On Some Aspects of Big Data Processing in Apache Spark, Part 2: Useful Design Patterns
In this post, learn to construct Spark applications in a maintainable and upgradable way, where at the same time "task not serializable" exceptions are avoided.
Join the DZone community and get the full member experience.
Join For FreeIn my previous post, I demonstrated how Spark creates and serializes tasks. In this post, I show how to utilize this knowledge to construct Spark applications in a maintainable and upgradable way, where at the same time "task not serializable" exceptions are avoided.
When I participated in a big data project, I needed to program Spark applications to move and transform data from/to relational and distributed databases, like Apache Hive. I found such applications to have a number of pitfalls, so all "hard to read code," "method is too large to fit into a single screen," etc. problems need to be avoided for us to focus on deeper issues. Also, Spark jobs are similar: data is loaded from a single or multiple databases, gets transformed, then saved to a single or multiple databases. So it seems reasonable to try to use GoF patterns to program Spark applications.
This post is organized as follows:
- Section 1 describes my system.
- Section 2 discusses what GoF patterns may be useful in this case.
- In Section 3, I present a solution to the described problem (fully workable code on GitHub).
Let's go.
1. Problem
A typical Spark application is as follows (Fig 1). There are multiple data sources (databases, files, etc.): DBi, i=1:N, and a Java Spark server. We need to load data from the data sources, transform the data, and save the transformed data to different or the same data sources. Each application may have different combinations of input and output data sources.
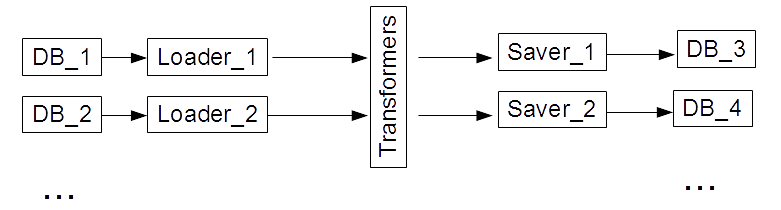
Fig 1: A typical Spark application
To make my code concise and run out of the box, I simplify the problem: let there be 2 JSON files as data sources (Fig 2). Then, the data undergoes transformations: the transformations are a trivial unit transformation or a union of the two datasets. Finally, there are two savers. One returns a dataset schema, and the other shows a dataset content. I took the code of the "Master Apache Spark - Hands On!" course of Imtiaz Ahmad as a starter code. Despite its simplicity, the code is enough to illustrate how to use basic design patterns in Spark applications.
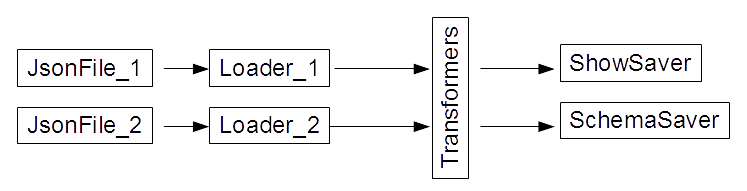
Fig 2: Our simplified system
Let's investigate 2 Spark applications (Fig 3). The first one is a simple load-transform-save job (A). The second one is a more complex case, where two datasets are merged into one and then saved (B). How do we program these Spark applications with minimal code duplication?

