Migrating From ClickHouse to Apache Doris: What Happened?
Explore this migration process from ClickHouse to Apache Doris to figure out if it is the right move for you and your data.
Join the DZone community and get the full member experience.
Join For FreeMigrating from one OLAP database to another is huge. Even if you're unhappy with your current data tool and have found some promising candidates, you might still hesitate to do the big surgery on your data architecture because you're uncertain about how things are going to work. So you need experience shared by someone who has walked the path.
Luckily, a user of Apache Doris has written down their migration process from ClickHouse to Doris, including why they need the change, what needs to be taken care of, and how they compare the performance of the two databases in their environment.
To decide whether you want to continue reading, check if you tick one of the following boxes:
- You need your join queries to be executed faster.
- You need flexible data updates.
- You need real-time data analysis.
- You need to minimize your components.
If you do, this post might be of some help to you.
Replacing Kylin, ClickHouse, and Druid With Apache Doris
The user undergoing this change is an e-commerce SaaS provider. Its data system serves real-time and offline reporting, customer segmentation, and log analysis. Initially, they used different OLAP engines for these various purposes:
- Apache Kylin for offline reporting: The system provides offline reporting services for over 5 million sellers. The big ones among them have more than 10 million registered members and 100,000 SKUs, and the detailed information is put into over 400 data cubes on the platform.
- ClickHouse for customer segmentation and Top-N log queries: This entails high-frequency updates, high QPS, and complicated SQL.
- Apache Druid for real-time reporting: Sellers extract data they need by combining different dimensions, and such real-time reporting requires quick data updates, quick query response, and strong stability of the system.
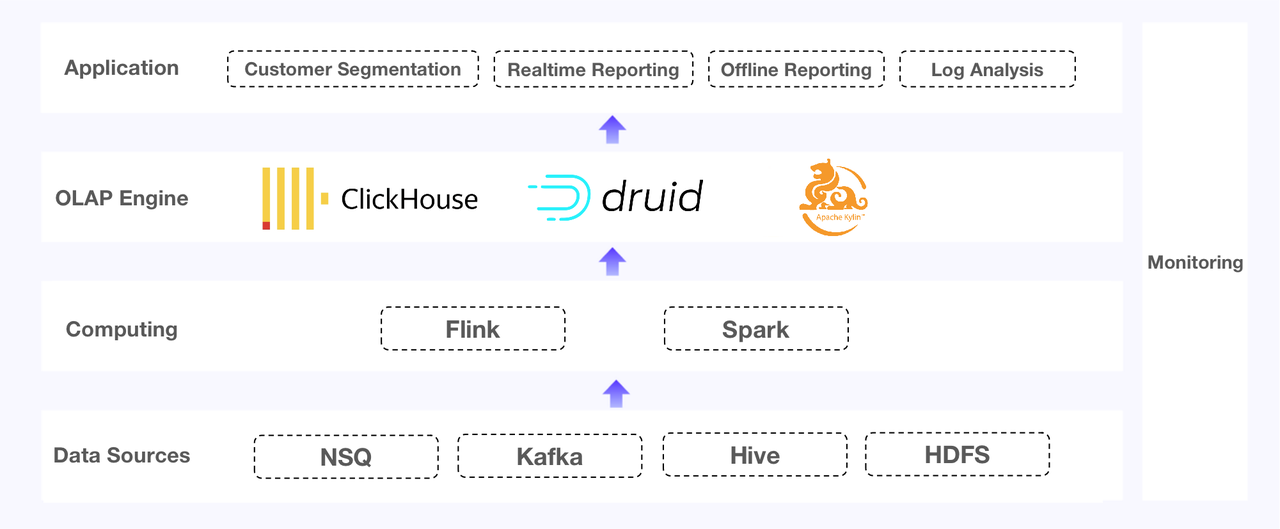
The three components have their own sore spots.
- Apache Kylin runs well with a fixed table schema, but every time you want to add a dimension, you need to create a new data cube and refill the historical data in it.
- ClickHouse is not designed for multi-table processing, so you might need an extra solution for federated queries and multi-table join queries. And in this case, it was below expectation in high-concurrency scenarios.
- Apache Druid implements idempotent writing, so it does not support data updating or deletion itself. That means when there is something wrong at the upstream, you will need a full data replacement. Such data fixing is a multi-step process if you think it all the way through because of all the data backups and movements. Plus, newly ingested data will not be accessible for queries until it is put in segments in Druid. That means a longer window such that data inconsistency between upstream and downstream.
