Architecture and Code Design, Pt. 1: Relational Persistence Insights to Use Today and On the Upcoming Years
Learn how potential behaviors that can add extra processing and resource consumption to your databases integration and get up to date with news on what's out there.
Join the DZone community and get the full member experience.
Join For FreeThis two-part series explores from a persistence perspective topics such as application architecture, code design, framework solutions, traps, and news of the Jakarta EE world that can help you design and architect better solutions in the upcoming years.
In part one (this article), we'll understand how potential behaviors that can add extra processing and resource consumption to your databases integration and get up to date with news on what's out there and what's coming for Java applications that rely on relational data storage integration.
In part two, we take into consideration the need to leverage a great number of storage options currently for persisting and managing data in Java applications. They vary from relational (SQL) to NoSQL, in-memory graph databases. They can be either traditional on-premise and self-managed or run as a cloud service (DBaaS - Database as a Service). Taking this into consideration, get to know enterprise ways of handling polyglot persistence architectures for Java solutions and become aware of several roadblocks that are possibly slowing down both your service and your team's performance today.
Let's start drilling down into the most popular persistence solution so far, JPA, with an added perspective from application architecture design patterns, object oriented-programing principles, and more.
What to Expect From Java Persistence API (JPA)
When working with a relational database management system (RDBMS), the most common approach for Java developers is to rely on Java Persistence API (JPA). JPA is a stable and mature solution, as you can notice per its lifecycle represented in the image below. It not only supports the adoption of design patterns but also influences and gets influenced by fast-paced frameworks that do not implement them.
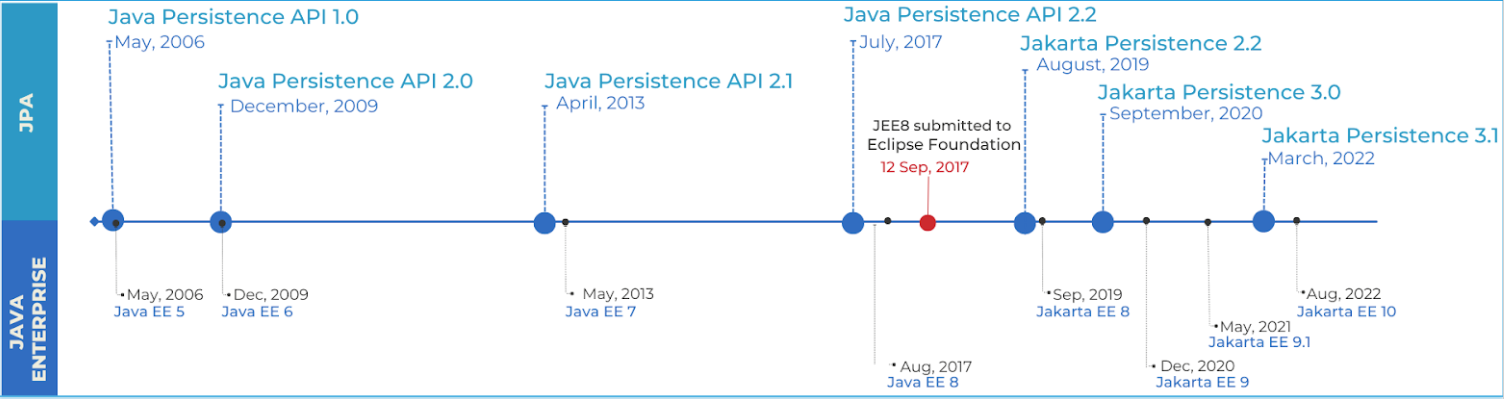
With the latest release of Jakarta EE 10, we have a new minor version release of JPA 3.1. Here are two highlights of JPA 3.1:
1. java.util.UUID is now treated as a basic Java type and can be used as a primary key or part of a composite primary key.
@Entity
public class Player {
@ID @GeneratedValue(strategy=GenerationType.UUID)
private java.util.UUID id;
…
}
2. There are several improvements and new capabilities in the querying capabilities. Jakarta Persistence QL (JPQL) has new numeric functions such as CEILING, FLOOR, ROUND, and new functions to handle date and time (along with compatible methods via criteria API). For dates, for example, the SQL types LOCAL DATE, LOCAL TIME and LOCAL DATETIME can be retrieved by functions as java.time.LocalDate, java.time.LocalTime and java.time.LocalDateTime, respectively.
As of today, December 2022, the two frameworks that currently implement JPA 3.1 are Hibernate ORM 6.0.0.Final and EclipseLink 4.0.0-M3. Notice you can expect several enhancements and updates in these frameworks. If you plan to use or upgrade to Hibernate 6, for example, you can expect several enhancements, such as using jakarta.persistenceclasses, instead of javax.persistence, in this case, a consequence of now implementing a JakartaEE — instead of Java EE — specification.
Designing Persistence: Frameworks and Best Practices
Make informed decisions regarding the next framework and data-related design pattern to adopt on your next project as much as you can. Otherwise, you might find out a bit too late that what you thought was a good "catch" actually ended up being a very costly "trap".
The rich Java ecosystem offers us a large number of framework options to pick from, varying according to the target database paradigm. For relational databases, the possible Object–Relational Mapper (ORM) frameworks can either be or not be an implementation of the JPA specification. These frameworks provide a common API and rely on specific database drivers to integrate with multiple options. For NoSQL integration, the common popular approach (and generally, the supported one) is to use the vendor's database driver without a common abstraction API. As a result, integration with different NoSQL engines likely results in different code implementations.
Let's take a better look at the relational (SQL) landscape for now, and see about Java and NoSQL in the next sections.
