Looking for the Best Java Data Computation Layer Tool
This essay is a deep dive into 4 types of data computation layer tools (class libraries) to compare structured data computing capabilities and basic functionalities.
Join the DZone community and get the full member experience.
Join For FreeIn most cases, structured data is computed within the database in SQL. In a few other cases where the database is either absent or unavailable, Java programmers need to perform computations with Java. Hardcoding, however, involves a heavy workload. A more convenient alternative is the Java data computation layer tool (including library functions). The tool computes data and returns the result set. Here we examine the structured data computation abilities of several Java data computation layer tools.
1. SQL Engine for Files
This type of tool uses files, such as CSV and XLS, like physical database tables and offers a JDBC interface upward to allow programmers to compute the tables in SQL statements. There are many products of this type, such as CSVJDBC, XLSJDBC, CDATA Excel JDBC, and xlSQL, but none is mature enough to use conveniently. CSVJDBC is the most mature if we must pick one among them.
CSVJDBC is a free, open-source Java class library, which is naturally integration-friendly. Users just need to download a jar to integrate it with a Java program through the JDBC interface. Below is a part of the tab-separated text file d:\data\Orders.txt:
OrderID Client SellerId Amount OrderDate
26 TAS 1 2142.4 2009-08-05
33 DSGC 1 613.2 2009-08-14
84 GC 1 88.5 2009-10-16
133 HU 1 1419.8 2010-12-12
…
The following block of code reads in all records of the file and print them out in the console:
xxxxxxxxxx
package csvjdbctest;
import java.sql.*;
import org.relique.jdbc.csv.CsvDriver;
import java.util.Properties;
public class Test1 {
public static void main(String[] args) throws Exception {
Class.forName("org.relique.jdbc.csv.CsvDriver");
// Create a connection to directory given as first command line
String url = "jdbc:relique:csv:" + "D:\\data" + "?" + "separator=\t" + "&" + "fileExtension=.txt";
Properties props = new Properties();
// Can only be queried after specifying the type of column
props.put("columnTypes", "Int,String,Int,Double,Date");
Connection conn = DriverManager.getConnection(url,props);
// Create a Statement object to execute the query with.
Statement stmt = conn.createStatement();
//SQL: Conditional query
ResultSet results = stmt.executeQuery("SELECT * FROM Orders");
// Dump out the results to a CSV file/console output with the same format
CsvDriver.writeToCsv(results, System.out, true);
// Clean up
conn.close();
}
}
The Java class library has rather good support for hot deployment. This is because it implements computations in SQL and can conveniently separate the SQL query from the Java code. Users can modify a SQL statement directly without compiling or restart the application.
Though CSVJDBC is excellent in Java integration and hot deployment, they are not the core abilities of a Java data computation layer tool. Structured data computation ability is at the heart of the tool, but the JDBC driver has a bad one.
CSVJDBC supports only a limited number of basic computations, including conditional query, sorting and grouping, and aggregation.
xxxxxxxxxx
// SQL: Conditional query
ResultSet results = stmt.executeQuery("SELECT * FROM Orders where Amount>1000 and Amount<=3000 and Client like'%S%' ");
// SQL: order by
results = stmt.executeQuery("SELECT * FROM Orders order by Client,Amount desc");
// SQL: group by
results = stmt.executeQuery("SELECT year(Orderdate) y,sum(Amount) s FROM Orders group by year(Orderdate)");
Set-oriented operations, subqueries, and join operations are also part of the basic computations, but all of them are not supported. Even the several supported ones have a lot of problems. For instance, CSVJDBC requires that all file data be loaded into the memory for sorting and grouping, and aggregation operations, so it would be better if the file size is not too large.
SQL statements do not support debugging and perform badly. CSVJDBCA supports only CSV files. Other data formats, Database tables, Excel files, and JSON data, should be converted to CSV files for processing. The conversion is cost-inefficient as hardcoding or a third-party tool is needed.
2. dataFrame Generic Functions Library
This type of tool intends to simulate Python Pandas by providing generic data types similar to dataFrame, docking various data sources downward, and offering functional interface upward. Tablesaw, Joinery, Morpheus, Datavec, Paleo, Guava, and many others belong to this type. With Pandas being the successful precursor, this type of Java data computation layer tool fails to attract many followers, hence the reason they are generally poorly developed. Tablesaw (the latest version is 0.38.2), however, is the most developed one among them.
