This article is a part of a series that looks at serverless from diverse points of view and provides pragmatic guides that help in adopting serverless architecture, tackling practical challenges in serverless, and discussing how serverless enables reactive event-driven architectures. The articles stay clear of a Cloud provider serverless services, only referring to those in examples (AWS being a common reference).
As discussed in the article, "Serverless Reference Architecture," serverless finds its footprint in diverse workload patterns. Web is the most common and ubiquitous application type, allowing the delivery of content and business journeys over the internet. This article details 5 patterns of serverless web architecture, with details on the motivation and impacts of using the pattern. The designs are presented in a cloud/vendor-neutral way with a supplementary AWS implementation. Given the range of services across all major cloud providers, the same pattern can be implemented across all. Finally, the details include a few potential pitfalls and best practices.
A few cross-cutting concerns across these patterns are:
- Idempotency of serverless functions
- Stateless workloads
- Potential issues and focus on cold start issues
- Use of message sidelining with concepts such as Dead Letter Queues
These patterns can co-exist within the same application depending on the context and requirements.
Pattern 1: Archetypical Web
| Name |
Archetypical Web |
Primary Arch Focus Area |
Web |
Secondary Arch Focus Area |
UX |
Short Description (Problem and Approach) |
The serverless solution to the typical web/mobile application that provides a SPA/Microfrontends UI and a REST backend, with serverless compute and serverless data and messaging. |
Motivation (The big picture) |
Most of the applications today are SPA with an API backend that provides transactional, querying, reporting, and other information services (i.e., the erstwhile MVC architecture). This pattern is a decoupled, serverless avatar of the same. |
When to Use |
- The application has a web/mobile channel that integrates with the microservices API backend layer that provides simple processing and DB CRUDs.
- The microservices workload processing is not blocking and involves minimal synchronous integrations.
- The UX layer can wait for a synchronous data response.
- The application is stateless and does not rely on a session state.
- The application's static content must be distributed across regions.
|
Impacts
|
- Reliability (HA services)
- Performance (Elastic compute, data, and messaging)
- Cost (Pay-As-You-Go with throttling and rate limiting and adaptive serverless DB capacity)
- Operational Excellence (Serverless Operations, Built-in support for logging, metrics, and tracing)
|
Design and Details |
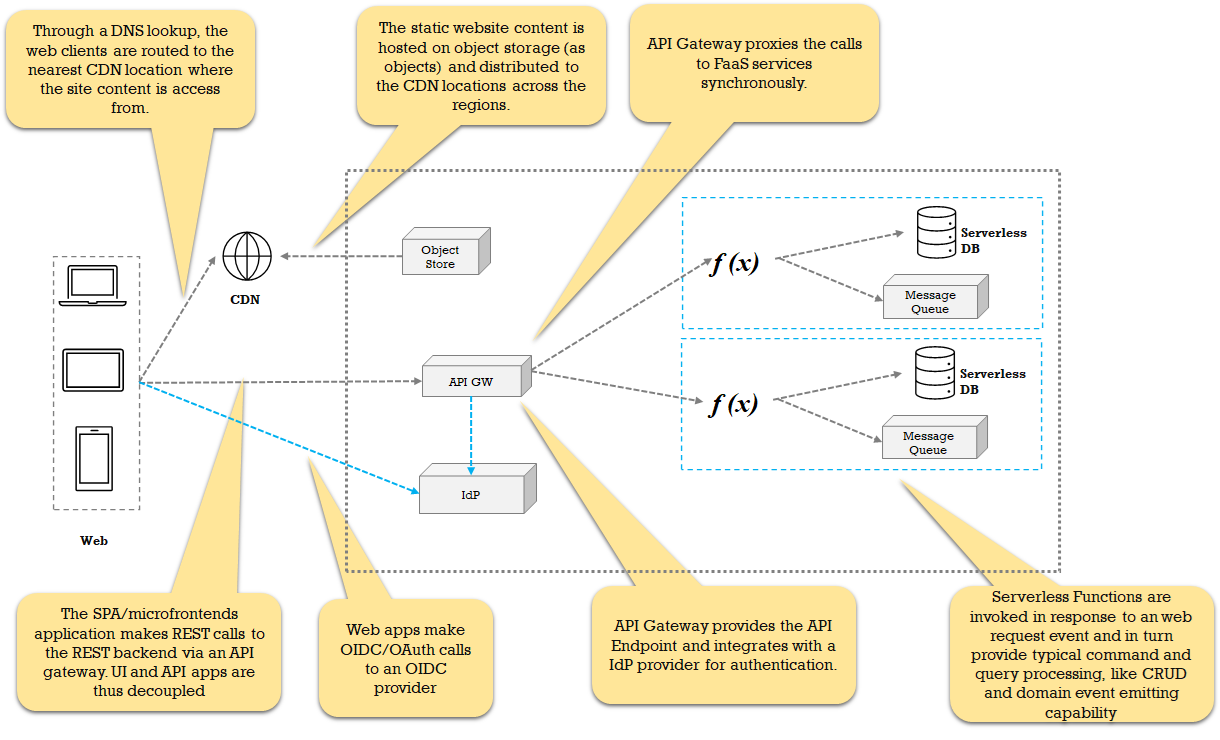
![Archetypical Web pattern used in a microservice]() The pattern is used in a microservices application that:
- Typically needs a DB CRUD-based processing and can emit events for other consumers to process.