When picking a framework, have in mind which data-related design patterns you plan to use in the service's persistence layer.
Within many types of Patterns of Enterprise Application Architecture, we'll now talk about a couple related to data integration and, consequently, to framework choices.
With respect to persistence integration code particularities, we can choose to internalize or externalize them into/out of the domain classes (entities). To demonstrate the key idea highlighted above, we'll discuss two patterns: Entity-Repository and Active Record.
Even though surrounded by polemic technical discussions, it is a fact that both patterns have their own advantages and disadvantages. Hidden traps might show up, though, once you weigh a pattern pro/con against design principles; or once you decide to untangle a framework's implementation and its particularities.
Let us quickly recapitulate each pattern and talk about these pattern trade-offs you must know to make informed decisions.
Entity-Repository Pattern
An implementation of the Entity-Repository Pattern brings an Entity as a pure object and, when needed, a respective Repository class to encapsulate any of this entity's database integration and operations. Database calls can be managed by the context lifecycle and are not mixed with business logic.
@Entity
public class Person {
private @Id Long id;
private @Column String name;
private @Column LocalDate birthday;
private @ManyToOne List<Address> addresses;
}
public interface PersonRepository extends <Person, String> {}
Person person =...;
// persist a person
repository.save(person);
List<Person> people = repository.listAll();
// finding a specific person by ID
person = repository.findById(personId);In this example, the Entity Person only holds its private attributes. In order to manage a Person's data, methods of the class PersonRepository can be used. Database integration particularities reside in the repository layer, and the entities are "passive" records being tracked and managed by, for example, an ORM.
Active Record Pattern
When using the Active Record Pattern, the entity holds its attributes, persistence methods, and even database connection details. It is, therefore, an "active" entity that can persist and manage itself, as you can notice in the following example:
@Entity
public class Person extends PanacheEntity {
{ public String name;
public LocalDate birthday;
public List<Address> addresses;
}
Person person =...;
// persist a person
person.persist();
List<Person> people = Person.listAll();
// finding a specific person by ID
person = Person.findById(personId);Notice the invocations of method data operations listAll and findById residing within the domain class Person.
"Ok, but what about them?" you might ask. With the basic concepts now clarified, the following insights cover the trade-offs of each approach and what to look out for when picking your solution's ORM.
Trade-Offs Summary
Entity-Repository Pattern:
Advantages: Decoupled code and good separation between data integration and domain classes - domain layer is not aware of data integration layer core details; Single Responsibility Principle easier to maintain.
Downsides: extra layers; poorly designed repository classes can: mistakenly manipulates objects differently than it should, and both break encapsulation and the Single Responsibility Principle.
Active Record Pattern:
Advantages: Slightly reduces code complexity; can provide faster coding experience in early/mid stages; Both data and methods that operate on it reside on the same model, forming a cohesive whole.
Downsides: Data integration particularities and domain logic are mixed; A single class represents both a database table and holds logic to operate on it, breaking the Single Responsibility Principle.
Watch Out for Potential Framework Traps
Consciously decide to adopt solutions, making sure to look at its multiple adoption aspects and consequences. For this particular topic, let's use Panache as our example, as it supports both Active Record and Repository implementations. Our goal is to demonstrate that broader analysis can be done by including aspects that are usually put aside during trade-offs investigation.
Since we're working with Java, let's take into consideration not only architectural designs but also OOP principles, such as encapsulation. Solutions can choose to break code encapsulation by either having developers explicitly set public attributes or by automatically generating getters and setters for every domain private attribute (which ends up the same). In our example, the Panache's guides state, at the time of writing, the following opinionated implementation detail about ORM Mapping simplifications:
"Use public fields. Get rid of dumb getters and setters. Hibernate ORM w/o Panache also doesn’t require you to use getters and setters, but Panache will additionally generate all getters and setters that are missing and rewrite every access to these fields to use the accessor methods. This way, you can still write useful accessors when you need them, which will be used even though your entity users still use field accesses. This implies that from the Hibernate perspective, you’re using accessors via getters and setters even while it looks like field accessors."
But remember, it's all about trade-offs: this is one short example just points that up since Panache provides a nicer developer experience and speed in exchange for, for example, breaking code encapsulation at a domain level.
Don’t try to find the best design in software architecture;
instead, strive for the least worst combination of trade-offs.
— Software Architecture: The Hard Parts, by Neal Ford, Mark Richards, Pramod Sadalage, and Zhamak Dehghani
Moving forward, let's discuss how to handle other storage options and its diversity.
Conclusion
Java is a powerful programming language that can be used to create high-performance applications. When working with databases, there are a number of factors that can affect both a solution's performance and architectural design quality aspects. In this first article, we have covered:
- What's new on the recent Jakarta EE 10 release with respect to persistence with JPA.
- How data-related design patterns and persistence framework implementation choices can impact our code design positively or negatively.
Check Out the Next Article of the Series
Architecture and code design: persistence-focused insights to use today and in the coming years - Part 2: Java integration with NoSQL Databases, Polyglot Persistence, In-memory storage, and more. Don't miss out on topics like the below, covered in part 2:
- How we can prospect polyglot Java solutions that handle not only traditional relational databases but also NoSQL databases, putting in place the challenges of the current path offered by vendors in contrast to the Jakarta EE specification under development, Jakarta NoSQL.
- In-memory database solutions advantages if compared to storage that can't match OOP; How such solutions can help you optimize the performance of your application.
As an extra reading recommendation, here's a nice article (with a video) about OOP encapsulation advantages.
Opinions expressed by DZone contributors are their own.
Comments