In-Memory Data Grids
Join the DZone community and get the full member experience.
Join For FreeIntroduction
The IT buzzword of 2012 is without a doubt Big Data. It’s new and here to stay, and for a good reason. Big data is data that exceeds the processing capacity of conventional database systems.
Great examples are CERN with the Large Hadron Collider, whose experiments generate 25 petabytes of data annually, or Walmart, which handles more than one million customer transaction every hour.
Problems
These vast amounts of data leave us with two problems.
- Problem 1: To gain value from this data, one must choose an alternative way to process it. The value of big data to an organization falls into two categories: analytical use, and enabling new products. Big data analytics can reveal insights hidden previously by data too costly to process, such as peer influence among customers, revealed by analyzing shoppers’ transactions, social and geographical data. Being able to process every item of data in reasonable time removes the troublesome need for sampling and promotes an investigative approach to data, in contrast to the somewhat static nature of running predetermined reports.
- Problem 2: The data is too big, moves too fast, or doesn’t fit the strictures of your database architectures. Remember the CERN case where the LHC produces over 25 Petabytes of data annually? No “classic” database architecture or setup is capable of holding these amounts of data.
Solutions
Fortunately, both problems can be solved by implementing the correct infrastructure and rethinking data storage. There are two critical factors in Big Data environments: size and speed. We already discussed the vast amounts of data and desire to be able to access and process the data fast. The latter is the main differentiator from more traditional data warehouses. Just imagine what you can do when you can access all your data real-time. Enter big data.
A common Big Data implementation is an in-memory data grid that lives in a distributed cluster, ensuring both speed, by storing data in-memory, and capacity by using scalability features provided by a cluster. As a bonus, availability is ensured by using a distributed cluster. As for the data storage, there are typically two kinds: in-memory databases and in-memory data grids.
But first some background. It is not a new attempt to use main memory as a storage area instead of a disk. In our daily lives there are numerous examples of main memory databases (MMDB), as they perform much faster than disk-based databases. An every day example is a mobile phone. When you SMS or call someone most mobile service providers use MMDB to get the information on your contact as soon as possible. The same applies to your phone. When someone calls you, the caller details are looked up in the contacts application, usually providing a name and sometimes a picture.
In memory data grids
In Memory Data Grid (IMDG) is the same as MMDB in that it stores data in main memory, but it has a totally different architecture. The features of IMDG can be summarized as follows:
- Data is distributed and stored on multiple servers.
- Each server operates in the active mode.
- A data model is usually object-oriented (serialized) and non-relational.
- According to the necessity, you often need to add or reduce servers.
- No traditional database features such as tables.
In other words, IMDG is designed to store data in main memory, ensure scalability and store an object itself. These days, there are many IMDG products, both commercial and open source. Some of the most commonly used products are:
- Hazelcast (http://www.hazelcast.com)
- JBoss Infinispan (http://www.jboss.org/infinispan)
- GridGain DataGrid (http://www.gridgain.com/features/in-memory-data-grid/)
- VMware Gemfire (http://www.vmware.com/nl/products/application-platform/vfabric-gemfire/overview.html)
- Oracle Coherence (http://www.oracle.com/technetwork/middleware/coherence/overview/index.html)
- Gigaspaces XAP (http://www.gigaspaces.com/datagrid)
- Terracotta Enterprise Suite (http://terracotta.org/products/enterprise-suite)
Why Memory?
The main reasons for using main memory for data storage are once again the two main themes of Big Data: speed and capacity. The processing performance of main memory is 800 times faster than an HDD and up to 40 times faster than an. Moreover, the latest x86 server supports main memory of hundreds of GB per server.
It is said that the limit of a traditional processing database’s (OLTP) data capacity is approximately 1 TB and that the OLTP processing data capacity would not increment well. If servers using main memory of 1 TB or larger become more commonly used, you will be able to conduct operations with the entire data placed in main memory, at least in the field of OLTP.
IMDG Architecture
To use main memory as a storage area, two weak points should be overcome:
- Limited capacity: involves data that exceeds the maximum capacity of the main memory of the server
- Reliability: involves data loss in case of a (system) failure.
IMDG overcomes the limit of capacity by ensuring horizontal scalability using a distributed architecture, and resolves the issue of reliability through a replication system as part of the grid (or a distributed cluster).
Now let’s discuss how an IMDG actually works. First of all, it is important to understand that an IMDG is not the same as an in-memory database, also referred to as MMDB (main memory databases). Typical examples of MMDBs are Oracle TimesTen or Sap Hana. MMDBs are full database products that simply reside in memory. As a result of being a full-blown database, they also carry the weight and overhead of database management features. IMDG is different. No tables, indexes, triggers, stored procedures, process managers etc. Just plain storage.
