Open-Source SPL Helps Java Handle Files of Open Formats: TXT, CSV, JSON, XML, and XLS
SPL (JVM-based programming language) can parse structured data files of regular-or irregular-format, represent 2D/hierarchical data in a uniform way, and more.
Join the DZone community and get the full member experience.
Join For FreeIt is common to process data files of open formats like TXT, CSV, JSON, XML, and XLS in Java applications. Hardcoding in Java is extremely complicated, so we often turn to certain ready-for-use open-source packages, but each package has its weaknesses.
Parsing Library
This type of class library enables to read an external file in Java as the latter’s internal object through a simpler coding process than hardcoded data retrieval. Common products include:
- OpenCSV for parsing TXT and CSV files
- SJ.json, Gson, and JsonPath for parsing JSON files
- XOM, Xerces-J, JDOM, and Dom4j intended to parse XML files
- POI, which is the XML parser
JsonPath offers JsonPath syntax and Dom4J provides XPath syntax to handle simple filtering computations. However, these libraries generally have weak computing ability and need to turn to hardcoding or other class libraries to accomplish computing tasks.
Spark
As Scala’s class library, Spark supports structured data files and has a relatively strong computing ability. The library’s disadvantage is the lack of parsing ability and needs the assistance of a third-party class library, like spark-xml for parsing XML and spark-excel or for parsing XLS. This makes the computation not as stable as using native class libraries. The Scala programming language has shortcomings. The far steeper learning curve than Java’s means high costs of learning, and too frequent releases of newer versions cause inconvenience to practical applications in practice.
Embedded Databases
Parsing a file and writing it to an embedded database, like SQLite, HSQLDB, and Derby makes it possible to use SQL’s powerful computing ability. Yet, embedded databases have complicated frameworks, and the data loading process is quite a hassle that results in serious delay. SQL’s powerful computing ability is not always powerful because it is only good at computing two-dimensional data but not good at handling hierarchical data like JSON/XML.
Certain class libraries, including file JDBC drivers like simoc/csvjdbc, xiao321, CsvJdbc, and XlsJdbc and DataFrame libraries such as Tablesaw and Joinery are able to compute structured data files, but they are immature, have weak computing ability, and thus have low practical value.
esProc SPL is another choice.
SPL is a JVM-based, open-source programming language. It offers simple parsing methods to read regular or irregular TXT, CSV, JSON, XML, and XLS files, provides specialized data objects to express two-dimensional data and hierarchical data in a uniform way, and supplies a wealth of functions that can meet various business computing requirements.
