MuleSoft: Best Practices on Batch Processing
Learn about the different scenarios and best practices for batch processing in Mule 4, including optimizing batch size, parallel processing, streaming, and more.
Join the DZone community and get the full member experience.
Join For FreeToday, organizations are frequently tasked with processing large volumes of data efficiently and accurately. Whether migrating vast datasets, synchronizing records between systems, or performing complex data transformations, batch processing is critical for ensuring these tasks are completed reliably and on time.
This article explores the best practices for batch processing in Mule 4 and offers insights into how you can design, implement, and optimize batch jobs to meet the demands of your enterprise. From optimizing batch size and leveraging parallel processing to ensuring data security and implementing robust error handling, we’ll cover the essential strategies to help you build efficient and reliable batch processing solutions.
Batch Processing Scenarios
Batch processing is a technique for handling and processing large volumes of data by dividing it into smaller, manageable chunks or “batches.” This method allows applications to efficiently process massive datasets, such as large files, database records, or messages, by splitting the workload into smaller pieces that can be processed independently and in parallel.
Scenario #1: Consolidating data from multiple sources and sending it to a single destination.

Integrating data sets to parallel process records
Scenario #2: Synchronizing between two systems/applications.

Synchronizing data sets between business applications
Scenario #3: ETL (Extracting, Transforming, and Loading) process between source and target systems.

Extracting, Transforming, and Loading (ETL) information into a target system
Scenario #4: Pushing data consumed via an API to a downstream legacy system.