As they work together, this architecture might be too demanding to navigate because it requires knowledge of all these components in terms of development, monitoring, and maintenance. Also, every time the user scales a cluster, they must stop the current cluster and migrate all databases and tables, which is not only a big undertaking but also a huge interruption to business.
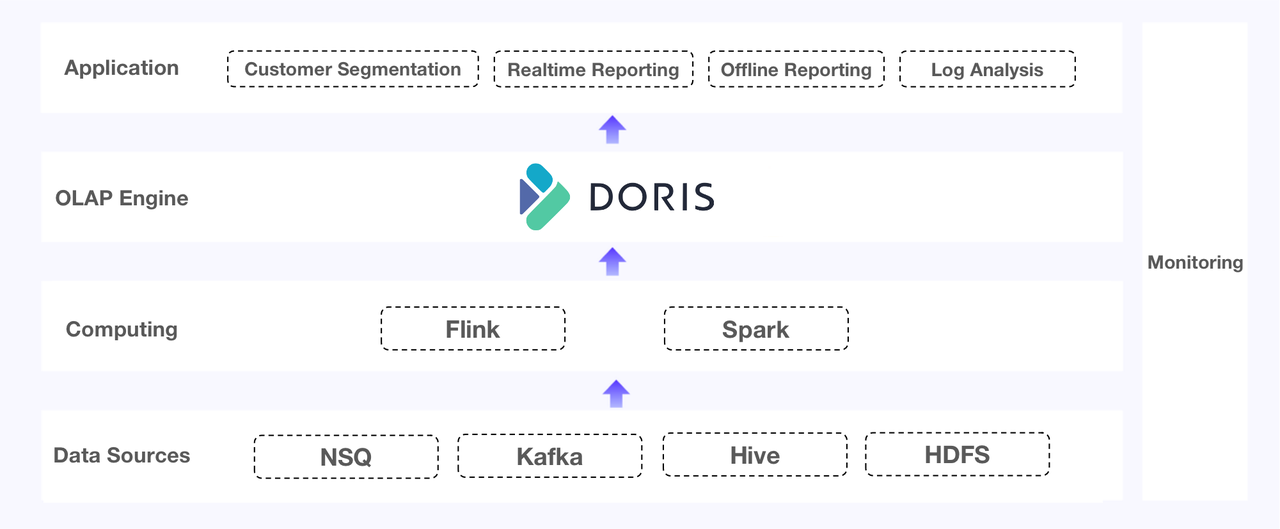
Apache Doris fills these gaps.
- Query performance: Doris is good at high-concurrency queries and join queries, and it is now equipped with an inverted index to speed up searches in logs.
- Data update: The Unique Key model of Doris supports both large-volume updates and high-frequency real-time writing, and the Duplicate Key model and Unique Key model support partial column updates. It also provides an exact-once guarantee in data writing and ensures consistency between base tables, materialized views, and replicas.
- Maintenance: Doris is MySQL-compatible. It supports easy scaling and light schema change. It comes with its own integration tools, such as Flink-Doris-Connector and Spark-Doris-Connector.
So they plan on the migration.
The Replacement Surgery
ClickHouse was the main performance bottleneck in the old data architecture, and why the user wanted the change in the first place, so they started with the ClickHouse.
Changes in SQL Statements
Table Creation Statements

The user built their own SQL rewriting tool that can convert a ClickHouse table creation statement into a Doris table creation statement. The tool can automate the following changes:
- Mapping the field types: It converts ClickHouse field types into the corresponding ones in Doris. For example, it converts String as a Key into Varchar and String as a partitioning field into Date V2.
- Setting the number of historical partitions in dynamic partitioning tables: Some tables have historical partitions, and the number of partitions should be specified upon table creation in Doris; otherwise, a "No Partition" error will be thrown.
- Determining the number of buckets: It decides the number of buckets based on the data volume of historical partitions; for non-partitioned tables, it decides the bucketing configurations based on the historical data volume.
- Determining TTL: It decides the time to live of partitions in dynamic partitioning tables.
- Setting the import sequence: For the Unique Key model of Doris, it can specify the data import order based on the Sequence column to ensure orderliness in data ingestion.
