Implement a Distributed Database to Your Java Application
Interference is a simple Java framework that enables you to run a distributed database service within your Java application.
Join the DZone community and get the full member experience.
Join For FreeBrief Description
i.o.cluster, also known as interference open cluster, is a simple Java framework that enables you to launch a distributed database service within your Java application, using a JPA-like interface and annotations for structure mapping and data operations. This software inherits its name from the interference project, within which its mechanisms were developed.
i.o.cluster is an open-source, pure Java software.
The basic unit of the i.o.cluster service is a node – it can be a standalone running service, or a service running within some Java application.
Each i.o.cluster node has its own persistent storage and can consider and used as a local database with the following basic features:
- It operates with simple objects (POJOs).
- It uses base JPA annotations (
@Table,@Column,@Transient,@Index,@GeneratedValue) for object mapping directly to persistent storage. - It supports transactions.
- It supports SQL queries with a READ COMMITTED isolation level.
- It uses persistent indices for fast access to data and increases the performance of SQL joins.
- It allows flexible management of in-memory data for stable operation of the node in any ratio of storage size/available memory.
Each of the nodes includes several mechanisms that ensure its operation:
- Core algorithms (supports structured persistent storage, supports indices, custom serialization, heap management, local and distributed sync processes).
- SQL and CEP processor.
- Event transport, which is used to exchange messages between nodes, as well as between a node and a client application.
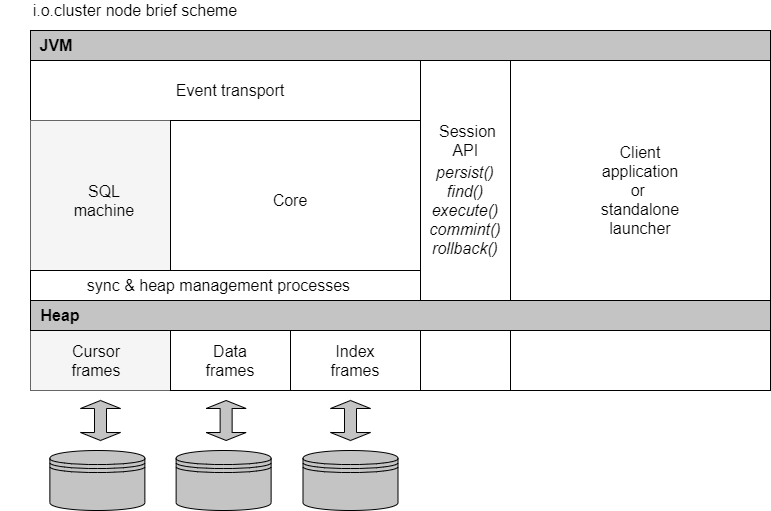
Nodes can be joined into a cluster, at the cluster level with inter-node interactions, we get the following features:
- It allows you to insert data and run SQL queries from any node included in the cluster.
- It supports horizontal scaling SQL queries.
- It supports transparent cluster-level transactions.
- It supports complex event processing (CEP) and simple streaming SQL.
- The i.o.cluster nodes do not require the launch of any additional coordinators.
i.o.cluster implements the most simple data management model, which is based on several standard JPA-like methods of the Session object:
persist()- placing an object in storage.find()- find an object by a unique identifier.execute()- execution of a SQL query.commit()- committing a transaction.rollback()- rollback a transaction.
As well, i.o.cluster software includes a remote client that provides the ability to remotely connect to any of the cluster nodes using internal event transport and execute standard JPA-like commands (persist, find, execute, commit, rollback).