TXT/CSV
SPL has a variety of built-in parsing functions that enable parsing various text files using simple code, and a rich set of functions for computing parsed text files in a consistent way.
Text Files of Regular Formats
A two-dimensional text file, like a database table, contains column names in the first row, corresponds one record to one row, and separates columns using a fixed symbol. The comma-separated CSV and the tab-separated TXT are the two most commonly seen formats. SPL offers the T function to parse any text file using one line of code:
s=T("D:\\data\\Orders.csv")
Text Files of Irregular Formats
SPL uses an import function that can work with a rich set of options to parse them. To parse a text file, separate by a horizontal double-dash. For instance:
s=file("D:/Orders.txt").import@t(;,"--")
A Wealth of Functions
On a parsed text file, SPL can accomplish SQL-style computations effortlessly:
- Filter:
s.select(Amount>1000 && Amount<=3000 && like(Client,"*s*")) - Sort:
s.sort(Client,-Amount) - Distinct:
s.id(Client) - Group & Aggregate:
s.groups(year(OrderDate);sum(Amount)) - Join:
join(T ("D:/data/Orders.csv"):O,SellerId; T("D:/data/Employees.txt"):E,EId) - Get topN:
s.top(-3;Amount) - Get TopN in each group:
s.groups(Client;top(3,Amount))
Text Files of More Irregular Formats
Generally, such a text file cannot be directly parsed into structured data. SPL offers flexible functional syntax to obtain desired data through simple handling. In a text file, for instance, every three lines form one record and the second row of each record contains multiple fields. We are trying to rearrange the file to transform it into a structured one, sorted by the 3rd and the 4th fields:
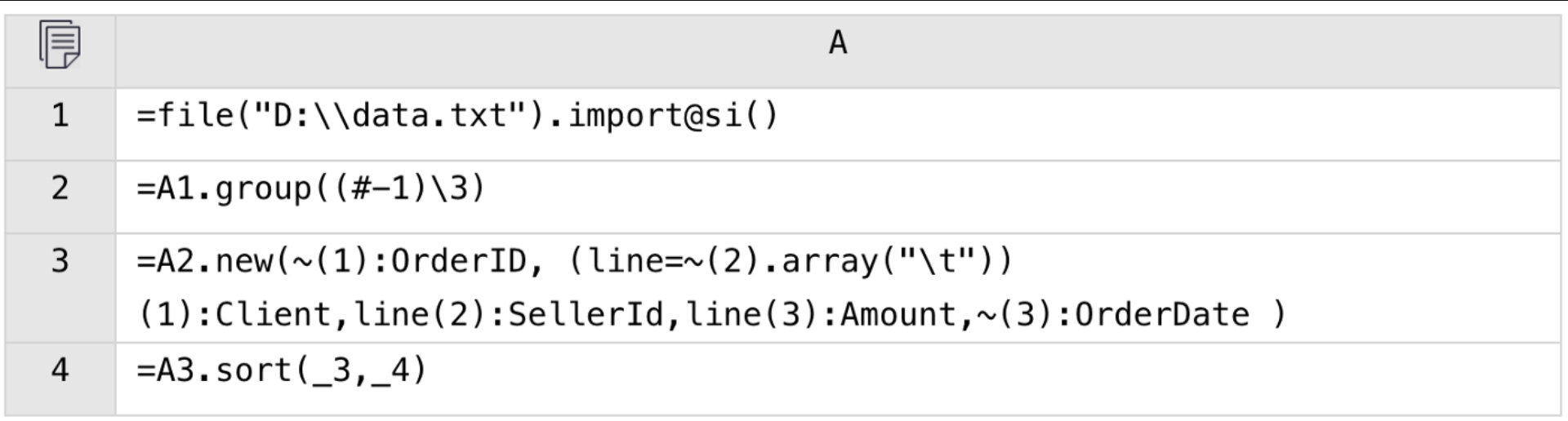
SPL also supports SQL syntax of SQL92 standard, covering set-oriented computations, case when, with, and nested queries. To perform a grouping and aggregation, for instance:
$select year(OrderDate),sum(Amount) from D:/data/Orders.txt group by year(OrderDate)
JSON/XML
SPL processes hierarchical data like JSON and XML conveniently by accessing any hierarchical level freely and computing data in a consistent way.
Specialized Hierarchical Structured Data Object
SPL expresses the hierarchical structure of JSON/XML data conveniently. Here is an example of how to read the hierarchical JSON string from a file and parse it:

The following screenshot shows the hierarchical structure:
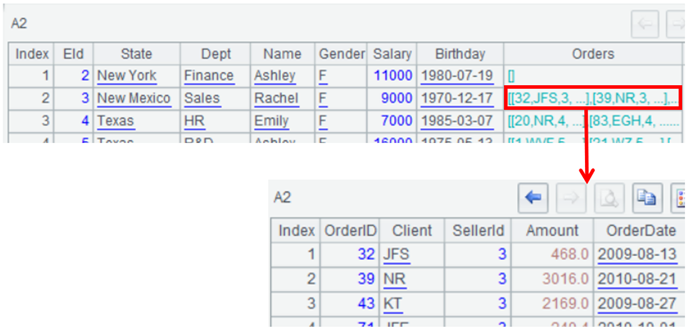
It is similar to reading and parsing an XML string:

Access Hierarchical Data
SPL accesses data on a certain level through the dot and in a certain position through the subscript.
