The Magic of Apache Spark in Java
An experience software architect runs through the concepts behind Apache Spark and gives a tutorial on how to use Spark to better analyze your data sets.
Join the DZone community and get the full member experience.
Join For FreeApache Spark is an innovation in data science and big data. Spark was first developed at the University of California Berkeley and later donated to the Apache Software Foundation, which has maintained it since. Spark is 100x faster than similar big-data technologies like Hadoop.
Apache Spark was not designed just for data engineers. The majority of people who use Apache Spark are developers. But, there is a problem - if you search the internet, most of the resources are based on the Scala and Spark, so you may think that Spark APIs are designed just for Scala. In fact, Spark has great APIs and integration for Java that makes Java stronger for work with big data. In this article, I will try to explain a little bit about Spark and then dive in to the usage of Apache Spark in Java.
Note: In this article, every time I use the word Spark, I use the prefix Apache so as not to be confused with absolutely different web framework named Spark Java.
Apache Spark in a Nutshell
Apache Spark is a strong, unified analytics engine for large scale data processing. Spark has grown very rapidly over the years and has become an important part of enterprise architecture. Internet powerhouses such as Netflix, Amazon, NASA, TripAdviser, and eBay are using Spark at massive scale. They are using it for processing petabytes of data on clusters of over 8,000 nodes.
Apache Spark provides high-level APIs in Scala, Java, Python, and R and programmers with these APIs are able to work with massive data and large scale data processing.
Features of Apache Spark
Speed
Spark provides 100x faster processing speeds for applications because it stores the intermediate processing data in memory and does not have any read and write to disk unless you ask it to do. In the case, you asked it to use disk it acts 10x faster than regular technologies like Hadoop.
Multi Language Support
Spark has direct API's for Java, Scala, and Python.
Advance Analytics Component
Unlike Hadoop, Spark does not just support MapReduce, it also has components like SQL queries, machine learning, and graph algorithms that satisfy the needs of technologists.
Spark Execution Model
Actually, Spark is a distributed processing engine and follows master-slave architecture. Like every master-slave system, there is one master node and some slave nodes that follow the master node. In Spark, the master node is called the driver and the slave nodes are called the executers. Suppose that you want to execute application A1 with Spark. Spark will create one driver node and some executers to execute application A1.
If you want to execute application A2, the same process will be created for A2.
![]() Spark Driver
Spark Driver
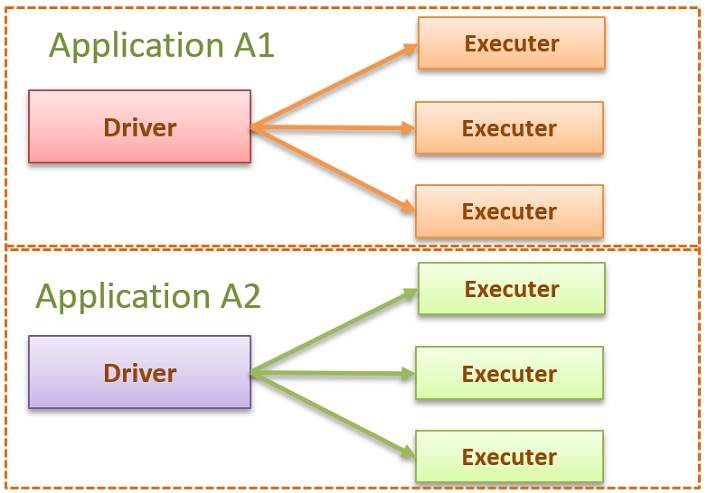 Spark Driver
Spark DriverResponsible for analyzing, distributing, scheduling, and monitoring work across the executers.
Spark Executor
Executors are the main worker. Jobs are completely or partially assigned to them by the driver and they execute the jobs and give results and feedback to the driver.
Apache Spark Deployment Modes
Client Mode
The driver starts on your local machine, but the executors run on clusters.
Cluster Mode
Drivers and executors are all in the clusters. Since Apache Spark does not have any embedded cluster managers, it relies on third-party cluster managers like Apache Yarn, Apache Mesos, or standalone.
Local Mode
Everything will start in a single JVM. This mode is not very practical and is mostly used for debugging and development purposes - all samples in this article will be done in this mode.