The data model used in IMDG is key-value pairs. A key-value pair is a list with only two parts: a key and a value. The key can be used for storing and retrieving the values in the list. A key can be compared to the index or primary key of a table in a database. Note that IMDG are closely tied to development environments such as Java as the key-value pairs are represented by the structures provided by such a programming environment. Most IMDGs are written in Java, and can only be used within other Java applications. Therefore, the values of key-value pairs can be anything supported by Java, ranging from simple data types such as a string or number, to complex objects. This overcomes the two important hurdles: as you can store complex Java objects as value, there’s no need to translate these objects into a relational datamodel (which is the case in more traditional applications using a database for storage). Furthermore, the seeming limitation of being able to store only one value per key, is actually no limitation at all.
Large memory sizes
Most of the products introduced above use Java as an implementation language. Java reserves and uses a part of the RAM (internal memory) for dynamic memory allocation. This reserved memory space is called the Java heap. All runtime objects created by a Java application are stored in heap.
Using large amounts of data causes two problems.
- Size limitation: By default, the heap size is 128 MB, but for current business applications, this limit is reached easily. Once the heap is “full”, no new objects can be created and the Java application will show some nasty errors.
- Performance: It is possible to increase the size of the heap, but this introduces some new problems. When a heap reaches a size of more than 4 gigabytes, Java will have serious issues with memory managements, causing your application to slow down or even freeze. Java has a feature called Garbage Collector, which periodically scans the heap and checks each object if it is still valid and being used. If not, the garbage collector removes the object and defragments the newly available space. The problem is, the larger the heap size, the more work to do for the garbage collector, resulting in performance degradation.
Imagine a large bank has a Java application that manages customers, accounts and transactions. We have seen that an IMDG allows the application to store and access all data very quickly by caching it in memory, instead of storing the data in relatively slow databases. Let’s assume the combined data has a size of 40 gigabytes. Storing it in heap is simply not possible, considering the performance penalties of Java’s memory management capabilities.
The graph below illustrates the garbage collection pause time when placing cached data in heap:
Terracotta’s BigMemory product has a method to overcome these limitations. The method is to use an off-heap memory (direct buffer). Data will not be stored in Java’s heap, but directly in the available internal memory (RAM). Since, this is not subject to Java’s garbage collector, there are no performance penalties. The differences on performance are significant, as can be seen in the graph below:
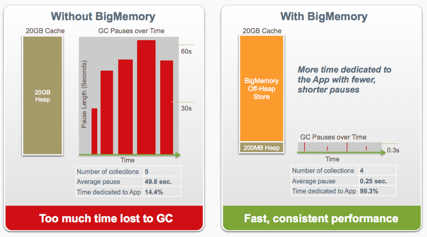
Using off-heap storage has some major benefits:
- You can use all the available memory on your machine, not just the memory that is allocated to the heap (usually less that 512 Mb). This allows you to store more data in a in-memory data grid, greatly speeding up your application.
- The heap can be relieved by storing data in native memory, speeding up Java applications as less heap space has to be garbage collected.
Clustering, fail over and high availability
So far, we have seen IMDG features that are applicable to a single server. However, the real power of IMDG lies in it’s networking and clustering capabilities, providing features as data replication, data synchronization between clients, fail over and high availability. To achieve this, a cluster of servers (or server array) acts a backbone of the infrastructure. Applications (that still can have their own IMDG or off-heap cache) that are connected to the cluster can share, replicate and backup their data with either the cluster or other applications.
The graph below depicts a typical setup using Terracotta's BigMemory:
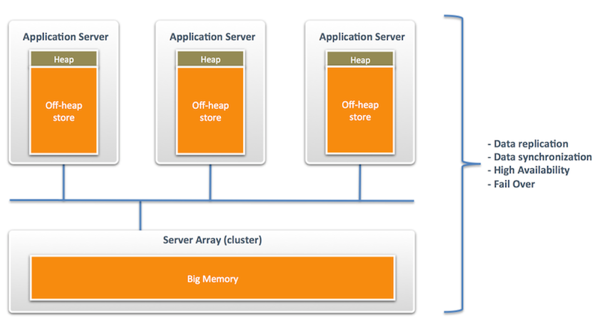
The caches on the application servers are usually referred to as “level 1” cache, while the data cache on the server array is referred to as “level 2” cache. There are many different scenarios possible for storing, clustering, synchronizing and replicating data. Covering all these topics goes far beyond the scope of this article. For more information, consult the technical documentation of the product of your choice.
Conclusion
Big Data brings us some new challenges. First of all, storing and accessing vast amounts of data makes us rethink traditional methods and technologies. Next, there’s the question what to do with all the available data. The potential value for marketing, financial and other businesses is huge.
In order to facilitate Big Data, in-memory data grids are considered the best option. IMDGs with off-heap storage are even more powerful, allowing data centric enterprise application to overcome certain limits of the Java platform, such as memory and performance constraints.
As the amount of data that (large) companies produce and store, grows exponentially, databases will hit a limit. Accessing your data without a performance penalty simply will not be possible. The answer to this is using an IMDG.
Opinions expressed by DZone contributors are their own.
Comments