As a free, open-source Java class library, Tablesaw requires only the deployment of core jars and dependent packages to be integrated. The basic code generated by it is simple, too. To read in and print out all records of Orders.txt, for example, we have the following code:
xxxxxxxxxx
package tablesawTest;
import tech.tablesaw.api.Table;
import tech.tablesaw.io.csv.CsvReadOptions;
public class TableTest {
public static void main(String[] args) throws Exception{
CsvReadOptions options_Orders = CsvReadOptions.builder("D:\\data\\Orders.txt").separator('\t').build();
Table Orders = Table.read().usingOptions(options_Orders);
System.out.println(orders.print());
}
}
Besides CSV files, Tablsaw also supports other types of sources, including RDBMS, Excel, JSON, and HTML. Basically, it can satisfy the daily analytic work. The functional computations bring in a satisfactory debugging experience by supporting a set of functionalities, such as break a point, step, enter and exit while reducing hot deployment performance by requiring recompilement for any change of the algorithm.
Structured data computations are always our focus. Below are several basic computations:
xxxxxxxxxx
// Conditional query
Table query= Orders.where(
Orders.stringColumn("Client").containsString("S").and(
Orders.doubleColumn("Amount").isGreaterThan(1000).and(
Orders.doubleColumn("Amount").isLessThanOrEqualTo(3000)
)
)
);
// Sorting
Table sort = Orders.sortOn("Client", "-Amount");
//Grouping & aggregation
Table summary = Orders.summarize("Amount", sum).by(t1.dateColumn("OrderDate").year());
// Joins
CsvReadOptions options_Employees = CsvReadOptions.builder("D:\\data\\Employees.txt").separator('\t').build();
Table Employees = Table.read().usingOptions(options_Employees);
Table joined = Orders.joinOn("SellerId").inner(Employees,true,"EId");
joined.retainColumns("OrderID","Client","SellerId","Amount","OrderDate","Name","Gender","Dept");
For computations like sorting and grouping and aggregation operations that only need to take a few factors into consideration, the gap between Tablesaw and SQL are very small. If a computation, like conditional query and the join operation, involves a lot of factors, Tablesaw generates far more complicated code than SQL does. The reason is that Java, not intrinsically intended for structured data computing, must trade complicated code for an equal computing ability as SQL. Fortunately, the high-level language supports lambda syntax to be able to generate relatively intuitive code (though not as intuitive as SQL). The conditional query can be rewritten as follows:
xxxxxxxxxx
Table query2=Orders.where(
and(x->x.stringColumn("Client").containsString("S"),
and(
x -> x.doubleColumn("Amount").isGreaterThan(1000),
x -> x.doubleColumn("Amount").isLessThanOrEqualTo(3000)
)
)
);
3. Lightweight Databases
The characteristics of lightweight databases are small, easy to deploy, and convenient to integrate. Typical products of the lightweight databases include SQLite, Derby, and HSQLDB. Let’s take a special look at SQLite.
SQLite is free and open source. Only one jar is needed to do the integration and deployment. It is not a stand-alone system and usually runs within a host application, such as Java, through an API interface. When it runs on an external storage disk, it supports a relatively large data volume. When it runs in the memory, it performs better but supports a smaller data volume. SQLite adheres to the JDBC standards. For example, to print out all records of orders table in the external database exl, we have the following code:
xxxxxxxxxx
package sqliteTest;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class Test {
public static void main(String[] args) throws Exception {
Connection connection =DriverManager.getConnection("jdbc:sqlite/data/ex1");
Statement statement = connection.createStatement();
ResultSet results = statement.executeQuery("select * from Orders");
printResult(results);
if(connection != null)connection.close();
}
public static void printResult(ResultSet rs) throws Exception{
int colCount=rs.getMetaData().getColumnCount();
System.out.println();
for(int i=1;i<colCount+1;i++){
System.out.print(rs.getMetaData().getColumnName(i)+"\t");
}
System.out.println();
while(rs.next()){
for (int i=1;i<colCount+1;i++){
System.out.print(rs.getString(i)+"\t");
}
System.out.println();
}
}
}
The support of SQLite for source data use is demanding. Data, no matter of what type, must be loaded to it for computation (Certain lightweight databases can directly identify CSV/Excel files as a database table). There are two ways to load the CSV file Orders.txt. The first uses Java to read in the CSV file, composes each row into an insert statement, and then executes the statements. This requires a lot of coeds. The second is manual. Users download the official maintenance tool sqlite3.ext and execute the following commands at the command line:
sqlite3.exe ex1 .headers on .separator "\t" .import D:\\data\\Orders.txt Orders |
Though losing points in the source data support scalability, the database software reclaims them by winning the structured data computation test. It handles all basic algorithms conveniently and performs well.