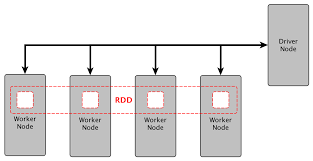
Resilient Distributed DataSet (RDD)
Before getting into the details of Apache Spark, let's take a look at a very important concept in Spark named Resilient Distributed Data sets. RDD is the fundamental data structure in Spark. It is an immutable, distributed collection of objects. Each data set in RDD is divided into logical partitions, which may be computed on different nodes of clusters. RDD contains Java, Python, and Scala objects, including user defined classes.
You are not qualified as a Spark developer until you understand RDD in detail, because it is a fundamental technique used to represent data in Spark's memory.
As mentioned before, RDD can be created from many resources. Take a look at the below sample code to create RDD in Java from a sample text file named "myText.txt".
xxxxxxxxxx
JavaRDD<String> distFile = sc.textFile("myText.txt");
RDD supports two types of operations: Actions and Transformations.
Transformations
Transformations are simply the building of new RDDs from existing RDDs. They take an RDD for an input and produce one or more RDDs as an output. Consider the following sample info that RDD created from inputRDD.
x
JavaRDD<String> inputRdd = sparkContext.textFile("myText.txt");
JavaRDD<String> infoRdd = inputRdd.filter(new Function<String,Boolean>(){
public Boolean call(String input){
return input.contains("INFO");
}
});
Actions
Unlike transformations, the output of an Action is not RDD, it is, rather, an operation like "count."
x
JavaRDD<String> distFile = sc.textFile("myText.txt");
int totalLength = distFile.count();
Note: Spark is lazy and all operations will trigger once they are called at runtime.
There is another concept, called a DataFrame, which also is resilient and distributed that used in processing data. A DataFrame is a distributed collection of data which organized into named columns. It is conceptually equivalent to tables in relational data bases (RDBMS).
Datasets are the latest concept in this area. Spark Datasets are an extension of the Dataframes API with the benefits of both RDDs and Datasets. It is fast as well, as it provides a type-safe interface. Type safety means that the compiler will validate the data types of all the columns in the dataset during compilation only and will throw an error if there is any mismatch in the data types.

RDD. vs DataFrame vs. DataSet
| RDD | DataFrame | DataSet | |
| Data Representation | RDD is a distributed collection of data elements without any schema. | It is also the distributed collection organized into the named columns. | It is an extension of Dataframes with more features like type-safety and object-oriented interface. |
| Optimization | No in-built optimization engine for RDDs. Developers need to write the optimized code themselves. | It uses a catalyst optimizer for optimization. | It also uses a catalyst optimizer for optimization purposes. |
| Aggregation operation |
RDD is slower than both Dataframes and Datasets to perform simple operations like grouping the data. | It provides an easy API to perform aggregation operations. It performs aggregation faster than both RDDs and Datasets. | Dataset is faster than RDDs, but a bit slower than Dataframes. |
Apache Spark Components
Spark has six main components that empower its functionality and all of these components are tightly integrated.
Spark Core
Spark Core is the heart of Apache Spark and all the functionalities provided by Spark are built on top of Spark Core. Spark Core provides in memory computation to increase the performance and speed of Apache Spark. This component provides the following functionality: RDD, IO-related functionality, task dispatching, and fault recovery.
Spark SQL
Spark SQL provides native support for SQL to query data stored in resources such a RDD or any external resources. CSV, JSON, JDBC are some of the resources that are supported by Spark SQL.
Like any other SQL supported platform, Spark has a standard functions. You can see some Spark SQL supported functions in the below table - we will also look at a real world example later in this article.
| Aggregate Functions | count, AVG, First, Grouping, Last, Max, Min, SUM |
| Standard expressions | select, to_date, add_month, and, or, any |
| Filters | like, contains, starts with, ends with |
Spark ML
SparkML brings machine learning capabilities to the Spark ecosystem and provides tools such as:
- Common learning algorithms, such as classification, clustering, collaborative filtering, and SVN.
- Featurization: feature selection, extraction, and transformation.
- Utilities: linear algebra and statistics.
Spark Streaming
Spark Streaming is an extension of Spark Core that allows data engineers and data scientists to process data from various sources like Kafka, Flume, and Amazon Kinesis. This processed data can be pushed directly to a database, file system, or live dashboard.