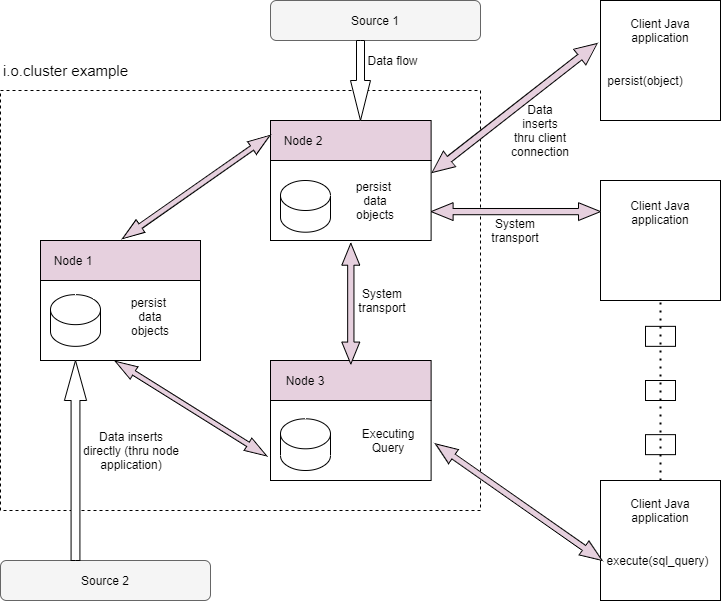
Distributed Persistent Model
Interference open cluster is a decentralized system. This means that the cluster does not use any coordination nodes; instead, each node follows to a set of some formal rules of behavior that guarantee the integrity and availability of data within a certain interaction framework.
Within the framework of these rules, all nodes of the i.o.cluster are equivalent. There is no separation in the system of master and slave nodes — changes to user tables can be made from any node, also all changes are replicated to all nodes, regardless of which node they were made on.
Talking about transactions, running commit in a local user session automatically ensures that the changed data is visible on all nodes in the cluster.
To include a node in the cluster, you must specify the full list of cluster nodes (excluding this current one) in the cluster.nodes configuration parameter.
The minimum number of cluster nodes is 2, and the maximum is 64.
After configuration, we may start all configured nodes as clusters in any order. All nodes will be using specific messages (events) to provide inter-node data consistency and horizontal-scaling queries.
The minimum number of cluster nodes is 2, and the maximum is 64.
After configuration, we may start all configured nodes as clusters in any order. All nodes will be using specific messages (events) to provide inter-node data consistency and horizontal-scaling queries.
Rules of Distribution
The concept of interference open cluster is based on a simple basic requirement, which can be literally expressed as follows: we must allow insertion and modification of data at the cluster level from any node, and we must allow data retrieval from any node, using as much as possible the computing resources of the cluster as a whole. Further, we accept the condition that all cluster nodes must be healthy and powered on, if any of the nodes has been turned off for a while, it will not be turned on to receive data until her storage is synchronized with other nodes. In practice, in the absence of changes at the moment, this means that there are identical copies of the storage on the cluster nodes. To prevent conflicts of changes in the cluster, several lock modes are used:
- Table level (a session on a node locks the entire table).
- Frame level (a session on a node locks a frame)
- Disallowed changes for non-owner nodes
here it is necessary to explain in more detail: all data inserts on a certain node are performed into a frame that was allocated on the same node, for which, in turn, the node is the owner. This is done so that when there are simultaneous inserts into a table from several nodes at once, there are no conflicts during replication. Subsequently, this distinction allows us to understand whether or not to request permission to change the data in the frame at the cluster level or not. Moreover, it allows us to implement a mode when changes to frames on a non-owner node are prohibited. This mode is used on cluster nodes if one or more other nodes become unavailable (we cannot know for certain whether the node is down or there is a problem in the network connection).
So, let's repeat again:
- All cluster nodes should be equivalent.
- All changes on any of the nodes are mapped to other nodes immediately.
- Data inserts are performed in the local storage structure, and then the changes are replicated to other nodes.
- If replication is not possible (the node is unavailable or the connection is broken), a persistent change queue is created for this node.
- The owner of any data frame is the node on which this frame has been allocated.
- Data changes in node own data frame are performed immediately, else, performed distributed lock for data frame on cluster level.
- If the cluster has failed (some nodes are offline or connection broken), all data changes are not allowed or changes in only the node's own data frames are allowed.
- The cluster uses the generation of unique identifiers for entities (@DistributedId annotation) so that the identifier is unique within the cluster, but not just within the same node.
- The cluster does not use any additional checks for uniqueness, requiring locks at the cluster level.
SQL Horizontal-Scaling Queries
All SQL queries called on any cluster nodes will be automatically distributed among the cluster nodes for parallel processing. Such a decision is made by the node based on the analysis of the volume of tasks (the volume of the query tables is large enough, etc.).
If a node is unavailable during the processing of a request (network fails, service stopped), the task distributed for this node will be automatically rescheduled to another available node.
Complex Event Processing Concepts
So, we must allow insertion and modification of data at the cluster level from any node, and we must allow data retrieval from any node, using as much as possible the computing resources of the cluster as a whole.
The next concept of interference open cluster is that any table is at the same time a queue, in particular, using the SELECT STREAM clause, we can retrieve records in exactly the same order in which they were added. Usually, at the cluster level, the session.persist() operation can be considered as publishing a persistent event. Based on our basic distribution rules, we send this event to all nodes.
interference open cluster does not currently support the standard DML UPDATE and DELETE operations, instead of for bulk table processing (including the optional WHERE clause) we have implemented PROCESS and PROCESS STREAM clauses that allow us to process each record from a selection of one of the EventProcessor interface implementations. On the one hand, this approach allows us to obtain results similar to those that we would achieve using UPDATE and DELETE, on the other hand, it significantly expands the possibilities for custom processing of records, allowing full event processing. For the sake of fairness, it is need noting that you can get similar results using standard SELECT and SELECT STREAM, using some custom code to process the result set, but PROCESS and PROCESS STREAM implement the processing at the core level of the cluster, which significantly improves the performance, second, these statements are launched at the cluster level and provide a ready-made implementation for distributed event processing.
In order to create a custom EventProcessor implementation, we need to implement two methods:
boolean process(Object event)
In this method, custom event handling should be implemented, in case of successful processing, true is returned.
boolean delete()
If this method returns true, the record will be deleted from the table upon successful completion of processing (the process method returned true).
Next, we can use the following query:
PROCESS fully_qualified_class_name alias
WITHIN fully_qualified_event_processor_class_name
[WHERE condition1 AND/OR condition2 … ]
[ORDER BY alias.column_name … ]
For example, it might look like this:
String sql = "process su.interference.entity.SomeEvent d within su.interference.processor.SomeEventProcessor where d.eventType = 1";
ResultSet rs = s.execute(sql);
The PROCESS statement allows to process records from one specific table in batch mode, currently the query does not support any joins to other tables. The PROCESS statement is a distributed operation and performs processing on all nodes of the cluster, for which it locks the table at the cluster level while the query is running for any other PROCESS statements may be launched from other nodes or from other sessions.
This processing is performed inside a transaction, therefore, after execution, we need to explicitly apply commit or rollback.
Online Complex Event Processing
Except standard batch processing, interference open cluster supports online complex event processing using SELECT STREAM (and PROCESS STREAM for launch with EventProcessor implementations) a clause in SQL statement.
SELECT STREAM query supports three modes of CEP:
- Events are processed as is, without any aggregations.
- Events are aggregated by column value using any of the group functions (tumbling window).
- Some window aggregates events for every new record (sliding window).
The basic differences between a streaming query and the usual one are as follows:
- The
execute()method returns aStreamQueueobject. - The request is executed asynchronously until
StreamQueue.stop()method will be called or until the application terminates. - The
StreamQueue.poll()method returns all records previously inserted into the table and according to the WHERE condition (if exist) and continues to return newly added records. - Each
StreamQueue.poll()method always returns the next record after the last polled position within the session, so that, provided that the SQL request is stopped and called again within the same session, data retrieve was continued from the last fixed position, in another session data will be retrieved from begin of the table. - Unlike usual, a streaming request does not support transactions and always returns actually inserted rows, regardless of the use of the
commit()method in a session inserting data (DIRTY READS).
Further Information
- GitHub: https://github.com/interference-project/interference
- More info: http://io.digital
Opinions expressed by DZone contributors are their own.
Comments