Serverless at Scale
The article discusses the architectures currently popular for achieving this Serverless Architecture for Scale use cases and how and when we can use them.
Join the DZone community and get the full member experience.
Join For FreeThis article is a part of a series that looks at serverless from diverse points of view and provides pragmatic guides that help in adopting serverless architecture, tackling practical challenges in serverless, and discussing how serverless enables reactive event-driven architectures. The articles stay clear of a Cloud provider serverless services, only referring to those in examples (AWS being a common reference). The articles in this series are published periodically and can be searched with the tag “openupserverless.”
In this article, we discuss considerations of running serverless at scale. The article also talks about the architectures currently popular for achieving this Serverless Architecture for Scale use cases and how and when we can optimally use the Serverless architecture for scale with AWS Lambda and Dynamo DB exemplar scalable options.
Why Talk About Serverless for Scalability?
When we talk about Scalability, we know that Scalability, Availability, and Performance can be best optimized in many cases with a Client fully controlled On-premises infrastructure setup. But when there are tighter budget approvals, the round-the-clock maintenance and billing costs of the operating systems management, server deployments, admins, etc., become problematic and are perceived as very high costs.
Pay as you Go, else DONT and save manifolds!
In serverless architecture, you need to optimize the code to trigger functions in response to events, and you’re charged only for the time when your trigger event is active. A sudden spike in load will lead to more events and, of course, more cost, but only for when the spike has occurred. Hence it significantly reduces operational cost and complexity associated with the same, and the developers can concentrate on only providing productive results. In the case of serverless architecture, the cloud service provider handles 100% of server management, which includes traffic optimization, development environment updates, resource allocation, and backend configuration. So it is like you are getting zero to minimal overhead at reduced costs!
Here, during periods of peak load, the serverless function can easily scale in response to the multiple concurrent requests at peak.
Design Model Considerations for Your Serverless Applications at Scale
Design 1: Serverless Synchronous Model
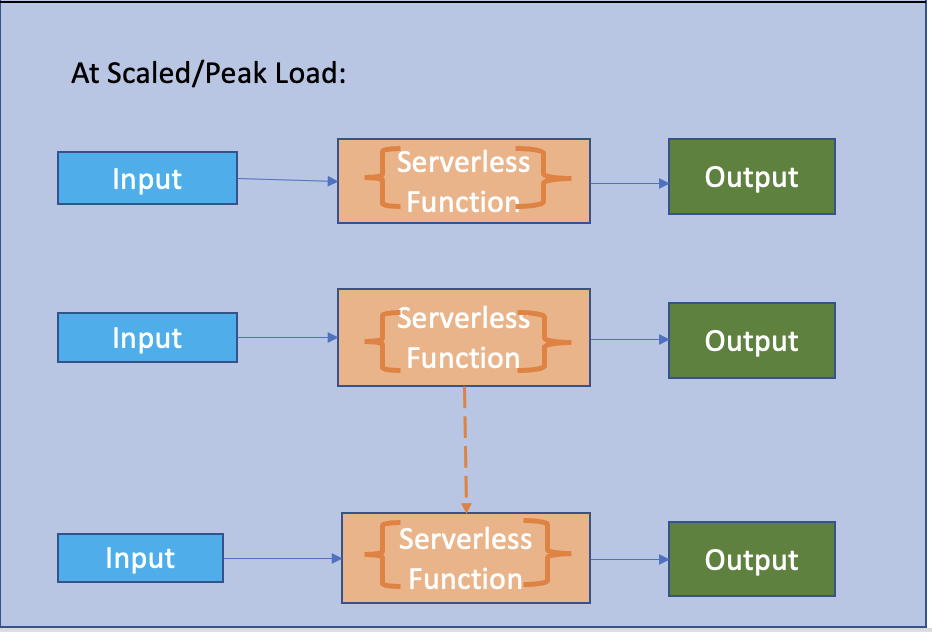
In the Serverless Synchronous model, the serverless function will scale corresponding to the number of requests/events resulting in the corresponding number of outputs.