GraphX
GraphX is a new component in the Apache Spark ecosystem that's designed for graphs and graph parallel computation. Since social networks modeling gets more and more important every day, using graph parallel algorithms for such scaled data has become a trend. GraphX provide the ability to deal with these algorithms; if you are interested in this field, you can find more information here.
Installing Apache Spark
In this part, we want to install Spark in the simplest way as we can, because we just want to use it for a development exercise. Live environment installations would be different and more sophisticated.
To get started, follow these steps:
- Download Spark 3 from here.
- Extract a binary zip file from the desired directory.
- Go to the sbin directory inside the Spark directory.
- Start the master node with this command:
start-master.sh
[Reza-Ganjis-MacBook-Pro:sbin Reza$ ./start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /Users/Reza/desktop/spark/spark-3.1.1-bin-hadoop2.7/logs/spark-Reza-org.apache.spark.deploy.master.Master-1-Reza-Ganjis-MacBook-Pro.local.out
Reza-Ganjis-MacBook-Pro:sbin Reza$
- start the slave node with the command:
start-worker.sh spark://master machine name:7077
x
my computer name is "Reza-Ganjis-MacBook-Pro.local" so the execution will be like this
Reza-Ganjis-MacBook-Pro:sbin Reza$ ./start-worker.sh spark://Reza-Ganjis-MacBook-Pro.local:7077
starting org.apache.spark.deploy.worker.Worker, logging to /Users/Reza/desktop/spark/spark-3.1.1-bin-hadoop2.7/logs/spark-Reza-org.apache.spark.deploy.worker.Worker-1-Reza-Ganjis-MacBook-Pro.local.out
Reza-Ganjis-MacBook-Pro:sbin Reza$
- Spark is now up in HTTP at port 8080:
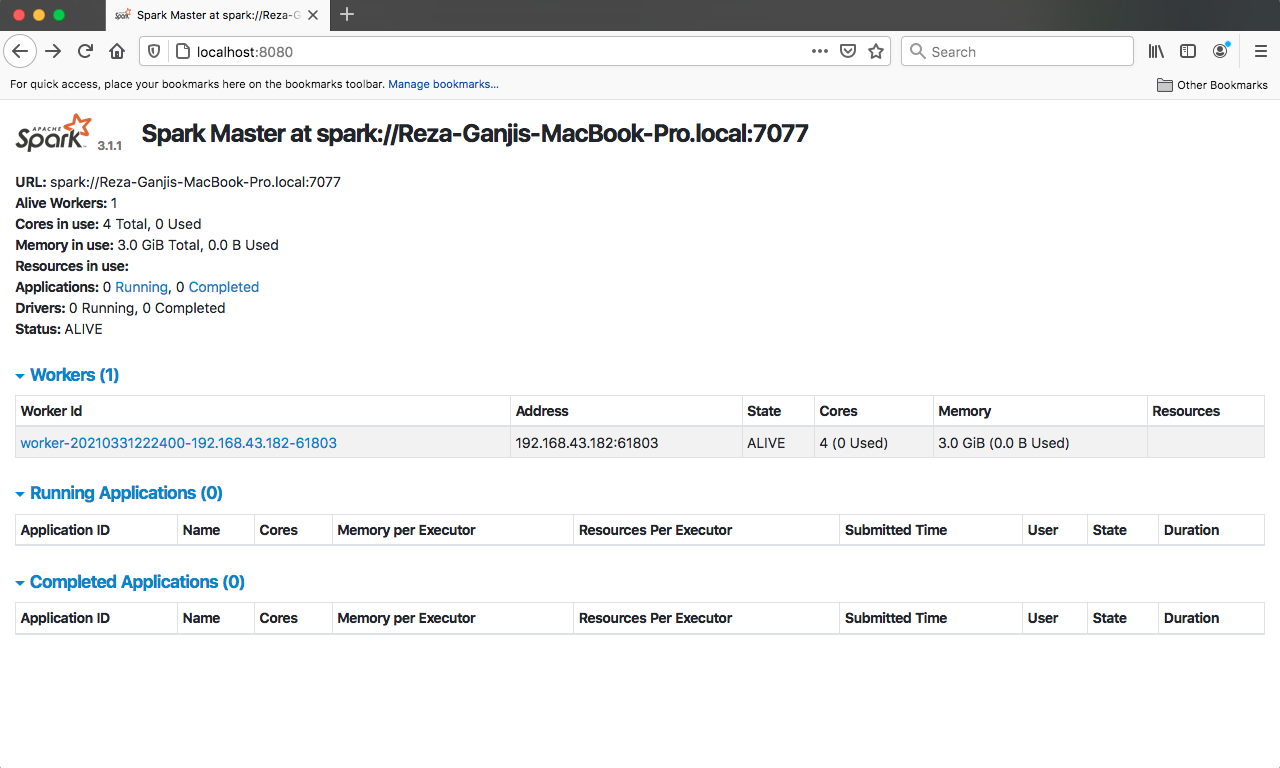
Apache Spark in Java