xxxxxxxxxx
// Conditional query
results = statement.executeQuery("SELECT * FROM Orders where Amount>1000 and Amount<=3000 and Client like'%S%' ");
// Sorting
results = statement.executeQuery("SELECT * FROM Orders order by Client,Amount desc");
// Grouping & aggregation
results = statement.executeQuery("SELECT strftime('%Y',Orderdate) y,sum(Amount) s FROM Orders group by strftime('%Y',Orderdate) ");
// Join operation
results = statement.executeQuery("SELECT OrderID,Client,SellerId,Amount,OrderDate,Name,Gender,Dept from Orders inner join Employees on Orders.SellerId=Employees.EId")
In a word, SQLlite has the intrinsic characteristics of a SQL engine, which are good hot-deployment performance and poor debugging experience.
4. Professional Structured Data Computation Languages
They are designed for computing structured data, aiming to increase algorithm expression efficiency and execution performance and with the support for diverse data sources, convenient integration, algorithm hot-deploy, and algorithm debugging. There are not many of them. Scala, esProc, and linq4j are the most used ones. Yet as linq4j is not mature enough, we just look at the other two.
Scala is made as a general-purpose programming language. Yet it has become famous for its professional structured data computation abilities, which encapsulate Spark’s distributed computing ability and non-framework, non-service-connected local computing ability. Scala runs on JVM, so it can be easily integrated with a Java program. To read in and print out all records of Orders.txt, for instance, we can first write the following TestScala.Scala script:
xxxxxxxxxx
package test
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.DataFrame
object TestScala{
def readCsv():DataFrame={
// Only the jar is needed for a local execution, without configuring or starting Spark
val spark = SparkSession.builder()
.master("local")
.appName("example")
.getOrCreate()
val Orders = spark.read.option("header", "true").option("sep","\t")
// Should auto-parse into the right data type before performing computations
.option("inferSchema", "true")
.csv("D:/data/Orders.txt")
// Should specify the date type for subsequent date handling
.withColumn("OrderDate", col("OrderDate").cast(DateType))
return Orders
}
}
Compile the above Scale script file into an executable program (Java class) and then it can be called from a piece of Java code, as shown below:
xxxxxxxxxx
package test;
import org.apache.spark.sql.Dataset;
public class HelloJava {
public static void main(String[] args) {
Dataset ds = TestScala.readCsv();
ds.show();
}
}
Scala code for handling basic structured data computations is fairly simple:
xxxxxxxxxx
//Conditional query
val condtion = Orders.where("Amount>1000 and Amount<=3000 and Client like'%S%' ")
//Sorting
val orderBy = Orders.sort(asc("Client"),desc("Amount"))
//Grouping & aggregation
val groupBy = Orders.groupBy(year(Orders("OrderDate"))).agg(sum("Amount"))
//Join operations
val Employees = spark.read.option("header", "true").option("sep","\t")
.option("inferSchema", "true")
.csv("D:/data/Employees.txt")
val join = Orders.join(Employees,Orders("SellerId")===Employees("EId"),"Inner")
.select("OrderID","Client","SellerId","Amount","OrderDate","Name","Gender","Dept")
// Positions of records are changed after the join, a sorting will keep the order consistent with that of the result set obtained using the other tools
.orderBy("SellerId")
Scala supports running the same code on a rich variety of data sources. It can be regarded as the improved Java, so it also boasts an excellent debugging experience. But, as a compiled language, Scala is hard to hot-deploy.