- Are SPAs with an API backend
- Can rely on REST calls for data and processing
- Does not require complex workflow processing
- Can work with serverless SQL and No-SQL databases for performance and elasticity
- Authenticates with a modern OIDC/OAuth scheme and uses the auth tokens to establish identity and access.
- Are completely stateless or do not put a massive constraint to have a state
- Do not provide a decoupled, asynchronous processing but have synchronous, blocked clients.
|
Hyper-Scaler Example |
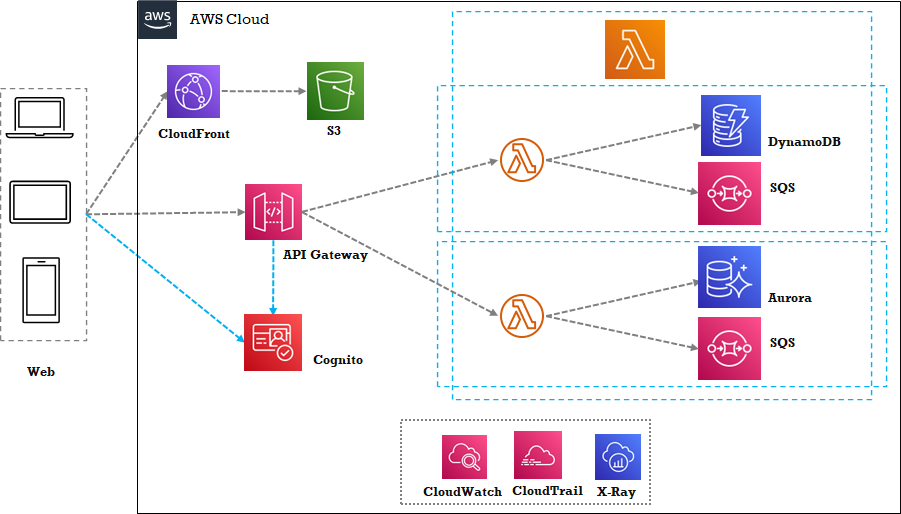
AWS: ![Archetypical Web hyper-scaler example]()
|
Watchouts and Best Practices |
- The scaling of serverless functions is directly based on the amount of traffic from the web. In case of spikes, the multiple functions would be spawned and run concurrently. So, the function concurrency should be calculated and set based on the analysis of application traffic patterns.
- Lookout for cold start issues along with concurrency settings. Microservices that run with functions that take large start-up times would affect the performance and costs.
- The spikes in web traffic can cause unwanted effects on the downstream applications that may not be elastic. The spikes will also consume the DB IO capacity resulting in higher costs. Use the gateway of the serverless functions to throttle the requests to an acceptable number.
- The DevOps CD stage includes a step more: to create an application package and upload it to object storage and then create a distribution for CDN distribution. Depending on the latency a change may take longer for the end users to see.
- Use the Log aggregation service to stream the logs from functions and API Gateway (access log).
- To check the pattern of traffic and debug any performance issues, enable the distributed tracing
- Enable the scaling rules for DB in tune with the application traffic patterns.
- Size the serverless function (Lambda) based on the performance/profiling tests. Right-sizing ensures performance and cost optimization.
- Caching can be enabled at API Gateway and configured at the CDN (CloudFront Level).
|
Pattern 2: Decoupled Web
| Name |
Decoupled Web |
Primary Arch Focus Area |
Web |
Secondary Arch Focus Area |
Messaging, UX |
Short Description (Problem and Approach) |
A serverless web application, that decouples HTTP requests from the request processing and does not block a processed response. |
Motivation (The big picture) |
In many write-intensive applications:
- The client should not be blocked for processing to complete: it is enough to know that request has been successfully accepted.
- The concurrency of serverless compute should be managed by a controlled processing cycle. Even more important when there is a dependency on downstream service.
- Modern microservices transaction patterns such as SAGA are ideal for this pattern.
|
When to Use |
- The application needs to scale up write requests, within a reasonable concurrency.
- The processing depends on a less elastic and scalable service (e.g., legacy system).
- Processing includes a complex workflow (e.g., SAGA Choreography).
- The client can handle alternate ways to know the request processing results (webhooks, WebSocket, polling).
|
Impacts
|
- Reliability – The request processing is queued for processing "later," so processing errors are managed better.
- Performance – The scaling of serverless processing is decoupled from external requests and reacts to messages in durable middleware, and user requests are not blocked.
- Cost – Concurrency is limited, so execution costs are saved.
- Operational Excellence – Greater control to re-try or side-line failed requests.