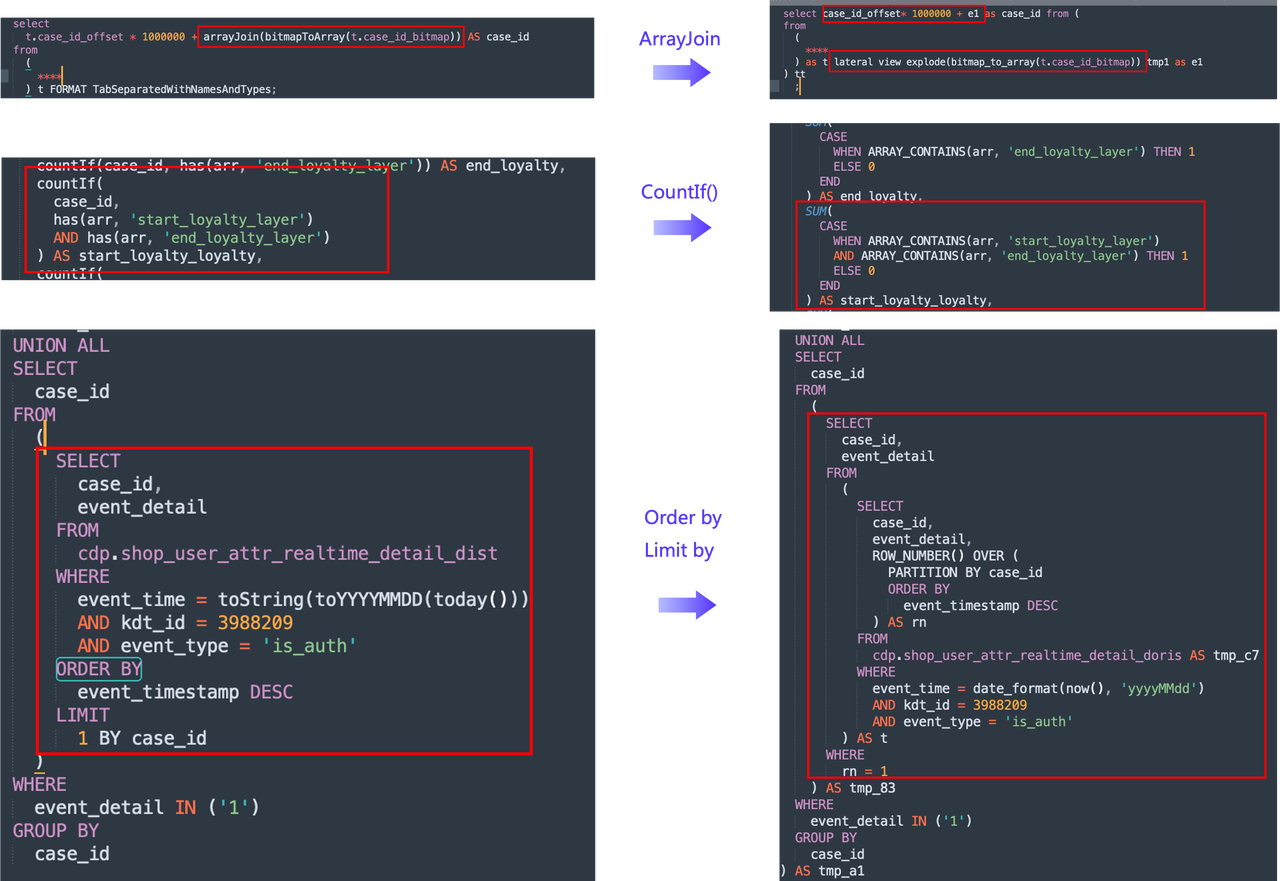
Query Statements
Similarly, they have their own tool to transform the ClickHouse query statements into Doris query statements. This is to prepare for the comparison test between ClickHouse and Doris. The key considerations in the conversions include:
- Conversion of table names: This is simple, given the mapping rules in table creation statements.
