Accelerate Innovation by Shifting Left FinOps: Part 4
Part 4 of this series covers cost optimization techniques for applications in the evolving practice of FinOps.
Join the DZone community and get the full member experience.
Join For FreeWe have understood the importance of cost models and how to create and refine cost models. In Part 3 of this series, we learned how to optimize our workload components, specifically cost optimization techniques for infrastructure. In this post, we will learn about the techniques for cost optimization of the application layer components(layer highlighted in blue).
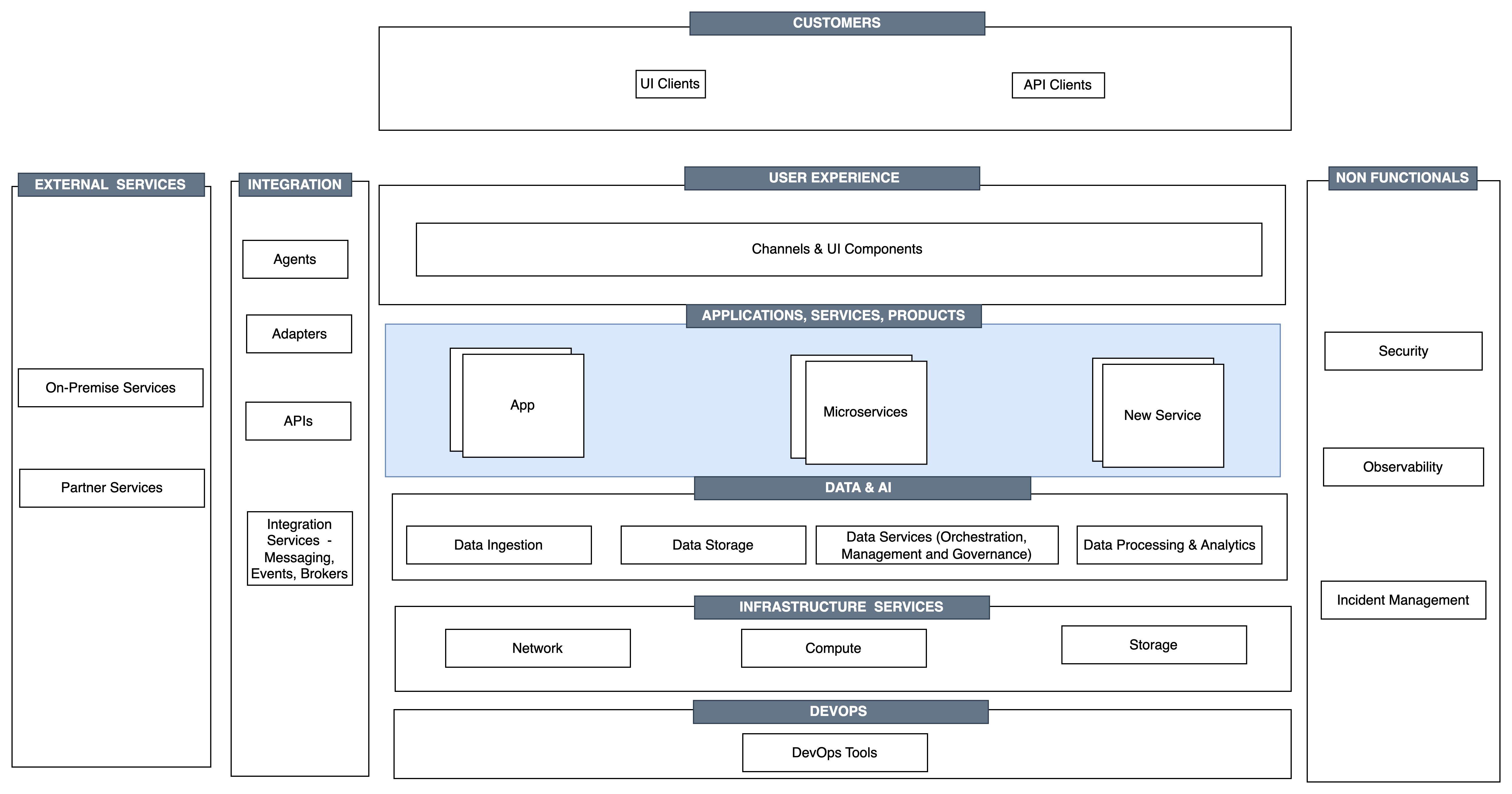
Key architecture components for a cloud-deployed workload.
There are various techniques that you can use to optimize cost based on the application design and architecture. The techniques are detailed below:
- Component Realization
- Job Slicing and Scheduling
- Incorporating a Control Plane
- Application Integration
Component Realization
Component realization ensures that the most optimal infrastructure components are always selected for each part of the application. For example, a microservice has code that needs to run; it takes data from storage and processes it, writing it back to storage. Can this code run as serverless? If not, can it be in a container? What are the storage requirements? Is it high performance (block) or low performance (object)? By always selecting the best resources for the application components, the solution is most aligned to the requirements. It also enables future upgrades and improvements if new resources or services become available from the vendor.
The first step is to review the application components and ensure the right compute is leveraged for the realization of the component.