Let's start by adding the following Maven dependencies to your project:
x
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.1.1</version>
</dependency>
SparkSession is the unified entry point of Apache Spark. You should first define the variable from type SparkSession. Before Spark 2.0, SparkContext was the entry point. SparkSession has every thing you need to create your Spark app:
SparkSession spark=SparkSession.builder().master("local[*]").getOrCreate();
The above code shows how to create a simple Spark session. As you can see, there is a method named master. Where there's an actual Spark master (driver) server, I am using locale[*] - this acts as a kind of development mode and it's a starter cluster for you and has one executor per core. You can also create SparkSession from a remote driver with the following code, but, in our examples, we just use a local mode.
xxxxxxxxxx
SparkSession spark=SparkSession.builder().master("spark:\\Driver IP:7077").getOrCreate();
We created a SparkSession in the above code. Actually, we call the machine that instantiates the SparkSession the driver, as it contains the context and communicates with the Cluster Manager to launch the executions on the workers (executors).
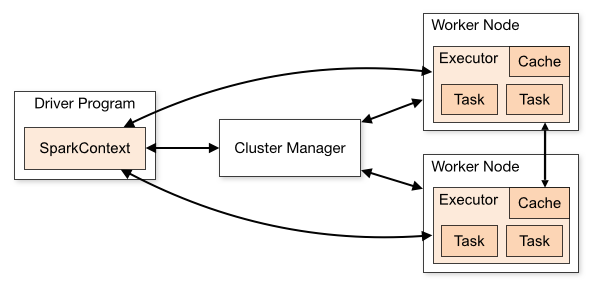
As the above picture shows, the driver contains the program and Spark Context sends the job to the workers via the Cluster Manager. You have an arbitrary number of workers; in the workers you have executors; in that, you have tasks and 'tasks are like a thread.' When you start in local mode the driver and the worker are on the same JVM or if you start in the cluster mode they are started on a separate JVM.
Okay, Enough Theoretical Concepts
Let's continue with a simple example. First, we have a CSV file with following data (the data is very simple and clear):