- Conversion of functions: For example, the
COUNTIFfunction in ClickHouse is equivalent toSUM(CASE WHEN_THEN 1 ELSE 0),Array Joinis equivalent toExplodeandLateral View, andORDER BYandGROUP BYshould be converted to window functions. - Difference in semantics: ClickHouse goes by its own protocol, while Doris is MySQL-compatible, so there needs to be an alias for subqueries. In this use case, subqueries are common in customer segmentation, so they use
sqlparse
Changes in Data Ingestion Methods
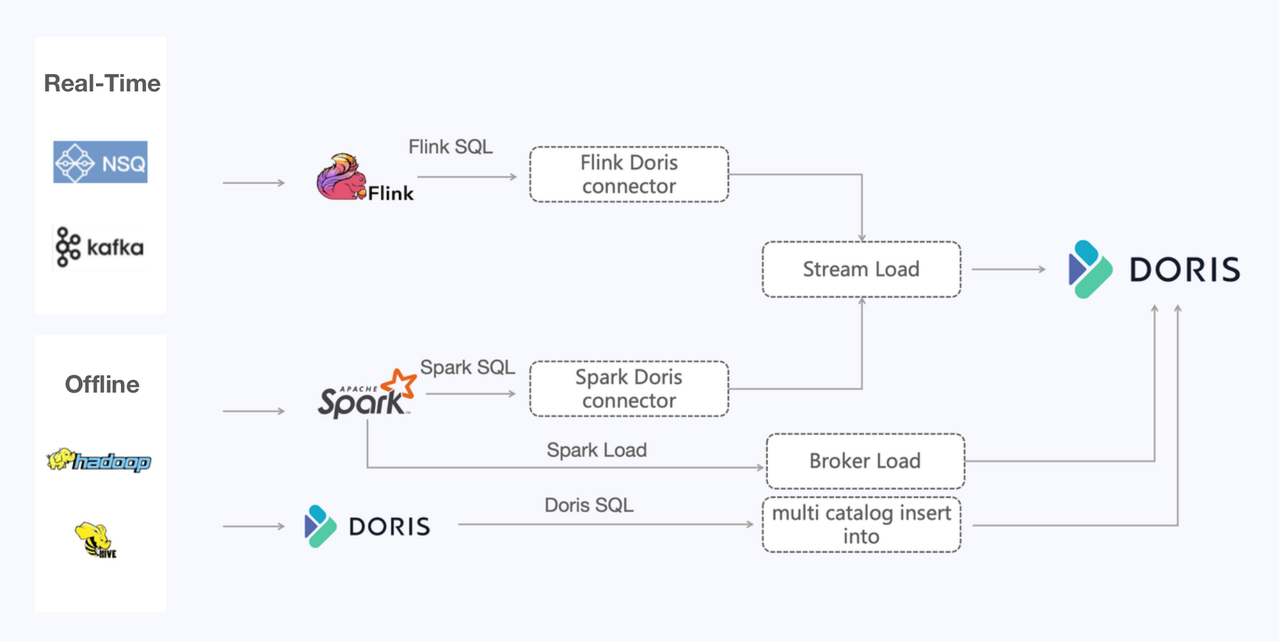
Apache Doris provides broad options for data writing methods. For the real-time link, the user adopts Stream Load to ingest data from NSQ and Kafka.
For the sizable offline data, the user tested different methods, and here are the takeouts:
- Insert Into
Using Multi-Catalog to read external data sources and ingesting with Insert Into can serve most needs in this use case.
- Stream Load
The Spark-Doris-Connector is a more general method. It can handle large data volumes and ensure writing stability. The key is to find the right writing pace and parallelism.
The Spark-Doris-Connector also supports Bitmap. It allows you to move the computation workload of Bitmap data in Spark clusters.
Both the Spark-Doris-Connector and the Flink-Doris-Connector rely on Stream Load. CSV is the recommended format choice. Tests on the user's billions of rows showed that CSV was 40% faster than JSON.
- Spark Load
The Spark Load method utilizes Spark resources for data shuffling and ranking. The computation results are put in HDFS, and then Doris reads the files from HDFS directly (via Broker Load). This approach is ideal for huge data ingestion. The more data there is, the faster and more resource-efficient the ingestion is.
Pressure Test
The user compared the performance of the two components on their SQL join query scenarios and calculated the CPU and memory consumption of Apache Doris.
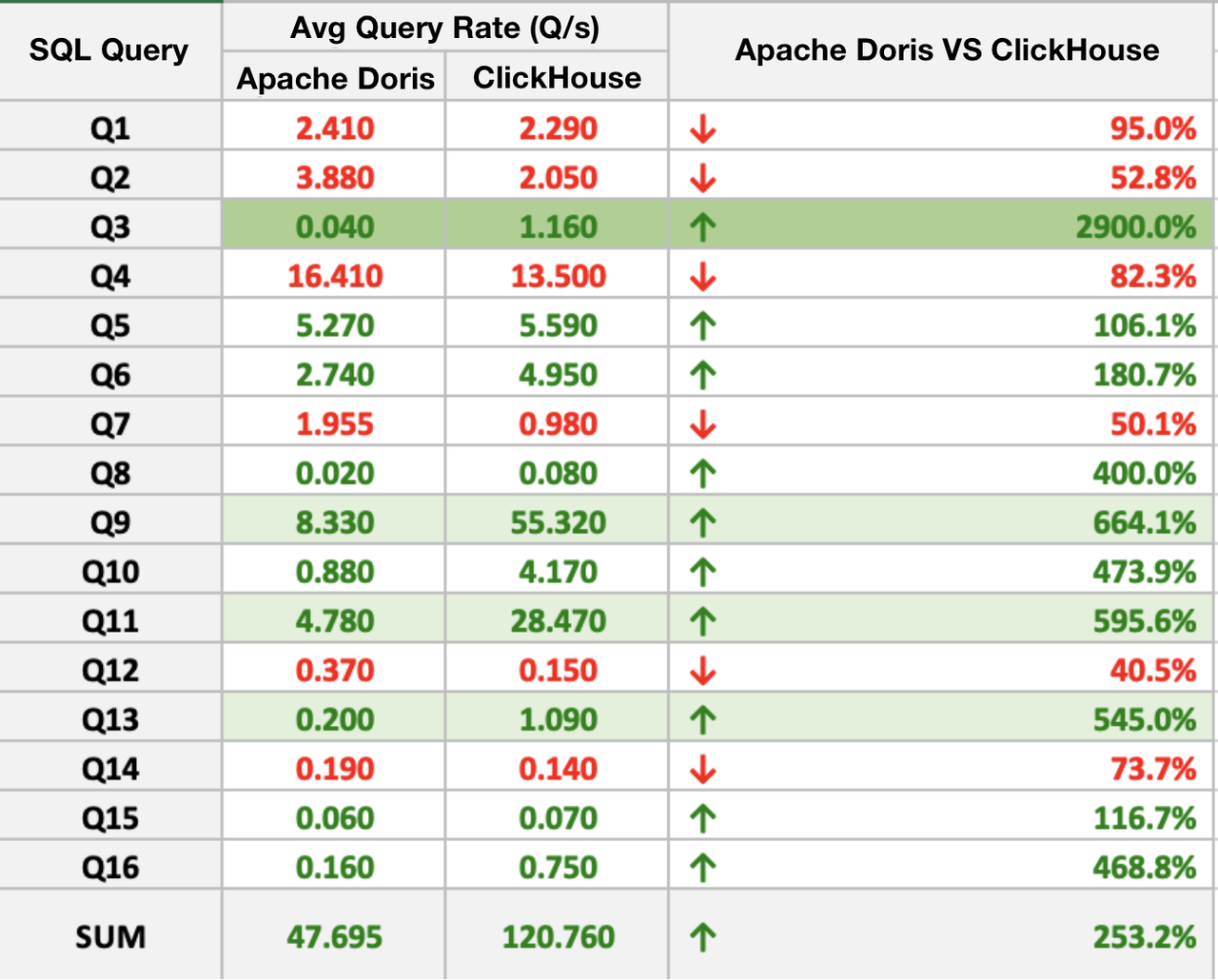
SQL Query Performance
Apache Doris outperformed ClickHouse in 10 of the 16 SQL queries, and the biggest performance gap was a ratio of almost 30. Overall, Apache Doris was 2~3 times faster than ClickHouse.
Join Query Performance
For join query tests, the user used different sizes of main tables and dimension tables.