|
Design and Details |
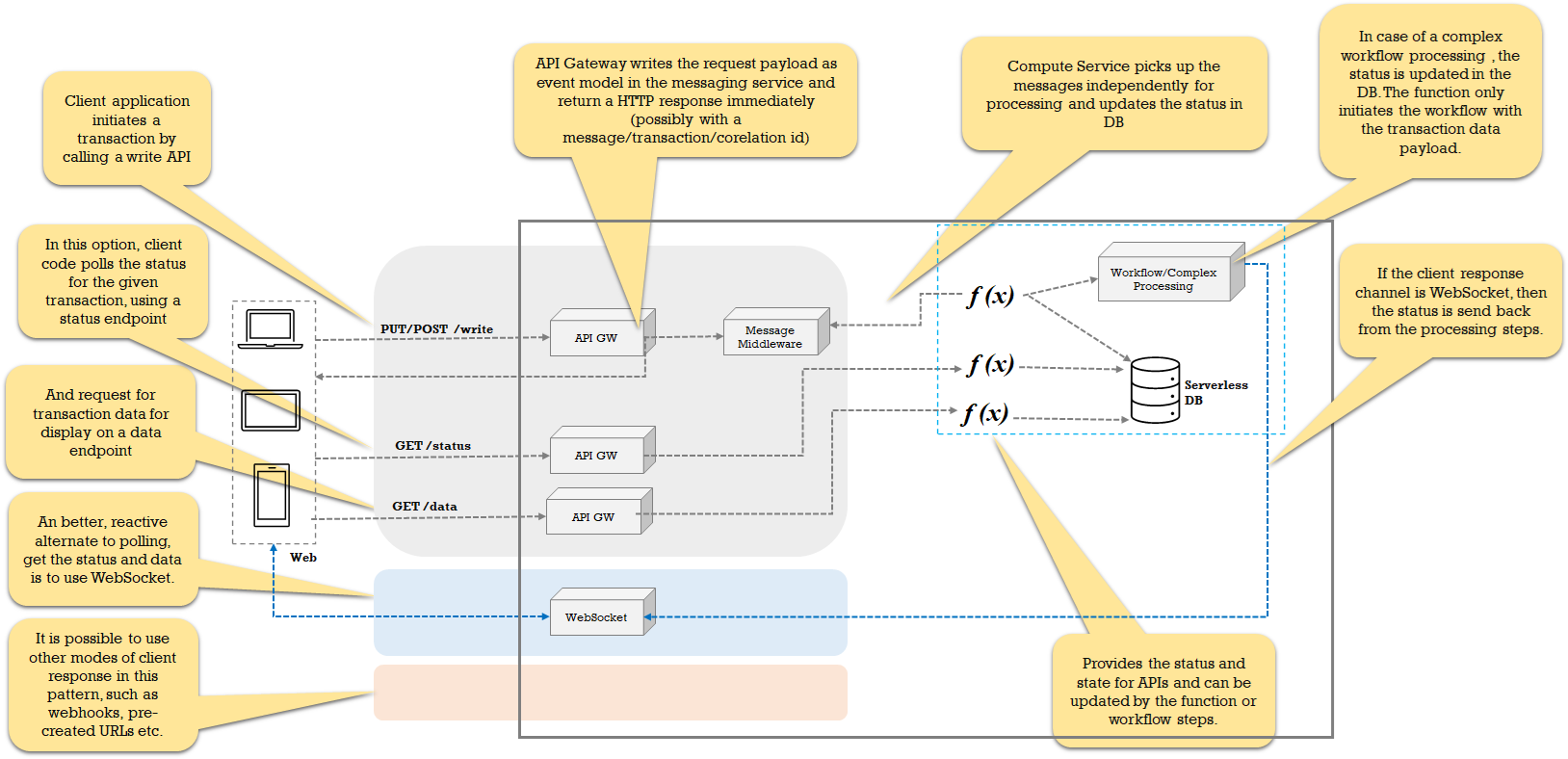
![Decoupled Web design and details]()
- The UI layer can be a SPA implemented in the same way and defined in the Archetypical Web pattern. The UI details have been omitted here for brevity. For native mobile apps, API integration and in-app notifications can be used. Same for IdP.
- Request polling is best suited when the UI just needs to get the results of the transaction and not engage in a multi-step user journey. Imagine a status page with a refresh option.
- WebSocket is best suited on a reactive web where the user journey may be based on multiple steps. Even for a simple status update scenario, WebSocket is a preferred option since it is reactive and does not waste request cycles.
- Authenticates with a modern OIDC/OAuth scheme and uses the auth tokens to establish identity and access: the authentication token is the underlying pattern. The authentication part is omitted here.
- This pattern involves re-imagining the UX to support the decoupled processing, responses, and potential use of WebSocket client for duplex communication.
|
Hyper-Scaler Example |
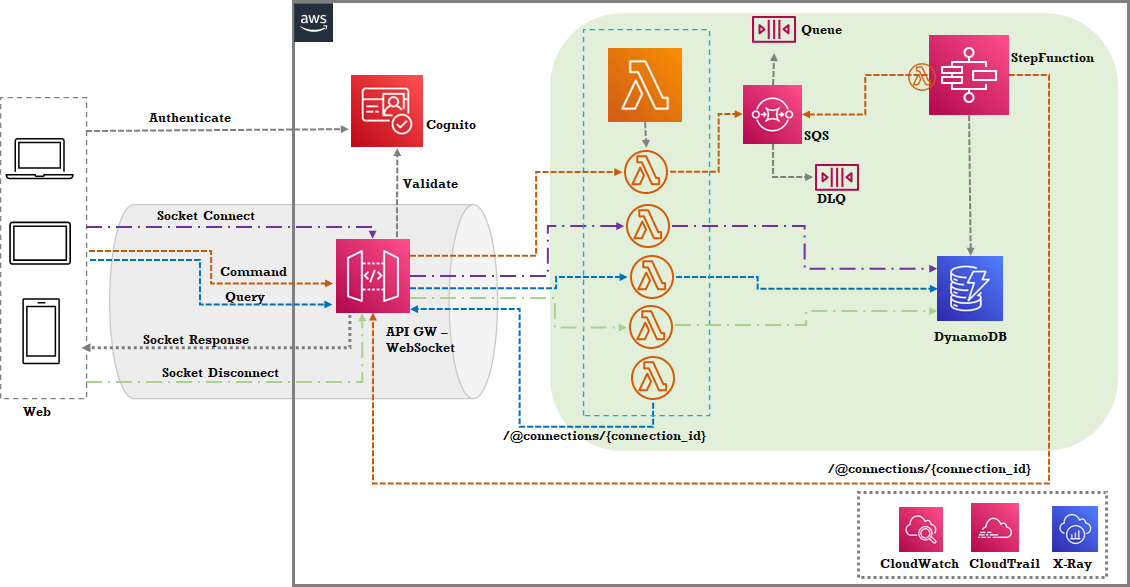
AWS: ![Decoupled Web hyper-scaler example]()
A Single DynamoDB is shown: it can mean multiple tables.
StepFunction execution would be via a workflow step (not shown here). - Instead of SQS, other messaging/streaming services such as Kinesis data streams can be used. Conceptually the ideas remain the same in such cases as well.
|
Watchouts and Best Practices |
- The function concurrency should be based on SQS message processing metrics.
- The SQS queue should be backed by a DLQ for failed messages. Alternatively, Lambda destinations can be used.
- Use the message id as a co-relation id for identifying the transactions and correlating the WebSocket connection identifier.
- Owing to the “At-Least-Once” message delivery guarantee of SQS, the command processors should be idempotent.
- Some of the best practices mentioned in the archetypical web are also applicable here.
|
Pattern 3: Duplex Web
Name |
Duplex Web |
Primary Arch Focus Area |
Web |
Secondary Arch Focus Area |
UX, Messaging |
Short Description (Problem and Approach) |
A serverless web application, that uses a full duplex, WebSocket channel for communication. As opposed to “Archetypical Web” and “Reactive Web”, this pattern does not use REST over HTTP for any microservices operation. The reads and writes are initiated via the same socket, which is alive until the client doesn’t terminate it. |
Motivation (The big picture) |
- The reads and write are completely decoupled and the front end is able to react to the response “in future” on the same WebSocket channel. This makes the front end completely reactive and non-blocking.
- Client(s) needs to receive notifications or events from the server on completion of a condition or a significant domain event.
- Supports the decoupled web cases where the writes initiate a distributed transaction (like a SAGA) where the results and status is pushed back from the server as needed
|
When to Use |
- Should be used in many long-lived session-based applications, where a user spends time logged in to an application; for example, back-office support applications, complex workflow applications, and Chat.
- Streaming client push application that displays dashboards, dynamic charts, and data tables
- Broadcasting or multiplexing of information
- The client can handle responses reactively (i.e., not on a blocked thread)
|
Impacts
|
- Reliability – The socket lifecycle is managed transparently and abstracted from the developer. In addition, the request processing can be queued for processing "later," so processing errors can be handled over a socket asynchronously.
- Performance – The scaling of serverless WebSocket processing resources is in response to the traffic and can be submitted to durable middleware. Since the design is fully reactive, the contention and blocking are minimal.
- Cost – The handler concurrency is controlled as per the volume, so execution costs are saved.
- Operational Excellence – Greater control to re-try or side-line failed requests
|
Design and Details |
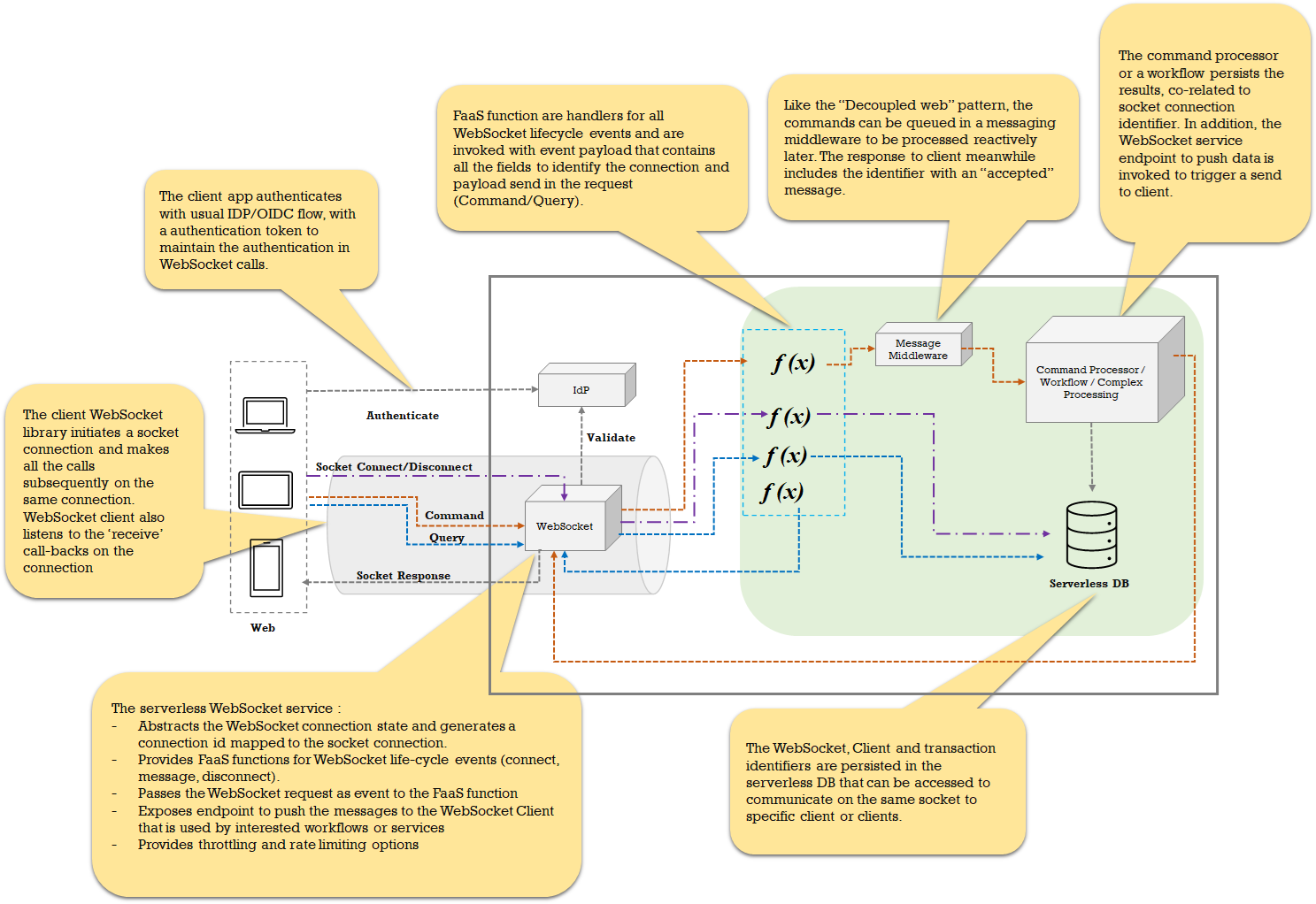
![Duplex Web design and details]()
- The UI consists of a WebSocket client that manages the connection with a socket endpoint. The rest of the library (for DOM and state handling) is similar to other typical web SPA. The UI and content distribution is the same as for other web patterns.