There is a tool that outperforms Scala. It is esProc, which is targeted at structured data computations. esProc offers a JDBC interface to be conveniently integrated into a piece of Java program. For instance, below is the code for reading in and printing out all records of Orders.txt:
xxxxxxxxxx
package Test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class test1 {
public static void main(String[] args)throws Exception {
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection = DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = connection.createStatement();
String str = "=file(\"D:/data/Orders.txt\").import@t()";
ResultSet result = statement.executeQuery(str);
printResult(result);
if(connection != null){
connection.close();
}
}
public static void printResult(ResultSet rs) throws Exception{
int colCount = rs.getMetaData().getColumnCount();
System.out.println();
for(int i=1;i<colCount+1;i++){
System.out.print(rs.getMetaData().getColumnName(i)+"\t");
}
System.out.println();
while(rs.next()){
for (int i=1;i<colCount+1;i++){
System.out.print(rs.getString(i)+"\t");
}
System.out.println();
}
}
}
The esProc code for handling basic structure data computations is simple and easy to understand:
xxxxxxxxxx
// Conditional query
str = "=T(\"D:/data/Orders.txt\").select(Amount>1000 && Amount<=3000 && like(Client,\"*S*\"))";
// Sorting
str = "=T(\"D:/data/Orders.txt\").sort(Client,-Amount)";
// Grouping & aggregation
str = "=T(\"D:/data/Orders.txt\").groups(year(OrderDate);sum(Amount))";
// Join operations