- Primary tables: user activity table (4 billion rows), user attribute table (25 billion rows), and user attribute table (96 billion rows)
- Dimension tables: 1 million rows, 10 million rows, 50 million rows, 100 million rows, 500 million rows, 1 billion rows, and 2.5 billion rows.
The tests include full join queries, and filtering join queries. Full join queries join all rows of the primary table and dimension tables while filtering join queries retrieve data of a certain seller ID with a WHERE filter. The results are concluded as follows:
Primary table (4 billion rows):
- Full join queries: Doris outperforms ClickHouse in full join queries with all dimension tables. The performance gap widens as the dimension tables get larger. The largest difference is a ratio of 5.
- Filtering join queries: Based on the seller ID, the filter screened out 41 million rows from the primary table. With small dimension tables, Doris was 2~3 times faster than ClickHouse; with large dimension tables, Doris was over ten times faster; with dimension tables larger than 100 million rows, ClickHouse threw an OOM error, and Doris functions normally.
Primary table (25 billion rows):
- Full join queries: Doris outperforms ClickHouse in full join queries with all dimension tables. ClickHouse produced an OOM error with dimension tables larger than 50 million rows.
- Filtering join queries: The filter screened out 570 million rows from the primary table. Doris responded within seconds, and ClickHouse finished within minutes and broke down when joining large dimension tables.
Primary table (96 billion rows):
Doris delivered a relatively quick performance in all queries, and ClickHouse was unable to execute all of them.
In terms of CPU and memory consumption, Apache Doris maintained stable cluster loads in all sizes of join queries.
Future Directions
As the migration goes on, the user works closely with the Doris community, and their feedback has contributed to the making of Apache Doris 2.0.0. We will continue assisting them in their migration from Kylin and Druid to Doris, and we look forward to seeing their Doris-based unified data platform come into being.
Opinions expressed by DZone contributors are their own.
Comments