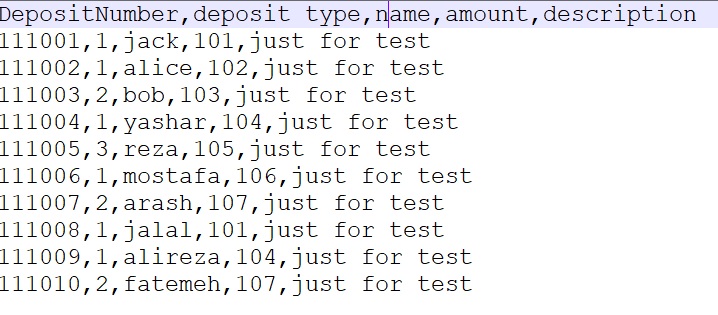
With the following code, we show the file content and schema:
xxxxxxxxxx
import org.apache.spark.sql.*;
public class SparkBonusTest {
private static final String CSV_URL="bonus.csv";
public static void main(String args[]){
SparkSession spark=SparkSession.builder().master("local[*]").getOrCreate();
Dataset<Row> csv = spark.read().format("csv")
.option("sep", ",")
.option("inferSchema", "true")
.option("header", "true")
.load(CSV_URL);
csv.show();
csv.printSchema();
}
}
This code calls a read method from Spark Context and tell it that the format of the file you should read is CSV. The separator between columns is ' , ' and the file has header ' inferSchema ' which tells Spark to automatically guess the data type. Finally, csv.show() prints the header and content. Here is the execution result:
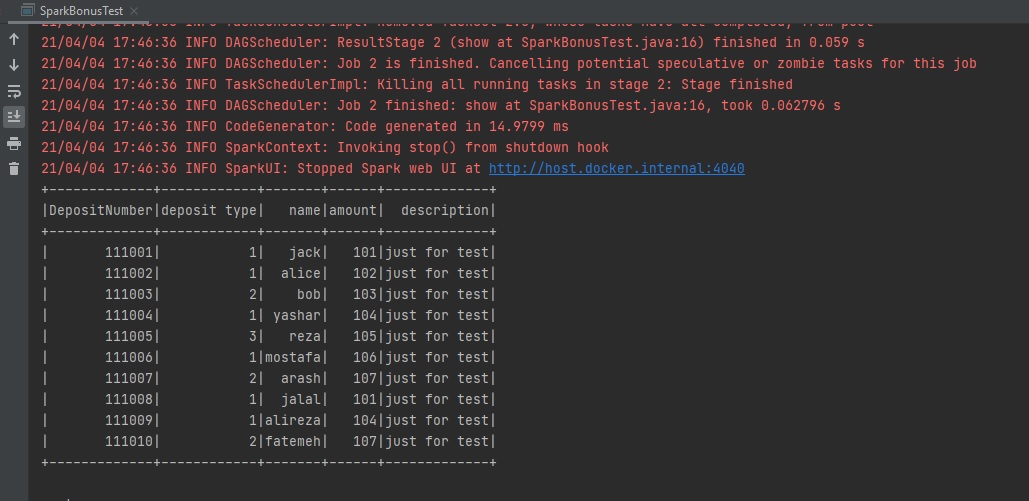
Let's take a quick but deeper look at the above code to review the driver and executor responsibilities in Spark. The red code executed by the driver and green codes by the executor.

Spark Filter, Most Widely Used Function
The Spark filter() or the where() function are used to filter the rows from DataFrame or Dataset based on the given one or multiple conditions or SQL expressions.
Example: show the rows where the name 'reza' appears.
xxxxxxxxxx
import org.apache.spark.sql.*;
public class SparkBonusTest {
private static final String CSV_URL="bonus.csv";
public static void main(String args[]){
SparkSession spark=SparkSession.builder().master("local[*]").getOrCreate();
Dataset<Row> csv = spark.read().format("csv")
.option("sep", ",")
.option("inferSchema", "true")
.option("header", "true")
.load(CSV_URL);