Job Slicing and Scheduling
Job slicing breaks down large jobs into multiple smaller jobs, which greatly improves the flexibility in how and when the jobs are processed. This not only improves the flexibility of the workload but increases the flexibility across all of your environments. Slicing offers the following benefits:
- Run in parallel: this can increase performance by allowing you to use multiple resources to complete the task, or complete the job in the same time with fewer resources. It also increases resilience; if an interruptible resource was used, only a small portion of the processing is impacted and can be recovered more easily.
- Flexibility of resource size: If you can slice the job and slice it into different sized pieces, you can use different sized resources. This allows you to utilize a wider variety of resources in your environment that are not used or increase the density of container style platforms.
- Variety of resources: Slicing also allows you to use different types of resources, using a service such as AWS Spot Fleet that automatically manages the allocation of Spot Instances based on your requirements and will provide resources at the lowest cost and with the lowest chance of interruption. The spot instances are cheater than On-demand instances and can provide compute capability at times up to 90% less cost. Other resources like network may have different cost based on the time of usage. For instance, data transfer cost may be less if you can plan your data transfer during off-peak hours.
- Variety of services: Depending on the job type and the size, you may consider alternatives for auto scale group of EC2 instances to be replaced by an EMR (Elastic Mapreduce) job. The EMR option could save money with regard to development and deployment, as well as keep the running cost less compared to running your microservice on EC2 with auto scaling.
Job scheduling allows you to either manually or programmatically decide when the job will execute. This will provide the following benefits:
- Batch Services: You can use services such as AWS batch to schedule jobs and optimize resources that are used.
- Unused resources: You can utilize existing resources within your environments that are unused. Similar to containers, you can use the same resource for different jobs at different times, allowing you to apply commitment discounts to the resource and achieve significant savings.
Guidance
It is a good practice to estimate the job timelines and the required computing and services to support the job. It is recommended to implement both slicing and scheduling for maximum flexibility both within your workload and across your workloads. It also increases workload resilience & future upgradability. The application component or the job needs to be designed in such a way that it takes advantage of these benefits with job slicing and scheduling.
Incorporating a Control Plane
For a multi-tenanted cloud application, it is recommended to have a control plane to ensure there is a separation of customer workloads. Another important aspect depending on the job size and projection of the compute needed, this control layer can schedule the jobs to be run on specific infrastructure. For example, you can schedule the bigger customer workloads on a more powerful cluster, and the smaller jobs can be provisioned a smaller clusters. This T-shirt sizing of the application infrastructure and scheduling the right jobs on the right infrastructure can be taken care of by this control layer. Another value add that this control layer can bring in is to schedule jobs to run during non-peak hours, reduce the number of instances required, or shut down the instances as soon as the jobs are complete, thus saving money on compute costs. Importantly this control plane layer has the view into the tasks for all customers and can make intelligent calls to ensure the tasks are scheduled as per priority and are completed quickly. Ultimately, the control plane choices shall depend on the specific needs of your workload.
A thorough cost analysis can help you determine which option is more cost-effective. In cases where data is missing, a Proof of Engineering (PoE) is recommended. As part of the PoE, the application needs to be monitored and analyzed with observability and Application Performance Management (APM) tools like AWS CloudWatch and Datadog. Based on the analysis, the application's performance and costs can be further optimized.
Batch vs. Real-Time
Batch and real-time techniques can both be used to optimize application costs, depending on the specific requirements of your workload. Once you confirm the data availability and processing requirements for your use case, you can select whether you want to do Batch processing or Real-time processing. Batch processing usually runs for a longer periods and can be run on lower-cost resources. These are ideal for workloads that are not time-sensitive. For use cases, requiring immediate processing and response Real-time Processing is recommended. Real-time processing is typically more expensive than Batch processing as they requires additional infrastructure for notification (SNS), queueing(SQS), and Event Processing (Kinesis, Kafka) capabilities. These elements cannot be run on spot-instances. Real-time processing best fits for workloads requiring immediate response or event-driven workloads. So, depending on your application requirements, the choice needs to be made between Real-time or Batch.
Application Integration and Workflows
In certain cases, a combination of batch and real-time may be the best solution. You can look at introducing a process or job orchestration layer in the application architecture as applicable, depending on the requirement. This layer can be realized with engines or components available from the cloud. Ones such solution is to use AWS STEP function which allows you quickly design a workflow to applications through automating and orchestrating microservices or processes. Choreography-based orchestration of workflows can also be considered as an alternative to AWS Step Function. One such alternative is Camunda. Camunda is an open-source workflow and decision automation platform that allows you to model, execute, monitor, and optimize business processes. Camunda can be deployed on-premises or in the cloud, with support for AWS, Azure, and Google Cloud. It also provides a REST API and various SDKs, making it easy to integrate with other systems and services. STEP functions have certain limitations based on the number of events the state machine can support. So, the number of parallel jobs that you can execute may be limited. The selection of an appropriate orchestration/choreography platform can be based on the functionality required and in a cost-optimal manner.
Apart from the workflow aspects, choosing the right integration platform that aligns with your requirements and budget is an important consideration. There are several open-source solutions or cloud-based platforms that can reduce infrastructure costs and provide scalability. Evaluate the options based on resource utilization, dynamic scalability, serverless architecture, and automation capabilities that give you the best performance at reduced cost.
In the next part of this series, we will discuss how to optimize the cost of data components of your solution,
Opinions expressed by DZone contributors are their own.
Comments