Best Practices for Optimizing Batch Processing
Batch Processes
- Transform your dataset upfront, before the processing phase, instead of transforming each record individually during processing. This approach is called front-load transformation.
- Before the processing phase, filter any unneeded fields or records from the input payload. Not touching them at all might be even faster and more reliable than going through the entire payload to avoid passing on those fields/records.
- Keep your batch deployments separate from real-time deployments.
- When co-running your multiple batch jobs:
- Evaluate resource (compute, file-space, memory) utilization.
- Chain batch jobs instead of running in parallel.
- Note the failure points, recovery time, and impact on other jobs.
- When it comes to file sizes:
- Split files into multiple smaller files or limit fields — large files can consume working memory.
- Evaluate chunked mode and file streaming mode.
- Watermark your source repositories because it allows:
- Greater resiliency in your processes.
- Simplified access to unprocessed data.
Streaming
Use streaming when writing to a CSV, JSON, or XML file.
By default, the entire payload is loaded into memory, but with streaming, small portions of the payload are loaded as they arrive, preventing out-of-memory issues.
Streaming affects your application's performance, slowing the pace at which it processes transactions.
Streaming limits access to the items in the output.
NOTE: For more information on streaming strategies and their configurations, refer here.
Batch Tuning
- Try to avoid DataWeave transformation(s) within the processor component of a batch step: DataWeave in a step processes one record at a time, which is inefficient. Instead, perform transformations during the input phase or batch commit (within the batch aggregator component of the step), where possible.
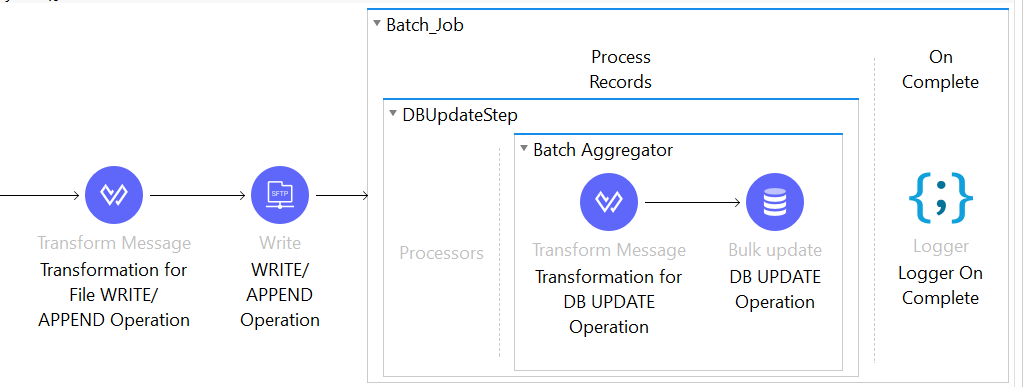
Processor component within the Batch Step is empty as the transformations are executed in the Input Phase.
- Avoid too many batch steps: Mule uses a queue between batch steps, which consumes memory. Disabling persistent queues will also introduce more latency between batch steps.
- Use the Iterator pattern to read large files without exhausting memory: You can achieve this by:
- Using the Iterator pattern within a DataWeave transformation to process data in chunks.
- Using a custom Java implementation that reads the files incrementally.
Within your transformation, coercing the output to an Iterator will output a java.util.Iterator that does not load the whole list into memory:
%dw 2.0
output application/java
---
payload as IteratorThe next message processor then pulls the Java objects from the Iterator one at a time, iterating over the payload without reading the entire contents.
- Use batch commits or streaming commits over individual inserts to endpoints: Batch commits of fixed size (aggregator size) are typically recommended. Otherwise, you can use streaming commits, which reduce memory consumption but can impact performance.
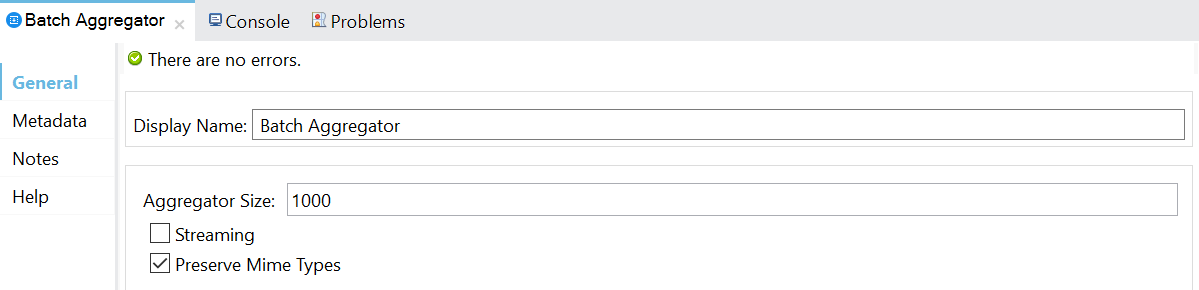
Batch Aggregator configuration for either Batch Commit or Streaming Commit
- Configure batch threads properly: Maximum concurrency (2 * CPU cores quantity) is set by default unless you configure it on the batch job scope. Increasing threads will improve performance but consume more memory and CPU. Increment or decrement slowly, as too many threads may also impact endpoints.
There will be 16 threads by default, but you can increase or decrease them to improve processing time.
- Consider setting the block size (+ or -) properly: Increasing the block size improves performance but impacts memory. Also, consider setting the block size to commit size when using a single batch step.
- Avoid storing the input payload in variables: Storing the entire input payload for batch processing in variables (flow, session, or record variables) can result in out-of-memory or heap space.
Never save the payload for batch processing in a variable.
- Define error handling within a separate batch failure step to reduce full replay.
- Configure your scheduling strategy: Depending on whether your application is single-worker or multi-worker hosted, configure your scheduling strategy:
-
ORDERED_SEQUENTIALwill only process one job at a time -
ROUND_ROBINwill be distributing jobs across workers.
-
General Tuning
- Not all formats are equal when it comes to performance. Bean (Java object) payloads tend to be the fastest. So, if it is a viable option given other considerations, create payloads as Java objects.
- Use DataWeave 2.0 instead of a scripting language such as Groovy or a programming language like Java to manipulate the contents of a message object. With DataWeave as the expression language, you can simply query the data directly and forget about those transformations.
- Usecaching for non-consumable payloads. The benefit is to handle messages quicker.
- Useconnection pooling for DB connectors.
- Determine the correct sizing for your application. There are different ways to right-size your application, and these tasks could include knowing the following:
- Size of the objects you will keep in memory at a given time.
- Amount of concurrent transactions.
- Volume of transactions.
- Avoid the ‘No Space Left On Device’ error by changing the retention policy of batch data being processed. Applications with significant or frequent batch jobs require large disk space. The batch process retains the history of batch instances in the temporary directory of Mule runtime. By default, the retention policy is set to 7 days. A monitoring process will remove temporary data that has met the expiration criteria. You can use a configuration like the one below:
<batch:job jobName="JobName" doc:id="01d87864-3dc8-4dae-9696-1f57b42126c1" >
...
<batch:history >
<batch:expiration maxAge="1" ageUnit="DAYS" />
</batch:history>
</batch:job>This will cause historical data to be removed after 1 day and could be appropriate, for instance, for a batch process that runs daily.
You will need to choose your expiration policy based on how frequently the batch process will run and how much data is processed.
- Modify thedefault frequency to delete expired batch job instances metadata sooner. By default, expired instances and their metadata are cleared every 60 minutes. You can modify this by changing the following property in
wrapper.conf:
mule.batch.historyExpirationFrequency={milliseconds}- Avoid the ‘No Space Left On Device’ error caused by a high volume of DataWeave temporary files. The DataWeave engine internally generates temporary files when handling big payloads. Sometimes, such volume can exhaust disk space on Mule runtime server machines. These temporary files will generally be removed after a full Garbage Collection (GC) procedureis triggered in JVM. However, if a Mule application's memory consumption is not significantly high and the GC procedure is not triggered frequently, the temporary files may accumulate on the disk. Since they cannot be removed quickly, this can exhaust disk space. The solution is to:
- Vertically upsize the application.
- Alternatively, add the following code on the involved flow to explicitly trigger the GC:
<logger level="INFO" doc:name="Trigger full GC" doc:id="31669a1e-2246-4d3c-823e-9460e5162d33" message='#[%dw 2.0
output application/json
var rv = java!java::lang::Runtime::getRuntime().gc()
---
"Explicitly trigger System.gc() " ++ if (rv == null) "finished" else "failed"]' />Conclusion
Implementing these best practices will allow you to design efficient, reliable, and scalable batch-processing solutions in MuleSoft. Properly designed batch jobs can easily handle large volumes of data with minimal resource consumption and will ensure smooth and effective integration processes.
Published at DZone with permission of PRAVEEN SUNDAR. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments