Leverage AWS Textract Service for Intelligent Invoice Processing in Account Payables Testing
In modern ERP systems, invoice creation and processing is a well-defined process and automated to an extent across organizations.
Join the DZone community and get the full member experience.
Join For FreeIn modern ERP systems, invoice creation and processing is a well-defined process and automated to an extent across organizations. Despite that, every organization has its own set of standard operating procedures that require tweaks/enhancements. There are intelligent document recognition software like Kofax, Oracle Intelligent Document Recognition (IDR), which offer the built features using AI and ML capabilities to identify the text and images on the invoices sent by the vendors to be paid, which are usually in the pdf format. There is no specific invoice layout or template that is followed, which leads to multiple variations in terms of layout and template differences, adding up the complexity for the built-in features not able to identify certain fonts, data inside the HTML tables, etc., leading to partial data entry causing the invoice entry operator to manually review and update the missing fields for each invoice.
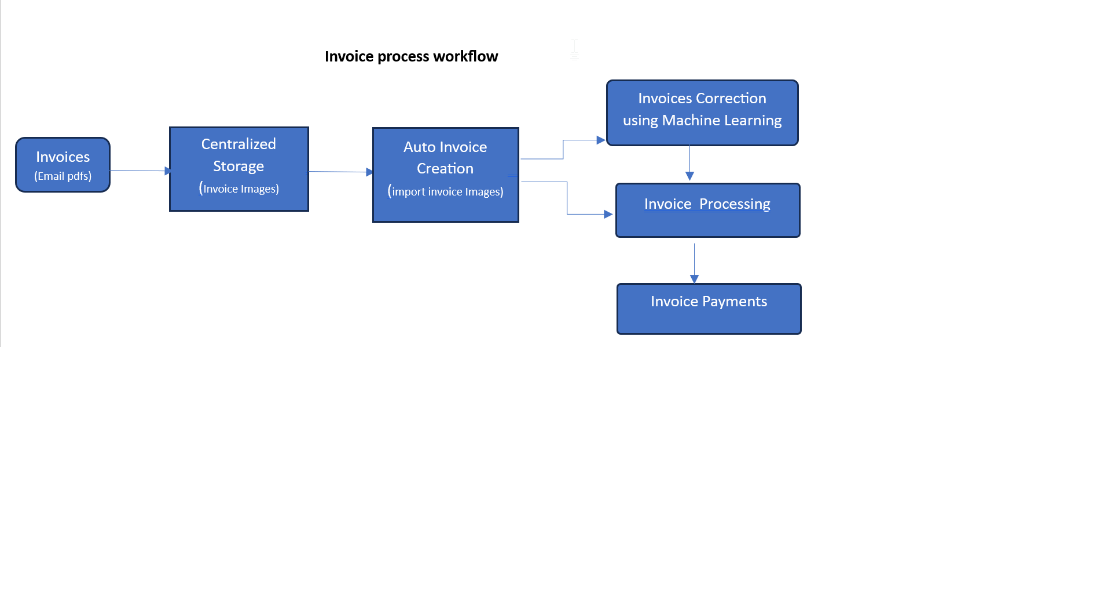
Invoices are emailed as PDF attachments to a dedicated Inbox setup to receive the incoming invoices from the vendors directly. It is advisable to segregate the inboxes based on the geographic location of the vendor and business units so they can be scheduled to auto-import and create invoices with the invoice details auto-populated.
QA teams, while testing this process, can’t automate the end-to-end testing due to challenges in the invoice text extracts, and even the semi-automated testing yields inconsistent results due to the varied invoice formats across the different vendors. The confidence rate achieved from the machine learning of the invoices does take a significant amount of time to reach the desired level.
AI and ML tools can be leveraged to perform the end-to-end testing without manual intervention using a mix of traditional automation tools like Selenium to automate the UI screens and Amazon Textract service, which automatically extracts information from printed text, forms and tables in the pdf document and the invoice details are stored as strings which are fed to the selenium script as an input data to check if the auto invoice details populated by the Kofax or IDR is correct and also anything that was not identified or left blank can be filled with the selenium auto script.
To analyze invoice and receipt documents, use the AnalyzeExpense API operations and pass a document file as input. AnalyzeExpense is a synchronous operation that returns a JSON structure that contains the analyzed text.
The results will vary depending on the number of different invoices that are used for testing as the AWS Textract service model will improve over a period of time in identifying even difficult fonts, data from tables, and geo-specific information. There is an associated license font for the AWS Textract service, but considering the effectiveness and accuracy in extracting the text from the invoices, it is a good model to utilize both in the testing and also as part of the business process improvement. Even the payables invoice entry users would save a lot of time in terms of manual review and reconciliation of the entered data. This is also a definite business use case to save on the manual data invoice entry hours and improve the operational efficiencies of the organization.
Opinions expressed by DZone contributors are their own.
Comments