However, in this case, if the target output system or the downstream system is not designed or modeled to handle the extra load, it may crash.
It is suitable in case of known target outputs at peak load. If we know our systems are capable of handling or storing the peak load at scale, then this model is probably very simplistic, fast, least expensive, and productive in its approach.
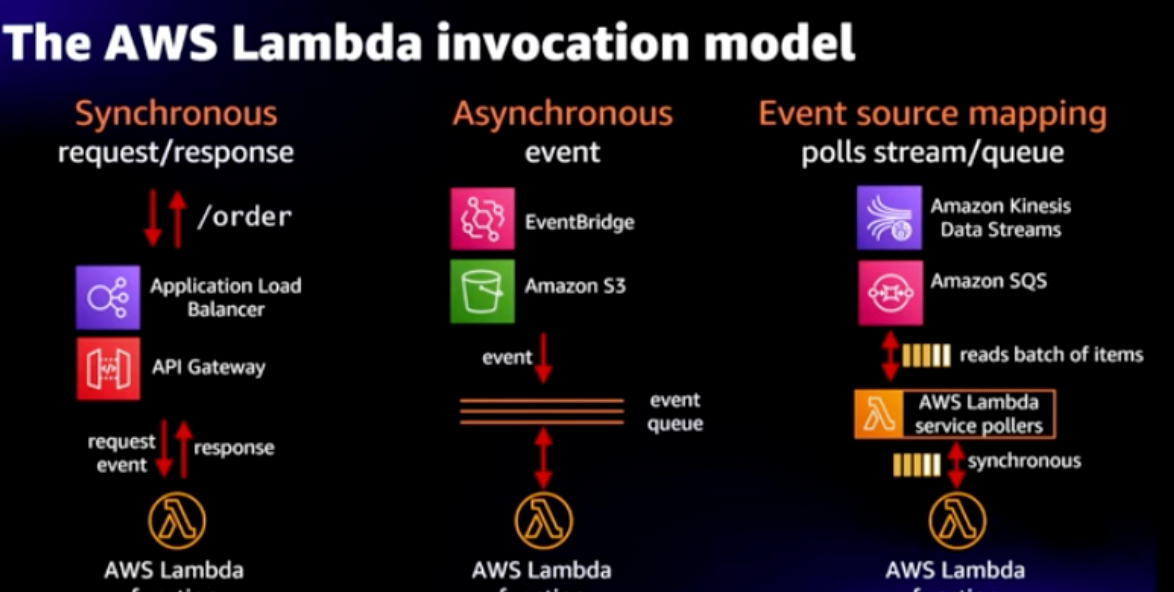
Design 2: Asynchronous Model More Suited for Cloud Native Design
In this model, we consider decoupling our architecture and using an intermediary resilient service to store the incoming bombardment of requests without any data loss.
For the intermediary storage service, we can consider any Event supporting models like queues, e.g., IBM MQ, Amazon SQS, or even durable storage like Amazon S3/Dynamo DB, etc. or any Streaming service like Apache Kafka, Amazon Kinesis, etc.
In this design, we can poll for the requests from the Queue/data store, for example, and then have a batch defined where the serverless functions can work on a defined batch size of requests per iteration and optimally send the results to the target systems.
In this model, we have much better control to handle the target systems' limitations, if any, while ensuring the reliability of the messages.
The Design Models Are Explained With AWS Lambda, Dynamo DB, and SES Serverless Options as Examples
Consider a large Airline service provider who may have to deal with millions of seasonal flight bookings varying as per different holiday seasons.
If the airline provider considers Design 1 elaborated above, a possible solution may look like the one below, with AWS Gateway talking to multiple backends like AWS Lambda, Dynamo DB, SES, and S3.
