Model Compression: Improving Efficiency of Deep Learning Models
Model compression is a key component of real-time deployment of deep learning models. This article explores different approaches to make models more efficient.
Join the DZone community and get the full member experience.
Join For FreeIn recent years, deep learning models have steadily improved performance in Natural Language Processing (NLP) and Computer Vision benchmarks. While part of these gains comes from improvements in architecture and learning algorithms, a significant driver has been the increase in dataset sizes and model parameters.
The following figure shows the top-1 ImageNet classification accuracy as a function of GFLOPS which can be used as a metric for model complexity.
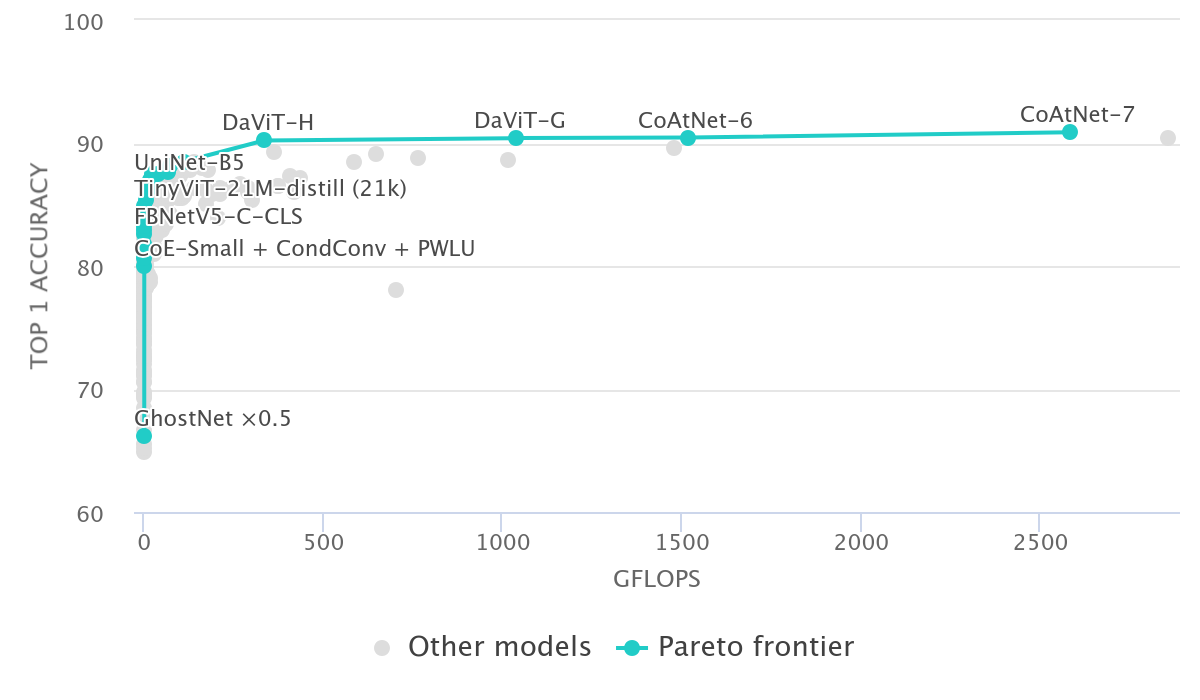
Scaling up data and model complexity seems to be the dominant trend and multi-billion or even trillion-parameter models are not uncommon. While these large models have impressive performance the sheer scale of these models makes it impossible to be used on edge devices or for latency-critical applications.
This is where model compression comes in. The goal of model compression is to reduce the model’s parameter count and/or latency while minimizing the drop in performance. There are several approaches but they can be grouped into three main categories:
- Pruning
- Quantization
- Knowledge Distillation (KD)
There are other approaches as well, like low-rank tensor decomposition, but we won't cover them in this article. Let’s go over these three primary techniques in detail.
Pruning
With pruning, we can make a model smaller by removing less important weights (neuron connections) or layers from a neural network. A simple strategy can be to remove a neuron connection if the magnitude of its weight falls below a threshold. This is called weight pruning and it ensures that we remove connections that are redundant or can be removed without affecting the final result much.
Similarly, we can remove a neuron itself based on some metric of its importance, e.g., the L2 norm of outgoing weights. This is called neuron pruning and is generally more efficient than weight pruning. 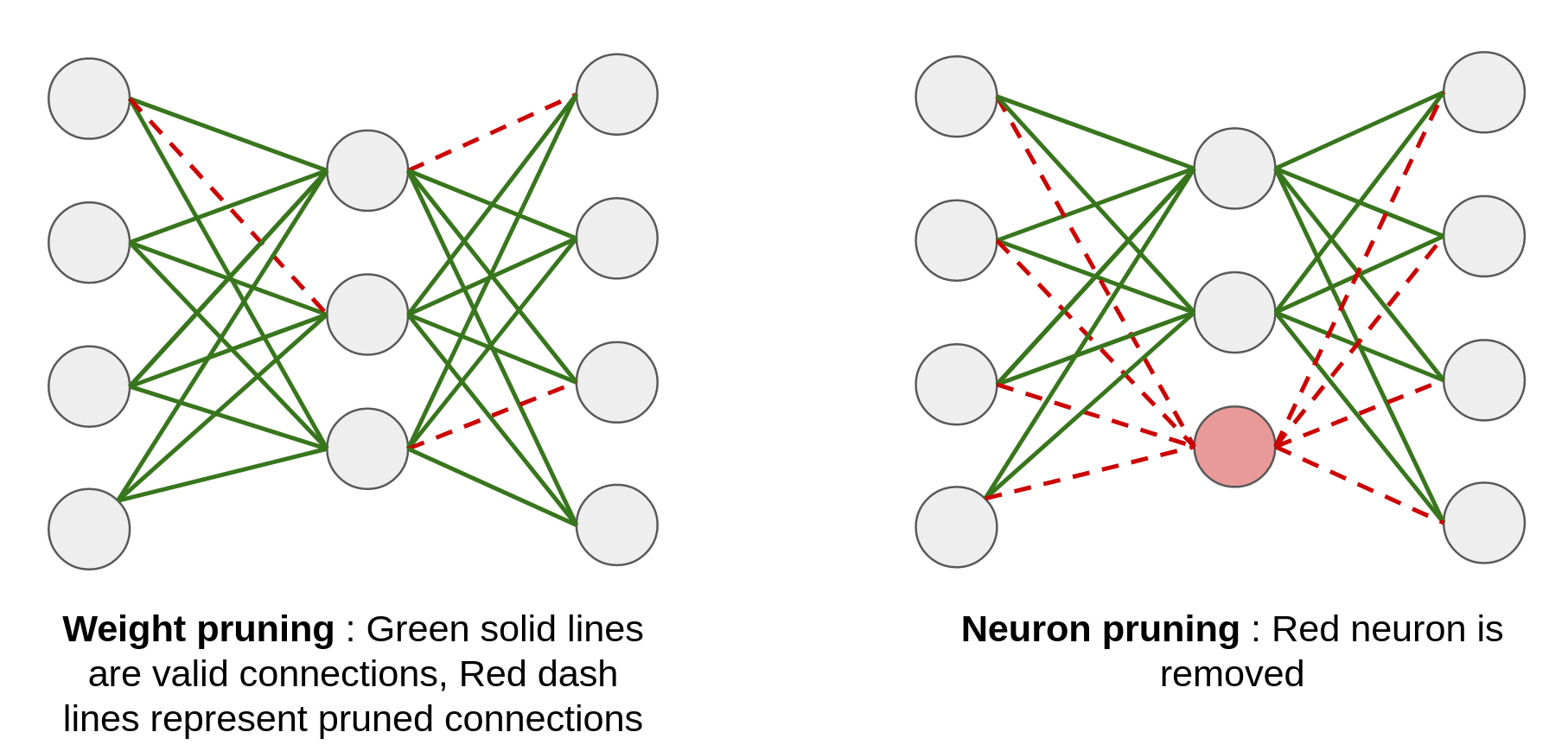
Another advantage of node pruning over weight pruning is that the latter leads to a sparse network which can be hard to optimize on hardware like GPU. Though it would reduce the memory footprint and FLOPS, it might not translate to reduced latency. The idea of pruning can be extended to CNNs as well where the relative importance of a filter/kernel can be determined based on its L1/L2 norm and only the important filters can be retained. In practice, pruning is an iterative process where we alternate between pruning and fine-tuning the model.
Using this approach we can achieve a minimal drop in performance while cutting down network parameters by over 50% as shown in the image below: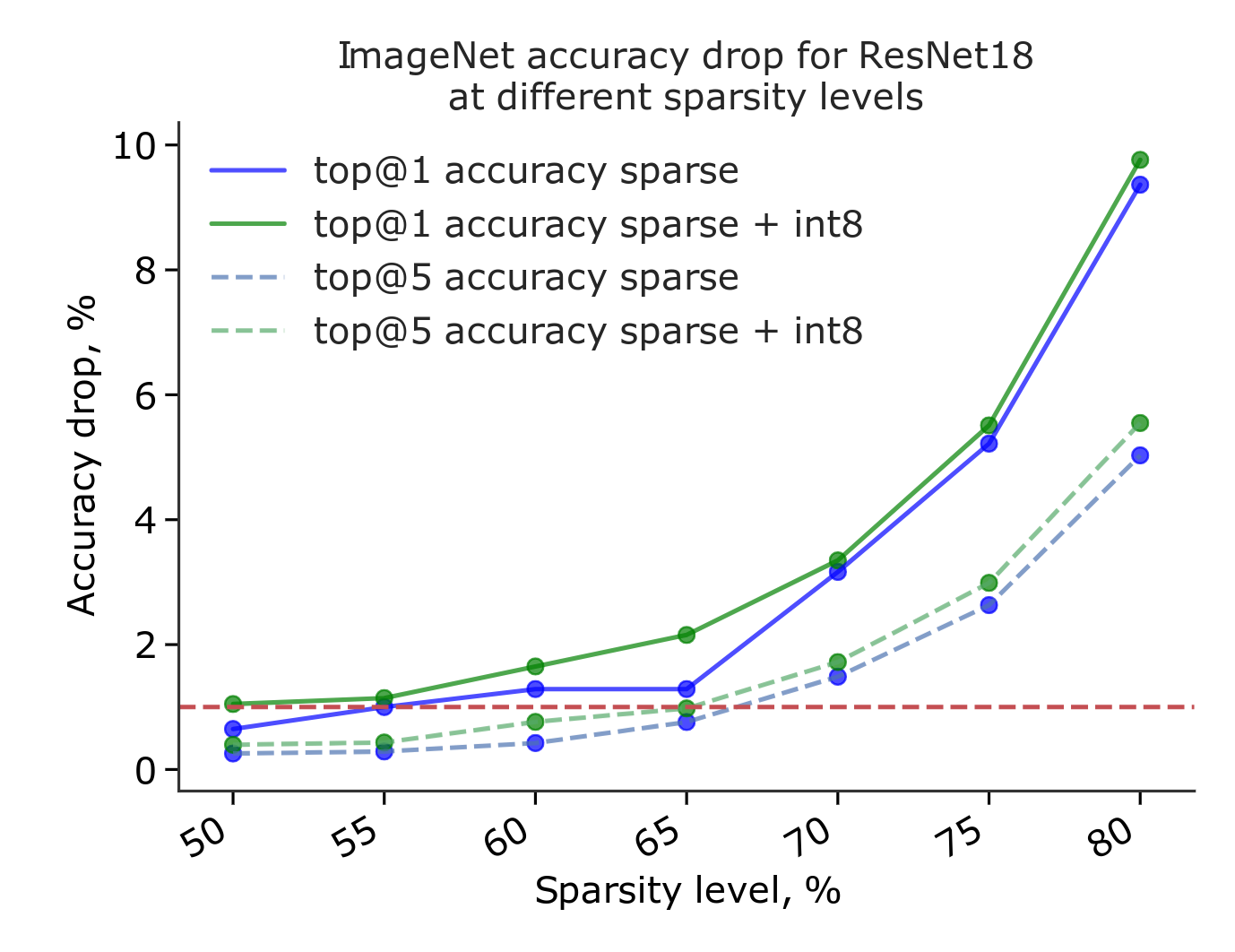
Quantization
The main idea behind quantization-based model compression is to reduce the precision of model weights to reduce memory and latency. Generally, deep learning models during or after training have their weights stored as 32-bit floating point (FP32). With quantization, these are generally converted to 16- (FP16) or 8-bit (INT8) precision for runtime deployment.
Quantization can be split into two categories:
Post-Training Quantization (PTQ)
This involves quantization of weights and activations post training and is achieved through a process called calibration. The goal of this process is to figure out a mapping from original to target precision while minimizing information loss. To achieve this we use a set of samples from our dataset and run inference on the model, tracking the dynamic range for different activations in the model to determine the mapping function.
Quantization Aware Training (QAT)
The main problem with training with lower precision weights and activations is that the gradients are not properly defined so we can't do backpropagation. To solve this problem using QAT, the model simulates target precision during forward pass but uses the original precision for the backward pass to compute gradients.
While PTQ is easy to implement and doesn't involve retraining the model, it can lead to degradation in performance. QAT, on the other hand, generally has better accuracy than PTQ but is not as straightforward to implement and increases training code complexity.
From a mathematical standpoint, quantization and calibration for a given weight/activation involves determining two values: the scale and zero point. Say we wanted to convert from FP32 to INT8:
# max_int for INT8 would be 255 and min_int 0
# max_float, min_float are deteremined in the calibration process
scale = (max_float - min_float) / (max_int - min_int)
# to allow for both positive and negative values to be quantized
zero_point = round((0 - min_float) / scale)
int8_value = round(fp32_value / scale) + zero_pointKnowledge Distillation
Knowledge distillation (KD) as the name suggests tries to distill or transfer the knowledge of the original model in this case called the teacher model to a smaller model called the student model. There are several ways to achieve this but the most common ones try to match the output or the intermediate feature representation of the teacher model with the student model. Interestingly, the student model trained on a combination of ground truth labels + soft labels from the teacher model's output performs better than trained on ground truth labels alone, and at times can even match the performance of the teacher model. One hypothesis for this behavior is that since the soft labels contain more information than ground truth labels (hard labels; e.g., zero-hot), it helps the student model generalize better.
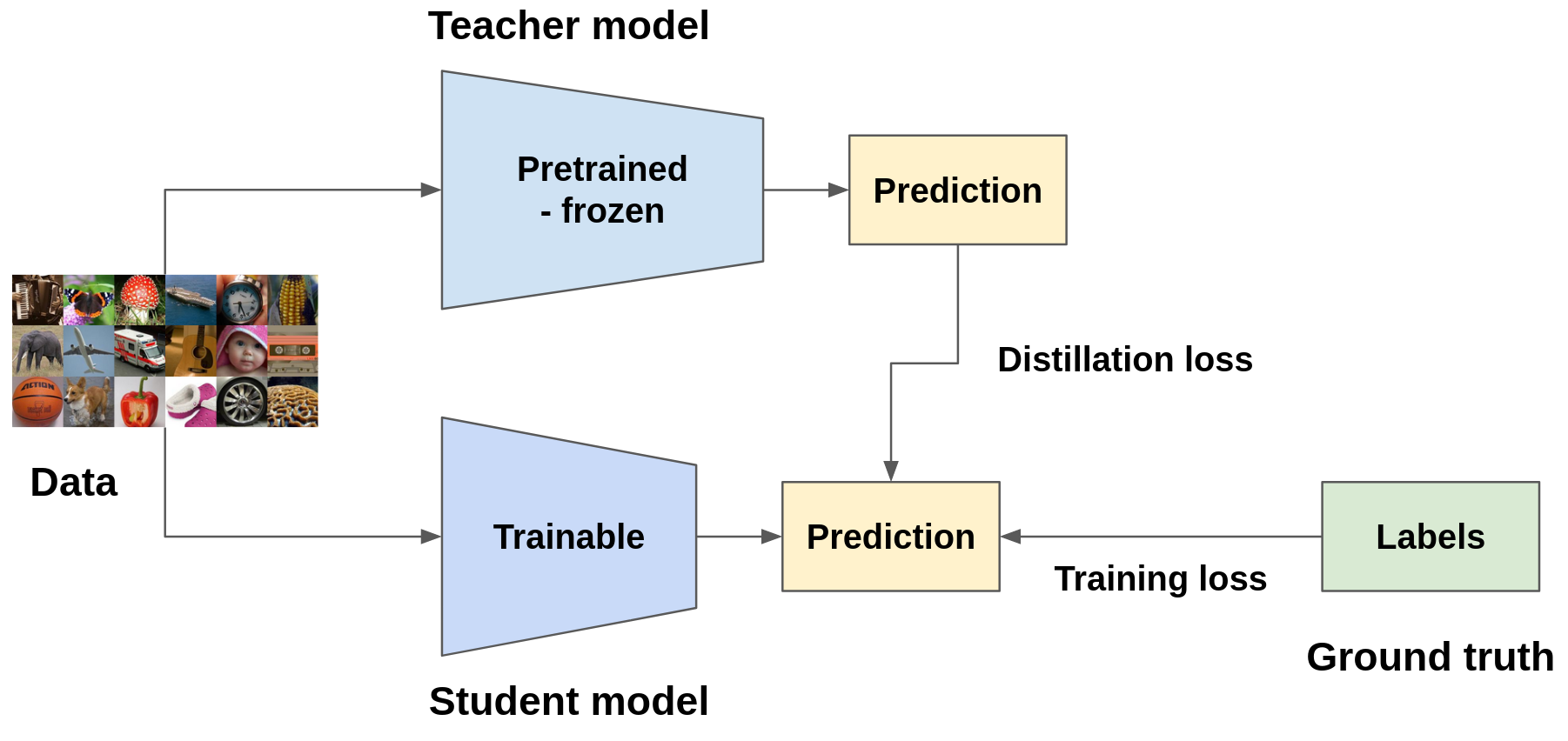
Knowledge distillation is one of the more flexible model compression techniques because the resulting model can have a different architecture than the original model and has potential for larger memory and latency reduction compared to pruning or quantization. However, it is also the most complex to train since it involves training the teacher model, followed by designing and training the student model.
Conclusion
In practice, it's common to combine multiple compression techniques together — e.g., KD followed by PTQ or Pruning — to achieve desired result in terms of compression and accuracy.
Opinions expressed by DZone contributors are their own.
Comments