- Get a set of
Clientfield values:A2.(Client) - Get
Ordersfield of the 10th record (the two-dimensional table value):A2(10).Orders - Get the 5th record of
Ordersfield in the 10th record:(A2(10).Orders)(5)
Compute Hierarchical Data
SPL computes two-dimensional data and hierarchical data in uniform code:

Handle Hierarchical Data Downloaded From the Web
Besides local hierarchical data, SPL can also handle hierarchical data downloaded from the web, such as WebService and RESTful. Retrieve hierarchical JSON data from RESTful and perform a conditional query as follows:

Many special data sources, like MongoDB, ElasticSearch and SalesForce also store data in a hierarchical level. SPL can directly retrieve data from them for further computation.
XLS
SPL can read/write various regular- or irregular-format XLS files effortlessly with strongly encapsulated POI and compute them with built-in functions and syntax through consistent coding.
SPL still uses T function to read row-wise XLS files of regular formats:
=T("d:\\Orders.xls")
It also performs subsequent computations in a similar way to handling text files. SPL uses xlsexport function to generate a regular-format, row-wise XLS file. To write data table A1 to the first sheet of a new XLS file and make the first row contain column names, for instance, SPL needs only one line of code:
=file("e:/result.xlsx").xlsexport@t(A1)
xlsexport function has many functionalities. It can write a data table to a specified sheet, certain rows of the data table to it, or specified columns of the data table to it:
=file("e:/scores.xlsx").xlsexport@t(A1,No,Name,Class,Maths)
xlsexport function can also be conveniently used to append data. Suppose there is an XLS file containing data and we are trying to append data in data table A1 to the end of the file, with the same appearance as the last row of the existing XLS file:
=file("e:/scores.xlsx").xlsexport@a(A1)
SPL uses xlsimport function to read data from row-wise XLS files of irregular formats. The function has rich and simplistic functionalities.
Import an XLS file without column headers and detailed data starts from the first row: file("D:\\Orders.xlsx").xlsimport().
- Import an XLS file by skipping the title in the first two rows:
file("D:/Orders.xlsx").xlsimport@t(;,3) - Import XLS data from the 3rd row to the 10th row:
file("D:/Orders.xlsx").xlsimport@t(;,3:10) - Import 3 columns of an XLS file:
file("D:/Orders.xlsx").xlsimport@t(OrderID,Amount,OrderDate) - Import a sheet named "
sales":file("D:/Orders.xlsx").xlsimport@t(;"sales")
The xlsimport function also has other functionalities, like reading N rows backward, opening an XLS file using a password, and reading a large XLS file.
XLS Files With Extremely Irregular Formats
SPL uses xlscell function to read/write data in a specified range of a given sheet. To read cell A2 in sheet1, for instance:
=file("d:/Orders.xlsx").xlsopen().xlscell("C2")