Design 1 Example:
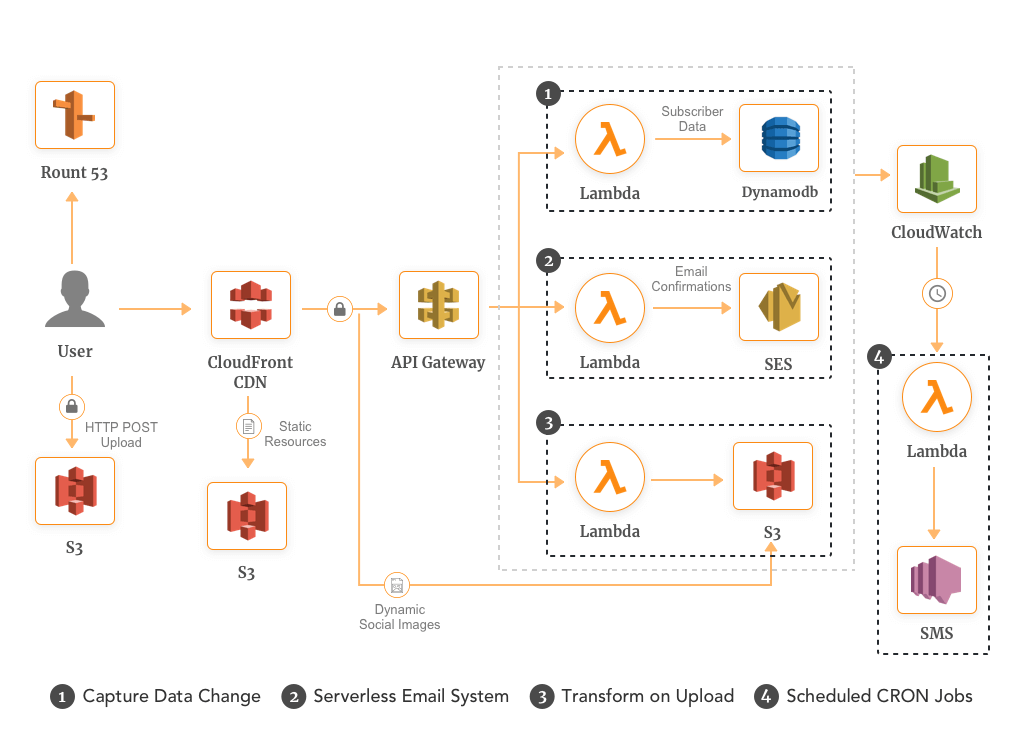
Here, we have used AWS API Gateway to route the messages to concurrent Lambda functions, which then output the results to Amazon DynamoDB, a NoSQL database that is used for storing data here and can scale as per the scaled loads, Amazon SES, a cost-effective, flexible, and scalable email service that enables the airline service provider to send email notifications to the users as needed and Amazon S3 is used for hosting the static website content like HTML, media files, CSS, JavaScript which acts as a front end in the airline client’s browser.
Here, the three target systems – Dynamo DB, SES, and S3 are well-scalable products by themselves with their own scaling capacities; hence the design would be a good fit to be considered with CloudWatch alarms set-up to trigger another set of Lambda functions to send notification messages to the users as needed in case of any alerts from the alarms.
We can leverage CloudFront to distribute the static content securely and globally and provide a better performance, as shown above. Caching static content with CloudFront gives you the performance and scale you need to provide viewers with a fast and reliable experience. CloudFront scales automatically as globally-distributed clients get the requested data available right at the edge where your users are located. Amazon CloudFront can be used for dynamic content and to leverage features like caching.
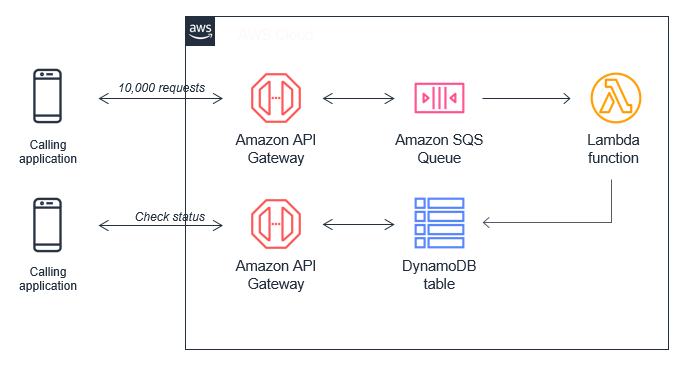
Another Scenario could be that of a Retail chain that expects peak loads only in case of a Super-Sales period but, of course, cannot afford to be dependent on the target system capacity as this Sales day could be that of Black Friday where the expected throughput may be manifolds the normal business day.
Here, we can go for an option as specified below by introducing Amazon SQS, for example, to store the messages reliably and then trigger the Lambda function in a batch size that is well-suited for its underlying storage in the Dynamo DB scalable datastore.
Design 2 Example:
Lambda Concurrency vs Throughput
We can do a high-level concurrency estimation of lambda based on the throughput and the function execution time as follows:
Concurrency Estimation
Avg Function execution time in seconds * average requests/sec = Concurrency estimate
Eg.
if Average execution time of request is 0.2 seconds and throughput is 5 requests/sec, then concurrency estimate = 0.2 *5 = 1
Scaling Limits in Serverless
When all current containers for the required function are already in the middle of processing events, the Serverless function needs to scale out.
And it does so magically without any effort!
For example, the AWS Lambda function will scale out automatically to support the extra load without any need to provide for the same in advance from your side. And more so, the lambda cost for processing 500 events in parallel by 500 containers will be the same as processing one event at a time serially by one container.
So are we saying we can scale out indefinitely with the serverless architecture?
Obviously No. The Cloud Service Provider will be bankrupt in that case in no time!
So by default, each CSP will set these limits for the number of concurrent executions across all its serverless functions per account per region. E.g. per the AWS account, this limit is currently 1000 for the Lambda functions, but we can request to get this increased by contacting the CSP Support team.
If we reach this Scaling limit set by the CSP, we see Throttling errors in the execution.
It is important to note since this limit is account-wide, one serverless function that has scaled out BIG can potentially impact the performance of every other function in the same account. Hence it is advisable to segregate different potential services expected to scale in different accounts to avoid these throttling issues.
Concurrency Controls
Another option to avoid Throttling errors due to the scaling limits described above is to configure Concurrency Controls per function at the CSP level.
So in the case of AWS Lambda, we can configure it as below:
Reserved Concurrency
We can set Reserved Concurrency per function so that other functions cannot use its limit and cause throttling issues to this function when trying to scale out. This can usually be configured free of charge.
Provisioned Concurrency
With Provisioned Concurrency, we can request for some pre-provisioned environments by the CSP to immediately run and respond to expected peak loads. With Provisioned Concurrency, the CSP will take care of the provision of your environments for you without any latency of cold starts. This, however, is a chargeable option.
Other Stress Points
Besides throttling errors, we may see other stress points as below during this execution at scale:
- DB load can impact query performance and Lambda execution time.
- Higher the lambda execution time, the more the cost, and it can also cause API Gateway timeouts (~29 sec).
- Higher lambda execution time can also cause Lambda function timeouts (~15 min).
- Lambda burst throttling can cause API Gateway errors.
Optimizations
If we come across the stress points listed above, we can work on below possible optimization solutions:
- Lambda function -> AWS Step Functions Workflow
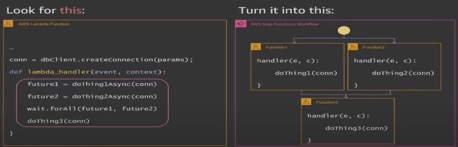
2. Richer workflows as below:

3. API Gateway Throttling options.
4. Convert API from Synch to Asynch and use patterns such as Polling, Webhooks, Websockets, etc.
5. Consider changing database types like Amazon Aurora Serverless data API or the use of Dynamo DB.
6. Pool and share database connections.
Serverless Scaling Model
The serverless function, e.g., Lambda by default, follows a horizontal scaling model by instantiating new containers to handle the extra load.
We can, however, configure the serverless function to scale vertically too. E.g., Lambda functions in AWS can be manually configured to scale from 128 MB to 10 GB of RAM (currently), and the performance scales vertically proportionately.
Opinions expressed by DZone contributors are their own.
Comments