csv.filter("name like 'reza'").show();
csv.printSchema();
}
}
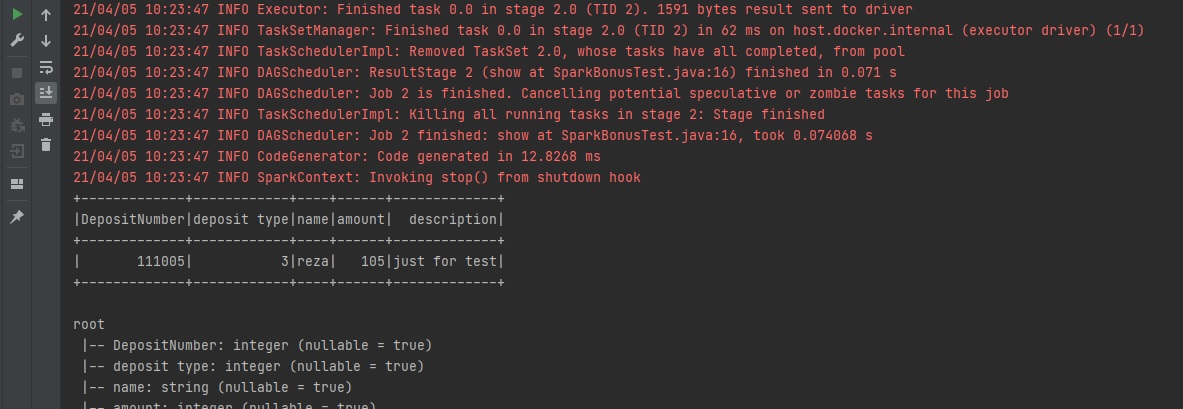
Example: Show the rows with an amount greater than 103:
x
import org.apache.spark.sql.*;
public class SparkBonusTest {
private static final String CSV_URL="bonus.csv";
public static void main(String args[]){
SparkSession spark=SparkSession.builder().master("local[*]").getOrCreate();
Dataset<Row> csv = spark.read().format("csv")
.option("sep", ",")
.option("inferSchema", "true")
.option("header", "true")
.load(CSV_URL);
csv.filter("amount >102").show();
csv.printSchema();
}
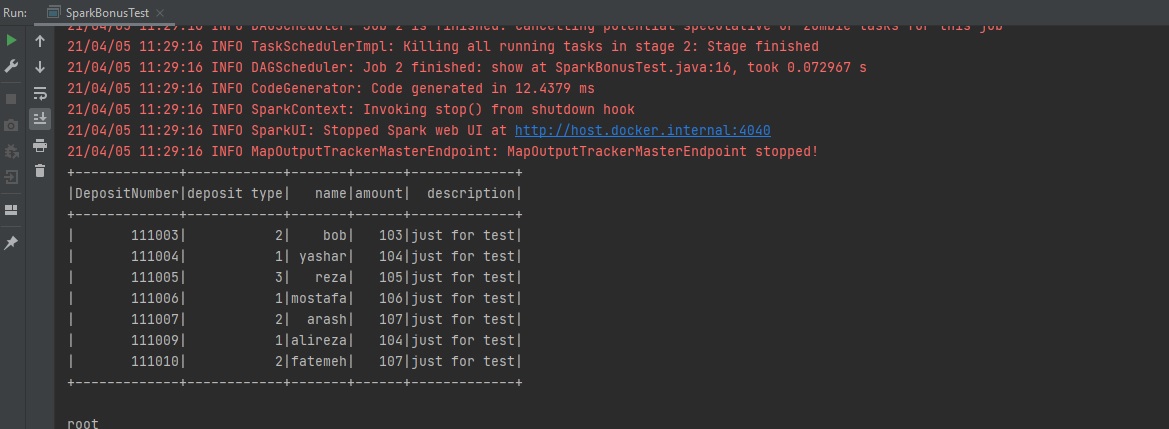
Can Query Expressions Be Written in a Better Way
The answer is absolutely yes; you can simply use Scala functions to improve the readability of your code. Let's look at this example:
xxxxxxxxxx
import org.apache.spark.api.java.function.FilterFunction;
import org.apache.spark.sql.*;
public class SparkBonusTest {
private static final String CSV_URL = "bonus.csv";
public static void main(String args[]) {
SparkSession spark = SparkSession.builder().master("local[*]").getOrCreate();
Dataset<Row> csv = spark.read().format("csv")
.option("sep", ",")
.option("inferSchema", "true")
.option("header", "true")
.load(CSV_URL);
csv.filter(new FilterFunction<Row>() {
public boolean call(Row row) throws Exception {
return row.getAs("amount").equals(102);
}
}).show();
csv.printSchema();
}
}
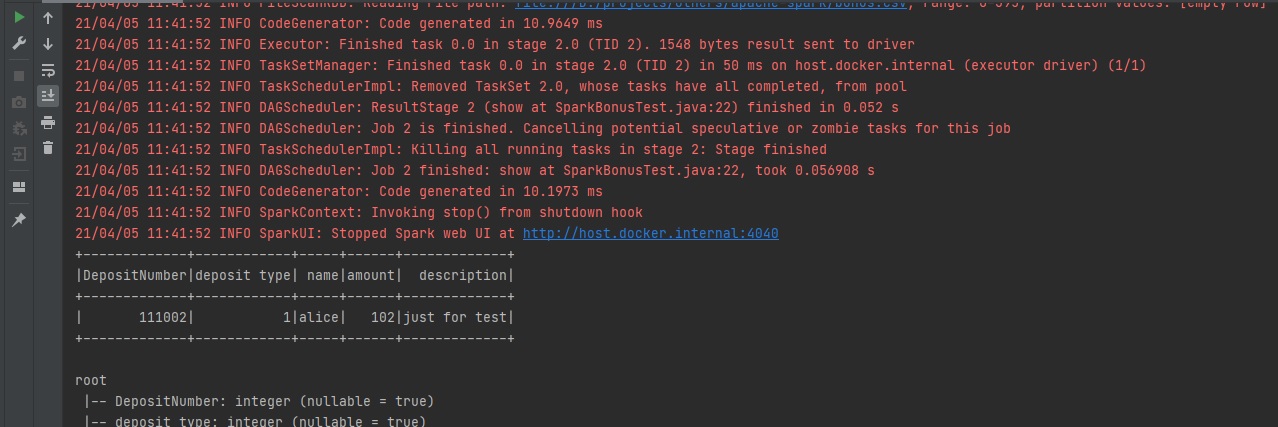
User Defined Functions (UDF)
As you saw in the previous example, you can use some standard functions as a filter. There is a feature named UDF that allows you to define your custom functions. Consider this example: in the sample CSV file there is a column named deposit type that has a value of 1,2,3. We want to print Short Term Deposit instead of 1, Long Term Deposits instead of 2 and Current Deposit instead of 3:
xxxxxxxxxx
import org.apache.spark.sql.*;
import org.apache.spark.sql.api.java.UDF1;
import org.apache.spark.sql.types.DataTypes;
import static org.apache.spark.sql.functions.callUDF;
import static org.apache.spark.sql.functions.col;
public class SparkBonusTest {
private static final String CSV_URL = "bonus.csv";
private static final String ACTUAL_DEPOSIT_FUNCTION = "getActualDepositType";
private static final String SHORT_TERM_DEPOSIT = "Short Term Deposit";
private static final String LONG_TERM_DEPOSIT = "Long Term Deposit";
private static final String CURRENT_DEPOSIT = "Current Deposit";
public static void main(String args[]) {
SparkSession spark = SparkSession.builder().master("local[*]").getOrCreate();
Dataset<Row> csv = spark.read().format("csv")
.option("sep", ",")
.option("inferSchema", "true")
.option("header", "true")
.load(CSV_URL);
spark.udf().register(ACTUAL_DEPOSIT_FUNCTION, getAccurateDepositType, DataTypes.StringType);
csv.withColumn("deposit name", callUDF(ACTUAL_DEPOSIT_FUNCTION, col("deposit type"))).show();
}
private static final UDF1 getAccurateDepositType = new UDF1<Integer, String>() {
public String call(final Integer i) throws Exception {
switch (i) {
case 1:
return SHORT_TERM_DEPOSIT;
case 2:
return LONG_TERM_DEPOSIT;
case 3:
return CURRENT_DEPOSIT;
}
return null;
}
};
}
There is a method named withColumn that adds or replaces a new column to your data set:
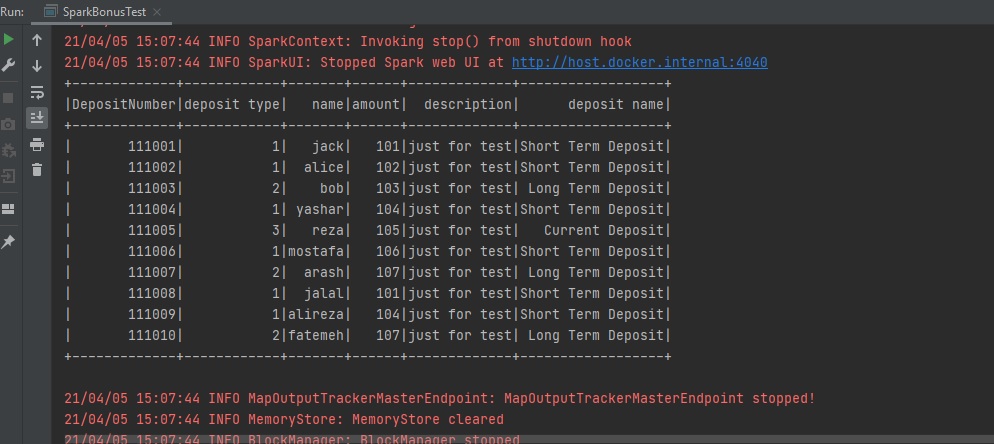
Spark Aggregate Function
groupBy is the key function in this part. Before applying every aggregate function you should first call the groupBy function and then call the desired aggregate function. Let's look at some examples.