SPL is capable of parsing free-format XLS files with its agile syntax. One instance is to parse the following file into a standard two-dimensional table (table sequence):
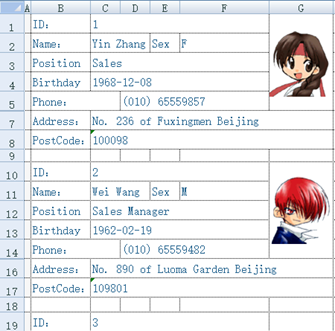
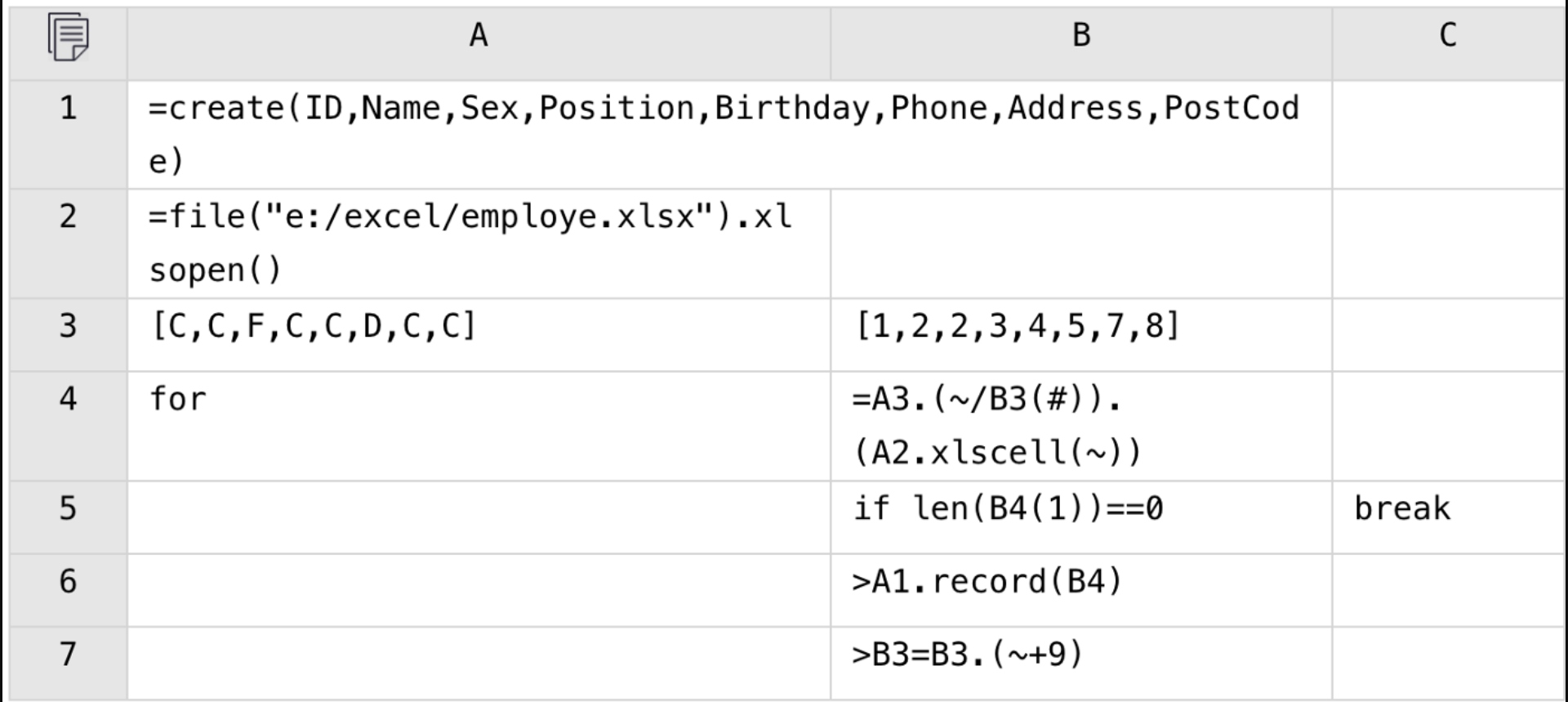
The file has a very irregular format. Writing Java code directly with POI will be a heavy and time-consuming job, but SPL code is short and concise:
The xlscell function can also be used to write data to an irregular-format range. For instance, the blue cells in the following XLS file contain irregular table headers and we are trying to fill data in the corresponding blank cells:
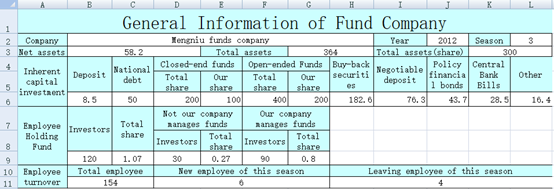
The POI code will be bloated and lengthy. SPL code, as shown below, is short and concise:
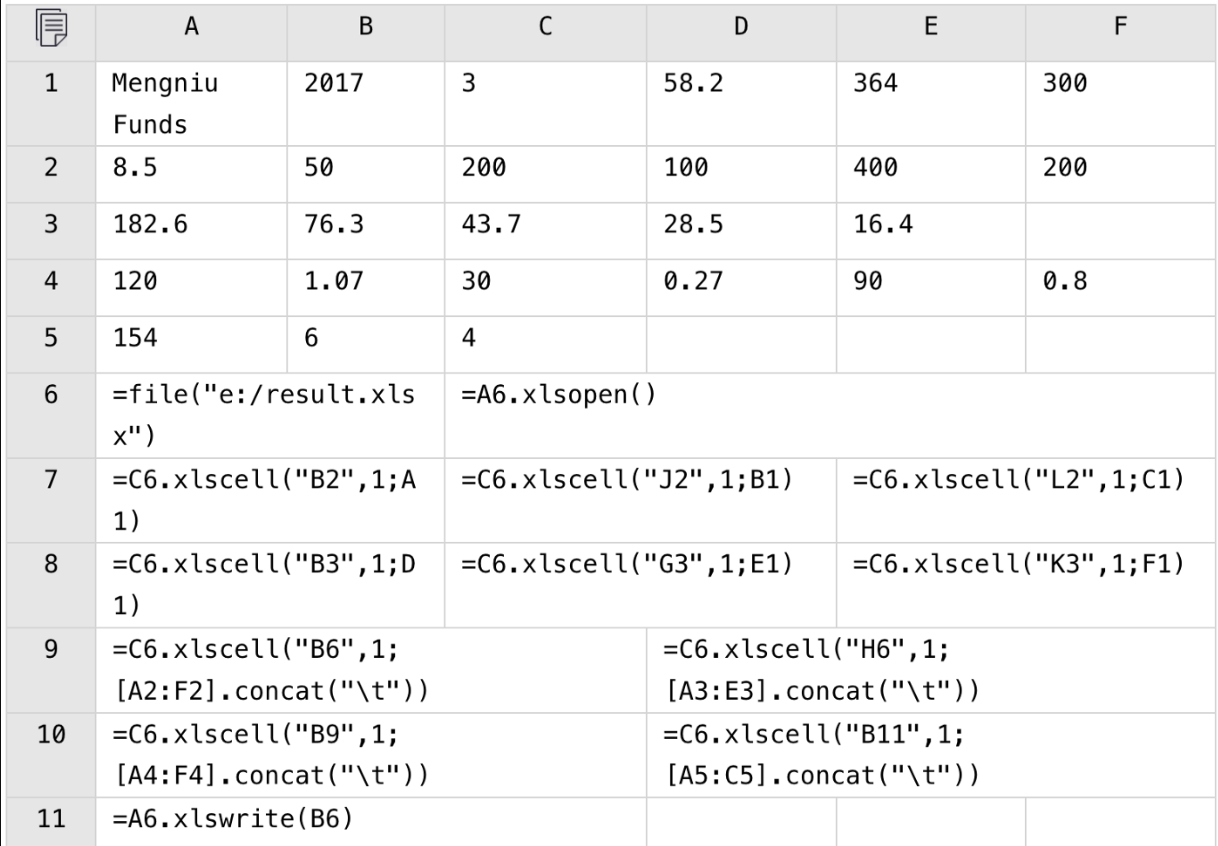
Note that row6, row9 and row11 have continuous cells where SPL condenses code to fill them together. POI, however, can only operate cell by cell.
Remarkable Computational Capacity
SPL supplies a great number of string functions and date functions, as well as convenient syntax to effectively simplify code for achieving complex logics that both SQL and stored procedures find hard to handle.
A Great Wealth of Date and String Functions
Besides functions for performing regular computations like getting a date before or after a specified date and string truncation, SPL offers more date and string functions that outrun SQL in both quantity and functionality.
Get the date before or after a specified number of quarters:
elapse@q("2020-02-27",-3) // Return 2019-05-27
Get the date N workdays after:
workday(date("2022-01-01"),25) // Return 2022-02-04
String functions: check whether a string all consists of letters.
isdigit("12345") // Return true
Get a string before a specified substring:
substr@l("abCDcdef","cd") // Return abCD
Split a string into an array of substrings by vertical bar: ["aa","bb","cc"]
Java - Copy code:
"aa|bb|cc".split("|") // Return
SPL also offers functions to get a date before or after a number of years, get which quarter the date belongs to, split a string according to a regular expression, get the where or select part of a SQL statement, get words from a string, split HTML by the specific marker, etc.
Convenient Function Syntax
SPL supports function options. This allows functions with similar functionalities to use the same name and distinguishes them with different options. The basic functionality of select function is to filter data. If we need to get the first eligible record, we use @1 option:
T.select@1(Amount>1000)
SPL uses @b option to perform quick filtering on ordered data using the binary search algorithm:
T.select@b(Amount>1000)
SPL uses @o option to perform order-based grouping on data ordered by grouping field that puts neighboring records having same grouping field values:
T.groups@o(Client;sum(Amount))
Function options can work together:
Orders.select@1b(Amount>1000)
Usually, parameters in a structured computation function are complicated. SQL, for instance, uses a lot of keywords to divide parameters of a statement into multiple groups, causing inconsistent statement structure. SPL has hierarchical parameters. It employs semicolons, commas, and colons to identify parameters to three levels, and writes complicated parameters in a simple way.
join(Orders:o,SellerId ; Employees:e,EId)
Achieving Complex Business Logics Simply
SPL has excellent computational capability. It handles order-based computation, set-oriented computations, joins, and stepwise computations that SQL/stored procedures find hard to handle effortlessly. To count the longest number of days when a stock rises consecutively, SPL has the following code:

To find the first n big customers whose orders amount takes up at least half of the total and sort them by the amount in descending order:

Cross-Data-Source Computations
SPL supports diverse data sources, including not only structured data files, but various types of databases and NoSQL like Hadoop, Redis, Kafka, and Cassandra, and thus can accomplish computations involving different types of sources, like a join between xls and txt:
=join(T("D:/Orders.xlsx"):O,SellerId; T("D:/Employees.txt"):E,EId)
Ease of Integration
SPL offers a convenient and easy-to-use JDBC driver. A piece of simple code, like SQL, can be directly embedded in a Java program:
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = connection.createStatement();
String str="=T(\"D:/Orders.xls\").select(Amount>1000 && Amount<=3000 &&
like(Client,\"*s*\"))";
ResultSet result = statement.executeQuery(str);
Storing Computing Code Separately From the Java Program Reduces Coupling
For complicated SPL code, we can first save it as a script file and then invoke it in the Java program as we call the stored procedure. This effectively reduces coupling between computing code and the front-end application.
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
CallableStatement statement = conn.prepareCall("{call scriptFileName(?, ?)}");
statement.setObject(1, "2020-01-01");
statement.setObject(2, "2020-01-31");
statement.execute();
SPL: Achieve Hot Swap by Placing Computing Code Outside the Java Program
SPL is interpreted language that can achieve hot swap by placing computing code outside the Java program. An interpreted language executes in real-time without recompilation after any changes, without restarting the Java application. This makes maintenance convenient and creates a more stable system.
Though many class libraries are available for computing TXT/CSV/JSON/XML/XLS, they have their defects. SPL, as a JVM-based, open-source programming language, can parse structured data files of regular-or irregular-format, represent two-dimensional data and hierarchical data in a uniform way, and perform common SQL-style computations using consistent coding. SPL boasts a richer set of string and date functions, more convenient syntax, and more powerful computing capacity. It offers an integration-friendly JDBC driver, supports placing algorithms in or outside the application, which can effectively decrease system coupling, and achieves hot-swappable code.
Published at DZone with permission of Jerry Zhang. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments