and complex datasets.
These features make ClickHouse an ideal platform for implementing fast and efficient filtered vector searches. This integration offers the best of both worlds: the powerful analytical capabilities of ClickHouse and the nuanced vector database functionalities essential for handling complex, metadata-rich vector data.
Multi-Scale Tree Graph Algorithm
Multi-Scale Tree Graph (MSTG) is a new vector index developed by MyScale. Unlike popular algorithms such as HNSW, which relies solely on hierarchical graphs, and IVF (Inverted File Index), which can be viewed as a two-level tree, MSTG combines the best parts of both hierarchical graph and tree structures in its design.
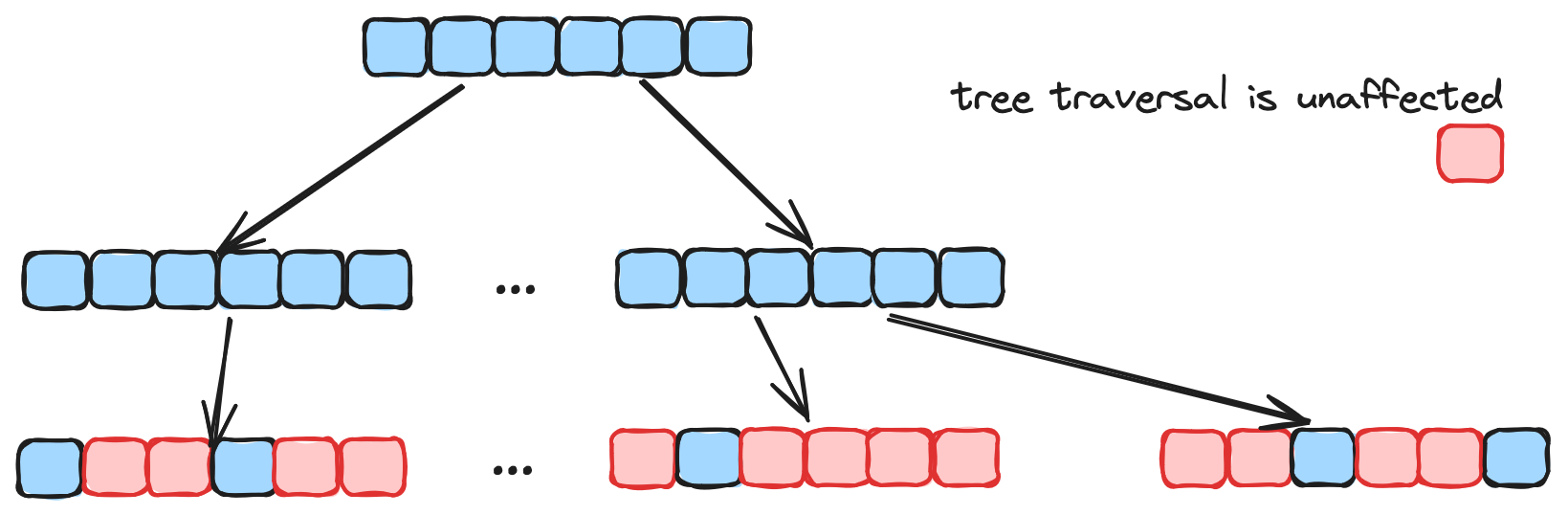
A graph algorithm excels at initial convergence and is usually faster at unfiltered search. However, its efficiency is severely hampered in filtered search. On the other hand, tree algorithms are slower and have lower accuracy for unfiltered search, but tree traversal is unaffected by filtered elements and retains performance for filtered search, as illustrated in the figure below. Therefore, combining these two algorithms in MSTG yields high performance and high accuracy for both cases and achieves fast index build time. In addition, MSTG has accelerated both pre-filtering and vector distance computation with SIMD (Single Instruction, Multiple Data), greatly improving computation throughput on modern CPUs.
Conclusion
Vector search seeks similar data points based on vector representations, but real-world scenarios require more than pure vector search. Vectors with metadata often necessitate filtered vector search, which is crucial for intricate retrieval scenarios.
MyScale's innovative approach to filtered vector search, combining the strengths of ClickHouse and the proprietary MSTG algorithm, offers a powerful solution for complex, large-scale vector searches. This integration provides both speed and precision, making MyScale a leader in vector database technology.
Published at DZone with permission of Hao Liu. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments