In-House Model Serving Infrastructure for GPU Flexibility
In this article, learn how to create a GPU SKU-agnostic serving infrastructure for flexibility, efficiency, and resilience.
Join the DZone community and get the full member experience.
Join For FreeAs deep learning models evolve, their growing complexity demands high-performance GPUs to ensure efficient inference serving. Many organizations rely on cloud services like AWS, Azure, or GCP for these GPU-powered workloads, but a growing number of businesses are opting to build their own in-house model serving infrastructure. This shift is driven by the need for greater control over costs, data privacy, and system customization. By designing an infrastructure capable of handling multiple GPU SKUs (such as NVIDIA, AMD, and potentially Intel), businesses can achieve a flexible and cost-efficient system that is resilient to supply chain delays and able to leverage diverse hardware capabilities. This article explores the essential components of such infrastructure, focusing on the technical considerations for GPU-agnostic design, container optimization, and workload scheduling.
Why Choose In-House Model Serving Infrastructure?
While cloud GPU instances offer scalability, many organizations prefer in-house infrastructure for several key reasons:
- Cost efficiency: For predictable workloads, owning GPUs can be more cost-effective than constantly renting cloud resources.
- Data privacy: In-house infrastructure ensures complete control over sensitive data, avoiding potential risks in shared environments.
- Latency reduction: Local workloads eliminate network delays, improving inference speeds for real-time applications like autonomous driving and robotics.
- Customization: In-house setups allow fine-tuning of hardware and software for specific needs, maximizing performance and cost-efficiency.
Why Serve Multiple GPU SKUs?
Supporting multiple GPU SKUs is essential for flexibility and cost-efficiency. NVIDIA GPUs often face long lead times due to high demand, causing delays in scaling infrastructure. By integrating AMD or Intel GPUs, organizations can avoid these delays and maintain project timelines.
Cost is another factor — NVIDIA GPUs are premium, while alternatives like AMD offer more budget-friendly options for certain workloads (see comparison on which GPU to get). This flexibility also allows teams to experiment and optimize performance across different hardware platforms, leading to better ROI evaluations. Serving multiple SKUs ensures scalability, cost control, and resilience against supply chain challenges.
Designing GPU-Interchangeable Infrastructure
Building an in-house infrastructure capable of leveraging various GPU SKUs efficiently requires both hardware-agnostic design principles and GPU-aware optimizations. Below are the key considerations for achieving this.
1. GPU Abstraction and Device Compatibility
Different GPU manufacturers like NVIDIA and AMD have proprietary drivers, software libraries, and execution environments. One of the most important challenges is to abstract the specific differences between these GPUs while enabling the software stack to maximize hardware capabilities.
Driver Abstraction
While NVIDIA GPUs require CUDA, AMD GPUs typically use ROCm. A multi-GPU infrastructure must abstract these details so that applications can switch between GPU types without major code refactoring.
- Solution: Design a container orchestration layer that dynamically selects the appropriate drivers and runtime environment based on the detected GPU. For example, containers built for NVIDIA GPUs will include CUDA libraries, while those for AMD GPUs will include ROCm libraries. This abstraction can be managed using environment variables and orchestrated via Kubernetes device plugins, which handle device-specific initialization.
Cross-SKU Scheduling
Infrastructure should be capable of automatically detecting and scheduling workloads across different GPUs. Kubernetes device plugins for both NVIDIA and AMD should be installed across the cluster. Implement resource tags or annotations that specify the required GPU SKU or type (such as tensor cores for H100 or Infinity Fabric for AMD).
- Solution: Use custom Kubernetes scheduler logic or node selectors that match GPUs with the model's requirements (e.g., FP32, FP16 support). Kubernetes custom resource definitions (CRDs) can be used to create an abstraction for various GPU capabilities.
2. Container Image Optimization for Different GPUs
GPU containers are not universally compatible, given the differences in underlying libraries, drivers, and dependencies required for various GPUs. Here’s how to tackle container image design for different GPU SKUs:
Container Images for NVIDIA GPUs
NVIDIA GPUs require CUDA runtime, cuDNN libraries, and NVIDIA drivers. Containers running on NVIDIA GPUs must bundle these libraries or ensure compatibility with host-provided versions.
- Image Setup: Use NVIDIA's CUDA containers as base images (e.g.,
nvidia/cuda:xx.xx-runtime-ubuntu) and install framework-specific libraries such as TensorFlow or PyTorch, compiled with CUDA support.
Container Images for AMD GPUs
AMD GPUs use ROCm (Radeon Open Compute) and require different runtime and compiler setups.
- Image setup: Use ROCm base images (e.g.,
rocm/tensorflow) or manually compile frameworks from a source with ROCm support. ROCm's compiler toolchain also requires HCC (Heterogeneous Compute Compiler), which needs to be installed.
Unified Container Registry
To reduce the maintenance overhead of managing different containers for each GPU type, a unified container registry with versioned images tagged by GPU type (e.g., app-name:nvidia, app-name:amd) can be maintained. At runtime, the container orchestration system selects the correct image based on the underlying hardware.
Driver-Independent Containers
Alternatively, consider building driver-agnostic containers where the runtime dynamically links the appropriate drivers from the host machine, thus eliminating the need to package GPU-specific drivers inside the container. This approach, however, requires the host to maintain a correct and up-to-date set of drivers for all potential GPU types.
3. Multi-GPU Workload Scheduling
When managing infrastructure with heterogeneous GPUs, it is essential to have an intelligent scheduling mechanism to allocate the right GPU SKU to the right model inference task.
GPU Affinity and Task Matching
Certain models benefit from specific GPU features such as NVIDIA’s Tensor Cores or AMD’s Matrix Cores. Defining model requirements and matching them to hardware capabilities is crucial for efficient resource usage.
- Solution: Integrate workload schedulers like Kubernetes with GPU operators, such as NVIDIA GPU Operator and AMD ROCm operator, to automate workload placement and GPU selection. Fine-tuning the scheduler to understand model complexity, batch size, and compute precision (FP32 vs. FP16) will help assign the most efficient GPU for a given job.
Dynamic GPU Allocation
For workloads that vary in intensity, dynamic GPU resource allocation is essential. This can be achieved using Kubernetes' Vertical Pod Autoscaler (VPA) in combination with device plugins that expose GPU metrics.
4. Monitoring and Performance Tuning
GPU Monitoring
Utilize telemetry tools like NVIDIA’s DCGM (Data Center GPU Manager) or AMD’s ROCm SMI (System Management Interface) to monitor GPU usage, memory bandwidth, power consumption, and other performance metrics. Aggregating these metrics into a centralized monitoring system like Prometheus can help identify bottlenecks and underutilized hardware.
Performance Tuning
Periodically benchmark different models on available GPU types and adjust the workload distribution to achieve optimal throughput and latency.
Latency Comparisons
Below are the latency comparisons between NVIDIA and AMD GPUs using a small language model, llama2-7B, based on the following input and output settings (special callout to Satyam Kumar for helping me run these benchmarks).
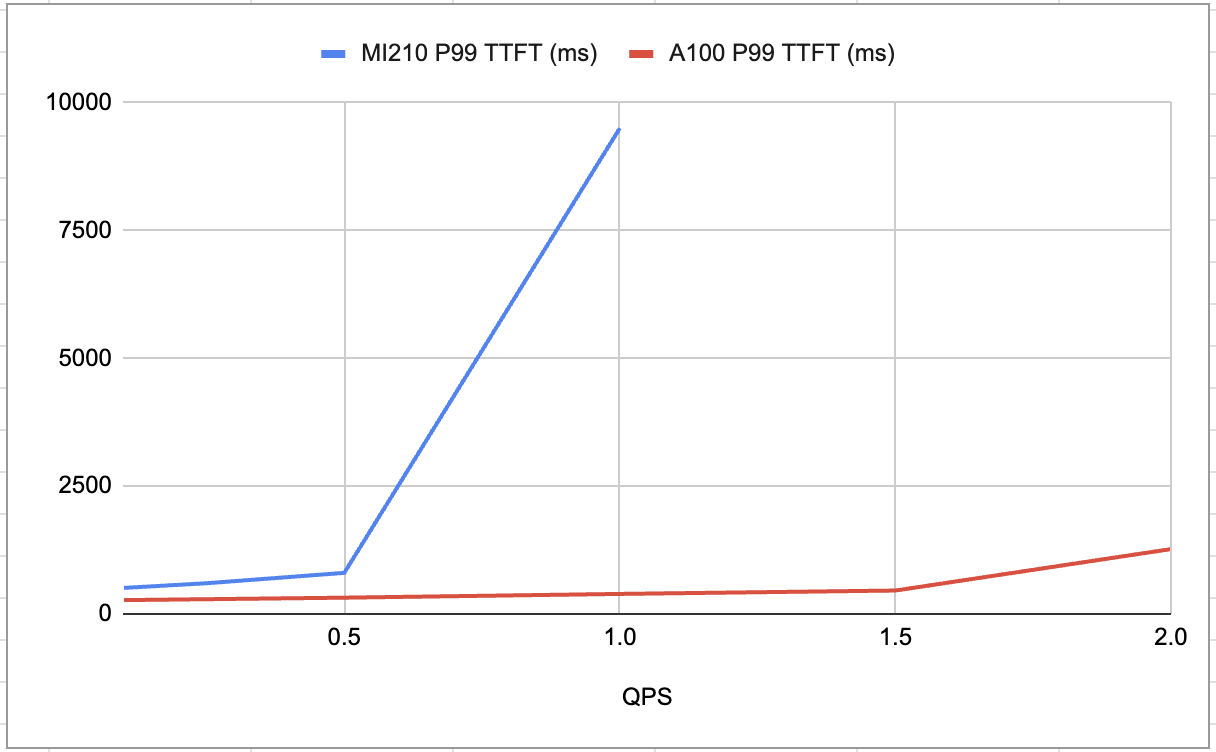
Figure 1: AMD’s MI210 vs NVIDIA’s A100 P99 latencies for TTFT (Time to First Token)
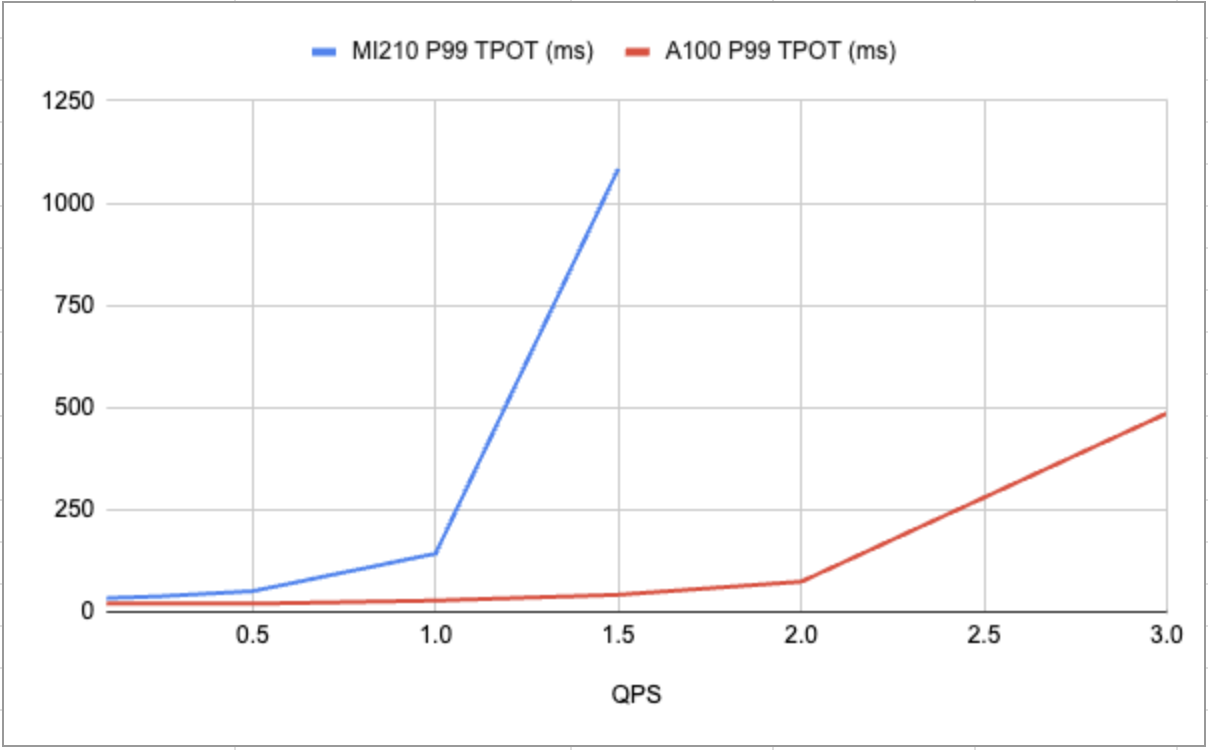
Figure 2: AMD’s MI210 vs NVIDIA’s A100 P99 latencies for TPOT (Time per output token)
Here is another blog based on performance and cost comparison: AMD MI300X vs. NVIDIA H100 SXM: Performance Comparison on Mixtral 8x7B Inference, which can help in making decisions about when to use which hardware.
Conclusion
The in-house model serving infrastructure provides businesses with greater control, cost-efficiency, and flexibility. Supporting multiple GPU SKUs ensures resilience against hardware shortages, optimizes costs, and allows for better workload customization. By abstracting GPU-specific dependencies, optimizing containers, and intelligently scheduling tasks, organizations can unlock the full potential of their AI infrastructure and drive more efficient performance.
Opinions expressed by DZone contributors are their own.
Comments