Example: Show the sum of amounts per deposit type:
xxxxxxxxxx
import org.apache.spark.sql.*;
import static org.apache.spark.sql.functions.col;
public class SparkBonusTest {
private static final String CSV_URL = "D:/projects/others/apache-spark/bonus.csv";
private static final String ACTUAL_DEPOSIT_FUNCTION="getActualDepositType";
public static void main(String args[]) {
SparkSession spark = SparkSession.builder().master("local[*]").getOrCreate();
Dataset<Row> csv = spark.read().format("csv")
.option("sep", ",")
.option("inferSchema", "true")
.option("header", "true")
.load(CSV_URL);
csv.groupBy(col("deposit type")).sum("amount").show();
}
}
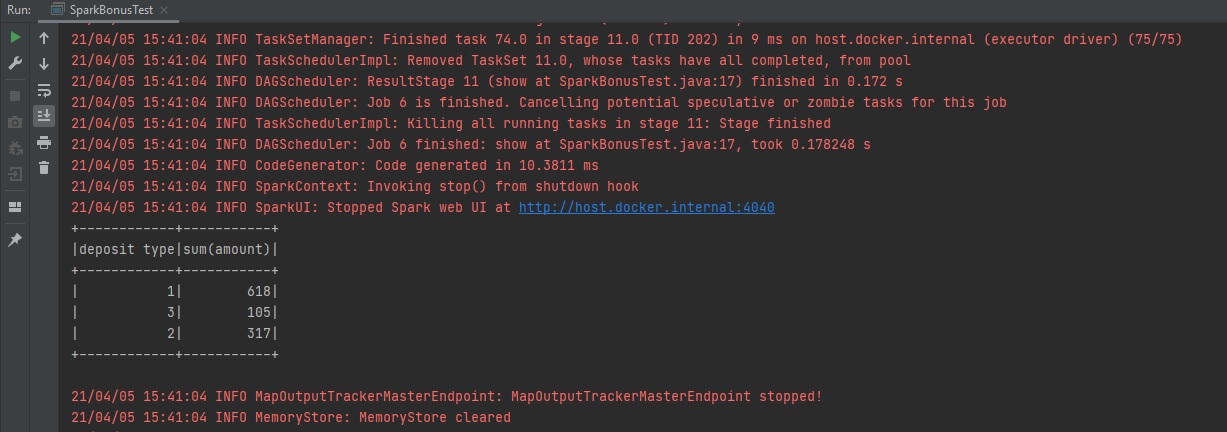
To do it in a more complex way, let's show the average of the amount per deposit type:
xxxxxxxxxx
import org.apache.spark.sql.*;
import org.apache.spark.sql.api.java.UDF1;
import org.apache.spark.sql.types.DataTypes;
import static org.apache.spark.sql.functions.callUDF;
import static org.apache.spark.sql.functions.col;
public class SparkBonusTest {
private static final String CSV_URL = "bonus.csv";
private static final String ACTUAL_DEPOSIT_FUNCTION = "getActualDepositType";
private static final String SHORT_TERM_DEPOSIT = "Short Term Deposit";
private static final String LONG_TERM_DEPOSIT = "Long Term Deposit";
private static final String CURRENT_DEPOSIT = "Current Deposit";
public static void main(String args[]) {
SparkSession spark = SparkSession.builder().master("local[*]").getOrCreate();
Dataset<Row> csv = spark.read().format("csv")
.option("sep", ",")
.option("inferSchema", "true")
.option("header", "true")
.load(CSV_URL);
spark.udf().register(ACTUAL_DEPOSIT_FUNCTION, getAccurateDepositType, DataTypes.StringType);
csv.withColumn("deposit name", callUDF(ACTUAL_DEPOSIT_FUNCTION, col("deposit type")))
.groupBy("deposit name").avg("amount").show();
}
private static final UDF1 getAccurateDepositType = new UDF1<Integer, String>() {
public String call(final Integer i) throws Exception {
switch (i) {
case 1:
return SHORT_TERM_DEPOSIT;
case 2:
return LONG_TERM_DEPOSIT;
case 3:
return CURRENT_DEPOSIT;
}
return null;
}
};
}
You can find all the functions and latest updates here.
More Work
Take a quick look at Apache Zeppelin.
Opinions expressed by DZone contributors are their own.
Comments