- The application relies on the token-based auth and passes the identity token in the WebSocket request.
- The WebSocket serverless service validates the token for each request.
- WebSocket serverless service manages the low-level connection details and provides the ability to configure FaaS handlers to delegate the WebSocket lifecycle events.
- The Query requests can be request and reply or a socket send.
- The command requests can be fulfilled with the decoupled web pattern where the request is queued and a command processor processes from the queue.
- The WebSocket service provides an endpoint to publish messages on a specific socket. The connection identifiers are persisted in DB and both query and command processors can use those to call the endpoint for a socket send.
|
Hyper-Scaler Example |
AWS: ![Duplex Web hyper-scaler example]()
- It is important to save the socket connection id in the database to refer to it when a service wishes to send back data for a specific client over an existing connection.
- The API Gateway WebSocket service delegates the life cycle handlers to Lambda functions and provides an endpoint to publish on a socket based on an internal connection id. API Gateway maps internal connection id with low-level socket connection id.
|
Watchouts and Best Practices |
- Unlike REST, WebSocket does not provide a standard API-like functionality where a schema language can be defined. The syntax of the payload has to be agreed upon between the client and the WebSocket service.
- Some WebSocket connections may not be terminated properly, due to which a disconnect lifecycle event may not be emitted, so it is important to keep track of stale connections and clean those up with a different process.
- The size of the payload in a single socket response should be carefully crafted. It might make much more sense to send multiple logical responses on a channel for the same outcome instead of sending a big response.
- The transaction or query request that is fulfilled asynchronously should have a mapping in the database to construct the request by services later on.
- The client should ensure that the authentication tokens are sent for calls to the socket endpoint and the socket should validate the token. Before sending an asynchronous response, the service may check the validity of the token if the token is persisted locally. Usually, if a connection is valid and live, the token is valid and this can be ensured by the client app.
- The endpoint exposed by the API Gateway for
@connections should be an internal URL that the services can access (not the global, internet endpoint). This may need the use of VPC Endpoints to access the internal API Gateway endpoint.
Some of the best practices mentioned in the archetypical web are also applicable here. |
Pattern 4: Scatter-Gather Web
Name |
Scatter-Gather Web |
Primary Arch Focus Area |
Web |
Secondary Arch Focus Area |
UX, API |
Short Description (Problem and Approach) |
In a modern microservices architecture, information and processing are distributed. A logical flow for an end-user needs an accumulation of information from different services. So, an API contract can be composed of information across aggregates. A serverless scatter-gather pattern puts the responsibility of this orchestration on a single component to avoid multiple sequential, parallel, or concurrent requests from the clients. A typical orchestrator is a serverless GraphQL service. A channel-specific scatter-gather component fulfills a BFF (Backend For frontend) pattern requirements. |
Motivation (The big picture) |
Use multiple resolvers to fulfill a data request spanning across services, without needing to make clients chatty over multiple calls. Enable a customer-driven query scheme to limit the data needs of per client; an implementation of BFF pattern. It is possible to use a serverless function to orchestrate calls to microservices as a means to scatter-gather, but that is limited in performance and scaling and does not provide customer-driven queries and subscriptions, as a GraphQL-based implementation of this pattern. |
When to Use |
- User journeys are complex and scoped on cross-microservices boundaries.
- Resolve the issue of ‘under-fetching,’ i.e., multiple calls across APIs to fulfill a logical data requirement
- Resolve the issue of ‘over-fetching,’ i.e., a fixed API response for all clients and channels; this is achieved in combination with a customer-driven query service such as GraphQL
- Schema-first design
|
Impacts |
- Reliability – Like API Gateway, a serverless GraphQL service is managed by the cloud platform, and thus is elastic and HA.
- Performance – Addresses the issue of under and over-fetching, thus improving the client performance; but for complex downstream resolvers, the overall performance can be impacted.
- Cost – The serverless cost model for GraphQL service provides a usage-based model. In addition, resolvers are FaaS functions, so costs are controlled with concurrency and throttling checks.
|
Design and Details |
![Scatter-Gather Web design and details]()
- The UI is a client library that supports customer-driven queries with GraphQL. The UI and content distribution is the same as for other web patterns.
- A single GraphQL service provides the ability to create multiple APIs schemas, even for the same service for different client types.
- GraphQL service configures the parts of the schema with different resolvers and "scatters" the request to multiple resolvers as configured. The service also “gathers” the responses and constructs the response as per schema.
- In this approach, UI and backend teams can work independently since they are coupled only with a schema definition that is defined first.
- The resolvers for mutations can adopt a decoupled pattern by using messaging middleware with workflow/state machines for complex transactions.
- The resolvers for queries can be practically any service that accepts an HTTP request and can send a response (for example, FaaS functions, External Systems, HTTP Gateways, etc).
- The resolvers can use multiple database engines and types to fulfill the same query. It is consistent with the polyglot support in microservices.
- The API is unlike a REST standard that uses HTTP verbs and resource definitions. The API is designed around a logical operation. Individual microservices that the resolvers integrate with can expose the functionality with REST over HTTP.
|
Hyper-Scaler Example |
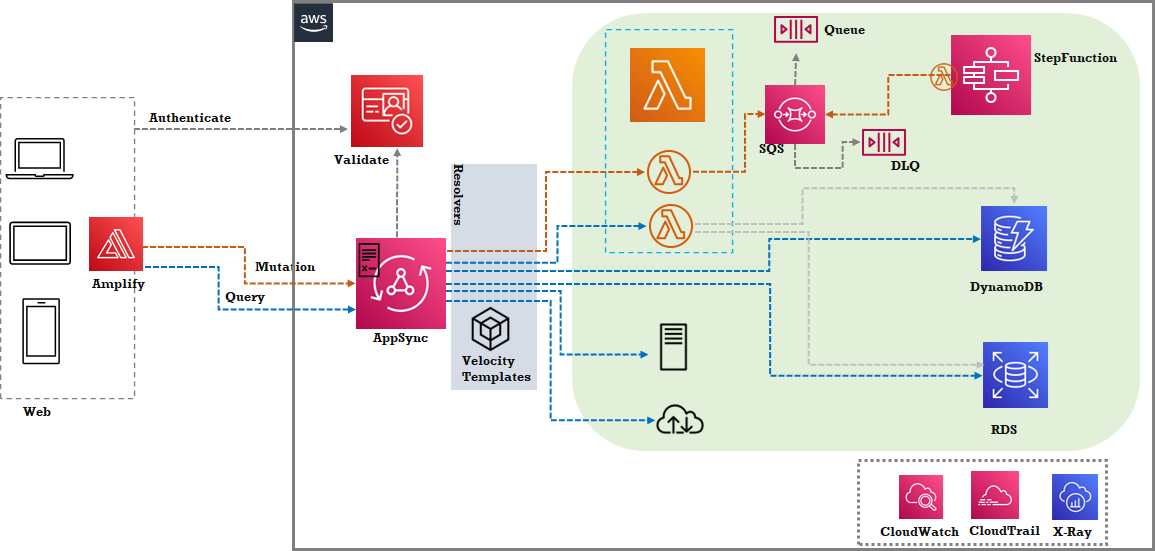
AWS: ![Scatter-Gather Web hyper-scaler example]()
- In addition to a schema-based GraphQL API, AppSync also provides subscriptions and offline data synchronization as well.
- The AppSync service provided a lightweight translation layer to talk to multiple data sources using Apache Velocity Templates.
- The Front End GraphQL library is provided by the AWS Amplify Framework (using this is optional).
|
Watchouts and Best Practices |
- The GraphQL API does not adhere to either OpenAPI specification or REST over HTTP. It provides a specialized type-system that is used to define the schema. So, it is not operable with all HTTP clients, unless a GraphQL client is used. This impacts interoperability.
- The resolvers make synchronous calls to fetch the data, a complex set of resolvers for an API query would run into performance issues if the resolver endpoint were not performant.
- In this approach to API design, the schema should be used as a common contract that all teams adhere to and build and release independently. For example, the frontend/UX team can use the schema definition to define the UI behavior, without dependency on the actual API implementation.
- The concurrency for lambda resolvers should factor in all lambda resolvers used for queries. A throttling in a single lambda resolver can impact the overall API response.
- The mutations via the GraphQL API, if complex, should adopt the decoupled web pattern and communicate the status via client subscriptions.
|
Pattern 5: Strangled Web
Name |
Strangled Web |
Primary Arch Focus Area |
Web |
Secondary Arch Focus Area |
UX, Hybrid, Migration |
Short Description (Problem and Approach) |
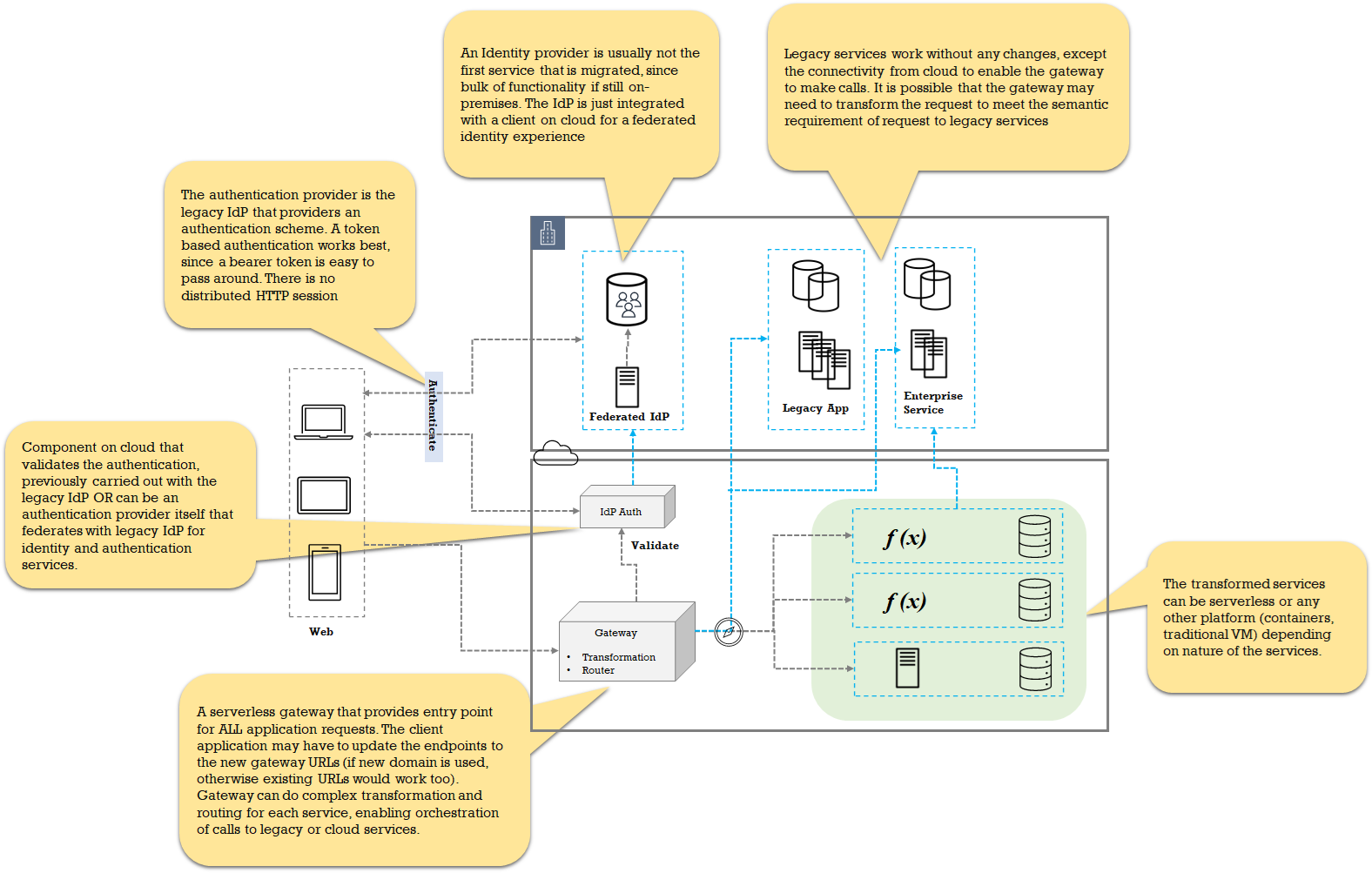
Two modernization drivers – Cloud migration and microservices transformation are best advised to be done incrementally. A big-bang modernization may result in a big-bang disaster owing to the sheer complexity of domain, technology, and skills. A strangler approach to migration allows hedging of risks and focus on parts of the system for modernization. The strangled web pattern enables co-existing of a legacy web application with modernized services that continue to deliver value to customers. |
Motivation (The big picture) |
When a system is seen as a whole, made from cohesive parts, migration and modernization are focused exercises. For legacy monoliths running on-premises, migration paths can be that of re-platform, re-host, or re-architecture. When these strategies are applied to a small set of services, the migration is strangled with better control and planning. To enable strangling, an orchestrator, or a router component with integrations with cloud and on-premises legacy applications are proposed by strangled-web pattern based on serverless. |
When to Use |
- The modernization exercise is planned to be done incrementally and there are identified services that are on the path of microservices and cloud modernization.
- A hybrid strategy is followed where legacy application services run on-premises and a set of services would run on the cloud following a re-platform or a re-architecture migration path.
- The cloud and on-premises networks have been connected.
|
Impacts |
- Reliability – The cloud serverless components are HA and scalable. The services on legacy platforms would continue to provide the same level of reliability.
- Performance – One of the outcomes of the transformation is to tune the performance of services; serverless microservices performance can be expected to improve
- Cost – Since the transformation is phased, the journey is expected to be focused on services that provide maximum value. In addition, the cloud serverless cost model will optimize the cost of running the services.
|
Design and Details |
![Strangled Web design and details]()
- A critical aspect of strangling is the UI layer. While it is easy to reason about API-based service, the user experience is much more complicated than that. If the UI is monolithic with no clear seams based on business service, then UI should be on the path of microservices transformation, with approaches like SPA and Microfrontends. Strangling a monolithic app is difficult without changing the underlying UI skeleton. In these cases there are two paths possible – to deal with UI modernization as part of strangling, which can be explained in a different pattern altogether, or the UI app is served from the legacy app, with changes to API endpoints. An ultra-legacy application that is based on technologies such as JSP or JSF and doesn’t use the
XMLHttpRequest-based API calls cannot leverage this pattern.
- Authentication is another one of the “early choices” that must be made. The legacy application uses traditional authentication. For example, a custom service in the application that maintains the user credentials must be enhanced to play the role of the identity provider, since such service is needed from the cloud-hosted services. The application must maintain a token that can be generated from the IdP and passed to the gateway endpoints. Although employing a simple token is the bare minimum, an OIDC compatible flow with
auth_code grant type is ideal and recommended bit of change for the strangling journey. The OIDC provider can be an existing IdP service itself or a cloud service that uses federated authentication with the IdP.
- The migrated services are (or should be) completely stateless (as microservices are) and the legacy application needs to adopt being stateless or at least needs to provide a façade layer that re-creates a session from the authentication token. A legacy application that heavily relies on HTTP session as maintained by the application server cluster needs to tweak the session management and delegate it to the session façade layer. The change to the mainstream legacy services is abstracted out so that there is minimal impact.
- Gateway is a logical component that provided (at least) transformation and routing functions. The gateway identifies the requests using any request pattern (URI, cookies, header etc) and decides to route appropriately. The gateway is hosted on a network zone that has connectivity with the legacy services.
- Gateway can connect with all kinds of transformed services – serverless or otherwise.
- The calls from the UI are recommended to be always routed via Gateway, even if it is technically possible to make requests across two domains from UI. Typically, the DNS hostname is kept the same as a legacy with the DNS-hosted zone records pointing the existing domain to the gateway URL.
- The legacy servers need to enable a CORS for the new app domain if a new domain has been chosen for cloud gateway.
|
Hyper-Scaler Example |
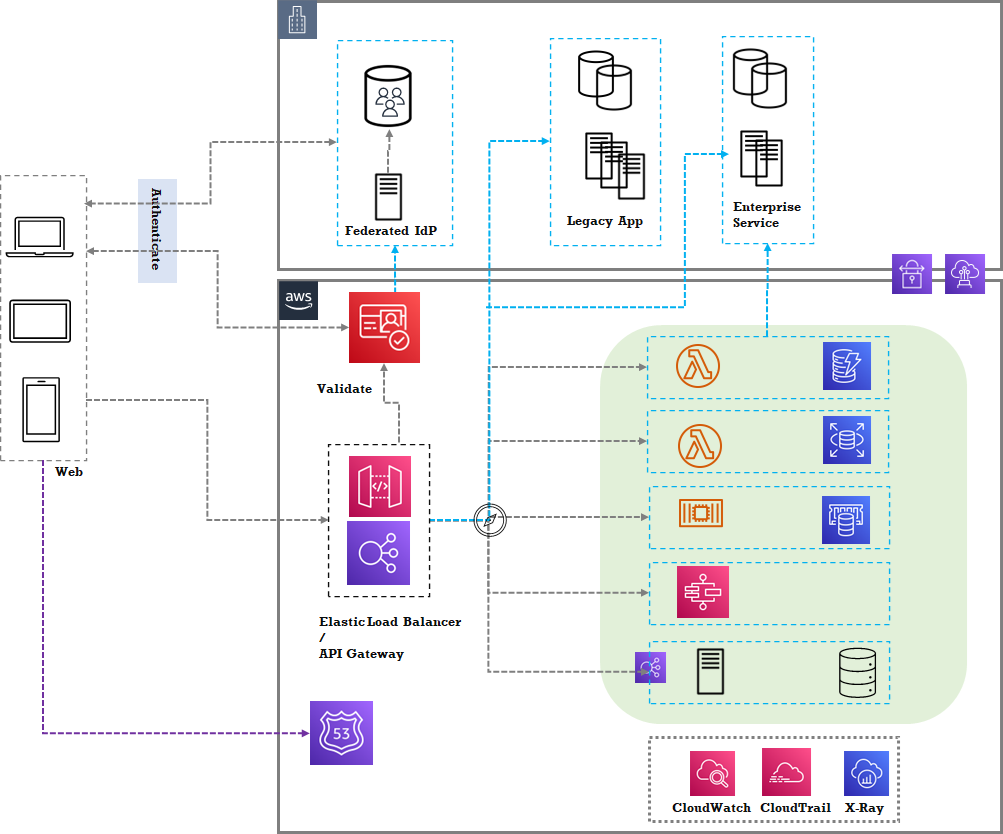
AWS: ![Strangled Web hyper-scaler example]()
- Both ALB and ELB can provide routing based on the rules that can be configured.
- Both ALB and ELB can be an OIDC/Cognito authentication point.
- ALB cannot do complex transformations while API Gateway can delegate to a transformer lambda for request and response transformation.
- A Route53-based DNS resolution is provided for the requests that the client application makes. These are the new DNS requests. To keep using the existing DNS name, the legacy hosted zone records can be migrated to Route53, or the existing DNS provider needs to be updated to map the A/CNAME records to the gateway URL.
|
Watchouts and Best Practices |
- It is recommended that the call from UI on a single domain i.e., of the gateway component and does not talk to legacy service directly. This is to:
- Make the UI requests consistent
- Enable monitoring and metrics on the gateway component itself
- Enable easy routing change on the gateway component when a certain service is finally transformed and migrated to the cloud
- Use a single CA-signed TLS certificate on the gateway
Technically it is possible that UI makes calls on two different domains – one for legacy and another for the cloud.
- Owing to the difference in scaling abilities between serverless a legacy service, any direct coupling would lead to a mismatch of scaling abilities which would result in failures and performance issues. This coupling should be addressed with concurrency and throttling controls.
- Changing the existing app domain may not be possible or even recommended. To use the existing domain the hosted zone records, need to be updated to map to the gateway address
- Enable an OIDC flow with existing IdP to provide the ability to use the authentication tokens to maintain sessions.
|


Comments