Fig 3: A basic spark application (A); A Spark application with two sources, one saver, and a union transformation (B)
2. Patterns
To attack this problem, let's choose design patterns from "Design Patterns: Elements of Reusable Object-Oriented Software." Also, we need our solution to be serializable. The following GoF patterns may come to mind here:
- Builder: The pattern consists of a Product, a Builder, and a Director. The Director directs the Builder to make a Product. The pattern is effective to build disparate products; that is why products are built in 2 steps. The first step configures the Builder. In the second step, the Director directs the Builder to build a Product. This pattern, however, is not particularly useful in our case since Spark applications have a common structure.
- Template Method: The pattern consists of an AbstractClass (with primitive operations, plus a skeleton method to chain these operations) and a ConcreteClass (with the primitive operations implemented). This is certainly useful in our case to define a skeleton of a load-transform-save application.
- Factory: The pattern consists of a Product (Interface), ConcreteProducts, a Creator (Interface), and ConcreteCreators. A ConcreteCreator creates a ConcreteProduct conditionally. This looks useful for us.
- Abstract Factory: The pattern consists of an AbstractFactory (Interface or Superclass), ConcreteFactories, an AbstractProduct (Interface or Superclass), ConcreteProducts, and a Client. The Client configures the ConcreteFactories (that share the same AbstractFactory parent), to build the ConcreteProducts (that share the same AbstractProduct parent). According to D. Banas's presentation "Abstract Factory Design Pattern," this pattern is most useful if combined with a Strategy pattern. This is right what we need! We can use both the similarities of how to run jobs and the similarities of how to build those jobs.
- Strategy: The pattern consists of a Strategy interface, and ConcreteStrategies to implement the interface. This allows a user to easily switch specific implementations of a functionality. It is useful in our case to program different loaders, transformers, and savers.
- Decorator: The pattern consists of a Component (Interface), ConcreteComponents, a Decorator (abstract class), ConcreteDecorators. ConcreteDecorators add functionality to ConcreteComponents. It is also useful in our case to add extra functionality to our methods. For example, we can truncate a relational database table before we write data into it. Let's combine these patterns to get a solution.
3. Solution
I propose the following solution to this problem (Fig 4). The solution is based on an Abstract Factory pattern. SimpleJobFactory and BasicJobPlan are a ConcreteFactory and a ConcreteProduct respectively. IFactory and IJobPlan are an AbstractFactory and an AbstractProduct interfaces accordingly.

Fig 4: Abstract Factory, Template Method, and Strategy patterns to program our Spark jobs
The classes' implementation details are shown in Fig 5. Notice that we keep a serializable SparkSession object in a separate instance of SparkSessionContainer. Every other class, that uses a SparkSession, extends a SparkSessionContainer.

Fig 5: How to implement Concrete Jobs and Concrete Factories in our case
Also notice that SimpleJobFactory and BasicJobPlan already contain skeleton methods to build a job (SimpleJobFactory.make()) and to run a job (BasicJobPlan.run()). These classes serve as AbstractClasses for a Template Method pattern. More elaborate job factories and job plans extend these classes.
Indeed, to create a job (B) plan, we need to add a second loader, a second saver, and another transformer (union) to the job (A) plan. Also, to create a job (B) concrete factory, we need to "decorate" the SimpleJobFactory.make() method to add the second loader, add the union transformer, and replace the basic saver with an empty one to save data by the new (second) saver. We can change job plan savers, transformers, and loaders on every step since we can access the job on every step in a ConcreteFactory.make() method. How to do this is shown in Fig 5.
Notice that our SimpleJobFactory depends on an I extends IJobPlan generic interface to utilize the methods and fields of SimpleJobFactory for more elaborate job plans. These more complex job plan interfaces depend on the loader, transformer, and saver interfaces. Loaders, transformers, and savers implement a Strategy pattern, so it is easier for us to switch different implementations.
To avoid "task not serializable" exceptions, we should put only serializable objects as class fields. Non-serializable objects should be created as local variables inside methods. See my previous post for details.
To run these jobs, we need to create a Spark Driver (see Part 1 to review Spark terminology), where we create a SparkSession instance, set data sources' configs, create Concrete Factories, make Concrete Jobs, and run the jobs.
public class JsonDriver {
public static void main(String[] args) {
final SparkSession spark = SparkSession.builder()
.appName("JSON Lines to Dataframe")
.master("local")
.getOrCreate();
final String path = "src/main/resources/multiline.json";
final String path2 = "src/main/resources/multiline2.json";
Map<String, String> options = new HashMap<>();
options.put("path", path);
options.put("path2", path2);
options.put("jobName", "Job_1");
IFactory factory = new TwoJobFactory(spark, options);
factory.make();
factory.getJob().run();
}Here, the Spark Driver acts as a Client to configure the Concrete Factories in an Abstract Factory pattern. There is a single SparkSession for the whole application. The session is provided to a SparkSessionContainer to be accessible to the container's children. The application runs in Local mode and prints a union of two data sets.
Conclusion
In this post, I demonstrated how to use GoF Abstract Factory, Template Method, and Strategy patterns to make a Spark application code modular, readable, upgradable, and also serializable. I hope this will be helpful for you in your Spark projects.
Opinions expressed by DZone contributors are their own.
Comments