str = "=join(T(\"D:/data/Orders.txt\"):O,SellerId; T(\"D:/data/Employees.txt\"):E,EId).new(O.OrderID,O.Client,O.SellerId,O.Amount,O.OrderDate,E.Name,E.Gender,E.Dept)";
esProc also provides corresponding SQL syntax for skilled SQL programmers. The above algorithm of handling grouping and aggregation can be rewritten as this:
| str="$SELECT year(OrderDate),sum(Amount) from Orders.txt group by year(OrderDate)" |
An esProc algorithm can be stored as a script file, too, which further reduces the code coupling. Here is an example:
Duty.xlsx stores daily duty records. Usually, one person will be on duty for several continuous workdays and then switch the job to the next person. Based on this table, we want to get the detailed duty data for each person in turn. Below is the data structure:
The source table (Duty.xlsx):
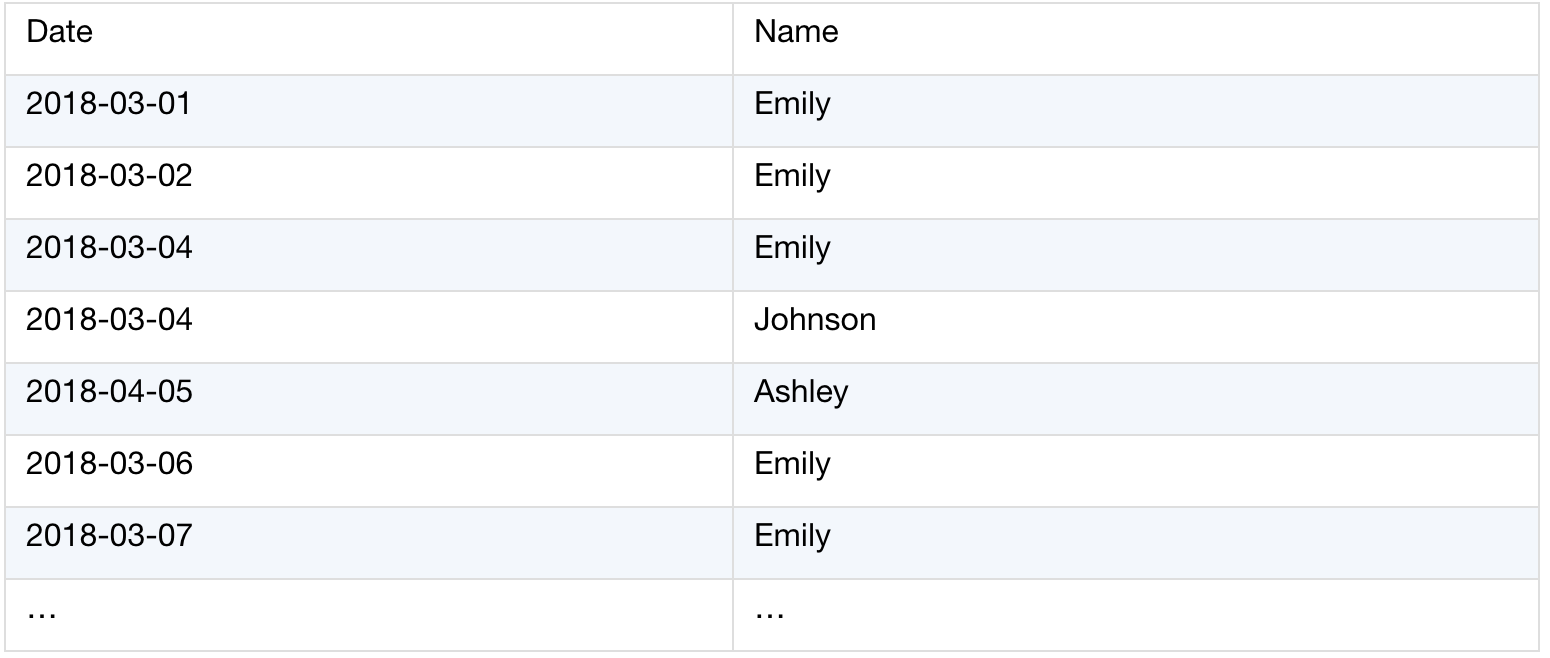
The processing result:
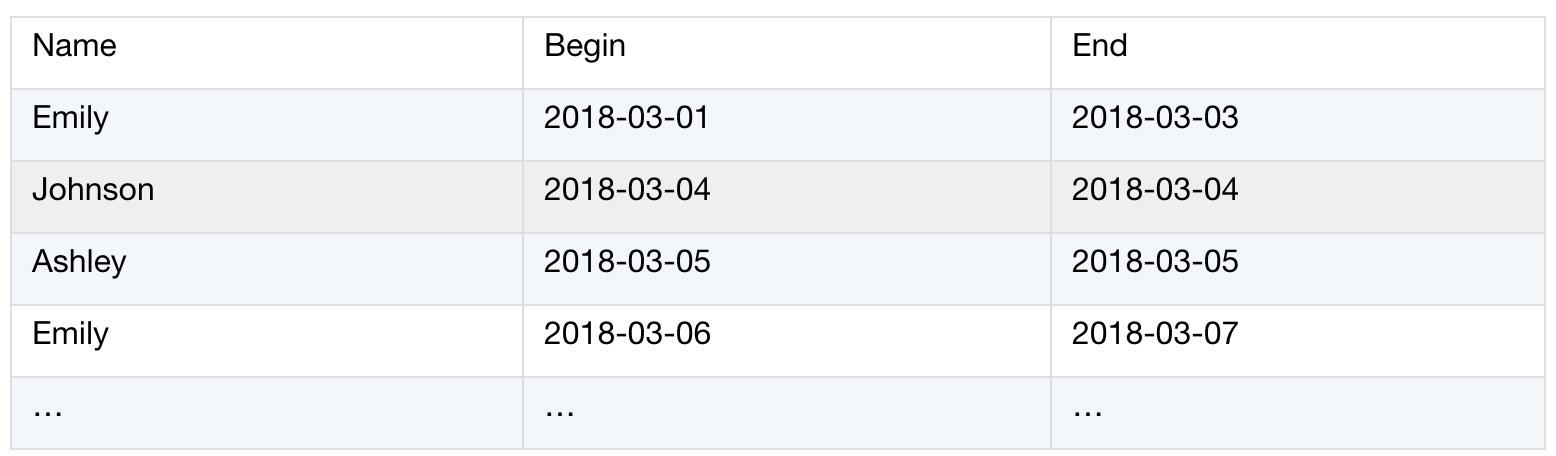
The following esProc script file (con_days.dfx) is used to implement the above algorithm:

Then the esProc script file can be called from the block of Java code below:
x
…
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection = DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = connection.createStatement();
ResultSet result = statement.executeQuery("call con_days()");
…
Though the above algorithm contains complex computing logic, which is hard to express even with Scala or a lightweight database, esProc is easy to implement with richer related functions and agile syntax.
Placing an algorithm outside of the main application also allows programmers to edit and debug code on the specialized IDE. This helps implement algorithms with extremely complex logic. Take the filtering of the running total as an example:
Database table sales stores customers’ sales amounts. The main fields are client and amount. The task is to find the first N big customers whose sum of sales amount takes up at least half of the total amount and sort them in descending order by amount.
We can use the esProc script below to achieve the algorithm and then call it in Java:
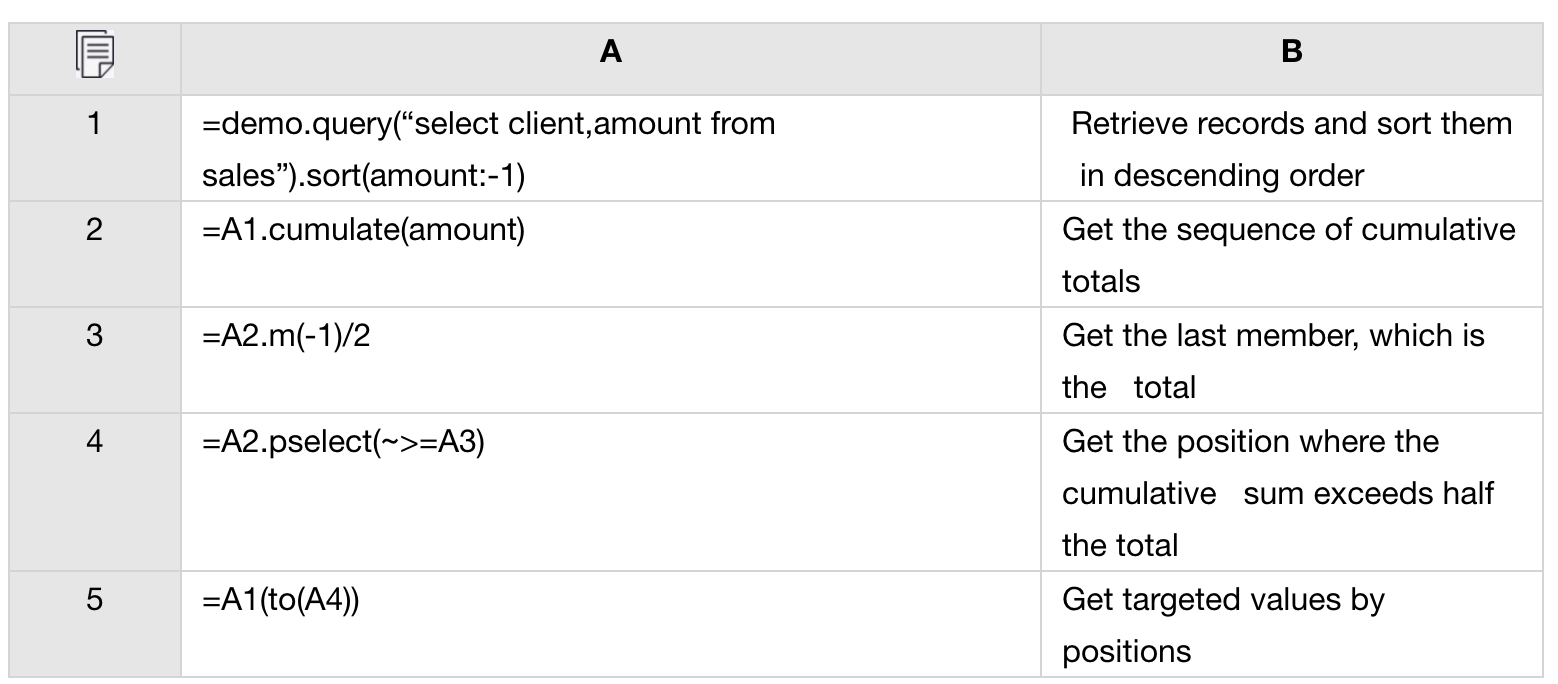
esProc has the most powerful structured data computation capability. Apart from this, it also excels at many other aspects, including code debugging, data source support, big data computing ability, and parallel processing support — which are explained in other essays.
Opinions expressed by DZone contributors are their own.
Comments